常见的文本分析大汇总
常见的文本分析大汇总
小P:小H,你平时做数据分析的时候,会考虑文本信息吗
小H:会啊,虽然能力一般,但是一些基础的信息还是会尝试挖掘的
小P:都有哪些信息可以挖掘啊
小H:比如词频、关键词提取、情感分析、主题词提取等等
词频与词云图
# pip install wordcloud
# pip install jieba
# 导入库
import re # 正则表达式库
import collections # 词频统计库
import numpy as np # numpy库
import jieba # 结巴分词
import wordcloud # 词云展示库
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt # 图像展示库
import jieba.analyse # 导入关键字提取库
import pandas as pd
- 词频提取
本文所有数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-文本分析】自动获取~
# 读取文本文件
with open('article1.txt', encoding='gbk') as fn:
string_data = fn.read() # 使用read方法读取整段文本
# 文本预处理
pattern = re.compile(u'\t|\n|\.|-|一|:|;|\)|\(|\?|"') # 建立正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符串替换掉
# 文本分词
seg_list_exact = jieba.cut(string_data, cut_all=False) # 精确模式分词[默认模式]
remove_words = ['的', ',', '和', '是', '随着', '对于', ' ', '对', '等', '能',
'都', '。', '、', '中', '与', '在', '其', '了', '可以',
'进行', '有', '更', '需要', '提供', '多', '能力', '通过',
'会', '不同', '一个', '这个', '我们', '将', '并', '同时',
'看', '如果', '但', '到', '非常', '—', '如何', '包括', '这'] # 自定义停用词
object_list = [i for i in seg_list_exact if i not in remove_words] # 将不在停用词列表中的词添加到列表中
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/5c/cshbhmfd1bg0zfq_52jlszfh0000gn/T/jieba.cache
Loading model cost 0.649 seconds.
Prefix dict has been built successfully.
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
word_counts_top5 = word_counts.most_common(5) # 获取前5个频率最高的词
for w, c in word_counts_top5: # 分别读出每条词和出现从次数
print(w, c) # 打印输出
数据 113
分析 48
功能 47
Adobe 45
Analytics 37
- 将词频转为词云图展示
# 词频展示
mask = np.array(Image.open('wordcloud.jpg')) # 定义词频背景
wc = wordcloud.WordCloud(
font_path='/Users/heinrich/opt/anaconda3/lib/python3.8/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf', # 设置字体格式,不设置将无法显示中文
mask=mask, # 设置背景图
max_words=200, # 设置最大显示的词数
max_font_size=100 # 设置字体最大值
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
plt.figure(figsize=(12,8))
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show()

关键词提取
# 读取文本数据
with open('article1.txt', encoding='gbk') as fn:
string_data = fn.read() # 使用read方法读取整段文本
# 关键字提取
tags_pairs = jieba.analyse.extract_tags(string_data, topK=5, withWeight=True,
allowPOS=['ns', 'n', 'vn', 'v', 'nr'], withFlag=True) # 提取指定词性
tags_list = [(i[0].word, i[0].flag, i[1]) for i in tags_pairs]
tags_pd = pd.DataFrame(tags_list, columns=['word', 'flag', 'weight']) # 创建数据框
tags_pd
| word | flag | weight | |
|---|---|---|---|
| 0 | 数据 | n | 0.313395 |
| 1 | 报表 | n | 0.163367 |
| 2 | 功能 | n | 0.150263 |
| 3 | 分析 | vn | 0.134857 |
| 4 | 用户 | n | 0.126633 |
情感分析
- snownlp是常见的中文分析包,主要功能包括:中文分词、词性标注、情感分析、文本分类、转换成拼音、繁体转简体、提取文本关键词、提取文本摘要、tf,idf、Tokenization(分割成句子)、文本相似。由于自带电商训练数据,支持快速分析。也提供自己训练语料库
- 基于标注好的玻森情感词典来计算情感值
# pip install snownlp
from snownlp import SnowNLP
import pandas as pd
import jieba
# 基于snownlp的情感打分
def get_snownlp_score(text):
s=SnowNLP(text)
score=s.sentiments
return score
# 基于玻森情感词典的情感打分
def get_BosonNLP_score(text):
df = pd.read_table("BosonNLP_sentiment_score.txt",sep= " ",names=['key','score']) # 加载情感词典
key = df['key'].values.tolist()
score = df['score'].values.tolist()
segs = jieba.lcut(text) # 分词
score_list = [score[key.index(x)] for x in segs if(x in key)]
return sum(score_list) # 计算得分
# 数据读取
comment = pd.read_excel('comment.xlsx')
pattern = re.compile(u'\t|\n|\.|-|一|:|;|\)|\(|\?|"') # 建立正则表达式匹配模式
comment['content'] = comment['content'].map(lambda x: re.sub(pattern, '', x)) # 将符合模式的字符串替换
comment.tail()

# 情感打分
comment['snownlp_score'] = comment['content'].apply(get_snownlp_score)
comment['BosonNLP_score'] = comment['content'].apply(get_BosonNLP_score)
comment.head()

基于LDA的主题词提取
# pip install gensim
import os
import tarfile
import jieba.posseg as pseg
from bs4 import BeautifulSoup
from gensim import corpora, models
import itertools
import matplotlib.pyplot as plt # 图像展示库
from matplotlib.font_manager import FontProperties
- 自定义函数
# 中文分词
def jieba_cut(text):
'''
将输入的文本句子根据词性标注做分词
:param text: 文本句子,字符串型
:return: 符合规则的分词结果
'''
rule_words = ['z', 'vn', 'v', 't', 'nz', 'nr', 'ns', 'n', 'l', 'i', 'j', 'an','a']
words = pseg.cut(text)
seg_list = [word.word for word in words if word.flag in rule_words]
return seg_list
# 文本预处理
def text_pro(words_list, tfidf_object=None, training=True):
'''
gensim主题建模预处理过程,包含分词类别转字典、生成语料库和TF-IDF转换
:param words_list: 分词列表,列表型
:param tfidf_object: TF-IDF模型对象,该对象在训练阶段生成
:param training: 是否训练阶段,用来针对训练和预测两个阶段做预处理
:return: 如果是训练阶段,返回词典、TF-IDF对象和TF-IDF向量空间数据;如果是预测阶段,返回TF-IDF向量空间数据
'''
# 分词列表转字典
dic = corpora.Dictionary(words_list) # 将分词列表转换为字典形式
# print('{:*^60}'.format('token & word mapping review:'))
# for i, w in list(dic.items())[:5]: # 循环读出字典前5条的每个key和value,对应的是索引值和分词
# print('token:%s -- word:%s' % (i, w))
# 生成语料库
corpus = [dic.doc2bow(words) for words in words_list] # 用于存储语料库的列表
# print('{:*^60}'.format('bag of words review:'))
# print(corpus[0])
# TF-IDF转换
if training:
tfidf = models.TfidfModel(corpus) # 建立TF-IDF模型对象
corpus_tfidf = tfidf[corpus] # 得到TF-IDF向量稀疏矩阵
# print('{:*^60}'.format('TF-IDF model review:'))
# print(list(corpus_tfidf)[0]) # 打印第一条向量
return dic, corpus_tfidf, tfidf
else:
return tfidf_object[corpus]
# 全角转半角
def str_convert(content):
'''
将内容中的全角字符,包含英文字母、数字键、符号等转换为半角字符
:param content: 要转换的字符串内容
:return: 转换后的半角字符串
'''
strs = []
for each_char in content: # 循环读取每个字符
code_num = ord(each_char) # 读取字符的ASCII值或Unicode值
if code_num == 12288: # 全角空格直接转换
code_num = 32
elif 65281 <= code_num <= 65374: # 全角字符(除空格)根据关系转化
code_num -= 65248
strs.append(chr(code_num))
return ''.join(strs)
# 解析文件内容
def data_parse(data):
'''
从原始文件中解析出文本内容数据
:param data: 包含代码的原始内容
:return: 文本中的所有内容,列表型
'''
raw_code = BeautifulSoup(data, 'lxml') # 建立BeautifulSoup对象
content_code = raw_code.find_all('content') # 从包含文本的代码块中找到content标签
content_list = [str_convert(each_content.text) for each_content in content_code if len(each_content) > 0]
return content_list
# 构造主题数寻优函数
def cos(vector1, vector2): # 余弦相似度函数
dot_product = 0.0;
normA = 0.0;
normB = 0.0;
for a,b in zip(vector1, vector2):
dot_product += a*b
normA += a**2
normB += b**2
if normA == 0.0 or normB==0.0:
return(None)
else:
return(dot_product / ((normA*normB)**0.5))
# 主题数寻优
def lda_k(x_corpus, x_dict):
# 初始化平均余弦相似度
mean_similarity = []
mean_similarity.append(1)
# 循环生成主题并计算主题间相似度
for i in np.arange(2,11):
lda = models.LdaModel(x_corpus, num_topics=i, id2word=x_dict) # LDA模型训练
for j in np.arange(i):
term = lda.show_topics(num_words=50)
# 提取各主题词
top_word = []
for k in np.arange(i):
top_word.append([''.join(re.findall('"(.*)"',i)) \
for i in term[k][1].split('+')]) # 列出所有词
# 构造词频向量
word = sum(top_word,[]) # 列出所有的词
unique_word = set(word) # 去除重复的词
# 构造主题词列表,行表示主题号,列表示各主题词
mat = []
for j in np.arange(i):
top_w = top_word[j]
mat.append(tuple([top_w.count(k) for k in unique_word]))
p = list(itertools.permutations(list(np.arange(i)),2))
l = len(p)
top_similarity = [0]
for w in np.arange(l):
vector1 = mat[p[w][0]]
vector2 = mat[p[w][1]]
top_similarity.append(cos(vector1, vector2))
# 计算平均余弦相似度
mean_similarity.append(sum(top_similarity)/l)
return(mean_similarity)
- 数据探索
# 汇总所有新闻
all_content = [] # 总列表,用于存储所有文件的文本内容
for root, dirs, files in os.walk('./news_data'): # 分别读取遍历目录下的根目录、子目录和文件列表
for file in files: # 读取每个文件
file_name = os.path.join(root, file) # 将目录路径与文件名合并为带有完整路径的文件名
with open(file_name, encoding='utf-8') as f: # 以只读方式打开文件
data = f.read() # 读取文件内容
all_content.extend(data_parse(data)) # 从文件内容中获取文本并将结果追加到总列表
print('新闻数量:%d' % len(all_content))
新闻数量:18374
- 中文分词
words_list = [list(jieba_cut(each_content)) for each_content in all_content] # 分词列表,用于存储所有文件的分词结果
- 模型拟合
# 训练集的文本预处理
dic, corpus_tfidf, tfidf = text_pro(words_list)
# 主题寻优
# 计算主题平均余弦相似度
news_k = lda_k(corpus_tfidf, dic)
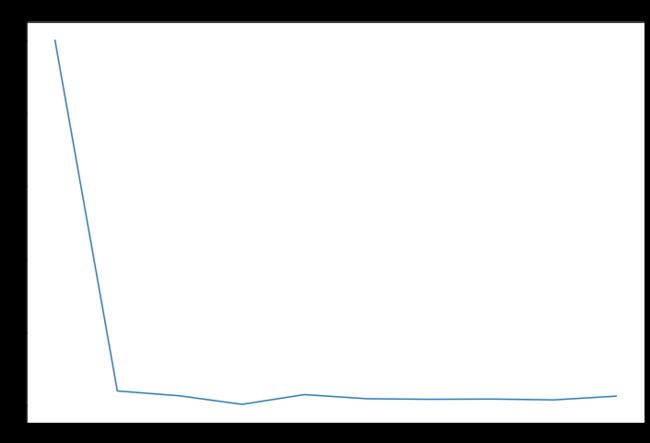
# 绘制主题平均余弦相似度图形
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
font = FontProperties(size=14) # 设置字体大小
plt.figure(figsize=(12,8))
plt.plot(news_k)
plt.title('新闻LDA主题数寻优', fontproperties=font)
plt.show()
# 模型训练
num_topics = 3 # 设置主题个数
lda = models.LdaModel(corpus_tfidf, id2word=dic, num_topics=num_topics) # 通过LDA进行主题建模
lda.print_topics(num_words=5) # 展示每个主题的5个关键词
[(0, '0.003*"小区" + 0.003*"登录" + 0.002*"编号" + 0.002*"户型" + 0.002*"信息"'),
(1, '0.002*"比赛" + 0.002*"是" + 0.001*"散布" + 0.001*"民族" + 0.001*"稳定"'),
(2, '0.001*"过客" + 0.001*"正方" + 0.001*"反方" + 0.001*"牛肉" + 0.001*"失事"')]
- 预测主题
with open('article1.txt', encoding='gbk') as f: # 打开新的文本
text_new = f.read() # 读取文本数据
text_content = data_parse(data) # 解析新的文本
words_list_new = jieba_cut(text_new) # 将文本转换为分词列表
corpus_tfidf_new = text_pro([words_list_new], tfidf_object=tfidf, training=False) # 新文本数据集的预处理
corpus_lda_new = lda[corpus_tfidf_new] # 获取新的分词列表(文档)的主题概率分布
print('{:*^60}'.format('topic forecast:'))
print(list(corpus_lda_new))
**********************topic forecast:***********************
[[(0, 0.23170891), (1, 0.73669183), (2, 0.0315993)]]
总结
文本分析的核心是自然语言处理,本文只能说是冰山一角,但是对于日常挖掘有用的文本信息也还OK,但是如果想更深层次的挖掘文本信息,还是需要寻求专业算法工程师的帮助,例如NLP实验室的同学们~
共勉~