一个例子带你了解MapReduce
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:zhuyc@vip.163.com。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
一个例子带你了解MapReduce
本文关键字:大数据、Hadoop、MapReduce、WordCount
文章目录
- 一个例子带你了解MapReduce
-
- 一、前期准备
-
- 1. 运行环境
- 2. 项目新建
- 二、从WordCount开始
-
- 1. 基本流程梳理
- 2. 常规思路实现
- 3. MR思想实现
- 三、MapReduce
-
- 1. Mapper
- 2. Reducer
- 3. Executor
- 4. 运行结果
一、前期准备
1. 运行环境
想要运行WordCount程序,其实可以不需要安装任何的Hadoop软件环境,因为实际上执行计算任务的是Hadoop框架集成的各种jar包。Hadoop启动后的各项进程主要用于支持HDFS的使用,各个节点间的通讯,任务调度等等。所以如果我们只是想测试程序的可用性的话可以只新建一个Java项目,然后集成Hadoop相关的jar包,直接运行程序即可。
这种方式只限于代码测试,因为可以随时修改代码并且执行,结果也可以很方便查看。本文主要讲解MapReduce的运行流程,因此不需要搭建任何Hadoop环境,关于Hadoop任务的提交方式将在其它文章中详细说明。
2. 项目新建
- 首先在IDEA中新建一个Maven项目:
- 修改pom.xml,添加Hadoop相关的依赖:
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.3.5version>
dependency>
dependencies>
二、从WordCount开始
对于Hadoop来说,它的Hello World经典案例当属WordCount了,给出一段文本,我们统计出其中一共包含多少单词。我们可以使用MapReduce的思想来将任务分步执行,这样的好处是更利于任务的分割与合并。现在描述可能没有多大的感觉,我们直接来看下面两个对比。
1. 基本流程梳理
按照常规思路,我们希望最终的结果是以Map形式存储,每个key存储单词,对应的value存储统计数量。于是,我们定义一个Map类型用来存储最终的结果。数据集先使用一个String[]来代替,在最后的MR完整实现中,会从文件中进行读取。
static String[] text = {
"what day is today",
"today is a good day",
"good good study",
"day day up"
};
2. 常规思路实现
如果只是单个的Java程序,我们可以这样做:
public static void main(String[] args) {
// 定义用于存放统计结果的Map结构
Map<String, Integer> map = new HashMap<>();
// 读取数组中的每个元素,模拟一次读取一行
for (String line : text){
// 将每个单词以空格分割
String[] words = line.split(" ");
// 读取每一个单词
for (String word : words){
// 每次将单词的统计结果取出,加1后放回
if (map.containsKey(word)){
map.put(word, map.get(word) + 1);
}else {
// 如果是第一次遇到这个单词,则存放1
map.put(word, 1);
}
}
}
// 输出结果
System.out.println(map);
}
由于是简单的Java程序,这里就不过多说明了,大家可以自己看一下注释。
3. MR思想实现
从上面的程序可以看到,我们使用循环结构,逐行逐个的处理每行字符串中的每个单词,然后将结果不断的更新到Map结构中。在这种情况下,如果我们让不同的线程【相当于不同的Hadoop节点】去处理不同行的数据,再放到Map中时,为了考虑线程安全问题,其实是无法发挥最大作用的,很多时候要等待锁的释放。如果我们用MapReduce的思想来将程序改写一些就会不同了。
- 定义一个K-V键值对结构
static class KeyValuePair<K,V>{
K key;
V value;
public KeyValuePair(K key, V value){
this.key = key;
this.value = value;
}
@Override
public String toString() {
return "{" +
"key=" + key +
", value=" + value +
'}';
}
}
以下程序的编写可以帮助大家理解MR过程中最为重要的3个核心步骤:Map、Shuffling、Reduce。这三个阶段会完成许许多多的工作,对于开发者来说我们最关心的是数据结构上的变化,因此,其中涉及到的排序等相关操作并没有去实现,想要深挖的小伙伴可以去看源码。
- Map阶段
在这一阶段,会对数据逐行处理,key为偏移量,value则是这一行出现的数据键值对列表。
static Map<Integer, List<KeyValuePair<String, Integer>>> doMapper(){
Map<Integer, List<KeyValuePair<String, Integer>>> mapper = new HashMap<>();
// 定义偏移量指标,作为key
int offset = 0;
for (String line : text){
String[] words = line.split(" ");
List<KeyValuePair<String, Integer>> list = new ArrayList<>();
for (String word : words){
// 将出现的单词作为键值对的key,将出现次数作为键值对的value
KeyValuePair<String, Integer> keyValuePair = new KeyValuePair<>(word, 1);
list.add(keyValuePair);
}
// 每次处理一行的数据,生成对应的键值对列表
mapper.put(offset, list);
// 调整偏移量,总字符加一个换行符
offset += line.length() + 1;
}
return mapper;
}
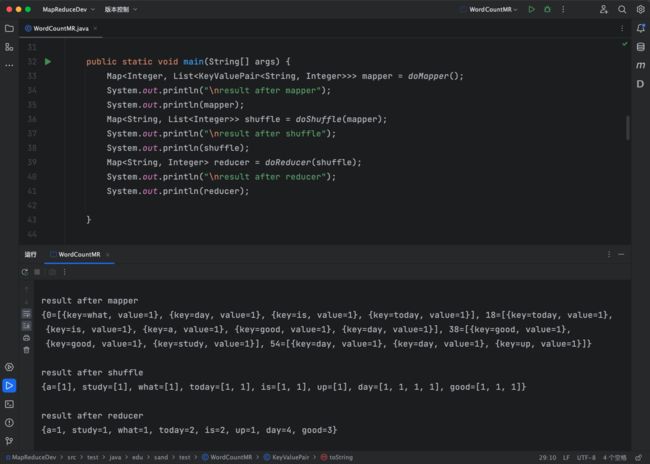
结果如下所示:
{0=[{key=what, value=1}, {key=day, value=1}, {key=is, value=1}, {key=today, value=1}], 18=[{key=today, value=1}, {key=is, value=1}, {key=a, value=1}, {key=good, value=1}, {key=day, value=1}], 38=[{key=good, value=1}, {key=good, value=1}, {key=study, value=1}], 54=[{key=day, value=1}, {key=day, value=1}, {key=up, value=1}]}
- Shuffling阶段
在这一阶段,将会把所有的key进行排序,并把相同的value放在同一个列表中。
static Map<String, List<Integer>> doShuffle(Map<Integer, List<KeyValuePair<String, Integer>>> mapper){
Map<String, List<Integer>> shuffle = new HashMap<>();
for (Integer key : mapper.keySet()){
List<KeyValuePair<String, Integer>> keyValuePairs = mapper.get(key);
for (KeyValuePair<String, Integer> keyValuePair : keyValuePairs){
// 将出现过的相同单词放在同一个列表中
if (shuffle.containsKey(keyValuePair.key)){
shuffle.get(keyValuePair.key).add(keyValuePair.value);
} else {
// 如果是第一次记录,则创建一个列表
List<Integer> list = new ArrayList<>();
list.add(keyValuePair.value);
shuffle.put(keyValuePair.key, list);
}
}
}
return shuffle;
}
此时,依然不涉及计算逻辑,结果如图所示:
{a=[1], study=[1], what=[1], today=[1, 1], is=[1, 1], up=[1], day=[1, 1, 1, 1], good=[1, 1, 1]}
- Reduce阶段
在这一阶段,会在每个key对应的value列表中执行我们需要的计算逻辑。
static Map<String, Integer> doReducer(Map<String, List<Integer>> shuffle){
Map<String, Integer> reducer = new HashMap<>();
for (String key : shuffle.keySet()){
List<Integer> values = shuffle.get(key);
Integer result = 0;
// 此处对value进行处理,执行累加
for (Integer value : values){
result += value;
}
reducer.put(key, result);
}
return reducer;
}
得到最终结果,执行结果如下:
{a=1, study=1, what=1, today=2, is=2, up=1, day=4, good=3}
- 程序运行结果
三、MapReduce
上面的例子帮大家简单的梳理了一下整体流程,这样我们就不需要debug去看每一步的执行效果了,因为只是模拟实现,所以省略了一些步骤。上面定义的KeyValuePair中出现的泛型也是整个流程的重要组成部分,实际执行计算任务时经常要根据需要合理的去定义Key与Value的类型。
1. Mapper
新建一个Class,继承Mapper,重写其中的map方法。可以先定义好泛型,然后再自动生成map方法。
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
/**
* 以下泛型声明的是map阶段输入和输出数据的对应类型
* KEYIN: 偏移量,为整数类型
* VALUEIN: 每一行的字符串,为文本类型
* KEYOUT: 单词,为文本类型
* VALUEOUT: 出现次数1,为整数类型
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* map阶段将字符的偏移量作为key,每次得到的value为一行的数据
* @param key 字符偏移量,包含换行符
* @param value 整行的数据
* @param context 将结果输出到下一阶段的对象
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
if (value != null){
// 获取该行的数据
String line = value.toString();
// 根据空格分离出每个单词
String[] words = StringUtils.split(line, ' ');
// 将每个单词以键值对输出
for(String word : words){
context.write(new Text(word), new LongWritable(1));
}
}
}
}
2. Reducer
新建一个Class,继承Reducer,重写其中的reduce方法。可以先定义好泛型,然后再自动生成reduce方法。
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 以下泛型声明的是reduce阶段输入和输出数据的对应类型,输入类型对应的是Map阶段的输出
* KEYIN: 单词,为文本类型
* VALUEIN: 出现次数1,为整数类型
* KEYOUT: 单词,为文本类型
* VALUEOUT: 统计次数,为整数类型
*/
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 本例中省略了对shuffle的自定义,获取到的是默认处理后的数据
* @param key 单词
* @param values 出现1次的数据列表[1,1,...]
* @param context 将结果最终输出的对象
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// 定义用于记录累加结果的变量
long sum = 0;
// 遍历列表,执行累加操作
for (LongWritable value : values){
sum += value.get();
}
// 输出最后的统计结果
context.write(key, new LongWritable(sum));
}
}
3. Executor
新建一个Class,继承Configured,并实现Tool接口,完整代码如下:
import edu.sand.mapper.WordCountMapper;
import edu.sand.reducer.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCountExecutor extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
// 初始化配置,可以通过这个对象设置各种参数
Configuration conf = new Configuration();
// 完成Job初始化,设置任务名称
Job job = Job.getInstance(conf, "wordCount");
// 设置Job的运行主类
job.setJarByClass(WordCountExecutor.class);
// 设置Map阶段的执行类
job.setMapperClass(WordCountMapper.class);
// 设置Map阶段的数据输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置Reduce阶段的执行类
job.setReducerClass(WordCountReducer.class);
// 设置Reduce阶段的数据输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定数据输入文件路径,如果指定的是文件夹,将读取目录下所有文件
FileInputFormat.setInputPaths(job, new Path("input/"));
// 指定结果输出文件路径,最后一级路径会自动创建,每次重新执行时需要删除或修改名称
FileOutputFormat.setOutputPath(job, new Path("output/wordCount"));
// 使用job调用执行,true代表显示详细信息,成功时返回0
return job.waitForCompletion(true) ? 0 : -1;
}
public static void main(String[] args) throws Exception {
// 调用执行
ToolRunner.run(new Configuration(), new WordCountExecutor(), args);
}
}
4. 运行结果
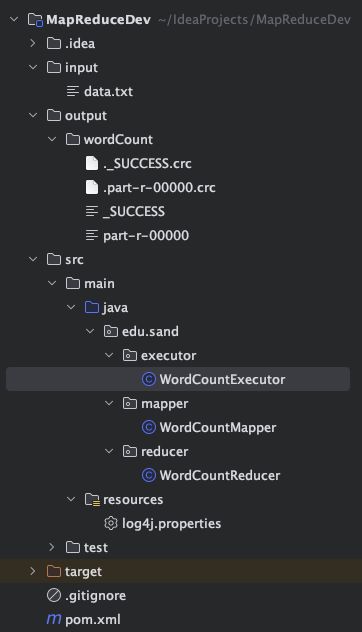
- 项目结构说明
由于是本地代码运行,所以数据输入和结果输出都保存在本地磁盘上,可以在src同级创建两个文件夹input和output。
- 日志配置
如果希望看到更详细的日志输出,可以在resources文件夹下创建一个log4j.properties,内容如下:
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%p\t%d{ISO8601}\t%r\t%c\t[%t]\t%m%n
第一行的日志级别可以设置为INOF或者DEBUG。
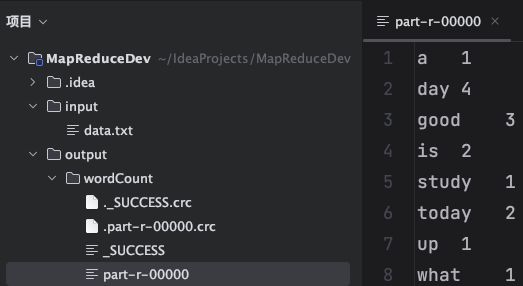
- 执行结果
运行后会在对应路径下自动生成一个文件夹,其中主要包含3类文件:任务执行标志文件、结果输出文件、校验文件。以crc结尾的文件为校验类文件,当任务成功执行时,会产生一个**_SUCCESS文件,具体的运行结果会存放在part-r-xxxxx**文件中,part文件的名称和个数取决于Reduce的数量以及开发者的需要。
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~
