MindSpore-FCOS模型权重迁移推理对齐实录
准备工作
环境:
wsl2 Ubuntu 20.04
mindspore 2.0.0
python 3.8
pytorch 2.0.1 cpu
基于已有的mindspore FCOS项目和FCOS官方pytorch权重来做迁移,
- FCOS官方pytorch实现
FCOS_imprv_R_50_FPN_1x权重 - MindSpore FCOS项目链接
该代码是mindspore1.6实现的,用新版本运行会有很多warning,warning的接口要更改为新的。
而且没提供训练好的权重,所以用官方的pytorch权重进行迁移,但其中发现MindSpore相比官方有许多地方不同。
权重转换
迁移其实就是在做权重的键值映射对齐,这其中有一些规律可寻,但不多,更多需要自己的分析比对,建立映射字典。
可参考的经验:
- https://gitee.com/lirongxi4/pt2ms_convert
一个迁移脚本,通用性一般 - https://mindspore.cn/docs/zh-CN/r2.0/migration_guide/overview.html
MindSpore官方的迁移指南
根据上述迁移经验,打印两种框架的权重的名称及shape进行比对,总结名称转换方式如下(pytorch的名称改为mindspore的):
import copy, torch
import mindspore as ms
def fcos_pth2ckpt():
m = ms.load_checkpoint('test.ckpt') # mindspore FCOS保存的随机权重
t = torch.load('./weights/FCOS_imprv_R_50_FPN_1x.pth', map_location=torch.device('cpu')) # pytorch FCOS权重
match_pt_kv = {} # 匹配到的pt权重的name及value的字典
match_pt_kv_mslist = [] # 匹配到的pt权重的name及value的字典, mindspore加载权重需求的格式
not_match_pt_kv = {} # 未匹配到的pt权重的name及value
matched_ms_k = [] # 被匹配到的ms权重名称
'''一般性的转换规则'''
pt2ms = {'module': 'fcos_body', # backbone部分
'stem.': '',
'.body': '',
'.rpn': '',
'downsample': 'down_sample_layer',
'backbone.fpn': 'fpn', # FPN部分
'fpn_inner4': 'prj_5',
'fpn_layer4': 'conv_5',
'fpn_inner3': 'prj_4',
'fpn_layer3': 'conv_4',
'fpn_inner2': 'prj_3',
'fpn_layer2': 'conv_3',
'top_blocks.p': 'conv_out',
'bbox_tower': 'reg_conv', # head部分
'cls_tower': 'cls_conv',
'bbox_pred': 'reg_pred',
'scales': 'scale_exp',
'centerness': 'cnt_logits',
"running_mean": "moving_mean", # BN部分
"running_var": "moving_variance",
}
'''BN层的特殊转换规则'''
pt2ms_bn = {
"weight": "gamma",
"bias": "beta",
}
for i in t['model'].keys():
pt_name = copy.deepcopy(i)
pt_value = copy.deepcopy(t['model'][i])
'''通用的处理'''
for k, v in pt2ms.items():
if k in pt_name:
pt_name = pt_name.replace(k, v)
'''BN层处理'''
if 'bn' in pt_name:
for k, v in pt2ms_bn.items():
if k in pt_name:
pt_name = pt_name.replace(k, v)
'''下采样层特别处理'''
if 'down' in pt_name:
if 'bias' in pt_name:
pt_name = pt_name.replace('bias', 'beta')
if 'down_sample_layer.1.weight' in pt_name:
pt_name = pt_name.replace('weight', 'gamma')
'''head部分的特殊处理'''
if 'cls_conv' in pt_name or 'reg_conv' in pt_name:
if '1' in pt_name or '4' in pt_name or '7' in pt_name or '10' in pt_name:
pt_name = pt_name.replace('weight', 'gamma')
pt_name = pt_name.replace('bias', 'beta')
'''改名成功,匹配到ms中的权重了,记录'''
if pt_name in m.keys():
assert pt_value.shape == m[pt_name].shape
match_pt_kv[pt_name] = pt_value
match_pt_kv_mslist.append({'name': pt_name, 'data': ms.Tensor(pt_value.numpy(), m[pt_name].dtype)})
matched_ms_k.append(pt_name)
else:
not_match_pt_kv[i + ' ' + pt_name] = pt_value
'''打印未匹配的pt权重名称'''
print('\n\n------------------未匹配的pt权重名称--------------------')
for j in not_match_pt_kv.keys():
print(j, np.array(not_match_pt_kv[j].shape))
'''打印未被匹配到的ms权重名称'''
print('\n\n------------------未被匹配到的ms权重名称--------------------')
for j in m.keys():
if j not in matched_ms_k:
print(j, np.array(m[j].shape))
print('end')
return match_pt_kv_mslist
输出:
------------------未匹配的pt权重名称--------------------
------------------未被匹配到的ms权重名称--------------------
fcos_body.backbone.end_point.weight [1001 2048]
fcos_body.backbone.end_point.bias [1001]
这俩权重不参与模型forward,是冗余的。
match_pt_kv_mslist就是转换后的mindspore权重,加载后测试发现输出有很大出入,第一个原因是mindspore1.10的ops.sort算子有bug,已提交[issue]https://gitee.com/mindspore/mindspore/issues/I7EHKI),后续版本修复了,所以我升级到2.0.0版本了,其他原因就是网络实现未对齐,接下来主要讲这部分。
区别一:输入处理未对齐
MindSpore FCOS项目链接 输入处理方式就与FCOS官方pytorch实现不一样
- offical pytorch FCOS:BGR 255 ,使用(mean=[102.9801, 115.9465, 122.7717], std=[1., 1., 1.])进行归一化
- MindSpore FCOS:RGB, 使用(mean=[0.40789654, 0.44719302, 0.47026115], std=[0.28863828, 0.27408164, 0.27809835])进行归一化
其他的裁剪,图像padding对推理结果影响不会很大。
归一化对齐为官方实现后仍发现图片值仍有不同(B通道的最大值不一样),可能Normalize的底层实现有区别?没有深究,后续直接用torch的Normalize结果张量输入到mindspore中以实现模型输入对齐。
输入对齐后的测试:使用coco2017验证集第一张图像(val/000000000139.jpg),resize到(800,1216)大小,两个框架的模型分别输入进去,输出有差别,
进行排查,发现模型第一个卷积的padding没对齐。
区别二:第一个7x7卷积padding方式未对齐
pytorch:
torch默认pad模式
![]()
卷积结果:
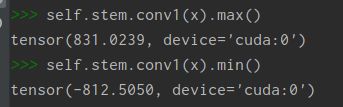
mindspore:
same模式下的卷积跟torch的pad模式下肯定不一样,且两种框架的same也不一样:算子区别

结果自然不一样:

原实现:
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=0, pad_mode='same', weight_init=weight)
改为:
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, pad_mode='pad', weight_init=weight)

结果这就对了。
其实发现设置mindsporefocs实现的resnet中的self.res_base=True就会调用正确的7x7卷积。
第一个卷积对了,但后面BN层就不对了,官方的BN层是一种frozenBN,没有使用eps,去除了eps按公式手动计算,但还是有误差,不知为何…
此外,mindspore实现的fcos的卷积pad_mode全选的same,这个肯定与官方的对不齐,pytorch官方的全使用的zeros模式,对应的mindspore应该是pad模式吧
FCOS对齐先放在这儿,后续再处理,已经有了一定的经验,先去做TOOD的迁移。