python基础学习4【Matplotlib、散点图、折线图绘制、读取存储不同数据源的数据(csv、txt、excel)、编码】
Matplotlib数据可视化基础(绘图基础语法和常用参数)
创建画布与子图
plt.figure()、plt.title()、plt.savefig()保存绘制的图、plt.show() 展示:
plt.legend():创建图例

figure.add_subplot():向figure添加一个Axes作为一subplot布局的一部分。
plt.xlabel()、plt.ylabel()
分析特征间的关系【散点图、折线图】
加载数据,当我想打印名称时,报错了:

不要怕。(哈哈哈哈哈)
我们在代码里面加上allow_pickle=True:(Numpy 1.16.3版本发行后,numpy.load() 和 numpy.lib.format.read_array() 采用allow_pickle关键字,现在默认为False)
data = np.load('./609/国民经济核算季度数据.npz',allow_pickle=True)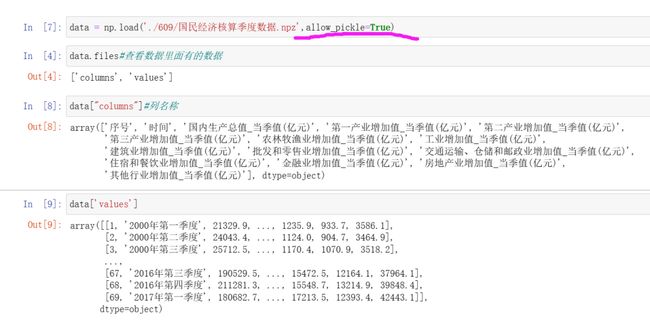
散点图(数值间关联关系:线性、非线性等)
matplotlib.pyplot.scatter()

plt.scatter(range(69),data['values'][:,2])#对季度形成散点图(所有行里面的第二列数据)

折线图【适合用于显示随时间而变化的连续数据】(增长趋势等)
plot函数:x,y:x,y轴;color:线条颜色【b,g,r,c,m,y,k(黑),w】
linestyle:线条样式

当添加样式等时的报错:

解决:(嗯,就是括号没加的勒)

l = ['r','g','b']#线条颜色m = ['o','*','D']for j,i in enumerate([3,4,5]):plt.plot(range(69),data['values'][:,i],c=l[j],marker = m[j],alpha=0.5)#alpha:透明度plt.legend(['The first industry','The two industry','The three industry'])plt.show()

读取不同数据源的数据(csv、txt、excel)
文本文件读取:read_table()
pd.read_table('./seeds_dataset.txt')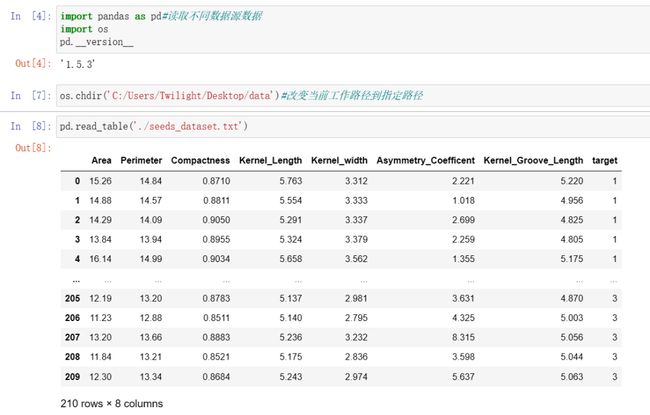
看一个报错:

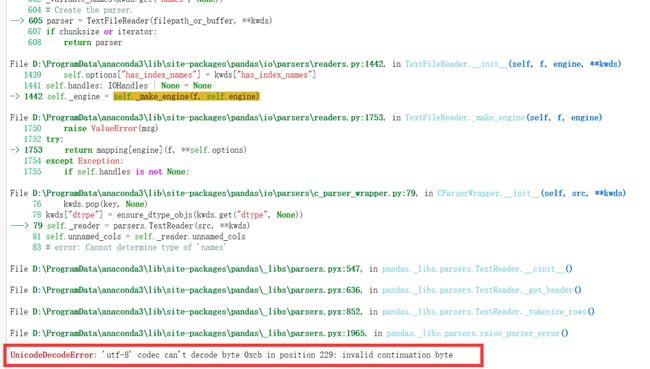
把报错信息拉到底,会发现是编码错误。因为每一个文本文件都会对应一个独一无二的编码方式。所以我们要加上编码格式:【常用的有utf-8、gbk】
pd.read_table('./detail.csv',encoding='gbk')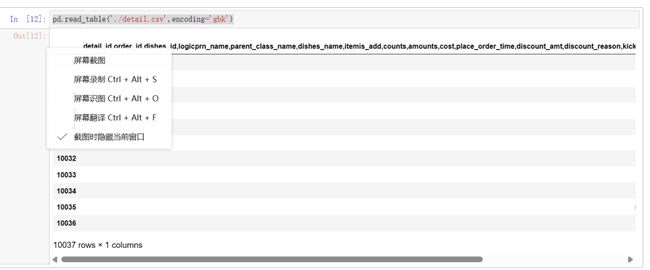
从表上可以看出分割符号是逗号,为了让图表更好看,我们将分隔符加上:
pd.read_table('./detail.csv',encoding='gbk',sep=',')
read_csv()
pd.read_csv('./detail.csv',encoding='gbk')
写入文本文件
DataFrame.to_csv()
data.to_csv('./temp.csv')#到当前路劲下去查看
用excel打开temp:

会发现与原始csv文件想比多了一列,如果不想要这一列,将index改为None:
data.to_csv('./temp.csv',index=None)#到当前路劲下去查看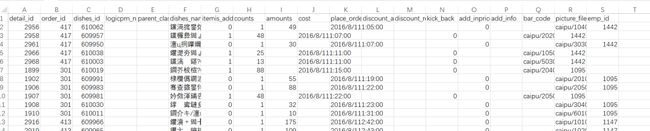
同理,也可以保存为文本文件:
data.to_csv('./temp.txt',index=None,sep='\t')#到当前路劲下去查看读写Excel文件
pandas提供了read_excel函数来读取“xls”"xlsx"两种Excel文件。
pd.read_excel()
pd.read_excel('meal_order_detail.xlsx',sheet_name=0)#sheet_name:查看工作表中的第一个表(sheetnames)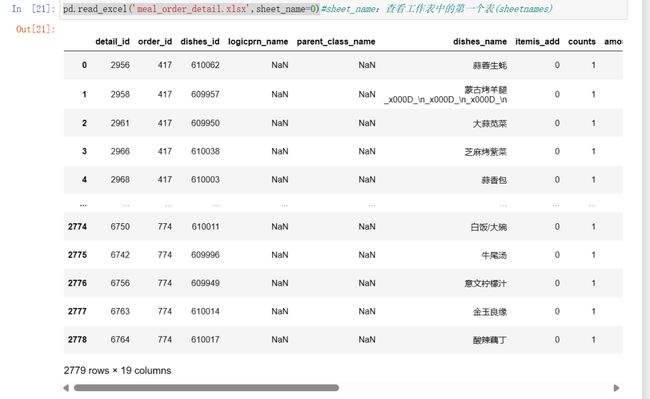
查看工作表中有几个表:
f = pd.ExcelFile('./meal_order_detail.xlsx')f.sheet_names

Excel文件存储
DataFrame.to_excel()
代码:
data.to_excel('./temp.xlsx',sheet_name='a')data.to_excel('./temp.xlsx',sheet_name='b')
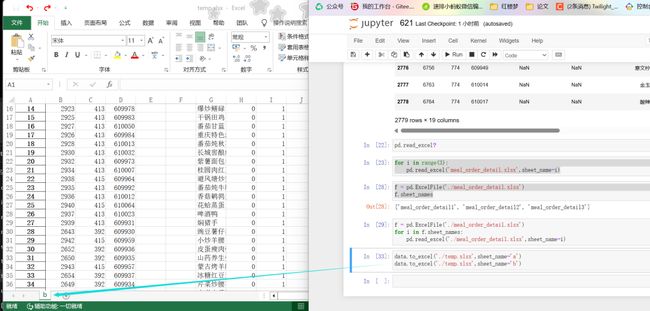
运行这样的代码并不能在一个工作表中生成多余的表,新加入的只会覆盖前面,如果要想达到效果,则需要另外加一些东西:(保存到同一个工作表不同工作簿)
with pd.ExcelWriter('./temp.xlsx') as w:data.to_excel(w,sheet_name='a')data.to_excel(w,sheet_name='b')
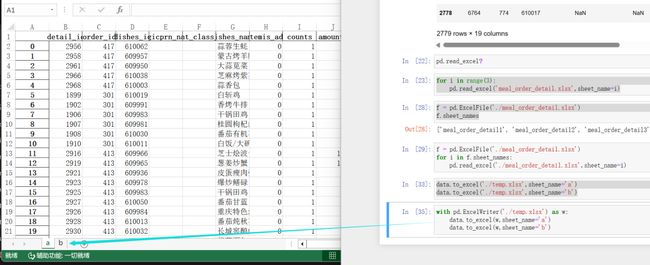
看一个报错:

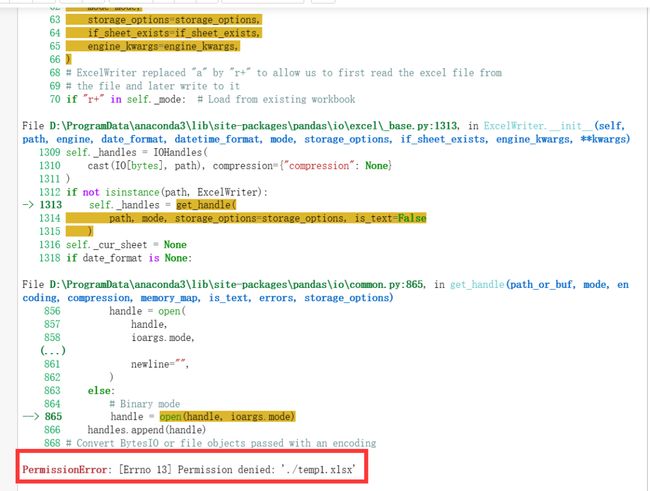
这时候只需要把你打开的temp1.xlsx文件关闭掉,再运行。