MEC相关论文笔记
论文名称:基于深度强化学习的车辆边缘计算调度
Deep Reinforcement Learning-Based Offloading Scheduling for Vehicular Edge Computing
前言
VEC绝对式车辆边缘计算‘(Abstract—Vehicular edge computing),是一种新型计算范例,可增强车辆终端能力,以支持低延迟和高能效的资源匮乏的车载应用。
本文研究了在典型的VEC场景中的泡沫调度问题的重要计算,在这种情况下,沿着高速公路行驶的VT打算调度其在队列中等待的任务,以最大程度地减少任务之间的权衡成本延迟和能源消耗。
由于任务特征多样,动态无线环境以及车辆移动引起的频繁移交事件,最佳解决方案应同时考虑在哪里安排以及何时安排每个任务。这种复杂的随机优化问题,我们通过精心设计的**马尔可夫决策过程(MDP)对其进行建模,并借助深度强化学习(DRL)**来处理巨大的状态空间。
本文的DRL实现是基于最新的近端策略优化(PPO)算法设计的。结合卷积神经网络(CNN)的参数共享网络体系结构用于近似策略和价值函数,可以有效地提取代表性特征。对状态和奖励表示进行了一系列调整,以进一步提高培训效率。广泛的仿真实验和与六种已知基线算法的全面比较及其启发式组合清楚地证明了所提出的基于DRL的泡沫调度方法的优势。
一、引言
车载应用的特点:计算量大,带宽消耗和/或等待时间敏感。
通过将这些资源需求任务分散到路边单元(RSU)中附加的MEC服务器,可以显着减少车载应用程序的执行延迟和能耗。同时,可以节省核心网络的带宽,从而降低了网络拥塞的风险。
车辆边缘计算(VEC)是移动边缘计算(MEC)在车辆场景中的应用。发泡任务是MEC / VEC技术的关键功能。由于数据传输和远程任务执行所引起的额外能量和时间消耗,将计算任务充斥到边缘服务器可能并不总是带来好处。一项关键的技术挑战是在制定泡沫决策时平衡计算和通信的总体成本。
马尔可夫决策过程(MDP)是一种有效的数学工具,可在动态环境中对用户行为的影响进行建模,并允许寻求最佳的起泡沫决策以实现特定的长期目标。应该构造一个描述系统动力学的状态转移概率矩阵(即,导致状态转移的用户动作的概率),然后可以通过值迭代或策略迭代来得出最优的起泡策略。
深度强化学习(DRL)被设想为解决复杂的顺序决策问题的有前途的解决方案。DRL特别适用于解决动态环境中发泡的MEC / VEC问题。首先,DRL可以针对长期起泡性能进行优化。这将胜过在静态环境中提出的方法的“一次性”和贪婪的应用,这可能会导致严格的次优结果。其次,通过DRL,无需与系统动力学相关的任何先验知识(例如,无线信道或任务到达特性),就可以通过直接与环境交互来学习最佳的泛洪策略。这样就避免了使用传统解决方案求解MDP时需要的状态转移矩阵。第三,DRL可以充分利用深度神经网络(DNN)强大的表示能力。即使在状态和动作空间很大的复杂问题中,最佳的起泡策略也可以适当地近似。
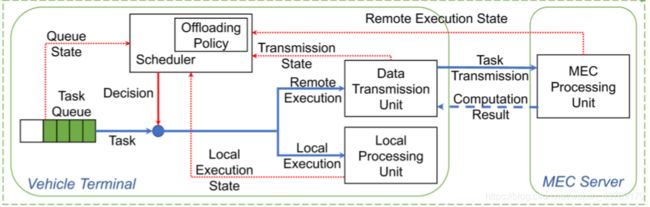
该论文研究了在典型的VEC场景中泡沫调度问题的计算。沿着高速公路行驶的VT(车辆终端)决定如何调度在其任务队列中等待的任务,如图1所示。任务是由不同的任务独立生成的应用程序,以使其具有不同的特征(关于数据大小和CVR)。
 RSU中配备的MEC服务器可用于进行VT的计算。无线车辆通信环境是复杂的。衰落统计可能是未知的,并且瞬时信道知识仅是因果可用的。由于VT的移动性,定期从一个服务RSU切换到另一个RSU。这些问题导致动态更改数据传输时间/能耗,甚至发生传输故障。因此,良好的调度策略不仅应决定在哪里调度每个任务(即,在VT中本地执行任务,还是在MEC服务器上远程执行),还应决定何时调度(即,每个任务的调度顺序和时间) )。由于复杂的环境动力学和广阔的状态空间,传统解决方案非常涉及此问题。为了应对这些挑战,我们设计了一种新颖的基于DRL的发泡调度方法,该方法可以最大程度地减少长期成本,而长期成本是在任务执行延迟和能耗之间进行权衡取舍的。主要贡献概述如下:
RSU中配备的MEC服务器可用于进行VT的计算。无线车辆通信环境是复杂的。衰落统计可能是未知的,并且瞬时信道知识仅是因果可用的。由于VT的移动性,定期从一个服务RSU切换到另一个RSU。这些问题导致动态更改数据传输时间/能耗,甚至发生传输故障。因此,良好的调度策略不仅应决定在哪里调度每个任务(即,在VT中本地执行任务,还是在MEC服务器上远程执行),还应决定何时调度(即,每个任务的调度顺序和时间) )。由于复杂的环境动力学和广阔的状态空间,传统解决方案非常涉及此问题。为了应对这些挑战,我们设计了一种新颖的基于DRL的发泡调度方法,该方法可以最大程度地减少长期成本,而长期成本是在任务执行延迟和能耗之间进行权衡取舍的。主要贡献概述如下:
- 我们通过精心设计的MDP对洪水调度过程进行建模,其中考虑了任务特征,无线传输和队列动态以及VT移动性的影响。 考虑到MDP本质上是无模型的,并且具有巨大的状态和动作空间,我们建议应用DRL来找到最佳策略。
- 应用了一系列方法来提高训练效率和收敛性能。 首先,我们设计基于近端策略优化(PPO)算法的训练方法,该方法是具有出色稳定性和可靠性的最新策略梯度方法[18]。 另外,为了更好地提取任务队列的代表性特征,在DNN体系结构中嵌入了卷积神经网络(CNN),用于近似泛洪调度策略和价值函数。 最后,通过有意地调整状态和奖励表示,可以避免在训练过程中进行大量的无效率的探索尝试,以进一步提高训练效率。
- 进行了广泛的仿真实验,以将所提出的基于DRL的泡沫调度方法与六种已知的基线算法及其启发式组合进行比较。 结果表明,我们的方法始终可以实现最低的长期成本。 明确展示了应用DRL解决VEC中复杂决策问题的潜力
第二部分介绍了系统模型。 在第三部分中,我们简要介绍了DRL的背景。 第四节将泛洪调度问题的计算公式化为MDP。 第五节详细介绍了DRL的实现和训练方法。第六节提供了仿真结果和讨论。 最后,第七节总结了本文
二、系统模型
均值为零且方差为σ2的复数高斯分布。
![]()
指标函数,如果满足条件Φ,则等于1,否则等于0。
![]()
A、系统架构
VEC [2]的典型应用场景,如图1所示。VT沿着高速公路行驶,由沿路边部署的RSU服务。相邻RSU之间的距离为L米,并且不同RSU的覆盖区域不重叠。因此,根据RSU的覆盖范围将道路划分为多个部分。一辆VT只能由一个RSU通过车辆到基础设施(V2I)通信来服务。当它驶过两个路段的边界时,就会发生切换。每个RSU配备有MEC服务器,其充当VT的邻近云,即,可以为每个VT保留一定量的计算资源以进行任务计算。位于网络后端的备份服务器通过有线连接连接到所有MEC服务器,并且可以在每个MEC服务器的计算资源不足时增强其功能。 MEC服务器可以通过核心网络相互通信。然而,为了避免降低核心网络的条件,通常不允许RSU之间传输原始的车载应用程序数据(例如,用于任务填充的输入数据),该数据通常较大。
从VT的角度来看,这项工作的重点是确定一种起步调度策略,该策略可以以最小的成本有效地完成车载应用程序计算任务的执行。在下文中,我们的分析集中于一个单一的代表性VT。(在本文中,假定为每个VT保留了一定量的MEC计算资源和V2I传输带宽。 在多个VT之间动态优化有限的计算和通信资源的分配是一个更具挑战性的问题,这是我们未来的研究主题之一。)VT与它的服务MEC服务器之间关于泡沫计算的交互如图1的底部所示。我们考虑VT中的抽象计算体系结构,它由一个任务队列组成,任务调度器,本地处理单元(LPU)和数据传输单元(DTU)(我们的工作重点是确定适当的洪流调度策略,以在复杂的车辆通信和计算环境中平衡本地和远程执行。 采用具有单个中央单元的计算架构)。可能由多种类型的应用程序生成的独立计算任务随机到达任务队列(按其生成时间排序)。任务计划程序综合所有可用的系统信息(包括队列状态,本地执行状态,传输状态和远程执行状态),并根据持续的调度策略来计划任务。根据计划的执行时间,分配给本地执行的任务在LPU上处理。对于远程执行,首先通过DTU将任务传输到服务的RSU。之后,RSU上的MEC服务器使用保留的计算资源执行任务,然后将计算结果发送回VT。
B 任务队列模型
我们将系统的工作负载建模为泊松过程,其速率为λ,表示每个时隙中到达VT的任务队列的预期计算任务数。 第i个(i∈N +)到达任务Ji被描述为一个三元组
![]()
在(1)中,tg i是生成Ji的时间,di(以位为单位)是任务输入数据的大小,而ki(以CPU周期/位为单位)是其CVR(计算体积比),可以通过应用程序配置文件来获得 。 队列中等待的所有任务都被认为是由计算密集型的车载应用程序生成的(例如,对象识别或病毒扫描)。 通常,与输入(例如图片或文件)相比,此类任务(例如对象标签或病毒报告)的计算结果具有足够小的数据大小[3]。 因此,在本文中,所有任务的输出数据的大小和传输时间都可以忽略不计。
我们考虑的任务没有严格的延迟要求或执行优先级。它们按照其生成时间在队列中排序。换句话说,当新任务到达时,它将被附加到任务队列的后端。如果调度程序将队列中的任何任务发送到LPU或DTU,则将其移至后面的任务以填补空位置。我们使用Q表示队列可以容纳的最大任务数,并使用q [t](q [t]≤Q)表示在时间段t队列中的实际任务数。如果q [t] = Q,则必须丢弃新的传入任务,并发生溢出事件。现在,可以用Q×3矩阵Q [t]表示在任意时隙t的任务队列的状态,其中第j(j∈{1,2,···,q [t]})行是由第j个等待任务的三个定义元素(用Q [t]⟨j⟩表示)组成,分别是任务生成时间,输入数据大小和CVR。 Q [t]中其余的Q-q [t]行中的每一行都是1×3全零向量,表示在该队列位置没有等待任务。
请注意,我们可以使用两种表示法来引用任务。 第一个反映自然任务生成过程。 例如,(1)中的Ji表示由车载应用程序生成的第i个任务,并且索引i可以是任何正整数。 第二种表示法反映任务队列的实时状态。 例如,Q [t]⟨j⟩是在特定时隙t在队列中等待的第j个(排序的)任务,并且整数索引j由Q上限。前一种表示法唯一地区分了不同的任务。 但是后者可以更好地帮助描述所考虑系统的动态性质。 为了便于演示,我们使用了与(1)类似的方法来描述任务Q [t]⟨j⟩:
![]()
C沟通模式
无线V2I通信(用于填充任务)是在块衰落环境中进行的。衰落系数在每个信道相干时间间隔内保持不变,该时间间隔可以是一个或多个时隙,但此后随机变化(不一定独立)。我们假设VT和它的服务RSU之间的信道衰落系数由它们之间的信号传播环境统计确定。例如,在瑞利衰落下,可以用h =〜hˆ h来建模复衰落系数h,其中h h〜CN(0,1)代表小规模衰落,而大衰落系数〜h反映了两种路径损耗的影响和阴影现象。通常,〜h是E,一组环境因素(例如VT x的位置,到服务RSU d的距离)以及可能其他因素的函数。由于E相对容易估算,因此知道E从而〜h在统计上将h描述为从CN(0,|〜
考虑到所使用的信道代码的能力,从VT到其服务RSU的可靠传输数据速率r是信道衰落系数的确定函数。这意味着,传输速率还由环境因素统计确定,即,它遵循条件概率密度函数(PDF)f(r | E)。出于演示目的,在本文中,我们限制集合E = {x,d}:通过VT的位置以及VT与服务RSU之间的距离来完全描述环境。对于固定的x和d,PDFf(r | E)是固定的函数,但VT或RSU都不知道。
在任何时隙t,VT都可以获得有关瞬时衰落系数h [t]的一定水平的知识,据此可以推断出数据速率r [t](以位/时隙为单位)。**如果VT打算在时隙t向RSU发送数据,那么r [t]比特数据可以被成功地传送。**因此,我们将ttx(v,t)表示为从时隙t开始将大小为v(以位为单位)的数据传输到服务RSU所花费的时间。满足
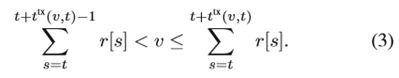
实际上,渠道知识只能是因果可用的。 VT的移动还有助于动态信道环境,在该环境中,信道增益会快速变化。 很难预测将来时隙的确切可达到的传输速率。 因此,只有在数据传输实际完成时才能知道ttx(v,t)的值。 因此,良好的调度计划策略应按顺序进行调度决策,而不是执行“一次性”解决方案。
VT的移动和动态无线信道环境引起的另一个问题是由于切换导致的传输失败。 如前所述,为避免降低核心网络的条件,不允许在RSU之间传输原始的车载应用程序数据。 当VT离开RSU的覆盖区域时,如果尚未完成任务的输入数据传输,则先前传输的数据无法传递到新的服务RSU,必须丢弃。 该任务必须由VT重新传输,以浪费能源和较大延迟为代价。 相反,由于计算输出数据的大小可忽略不计,如果在切换之前任务输入数据传输已完成,则可将计算结果从先前的服务RSU传递到新的RSU。
D计算模型
期望队列中的任务及时有效地执行,即等待时间和能量消耗小。 较大的延迟会降低车载应用程序的实用性和用户体验。 高能耗会很快耗尽VT的电池。 它们都可以视为任务执行的成本。 在LPU本地或在MEC服务器上进行远程计算每个任务所需的时间和精力如下所示。
1)本地执行模型:假定调度程序确定将任务Ji调度到时隙ta i的本地执行。 然后,从i开始,Ji的所有CPU周期(即diki)将在LPU上执行。 完成接口板上的Ji所需的时隙数为。其中,fl(周期/时隙)是接口板的CPU频率

根据[20]和[21],可以通过CPU频率的超线性函数将平均功耗pl(以焦耳/槽为单位)建模为pl =ξ(fl)ν,其中ξ和ν都是常数。 因此,可以通过以下方式获得本地执行Ji所消耗的能量:
![]()
2)远程执行模型:如果计划在任务ta i上执行任务Ji的任务,则DTU在任务ta i上开始将任务传递到服务RSU。 成功接收所有输入数据后,MEC服务器将为VT远程执行任务。 总时间消耗包括两部分:无线数据传输时间和MEC服务器上任务计算时间。 前者与计划的开始时间ta i有关,因为每个时隙的传输数据速率取决于VT的位置,如第II-C节所述。 可以根据(3)得出通过V2I通信完成对di比特数据的传送的时隙数为
![]()
另外,可以通过以下方式计算在MEC服务器上执行Ji所需的时隙数:

其中fs是服务提供商为VT保留的CPU频率。 因此,可以通过以下方法获得用于消耗Ji的总时隙:
![]()
从VT的角度来看,远程执行任务不会消耗精力。 注入Ji的能量消耗仅用于数据传输,由下式给出:
其中ptx(以焦耳/槽为单位)是VT的传输功率
![]()
E、目的
当VT沿着高速公路行驶时,调度程序会连续确定“在哪里”和“何时”执行在其队列中等待的任务。 对于每个任务Ji,前者指的是应在LPU上本地计算(由二进制指示符ai = 0表示)还是将其扩展到MEC服务器以进行远程执行(由ai = 1表示)。 后者是指本地计算或发泡操作的开始时间(用整数ta i表示)。
我们将任务Ji经历的等待时间定义为生成Ji的时刻(即(1)中的tg i)与完成Ji的时刻之间的总持续时间(时隙)。 因此,可以根据调度决策获得等待时间。
三、深度学习背景
DRL是增强学习(RL)的增强,其中DNN用于状态表示或函数逼近[11],[12]。 在RL问题中,代理会随着时间与环境交互。 在每个时间步长n,代理都会在状态空间S中观察环境状态sn,并遵循策略π(an | sn)从动作空间A中选择一个动作an,这是观察状态时采取actionan的概率 锡 然后,环境根据环境动力学P(sn + 1 | sn,an)和奖励函数R(sn,an,sn)转换到下一个状态sn + 1∈S并向主体发出奖励信号rn。 +1)。 除非代理观察到终端状态(在情节性问题中),否则此过程将无限期地继续。 代理从状态sm累积的奖励定义为

其中γ∈(0,1]称为折现因子,通常用MDP表示,定义为5元组,即M =(S,A,P,R,γ)。
值函数vπ(s)=Eπ[Gm | sm = s]是从状态s开始遵循策略π的累积奖励的期望。 动作值函数qπ(s,a)=Eπ[Gm | sm = s,am = a]是在状态s下选择策略a然后遵循策略π的累积奖励的期望。 它们分别表示状态和状态-动作对的优劣,并通过vπ(s)= $a∈Aπ(a | s)qπ(s,a)连接。 RL的目的是找到最佳策略π∗,以最大化对状态空间中任何状态的累积奖励的期望,即
DRL使用DNN近似策略和/或价值函数。 借助DNN强大的表示能力,可以支持较大的状态空间。 当前的DRL方法可以分为两类:基于价值的方法和基于策略的方法。
基于值的DRL方法采用DNN近似值函数(称为值网络),例如,深度Q网络(DQN)[23]和双DQN [24]。 通常,基于价值的DRL方法的核心思想是最小化价值网络和实际价值函数之间的差异。 自然目标函数可以写成
其中v(·;θ)是值网络,θ是其参数集。 vπ∗(·)表示实值函数,该函数未知,但通过不同的基于值的RL方法估计。 期望值En [·]表示在采样和优化之间交替的算法中,有限数量的样本的经验平均值。
基于策略的DRL方法使用DNN近似参数化策略(称为策略网络),例如REINFORCE [25]和Actor-Critic [26]。 与基于值的DRL方法相比,这些方法具有更好的收敛性,并且可以学习随机策略。 基于策略的DRL方法通过计算策略梯度的估算器来工作,最常用的梯度估算器具有以下形式:
其中π是随机策略,ˆ An是时间步长n的估计函数。
传统的基于策略的DRL方法,例如REINFORCE,有两个主要缺陷:1)蒙特卡洛采样(获取Gn)带来高方差,导致学习缓慢; 2)策略更新(使用相同策略的训练和抽样)可以轻松收敛到局部最优。
最近,提出了广义利益估计(GAE)以在方差和偏差之间做出折衷[27]。 GAE估算器写为
其中φ用于调整偏差方差的权衡,以及
为了缓解局部最优问题,引入了非政策学习以提高政策梯度方法的探索能力。 OpenAI提出的PPO算法是最新技术[18]。 它的目标功能是
裁剪函数clip(rn(θ),1-ϵ,1 + ϵ)限制了rn的值,从而消除了将rn移到区间[1-ϵ,1 + ϵ]之外的动机,其中ϵ是一个超参数。 控制片段范围。 通过取削波和未削波的物镜的最小值,最终目标被限制为削波和未削波的物镜的下限。 由于这些优点,本文设计了基于PRL的基于DRL的泛洪调度方法。
总结
VEC -绝对式车辆边缘计算
VC -车辆终端
MDP-马尔可夫决策过程
DRL-深度强化学习
PPO-近端策略优化
CNN-卷积神经网络
DNN-深度神经网络
CVR-计算体积比computation-to-volume ratio
本地处理单元LPU
数据传输单元DTU
路边单元RSU–其中有MEC服务器
PRL?
- VEC:增强VT能力,支持低延迟和高能效的车载应用。
- 本文:VT打算调度在队列中等待的任务,最大程度减少任务之前的权衡成本延迟和能源消耗。
- 方案应该考虑的内容:在哪安排(本地orMEC)何时安排(任务的时间和顺序)执行、每个任务。
- 使用马尔可夫决策过程MDP进行建模,借助深度学习DRL处理巨大的状态空间。
- DRL实现基于近端策略优化PPD算法设计,结合卷积神经网络CNN的参数共享网络体系结构用于近似策略和价值函数,可有效的提取代表性特征。
任务卸载task offloading是MEC/VEC技术关键。在制定卸载offloading决策时平衡计算和通信的总体成本。由于数据传输和远程任务执行所引起的额外能量和时间消耗,将计算任务充斥到边缘服务器可能并不总是带来好处
MDP可以在动态环境对用户行为的影响进行建模,并允许寻求最佳的卸载决策以实现目标。为此赢构造一个描述系统动力学的状态转移概率矩阵(即导致状态转移的用户动作的概率)。然后通过概值迭代或策略迭代得出最佳卸载决策。但难以对系统动力学建模,难以获得转换概率矩阵,尤其是在状态空间和空间动作大时。
DRL实用于该问题,DRL可以对长期卸载性能进行优化,无需学习系统动力学先验知识,可通过直接于环境交互学习最佳的泛洪策略。充分利用DNN强大的表示能力,表达状态和动作空间,适当近似。
典型的VEC场景中任务卸载问题的计算,VT决定如何调度在其任务队列中等待的任务。任务是由不同的任务独立生成的应用程序,以使其具有不同的特征(关于数据大小和CVR)。无线车辆通信环境是复杂的。衰落统计可能是未知的,并且瞬时信道知识仅是因果可用的。由于VT的移动性,RSU的切换可能导致动态更改数据传输时间/能耗,甚至发生传输故障
基于DRL的任务卸载算法,减少长期成本(即任务执行延迟和能耗之前权衡取舍):
精心设计的MDP对洪水调度过程进行建模,其中考虑了任务特征,无线传输和队列动态以及VT移动性的影响。 提高训练效率和收敛性能:基于近端策略优化(PPO)算法的训练方法–稳定性和可靠性。DNN体系结构中嵌入了卷积神经网络(CNN):为了更好的提取任务队列的代表性特征,用于近似泛洪调度策略和价值函数。 调整状态和奖励表示,避免进行无效率的探索尝试
系统模型
系统架构:
相邻RSU之间的距离为L米,不同RSU的覆盖区域不重叠。根据RSU的覆盖范围将道路划分为多个部分。一辆VT只能由一个RSU通过车辆到基础设施(V2I)通信来服务。边界时,就会发生切换。假设:“每个RSU为每个VT保留一定量的计算资源以进行任务计算”网络后端的备份服务器通过有线连接连接到所有MEC服务器。MEC服务器可以通过核心网络相互通信。不允许RSU之间传输原始的车载应用程序数据。
从VT角度看:需要确定起步调度策略,该策略可以以最小的成本有效地完成车载应用程序计算任务的执行。后续分析集中于一个单一的代表性VT。VT中的抽象计算体系结构,它由一个任务队列组成,任务调度器,本地处理单元(LPU)和数据传输单元(DTU)。多种类型的应用程序生成的独立计算任务随机到达任务队列(按其生成时间排序)。任务计划程序综合所有可用的系统信息(包括队列状态,本地执行状态,传输状态和远程执行状态),并根据持续的调度策略来计划任务。根据计划的执行时间,分配给本地执行的任务在LPU上处理。对于远程执行,首先通过DTU将任务传输到服务的RSU。RSU上的MEC服务器使用保留的计算资源执行任务,然后将计算结果发送回VT。
任务队列
任务负载建模为泊松过程。速率为λ,表示每个时隙中到达VT的任务队列的预期计算任务数
第i个任务Ji被描述为一个三元组:t是生成Ji的时间,di是任务输入数据的大小,ki是其CVR
队列中等待的所有任务都被认为是由计算密集型的车载应用程序生成的,此类任务的计算结果具有足够小的数据大小
本文,所有任务的输出数据的大小和传输时间都可以忽略不计。
考虑的任务没有严格的延迟要求或执行优先级,按时间在队列中排序
Q表示队列可以容纳的最大任务数,并使用q [t](q [t]≤Q)表示在时间段t队列中的实际任务数
Q×3矩阵Q [t]表示在任意时隙t的任务队列的状态
两种表示法来引用任务:1.反映自然任务生成过程 2.反映任务队列的实时状态
通信
在块衰落环境中进行的。衰落系数在每个信道相干时间间隔内保持不变,但此后随机变化
假设VT和它的服务RSU之间的信道衰落系数由它们之间的信号传播环境统计确定
切换时,若VT已经把任务输入数据传输完成,则可将计算结果由RSU传递
计算操作
本地计算:计算时间和计算消耗的能量
远程执行:无线传输时间和MEC计算时间,能量消耗仅用于数据传输
目的
调度程序连续确定“在哪”“何时”执行等待的任务。
为任务Ji做出调度决策的成本被定义为任务延迟和能耗之间的权衡
深度学习背景:
DRL是增强学习(RL)的增强,其中DNN用于状态表示或函数逼近。
在RL问题中,代理会随着时间与环境交互。 在每个时间步长n,代理都会在状态空间S中观察环境状态sn,
并遵循策略π从动作空间A中选择一个动作an,这是观察状态时采取actionan的概率 锡 然后,
环境根据环境动力学P和奖励函数R转换到下一个状态sn + 1∈S并向主体发出奖励信号。
除非代理观察到终端状态,否则此过程将无限期地继续。
RL的目的是找到最佳策略π∗,以最大化对状态空间中任何状态的累积奖励的期望
DRL使用DNN近似策略和/或价值函数。 借助DNN强大的表示能力,可以支持较大的状态空间。
本文设计了基于PRL的基于DRL的泛洪调度方法。
MDP公式
应用DRL解决调度问题,首先指定一个MDP,可以充分描述卸载调度过程,然后使用DRL为MDP找最佳策略
状态空间
每个时隙开始,调度程序监视系统状态,并根据状态做出调度决策。
每个状态用3Q矩阵+5个参数表示CT的任务队列,LPU,DTU,MEC服务器,最终的无线环境
LPU状态:LPU完成当前正在其运行的任务所需的剩余CPU周期数。完成时为0
DTU状态:DTU需要传给MEC服务器任务的剩余数据量。(可中断)
MEC服务器状态:表示MEC服务器需要为当前已完成的任务执行的剩余CPU周期数
当DTU状态参数和MEC状态参数为0时,才说DTU处于空闲,以便可以激活传输过程,否则任务无法调度
行动空间
本地执行LE(在哪安排),远程执行RE(在哪安排),保持HO(何时安排)
LE:将VT队列中的任务调度到LPU,任务被发送到LPU,LPU更改状态和任务队列的状态,随时隙更新
RE:DTU空闲且队列不空,可采取RE来填充指定任务以进行远程执行,DTU和MEC服务器状态变化,无需其他措施
HO:负责推迟任务调度,HOw意味着即使LPU和/或DTU能够接受计算或传输,调度程序仍决定将所有等待的任务在队列中等w个时隙。
如果无线条件较差并且频发导致不必要的大延迟和/或能量消耗,则适当推迟任务调度过程以等待更好的传输机会将是值得的。
行动空间和行动合法性
完整空间为三个结合的并集
每个时隙开始,调度程序监控系统状态并决定是否采取调度措施。
每个行为的合法性都与其他状态相关。
尽管系统在每个时隙中都有不同的状态,但调度程序的操作只会在执行该操作的那些时隙
其他时隙上系统状态的更改(称为中间状态)是由环境因素引起的,例如新到达的任务等
我们的MDP中的实际状态空间S仅包括可以采取措施时的状态。
奖赏
调度器在时隙tan上对状态sn采取行动,在tbn个时隙后,进入新状态sn + 1,基于此状态要采取新动作
基于状态转换的时间间隔内VT中所有任务的时间和能量消耗来定义奖励函数R
在每个时隙t,如果未完成到达的任务,则其等待时间将增加一个时隙。在时间段t表示VT中所有任务的总时间延迟
要算出VT中所有任务从动作sn到sn + 1的总时间延迟
能耗仅与任务本地计算和输入数据传输相关。计算在时间段tV中所有任务的总能耗
计算:采取行动后,VT中所有任务从状态sn到sn + 1的总能耗
在MDP中由任务队列溢出引起的成本∆o
在加权调度策略设计中适当选择加权参数α和β,以反映用户偏向较小的延迟或较低的能耗,而ζ是任务流量的惩罚参数。
MDP的奖励函数R(sn,an,sn + 1)被定义为成本函数的负数,表明这种过渡的程度如何。
选择常数参数ks来缩放奖励的值范围。
调度器可以遵循特定的随机调度策略π与环境进行交互。 然后获得马尔可夫链。
基于DRL的卸载调度
基于DRL的漫游调度方法。 首先用于逼近调度计划策略的DNN体系结构,然后设计基于PPO的训练方法来训练策略网络。
网络架构
DNN架构在训练过程中需要两个功能:作为学习目标的液体调度策略π,值函数v( sn;ω)用于优势估算
状态s∈S作为输入,但是具有不同的输出
利用参数共享的DNN架构同时估算策略和价值函数,策略网络和价值网络共享大多数网络结构。
区别在于共享的完全连接(FC)层之后的输出层,
对于策略网络,softmax层输出所有操作的概率分布。 对于价值网络,FC层输出状态值。
MDP的状态空间S非常大,使用单个FC网络结构进行特征提取会导致训练过程效率低下。
将CNN嵌入DNN架构中,以有效提取任务队列的代表性特征。
队列状态首先与输入状态分离,然后发送到CNN层。
CNN层的输出,在输入到FC层以促进功能逼近之前,与剩余状态信息并置。
四个卷积层用于提取队列中的特征。由于奖励中考虑了任务在队列中等待所花费的时间,每个时间步长的信号对我们的优化没有帮助。
训练算法
总体目标是将策略网络和价值网络的错误项组合在一起。利用GAE作为估算函数。
基于PPO的训练算法:用相同的参数(θold←θ)初始化两个DNN,一个用于采样(πθold),另一个用于优化(πθ)。
该算法在采样和优化之间交替,在采用阶段按照旧策略采样N条轨迹。
为了提高训练效率,此阶段预算每个轨迹中每个步长的广义优势估计。缓存采样数据进行优化。
优化阶段针对k个时期更新策略πθ的参数θ
在每个时期,我们都基于目标函数通过对缓存的采样数据进行随机梯度提升来改善策略πθ。
在优化阶段之后,我们用当前的πθ更新采样策略πθold并删除缓存的数据。然后,下一次迭代开始
探索阶段的随机策略不能确保根据当前状态选择的动作的合法性。
采样时选择的处理:如果选择了非法动作类型,系统将忽略该非法动作,使系统状态保持不变。
由于基于策略的DRL支持随机策略,因此总是有机会选择其他操作类型。
继续调度,在奖励中添加惩罚项ki。
当不存在由LEj或REj动作指定的任务时,我们让调度程序自动选择队列中的第一个任务
训练效率
训练过程很难收敛。为了解决这个问题,我们采取了一系列方法来提高培训效率。
我们限制选择HO动作。定义了两个常数参数,限制HO操作的最大等待时间。
每次调度程序执行HO动作时,调度最多可以延迟npg个时隙。如有必要,可以采取更多的HO动作来进一步推迟决策程序。
限制HO动作的最大等待时间不会改变原始MDP,但会显着减小动作空间。
每个时隙的长度可以非常小,这在连续的HO动作之间几乎没有区别。
为了避免训练过程探索保持任务太长时间的HO动作,系统会记录连续的等待时间。
当等待时间超过某个阈值时,将应用惩罚项kh。此阈值仅设置为L / V。
不鼓励VT在不执行任何任务的情况下通过RSU的整个覆盖范围。
通过设置常量参数psmax≤Q来进一步减小操作空间的大小,并将可能的LE和RE操作的数量限制为最大psmax
大量的非法行为也导致学习缓慢。在调度时,队列前面的任务应具有更高的优先级。
通过选择较小的psmax值,可以保证任务调度的公平性,尽管一定程度地牺牲了可实现的性能。
为了避免发生大量任务等待在队列,根据当前队列长度在奖励中添加惩罚项。kq和u反映了我们对队列长度的期望。
选择较大的kq和u值会导致等待任务的数量减少,训练过程也会更有效。
性能评估
进行了广泛的仿真实验,以评估基于DRL的泡沫调度方法(DRLOSM)。算法和网络架构是使用TensorFlow
每个任务的数据大小di和CVR ki都从表III所示各个区域内的均匀分布中采样。
代理(即调度程序)不知道所有实验环境设置,但是只要固定了环境,我们的DRLOSM就能够通过与环境直接交互来学习最佳的调度计划
融合表现
在实验环境中对其进行训练来验证所提出的DRLOSM的收敛性能
采用了两种不同的DNN体系结构作为泡沫调度策略:
提议的CNN嵌入式DNN体系结构(CNNembedded DNN)和3层FC DNN体系结构(3层FC)。
在3层FC中,每个FC层具有512个具有泄漏ReLU激活功能的神经元,并采用层归一化。
两种DNN架构的学习曲线(平均累积奖励与训练时期数)拟议的嵌入CNN的DNN的性能比3层FC好得多。
它可以获得更高的平均累积奖励,并且收敛速度更快。CNN嵌入的DNN的大小也小于3层FC的大小。
在训练过程中提出的DRLOSM的大量时间和计算开销。
我们的训练过程可以在远程云中完成。 VT仅需要执行推理过程即可做出泡沫决策。DRLOSM的推理过程非常高效
静态队列方案中的性能
通过与许多基准算法进行比较来评估DRLOSM的性能。该场景系统初始化后无法生成新任务。
-所有本地执行(AL):所有任务都在本地执行。
-全部开放(AO):所有任务都计划在MEC服务器上进行,而不管无线状况如何。
-随机泛滥(RD):以相同的概率随机选择动作空间中的所有动作。
-时间贪婪(TG):当LPU空闲时,将立即安排CVR最低的任务在本地执行。
当DTU闲置时,会立即安排CVR最高的任务进行泛洪。
在此算法中避免了HO动作,因为它们总是会增加任务等待时间。
-能源贪婪(EG):假设EG知道每个路段的预期V2I数据速率,仅在具有最佳无线条件的路段上执行任务,从而带来最低的能耗。
如果可以进一步降低能耗,则EG还可以安排任务以本地执行
基于以上五种基线算法采用预先定义的动作规则来指定浮动调度决策。
这些预定义的动作规则相对幼稚直观,使得决策过程更高效但灵活性较低。
除上述五个直观方法,GA遗传算法被用作另一种基线算法。
GA作为一种元启发式算法,是组合优化问题的一种使用解决方案。
GA:采用DEAP中的GA框架来实现此基线,调度计划被编码到每个人的染色体中,这是调度程序用来调度队列中任务的动作序列。
染色体中的每个基因都是整数,表示调度动作之一。
每个染色体的长度取决于EG的作用序列的长度,该序列的长度足以找到最佳解。
假设GA知道每个路段的无线状况。 因此,它可以通过在模拟环境中应用动作序列来评估每个人
当GA终止时,将选择最有适应能力的人员作为最终的计划计划。
GA是一种典型的“一次性”计划算法,它试图根据当前系统状态计算最佳的调度计划。
一旦根据调度计划制定的系统状态发生更改(例如,生成新任务),就应重新执行该状态。
如果新任务不断动态到达,则GA应该保持在线方式重新执行。GA运行成本很昂贵,它仅适于SQS
通过更改加权因子α和固定β= 1进行仿真。任务队列Q的初始状态和VT的初始位置x [0]都是随机选择的,但是对于所有算法而言,它们都是相同的。
在SQS中不存在任务超载的风险,因此在训练中将惩罚参数ζ和kq设置为0。
比较AL,EG,AO等由于切换导致传输失败而导致平均重传任务的数量,体现该算法的优势
分开总成本并单独考虑任务等待时间和能耗。
C动态队列中的性能
D组合策略
考虑应用一种组合决策策略(CDS),该决策策略可以在五种直观算法(即TG,EG,AL,AO和RD)之间动态切换,以实现比它们各自更高的性能
确定何时以及在不同环境中应采用哪种直观策略取决于专家知识。并且需要花费大量精力来微调决策规则。
在如此复杂和动态的环境中,提出的DRLOSM可以通过与环境直接交互并学习最佳的调度算法来解决这些问题。无模型的基于DRL的算法的优势显而易见
总结:
基于DRL的方法来解决这些问题。它是根据最新的PPO算法设计的。
由CNN增强的参数共享DNN体系结构可用于近似策略和价值函数。
已经考虑了一系列方法来处理较大的状态和动作空间并提高训练效率。
而无需任何先验的环境动力学知识,并且就长期成本而言,它明显优于许多已知的基线算法。
固定数量的MEC计算资源和V2I传输带宽被假定为每个VT保留。在更一般的条件下,应考虑每个RSU的资源限制。
VT将相互竞争或合作以共享有限的资源。在这种情况下,可能会使用多代理部分可观察的MDP(多代理POMDP)来表述调度调度问题