华夏代驾笔记
2.5部署mysql集群
一、部署MySQL节点
本课程使用的数据库是MySQL 8.0.23版本,所以我们需要往Docker中导入MySQL镜像,然后用命令就能创建出四个MySQL节点了。
1. 导入MySQL镜像
在课程GIT中你找到MySQL.tar.gz镜像文件,然后把这个文件上传到Linux系统,执行命令导入MySQL镜像。
docker load < MySQL.tar.gz
2. 设置虚拟机端口转发
因为四个MySQL容器的端口都是3306,所以我们要把这四个3306端口,映射到Linux系统的不同端口上(12001-12005),然后还要把Linux的这些个端口映射到Windows上面(12001-12005),我们才能用Navicat连接到MySQL容器。
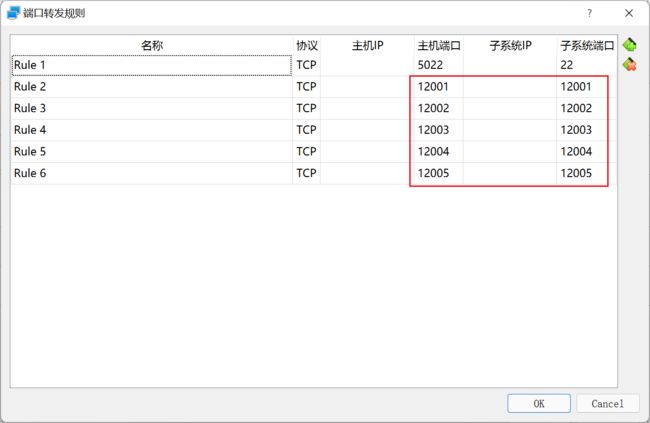
设置好端口转发,是立即生效的,你不需要重启虚拟机和CentOS系统。
3. 创建五个MySQL节点
为了给Docker中的容器分配固定的Docker内网IP地址,而且还跟其他现存的Docker容器IP不冲突,所以我们新创建一个Docker内网的网段。网络名字叫做mynet,网段是172.18.0.X,以后我们创建的容器都分配这个网段的IP。需要注意,172.18.0.1是网关的IP,我们不能用。
docker network create --subnet=172.18.0.0/18 mynet
docker run命令是创建容器的,配合上相应的参数,MySQL容器就能创建出来了。
创建第1个MySQL节点。
docker run -it -d --name mysql_1 -p 12001:3306 \
--net mynet --ip 172.18.0.2 \
-m 400m -v /root/mysql_1/data:/var/lib/mysql \
-v /root/mysql_1/config:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=abc123456 \
-e TZ=Asia/Shanghai --privileged=true \
mysql:8.0.23 \
--lower_case_table_names=1
创建第2个MySQL节点。
docker run -it -d --name mysql_2 -p 12002:3306 \
--net mynet --ip 172.18.0.3 \
-m 400m -v /root/mysql_2/data:/var/lib/mysql \
-v /root/mysql_2/config:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=abc123456 \
-e TZ=Asia/Shanghai --privileged=true \
mysql:8.0.23 \
--lower_case_table_names=1
创建第3个MySQL节点。
docker run -it -d --name mysql_3 -p 12003:3306 \
--net mynet --ip 172.18.0.4 \
-m 400m -v /root/mysql_3/data:/var/lib/mysql \
-v /root/mysql_3/config:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=abc123456 \
-e TZ=Asia/Shanghai --privileged=true \
mysql:8.0.23 \
--lower_case_table_names=1
创建第4个MySQL节点。
docker run -it -d --name mysql_4 -p 12004:3306 \
--net mynet --ip 172.18.0.5 \
-m 400m -v /root/mysql_4/data:/var/lib/mysql \
-v /root/mysql_4/config:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=abc123456 \
-e TZ=Asia/Shanghai --privileged=true \
mysql:8.0.23 \
--lower_case_table_names=1
运行docker ps -a命令看一下各个MySQL节点的运行状态,如果是Exited状态,说明该节点创建失败。

对于创建失败的MySQL节点,你运行docker rm 容器名字这个命令,把该MySQL删除,然后检查创建容器的命令是不是有错误,再重新创建该MySQL容器。
我们要创建的第五个MySQL节点是给事务中间件用的,并不存储业务数据,所以并不算MySQL集群中的节点。
docker run -it -d --name mysql_5 -p 12005:3306 \
--net mynet --ip 172.18.0.6 \
-m 400m -v /root/mysql_5/data:/var/lib/mysql \
-v /root/mysql_5/config:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=abc123456 \
-e TZ=Asia/Shanghai --privileged=true \
mysql:8.0.23 \
--lower_case_table_names=1
4. 导入数据文件
每个MySQL节点都需要执行对应的SQL文件,导入逻辑库和数据表。这些SQL文件放在课程的GIT上面了,你用Navicat去执行这些SQL文件。

注意第一个MySQL节点,要执行mysql_1.sql文件,然后以此类推,大家不要执行错了。
5. 注意事项
你每次启动虚拟机之后,都要启动Docker服务,然后把Docker中这些已经创建的容器运行起来。比如MySQL容器只要启动了,里面的MySQL就运行了。但是有的容器启动之后,我们还要进入到容器运行相应的脚本才可以,所以你要注意,不是把所有容器都启动了就是万事大吉。
比如启动MySQL容器可以执行下面的命令,每启动一个MySQL容器,等待10秒钟,再启动下一个MySQL,否则同事启动多个MySQL,容器容易崩溃。
docker start mysql_1
二、MySQL集群基础概念
1. 数据的切分
搭建MySQL集群之前要给大家普及一下MySQL集群的相关概念。虽然我在慕课网上讲了若干数据库的课程,但是毕竟有很多新同学,所以有些概念还是要说一下的。
MySQL单表数据超过两千万,CRUD性能就会急速下降,所以我们需要把同一张表的数据切分到不同的MySQL节点中。这需要引入MySQL中间件,其实就是个SQL路由器而已。这种集群中间件有很多,比如MyCat、ProxySQL、ShardingSphere等等。因为MyCat弃管了,所以我选择了ShardingSphere,功能不输给MyCat,而且还是Apache负责维护的,国内也有很多项目组在用这个产品,手册资料相对齐全,所以相对来说是个主流的中间件。

我们在MySQL_1和MySQL_2两个节点上分别创建订单表,然后在ShardingSphere做好设置。如果INSERT语句主键值对2求模余0,这个INSERT语句就路由给MySQL_1节点;如果余数是1,INSERT语句就被路由给MyQL_2执行。你看,通过控制SQL语句的转发就能把订单数据切分到不同的MySQL节点上了。将来查询的数据的时候,ShardingSphere把SELECT语句发送给每个MySQL节点执行,然后ShardingSphere把得到的数据做汇总返回给Navicat就行了。我们在Navicat上面执行CRUD操作,几乎跟操作单节点MySQL差不多,但是这背后确实通过路由SQL语句来实现的。
你可能要问,即便海量数据可以切分到不同的MySQL节点,但是日积月累,每个MySQL里面的数据还是会超过两千万的,那该怎么办?这个也简单,做数据归档就好了。对于1年以上的业务数据,可以看做是过期的冷数据。我们可以把这部分数据转移到归档库里面,例如ToKuDB、MongoDB或者HBase里面。这样MySQL节点就实现缩表了,性能也就上去了。比方说你在银行APP上面只能插到12个月以内的流水账单,再早的账单是查不到的。这就是银行做了冷数据归档操作,只有银行内部少数人可以查阅这些过期的冷数据。
2. 数据同步
数据切分虽然能应对大量业务数据的存储,但是MySQL_1和MySQL_2节点数据是不同的,而且还没有备用的冗余节点,一旦宕机就会严重影响线上业务。接下来我们要考虑怎么给MySQL节点设置冗余节点。
MySQL自带了Master-Slave数据同步模式,也被称作主从同步模式。例如MySQL_A节点开启了binlog日志文件之后,MySQL_A上面执行SQL语句都会被记录在binlog日志里面。MySQL_B节点通过订阅MySQL_A的binlog文件,能实时下载到这个日志文件,然后在MySQL_B节点上运行这些SQL语句,于是就保证了自己的数据和MySQL_A节点一致。

MySQL_A被称作Master(主节点),MySQL_B被称作Slave(从节点)。需要注意,主从同步模式里面,数据同步是单项的,如果你在MySQL_A上写入数据,可以同步到MySQL_B上面;如果在MySQL_B上面写入数据,是不能同步到MySQL_A节点的。于是我们要配置双向主从同步,也就是互为主从节点。

MySQL_A订阅MySQL_B的日志文件,MySQL_B订阅MySQL_A的日志文件,这样无论我们在哪个节点上写入数据,另一个节点就会自动同步到了。
3. 读写分离
绝大多数Web系统都是读多写少的,比如电商网站,我们都是要货比三家,然后再下单购买。所以搭建MySQL集群的时候,就要划定某些节点是读节点,某些节点是写节点。

我规划的是MySQL_1为写节点,MySQL_2和MySQL_3是读节点。多配制一些读节点也没问题,毕竟系统的读任务比较多。但是主从同步有个问题就是Master和Slave身份是固定,如果MySQL_1宕机,MySQL_2和MySQL_3都不能升级成写节点。那怎么办呢,给MySQL_1加上双向同步的MySQL_4节点。
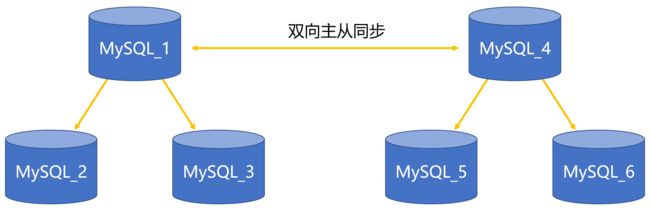
ShardingSphere会轮询的方式给MySQL_1和MySQL_4发送写操作的SQL语句(INSERT、DELETE、UPDATE等);如果是查询语句,ShardingSphere会发给其余四个读节点去执行,这就实现了读写分离。假设MySQL_1宕机,ShardingSphere通过心跳检测能知道,于是所有的写操作就转发给MySQL_4。反之如果MySQL_4宕机,MySQL_1也会接替工作。在上面示意图中的6个MySQL节点,无论哪一个宕机都不影响数据库整体的使用,都有各自的冗余节点。
4. 数据库分片
上面的6个MySQL节点并不是最终的MySQL集群方案,因为无论我在MySQL_1或者MySQL_4写入数据,最终都会同步给其他的节点,也就是说数据不能实现切分。于是我们要引入数据库分片概念,分片内部数据可以做读写分了和主从同步,但是分片之间数据是不能同步的。

如上图,前6个节点组成了第一个MySQL分片,后6个MySQL节点组成了另一个MySQL分片,两个分片之间没有任何的数据同步。这时候ShardingSphere把各种SQL语句路由给相应的MySQL分片,数据就实现了切分。
这么看来,我们想要搭建一个最普通的MySQL集群,至少需要12个MySQL节点,但是我们的虚拟机又没有那么大的内存,而且我们是开发环境,没必要配置冗余节点。负载不高,我们也不需要配置读写分离,所以我们只保留数据切分就够了。

例如分片A中我只保留了一个MySQL节点,其余五个节点都不需要。分片A和分片B切分的是某些数据表,比如司机表和钱包表的数据等等,分片C和分片D切分其他一些数据表的记录。
你可能要问,既然切分数据,用分片A和分片B就够了,把所有的数据表都弄到这两个分片上不行吗?这么做也是可以的。但是为了降低负载A和B分片的负载,我把订单相关的数据表放在了C和D分片上面。等将来我们正式部署项目的时候,四个分片一共需要24个MySQL节点,现阶段我们用四个MySQL节点就够了。
三、配置ShardingSphere
ShardingSphere是开源免费的数据库集群中间件,自带了各种切分数据的算法和雪花主键生成算法,甚至我们自己也可以写代码订制新的算法,相对来说比MyCat扩展性更强。更多介绍,大家可以去官网自己查阅。

我这里使用的是ShardingSphere 5.0版本,属于最新的版本。5.0版本的配置文件和4.0版本有很大的区别,所以大家百度的时候尽量看清楚ShardingSphere的版本号,目前百度上大多数帖子讲ShardingSphere配置,都是基于4.0版本的。
1. 设置端口转发
ShardingSphere默认使用3307端口,稍后我会把容器的3307端口映射到Linux的3307端口上,现在我们要把Linux的3307端口映射到Windows的3307端口上。

这里并不强制要求一定映射到Windows的3307端口,你也可以映射到其他端口。
2. 导入JDK镜像
因为ShardingSphere是基于Java技术的中间件,所以我们需要先导入JDK镜像,然后创建容器,再放入ShardingSphere程序。你先到GIT上找到jdk.tar.gz这个镜像文件,然后上传到Linux系统。
docker load < jdk.tar.gz
3. 创建容器
我们导入的JDK镜像里面包含的JDK版本是15.0.2的,然后我们用这个镜像创建Java容器。
docker run -it -d --name ss -p 3307:3307 \
--net mynet --ip 172.18.0.7 \
-m 800m -v /root/ss:/root/ss \
-e TZ=Asia/Shanghai --privileged=true \
jdk bash
4. 运行ShardingSphere
CentOS系统的/root/ss目录是让我们放入ShardingSphere程序的,所以你在GIT上找到ShardingSphere.zip文件,然后必须上传到该目录之下。接下来我们要解压缩ZIP文件,那就需要安装UNZIP命令。
yum install unzip -y
先解压缩ZIP文件,然后进入到bin目录,给bin目录中的脚本文件赋权限。
#解压缩文件
unzip ShardingSphere.zip
#进入bin目录
cd ShardingSphere/bin
#给脚本文件赋权限
chmod -R 777 ./*
#进入容器
docker exec -it ss bash
#进入bin目录
cd /root/ss/ShardingSphere/bin
#启动ShardingSphere
./start.sh
等待10秒钟,然后进入到ShardingSphere的logs目录,看一下stdout.log文件的内容。如果只有这些警告信息,说明ShardingSphere启动成功了。

等你重新启动虚拟机的时候,要把ss容器启动,然后进入到容器运行这个start.sh脚本才可以。不是只把ss容器运行就可以了,切记!!!
#运行ss容器
docker start ss
#进入ss容器
docker exec -it ss bash
#进入bin目录
cd /root/ss/ShardingSphere/bin
#运行脚本
./start.sh
然后观察stdout.log日志的输出内容,检查ShardingSphere是否启动成功。
5. 连接ShardingSphere
我在ShardingSphere的config/server.yaml文件中设置了远程连接的用户名和密码,你也可以修改成其他的,但是必须要重启ShardingSphere才可以。

在Navicat上面填写好连接信息,然后测试一下。

2.7安装NoSQL数据库
一、安装MongoDB
在本项目中,MongoDB是用来存储系统消息的。在Docker中安装MongoDB步骤稍微有点多,大家注意一下。
1. 导入镜像文件
你在GIT上找到MongoDB.tar.gz的镜像文件,然后把它导入Docker里面。
docker load < MongoDB.tar.gz
2. 创建容器
创建/root/mongo/mongod.conf文件,然后在文件中添加如下内容:
net:
port: 27017
bindIp: "0.0.0.0"
storage:
dbPath: "/data/db"
security:
authorization: enabled
创建MongoDB容器,端口是27017,分配400M内存
docker run -it -d --name mongo \
-p 27017:27017 \
--net mynet --ip 172.18.0.8 \
-v /root/mongo:/etc/mongo \
-v /root/mongo/data/db:/data/db \
-m 200m --privileged=true \
-e MONGO_INITDB_ROOT_USERNAME=root \
-e MONGO_INITDB_ROOT_PASSWORD=abc123456 \
-e TZ=Asia/Shanghai \
docker.io/mongo --config /etc/mongo/mongod.conf
3. 开放端口【一手资源+V: itspcool】
我们在虚拟机上,把Linux的27017端口映射到Windows的27017端口上面。

如果你Windows上安装了MongoDB,那么这个映射端口你可以改成别的。
4. 连接MongoDB【一手资源+V: itspcool】
在Navicat上面创建MongoDB连接,然后按照下面的配置去设置一下。
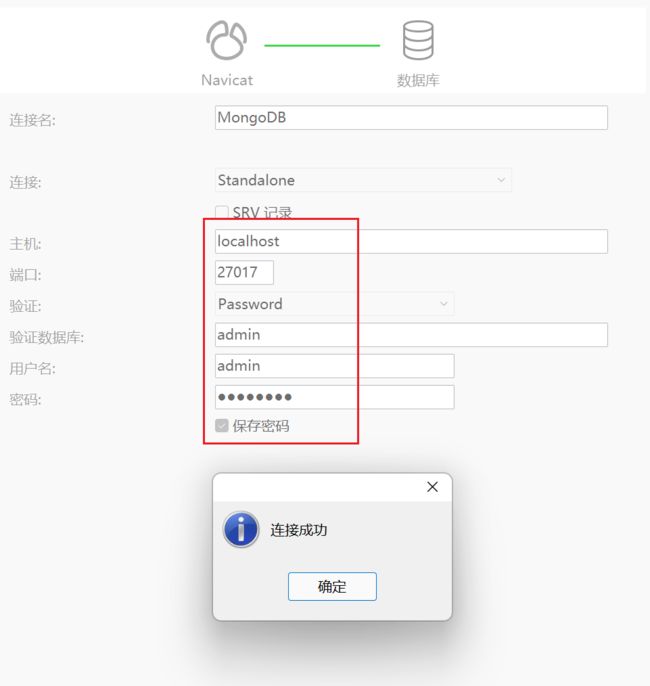
如果你将来重启了虚拟机,只需要重新启动MongoDB容器就可以了,不需要进入到MongoDB容器。
docker start mongo
二、安装Redis
本课程用Redis缓存Token令牌、司机和乘客的GPS定位等等,所以我们要把Redis容器创建出来。
1. 导入镜像文件
你在课程GIT上面找到Redis.tar.gz镜像文件,然后上传到Linux系统,我们用命令把镜像导入。
docker load < Redis.tar.gz
2. 创建容器
创建/root/redis/conf/redis.conf文件,然后添加如下内容:
bind 0.0.0.0
protected-mode yes
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 0
loglevel notice
logfile ""
databases 12
save ""
#save 900 1
#save 300 10
#save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
appendonly yes
appendfilename "appendonly.aof"
appendfsync always执行命令,创建Redis容器,分配200M内存。
docker run -it -d --name redis -m 200m \
-p 6379:6379 --privileged=true \
--net mynet --ip 172.18.0.9 \
-v /root/redis/conf:/usr/local/etc/redis \
-e TZ=Asia/Shanghai redis:6.0.10 \
redis-server /usr/local/etc/redis/redis.conf
3. 开放端口
我们要在把Linux的6379端口映射到Windows的6379端口,所以大家要在虚拟机上设置一下。

下次你重启虚拟机之后,也是正常运行Redis容器就可以,不需要进入到容器。
docker start redis
2.8安装Minio私有云存储
一、为什么要使用两种对象存储服务?
本课程一共用上了两种私有云存储:腾讯云对象存储服务、Minio对象存储服务。这两种对象存储服务都可以用来存储文件。那么为什么不只用其中的一种呢?毕竟腾讯云的对象存储服务是需要我们掏钱的,用Minio不能替代腾讯的对象存储服务吗?
其实完全可以只用Minio对象存储服务的。但是为了加强网络传输文件的安全性,需要给Minio配置HTTPS,这就需要用到数字证书和域名。我们本地电脑没有静态IP,所以就没办法绑定域名,从而无法设置数字证书开启HTTPS。如果司机在小程序上做实名认证的时候,上传的身份证和驾驶证照片通过HTTP协议传输,你觉得安全吗?好在腾讯云对象存储服务默认开启了HTTPS,所以我们把身份证和驾驶证的照片存储在腾讯云上面就很安全了。

在本课程中,我要用Minio存储代驾过程中的录音文件,这些文件体积比图片大,所以存储在腾讯云上面开销挺大,不划算,所以我们还是存储在本地的Minio上面吧。
也许有人想要问,我在硬盘上创建一个文件夹,然后让Java项目把接收到的代驾录音文件保存到这个文件夹里面不就行了么?干嘛还要费事安装Minio呢?
Minio是给本地硬盘的文件添加了网络代理,我们可以通过网络远程读写这些文件。比如部署在其他服务器的项目,就可以通过HTTP或者HTTPS协议访问到你这台主机上面的文件,这不是挺方便的么。
Minio的Web管理界面功能还是挺强大的,监控功能做的也很到位,作为一个免费的私有云存储,用在我们的代驾项目上绰绰有余。
二、安装Minio程序
1. 导入镜像文件
你在课程的GIT上面找到Minio.tar.gz镜像文件,然后用命令导入Docker环境。
docker load < Minio.tar.gz
2. 创建容器
我们首先创建/root/minio/data文件夹,然后给这个文件夹设置权限,否则Minio将无法使用该文件夹保存文件。
chmod -R 777 /root/minio/data
接下来我们创建容器,运行Minio程序。
docker run -it -d --name minio \
-p 9000:9000 -p 9001:9001 \
-v /root/minio/data:/data \
-e TZ=Asia/Shanghai --privileged=true \
--env MINIO_ROOT_USER="root" \
--env MINIO_ROOT_PASSWORD="abc123456" \
--env MINIO_SKIP_CLIENT="yes" \
bitnami/minio:latest3. 开放端口
我们需要把Linux系统的9000和9001端口,映射到Windows系统的9000和9001端口上。

我们打开浏览器,访问http://127.0.0.1:9001/login,然后填写好登陆信息,就能进入Web管理画面。

在管理画面中,我们可以创建存储桶,然后就能上传文件了。
我们将来重启虚拟机之后,也是正常运行minio容器就行了。
docker start minio
2.9安装其余中间件
一、安装RabbitMQ
本课程用RabbitMQ缓存系统发出的通知消息,每个用户都有自己的消息队列,而且我们还可以设置消息队列缓存消息的过期时间。这么做就比把消息直接存储到数据库更好。毕竟有很多用户长期不登录,那么他的消息队列缓存的消息过期也就自动销毁了,可以节省很多存储空间。

为什么不使用Kafka,而选用RabbitMQ呢?
因为RabbitMQ和Kafka的读写速度都很快,相差不大,但是RabbitMQ的收发消息更为灵活,支持同步和异步两种收发模式。而且RabbitMQ支持复杂的路由规则,我们可以灵活配置一个消息的广播模式,所以能适配更多的业务场景。你只有多使用RabbitMQ才能体会到它的各种优点。
1. 导入镜像
在课程GIT上面找到RabbitMQ.tar.gz文件,然后导入Docker里面。
docker load < RabbitMQ.tar.gz
2. 创建容器
docker run -it -d --name mq \
--net mynet --ip 172.18.0.11 \
-p 5672:5672 -m 500m \
-e TZ=Asia/Shanghai --privileged=true \
rabbitmq
3. 开放端口
我们需要把Linux的5672端口,映射到Windows系统的5672端口。
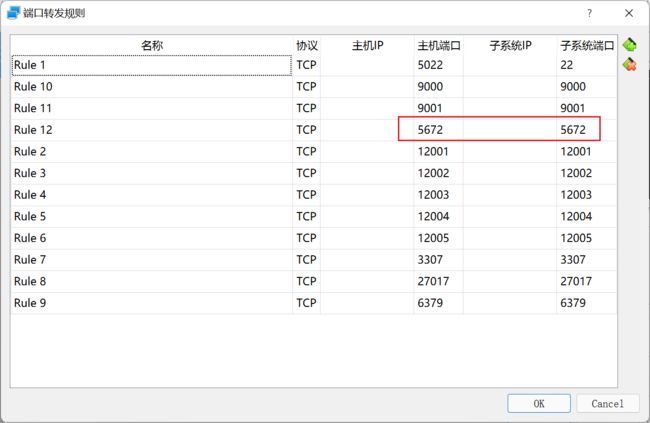
等你重启虚拟机之后,重新运行RabbitMQ容器就行了。
docker start mq
二、安装Nacos
本课程采用了Alibaba SpringCloud微服务架构,所以需要用Nacos作为注册中心。Nacos的作用类似Zookeeper,只不过微服务更加依赖于Nacos服务。
1. 导入镜像
你在GIT上面找到Nacos.tar.gz镜像文件,把它导入Docker之中。
docker load < Nacos.tar.gz
2. 创建容器
docker run -it -d -p 8848:8848 --env MODE=standalone \
--net mynet --ip 172.18.0.12 -e TZ=Asia/Shanghai \
--name nacos nacos/nacos-server
3. 开放端口
我们需要把Linux的8848端口,映射到Windows的8848端口上面。

打开浏览器访问http://localhost:8848/nacos/,在登陆画面填写默认帐户信息:用户名和密码都是nacos

在Web管理页面中,我们能看到Nacos的各项设置信息。
将来你重启虚拟机之后,重新运行nacos容器就可以。
docker start nacos
4. 设置内网穿透(仅限使用云主机的同学)
因为Nacos要发送心跳检测个微服务子系统,如果你的Nacos安装在了云端,因为你本地电脑没有公网IP,所以Nacos的心跳检测你就接收不到,导致子系统无法启动成功,遇到这种情况。我们要给本地电脑设置内网穿透才行。
推荐大家使用量子互联内网穿透软件,支持Windows、Linux和MacOS系统。虽然收费,但是并不贵,也不限制流量,比花生壳好多了。建议大家选购VIP3套餐,可以映射18个端口,足够学习本课程了。

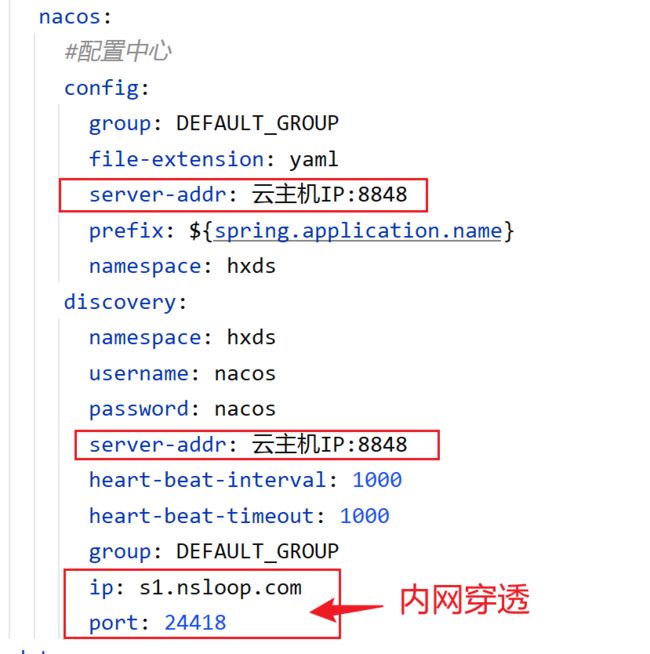
但凡用到Nacos的微服务子系统,这个子系统的端口号就必须做内网穿透。比如我把本地电脑的8001端口用内网穿透映射到外网某个URL和端口上面。
![]()
除了hxds-tm和common子系统的application-common.yml文件不需要修改之外,每个子系统的application.yml文件必须改成bootstrap.yml。在每个子系统的YML文件中,只要有Nacos的配置,你都要补上下面的配置。
三、安装Sentinel
在微服务体系中,我们需要用到Sentinel做限流。 Sentinel会监控应用的QPS或并发线程数等指标,当达到指定阈值时对流量进行控制,避免系统被瞬时的流量高峰冲垮,保障应用高可用性。
1. 导入镜像
在GIT上面找到Sentinel.tar.gz镜像文件,然后导入Docker里面。
docker load < Sentinel.tar.gz
2. 创建容器
docker run -it -d --name sentinel \
-p 8719:8719 -p 8858:8858 \
--net mynet --ip 172.18.0.13 \
-e TZ=Asia/Shanghai -m 600m \
bladex/sentinel-dashboard
3. 开放端口
我们要把Linux的8719和8858端口,映射到Windows的8719和8858端口上面。

打开浏览器访问http://localhost:8858/#/login,然后填写登陆帐户,用户名和密码都是sentinel

在Web管理画面我们看到Sentinel的监控信息,我们也可以设置某个Web微服务的阈值。当负载超过这个阈值,Sentinel就会自动限流。

等你将来重启虚拟机的时候,重新启动Sentinel容器就可以了。
docker start sentinel
二、部署HBase与Phoenix
1. 导入镜像文件
首先我们在课程共享的资源中找到phoenix.tar.gz镜像文件,然后把这个文件上传到CentOS系统中,执行命令,把镜像文件导入Docker之中。
docker load < phoenix.tar.gz
2. 创建容器
因为镜像中已经包含和HBase和Phoenix,所以我们只需要创建出容器即可。由于HBase需要使用的内存较大,这里我没有规定具体的内存大小,容器会自动使用空闲的内存。容器中数据目录是/tmp/hbase-root/hbase/data,我把这个目录映射到宿主机的/root/hbase/data目录。
docker run -it -d -p 2181:2181 -p 8765:8765 -p 15165:15165 \
-p 16000:16000 -p 16010:16010 -p 16020:16020 \
-v /root/hbase/data:/tmp/hbase-root/hbase/data \
--name phoenix --net mynet --ip 172.18.0.14 \
boostport/hbase-phoenix-all-in-one:2.0-5.0
3. 开放端口
我们要把Linux的2181、8765、15165、16000、16010、16020端口,映射到Windows的相应端口上面。

4. 初始化Phoenix
运行命令,进入到Phoenix容器中,然后执行命令设置HBASE_CONF_DIR环境变量。
docker exec -it phoenix bash
export HBASE_CONF_DIR=/opt/hbase/conf/
接下来我们要连接Phoenix的命令行客户端。虽然IDEA也内置了Phoenix客户端,但是Bug挺多的,用着并不方便,所以我建议大家使用Phoenix自带的命令行客户端更好一些。而且我们要执行的SQL语句也并不多,命令行客户端已经足够用了。
/opt/phoenix-server/bin/sqlline.py localhost
三、创建逻辑库和数据表
1. 创建逻辑库
为了存储数据,我们需要像操作MySQL一样,先创建逻辑库,然后定义数据表。在Phoenix的命令行客户端我们先来执行创建逻辑库的命令。
CREATE SCHEMA hxds;
USE hxds;
2. 创建数据表
接下来我们要创建order_voice_text、order_monitoring和order_gps数据表。其中order_voice_text表用于存放司乘对话内容的文字内容;
CREATE TABLE hxds.order_voice_text(
"id" BIGINT NOT NULL PRIMARY KEY,
"uuid" VARCHAR,
"order_id" BIGINT,
"record_file" VARCHAR,
"text" VARCHAR,
"label" VARCHAR,
"suggestion" VARCHAR,
"keywords" VARCHAR,
"create_time" DATE
);
CREATE SEQUENCE hxds.ovt_sequence START WITH 1 INCREMENT BY 1;
CREATE INDEX ovt_index_1 ON hxds.order_voice_text("uuid");
CREATE INDEX ovt_index_2 ON hxds.order_voice_text("order_id");
CREATE INDEX ovt_index_3 ON hxds.order_voice_text("label");
CREATE INDEX ovt_index_4 ON hxds.order_voice_text("suggestion");
CREATE INDEX ovt_index_5 ON hxds.order_voice_text("create_time");
order_monitoring表存储AI分析对话内容的安全评级结果。
CREATE TABLE hxds.order_monitoring
(
"id" BIGINT NOT NULL PRIMARY KEY,
"order_id" BIGINT,
"status" TINYINT,
"records" INTEGER,
"safety" VARCHAR,
"reviews" INTEGER,
"alarm" TINYINT,
"create_time" DATE
);
CREATE INDEX om_index_1 ON hxds.order_monitoring("order_id");
CREATE INDEX om_index_2 ON hxds.order_monitoring("status");
CREATE INDEX om_index_3 ON hxds.order_monitoring("safety");
CREATE INDEX om_index_4 ON hxds.order_monitoring("reviews");
CREATE INDEX om_index_5 ON hxds.order_monitoring("alarm");
CREATE INDEX om_index_6 ON hxds.order_monitoring("create_time");
CREATE SEQUENCE hxds.om_sequence START WITH 1 INCREMENT BY 1;
order_gps表保存的时候代驾过程中的GPS定位。
CREATE TABLE hxds.order_gps(
"id" BIGINT NOT NULL PRIMARY KEY,
"order_id" BIGINT,
"driver_id" BIGINT,
"customer_id" BIGINT,
"latitude" VARCHAR,
"longitude" VARCHAR,
"speed" VARCHAR,
"create_time" DATE
);
CREATE SEQUENCE og_sequence START WITH 1 INCREMENT BY 1;
CREATE INDEX og_index_1 ON hxds.order_gps("order_id");
CREATE INDEX og_index_2 ON hxds.order_gps("driver_id");
CREATE INDEX og_index_3 ON hxds.order_gps("customer_id");
CREATE INDEX og_index_4 ON hxds.order_gps("create_time");
四、编写hxds-nebula子系统
我们先来看一下hxds-nebula子系统的application.yml文件,里面的JDBC驱动和URL路径都是为了连接Phoenix的。如果你用的是云主机,别忘了URL要写云主机的IP,而且还要在安全组里面把相关端口开放一下。

1. 定义POJO类
既然我们要用MyBatis连接Phoenix,那么持久层的POJO类、DAO接口和XML文件都要配齐了才可以。在com.example.hxds.nebula.db.pojo包中,创建3个POJO类。
@Data
public class OrderGpsEntity {
private Long id;
private Long orderId;
private Long driverId;
private Long customerId;
private String latitude;
private String longitude;
private String speed;
private String createTime;
}
@Data
public class OrderMonitoringEntity {
private Long id;
private Long orderId;
private Byte status;
private Integer records;
private String safety;
private Integer reviews;
private Byte alarm;
private String createTime;
}
@Data
public class OrderVoiceTextEntity {
private Long id;
private String uuid;
private Long orderId;
private String recordFile;
private String text;
private String label;
private String suggestion;
private String keywords;
private String createTime;
}
2. 定义DAO接口
在com.example.hxds.nebula.db.dao包中,声明3个DAO接口。
public interface OrderGpsDao {
}
public interface OrderMonitoringDao {
}
public interface OrderVoiceTextDao {
}
3. 定义XML文件
在resources目录中创建mapper文件夹,定义3个XML文件。
4. 运行子系统
上述内容都配置完成之后,我们就可以启动hxds-nebula子系统了,如果控制台没有报错信息,说明咱们的配置都是正确的。