查看cuda版本
终端中输入'python'命令,运行python后,输入
import torch
print(torch.__version__)
print(torch.cuda.is_available())

如果输出的结果是False,那么说明当前的Pytorch版本无法使用显卡。
wins+R,cmd命令行输入:
nvidia-smi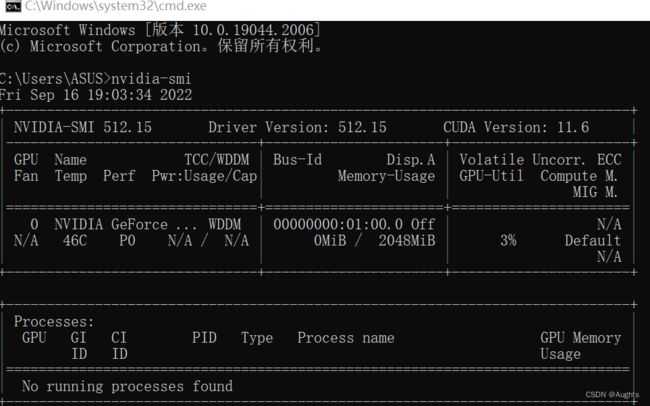
右上角为CUDA版本
配送对应torch的下载:
https://download.pytorch.org/whl/torch_stable.html
cuda安装地址:
下载链接:CUDA Toolkit Archive | NVIDIA Developer
安装cuda
步骤如下:



安装完成,先查看系统变量,然后添加cuda的系统变量:

测试:
win+R
nvcc -V
nvcc --version

出现错误:2022-09-17 10:09:57.076839: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'cudart64_101.dll'; dlerror: cudart64_101.dll not found
2022-09-17 10:09:57.077045: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
1.在目录C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2下搜索cudart64
缺少文件补回:
在用TensorFlowGPU版本训练模型时,运行后发现电脑跳过跳过了GPU,用的CPU运行,这时运行速度会非常慢.虽然能够运行,但是会弹出错误:缺少cudart_101.dll,所这个文件没有找到。其实这个问题的根本原因是:下载的TensorFlow和CUDA不匹配,比如TensorFlow2.2.0系列的应该和CUDA10.1匹配,好像TensorFlow2.3.0系列才会匹配CUDA10.2(我的另外的电脑用的2.3.0版本就不会有这个问题,虽然看官网说2.3.0也是适配10.1)。如果仔细观察,你会发现这个cudart64_101.dll是CUDA10.1里面的,10.2版本的更高(好像是cudart64_102.dll),解决方案也非常简单,那就是下载cudart64_101.dll,将其放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin路径中,这样就OK了。
如果不出意外,这个dll安装好了,运行后会出现另外一个问题,提示缺少cudnn64_7.dll文件(400多MB),原因很简单,TensorFlow2.2.0对应的是CUDA10.1的,前面提出的这2个文件都是基于10.1的,因此,缺少那个文件,就添加哪个文件即可。这样就可以用GPU版本了,速度有了很大提升。
文件下载地址
cudart64_101.dll free download | DLL‑files.com
最后仍然报错,于是把cuda换成10.0的版本
torch1.1.0下载
pip install -U https://download.pytorch.org/whl/cu100/torch-1.1.0-cp37-cp37m-win_amd64.whl
因为cuda10.0,torch1.1.0导致yolo文件中的代码需要更改,如果使用cuda10.1,pytorch1.4以上版本就好像没那么多问题。
| PyTorch 版本 | CUDA 环境 |
|---|---|
| 0.4.1、1.2.0、1.4.0、1.5.0(1)、1.6.0、1.7.0(1) | 9.2 |
| 1.2.0、1.1.0、1.0.0(1) | 10.0 |
| 1.4.0、1.5.0(1)、1.6.0、1.7.0(1) | 10.1 |
P4 = torch.cat([P4,P5_upsample],axis=1)
TypeError: cat() got an unexpected keyword argument 'axis'
这个问题是跑b站作者bubbliiiing写的YOLOv4(pytorch版本)代码中出现的问题,在yolo4.py中有一个特征层之间的连接过程
P4 = torch.cat( [P4,P5_upsample], axis=1),
作者给出的常见问题汇总给出的建议是将pytorch版本更新到1.2.0以上,但是我的显卡是老显卡,cuda版本9.0,查看了版本对应表,最高也只能安装1.0.1版本,但是对于旧版本应该也是可以用的,只要将axis去掉或者改为dim就可以了,具体为
P4 = torch.cat( [P4,P5_upsample], 1),
P4 = torch.cat( [P4,P5_upsample], dim=1)。
#################################################
ciou = (1 - box_ciou( pred_boxes_for_ciou[mask.bool()], t_box[mask.bool()]))* box_loss_scale[mask.bool()]
AttributeError: 'Tensor' object has no attribute 'bool'
ciou = ( 1 - box_ciou( pred_boxes_for_ciou[mask.bool], t_box[mask.bool] ) ) * box_loss_scale[mask.bool]
这个也是版本的问题,将pytorch版本换到1.2.0以上应该就可以解决,不过我的9.0版本的显卡最高也就只能装1.0.1版本,所以心态有点崩,不过最终还是解决了,既然作者用的是新版本的转化方式,那旧版本也应该有旧版本的转化方式,结果查询旧版本的更改方式,然后改为mask.type(torch.bool)就可以了。
ciou = ( 1 - box_ciou( pred_boxes_for_ciou[mask.type(torch.bool)],
t_box[mask.type(torch.bool)] ) ) * box_loss_scale[mask.type(torch.bool)]
#########################################################################
TypeError: sum() received an invalid combination of arguments - got (Tensor, axis=int), but expected one of:
* (Tensor input)
* (Tensor input, torch.dtype dtype)
didn't match because some of the keywords were incorrect: axis
* (Tensor input, tuple of ints dim, torch.dtype dtype, Tensor out)
* (Tensor input, tuple of ints dim, bool keepdim, torch.dtype dtype, Tensor out)
* (Tensor input, tuple of ints dim, bool keepdim, Tensor out)
按照提示,axis关键字错误,经查,torch中用dim,或者直接把axis关键字去掉,即改成:
torch.sum(torch.mul(users, pos_items), dim=1)
或者
torch.sum(torch.mul(users, pos_items), 1)
########################################################################
inter = inter[:, :, 0] * inter[:, :, 1]
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 2.00 GiB total capacity; 1.34 GiB already allocated; 0 bytes free; 39.88 MiB cached)
如果怎么修改,都会出现题中bug,甚至跑了几轮之后突然出现 cuda out of
memory,查看代码中是否存在一下代码(通常出现在main.py 或者数据加载的py文件中:
kwargs = {'num_workers': 6, 'pin_memory': True} if torch.cuda.is_available() else {}
将"pin_memory": True改为False
pin_memory就是锁页内存,创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
主机中的内存,有两种存在方式,一是锁页,二是不锁页,锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(注:虚拟内存就是硬盘),而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。显卡中的显存全部是锁页内存,当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。因为pin_memory与电脑硬件性能有关,pytorch开发者不能确保每一个炼丹玩家都有高端设备,因此pin_memory默认为False。
将train中pin_memory=True pin_memory=False。
后将Batch_size 由四降到二,Batch_size = 2。