jvm高级相关知识
二、字节码与类的加载篇
(18-21章)
1、Class文件结构


1.1、概述
1.1.1、字节码文件的跨平台性
1、Java语言:跨平台的语言(write once, run anywhere)
■ 当Java源代码成功编译成字节码后,如果想在不同的平台上面运行,则无须再次编译
■ 这个优势不再那么吸引人了。Python、PHP、Per1、Ruby、Lisp等有强大的解释器
■ 跨平台似乎已经快成为一门语言必选的特性
2、Java虚拟机:跨语言的平台
Java虚拟机不和包括Java在内的任何语言绑定,它只与“ Class文件”这种特定的二进制文件格式所关联。无论使用何种语言进行软件开发,只要能将源文件编译为正确的 Class文件,那么这种语言就可以在Java虚拟机上执行。可以说,统一而强大的c]ass文件结构,就是]ava虚拟机的基石、桥梁

jvm 规范:https://docs.oracle.com/javase/specs/index.html
所有的 JVM 全部遵守Java虚拟机规范,也就是说所有的JWM环境都是一样的,这样一来字节码文件可以在各种JM上运行
3、想要让一个Java程序正确地运行在 JVM 中,Java源码就必须要被编译为符合 JVM 规范的字节码
■ 前端编译器的主要任务就是负责将符合]ava语法规范的Java代码转换为符合JM规范的字节码文件
■ Javac是一种能够将Java源码编译为字节码的前端编译器
■ Javac编译器在将Java源码编译为一个有效旳字节码文件过程中经历了4个步骤,分别是词法解析、语法解析、语义解析以及生成字节码

Oracle 的 JDK 软件包括两部分内容:
● 一部分是将 Java 源代码编译成 Java 虚拟机的指令集的编译器
● 另一部分是用于实现 Java 虚拟机的运行时环境
1.1.2、Java的前端编译器

前端编译器 VS 后端编译器
Java源代码的编译结果是字节码,那么肯定需要有一种编译器能够将Jaνa源码编译为字节码,承担这个重要责仼的就是配置在path环境变量中的 Javac编译器。 Javac是一种能够将Java源码编译为字节码的前端编译器
HotSpot VM并没有强制要求前端编译器只能使用 Javac来编译字节码,其实只要编译结果符合JwM规范都可以被Jw所识别即可。在Java的前端编译器领域,除了 Javac之外,还有一种被大家经常用到的前端编译器,那就是内置在 Eclipse中的 ECJ(Eclipse Compiler for Java)编译器。和 Javac的全量式编译不同,ECJ是一种增量式编译器
■ 在 Eclipse中,当开发人员编写完代码后,使用“Ctrl+s”快捷键时,ECJ 编译器所釆取的编译方案是把未编译部分的源码逐行进行编译,而非每次都全量编译。因此ECJ的编译效率会比 Javac更加迅速和高效,当然编译质量和 Javac相比大致还是一样的
■ ECJ不仅是Eclipse的默认内置前端编译器,在Tomcat中同样也是使用ECJ编译器来编译jsp文件。由于ECJ编译器是釆用GPLv2的开源协议进行源代码公开,所以大家可以登录 eclipse官网下载ECJ编译器的源码进行二次开发
■ 默认情况下,Intellij DEA使用 Javac 编译器。(还可以自己设置为 AspectJ 编译器ajc)
前端编译器并不会直接涉及编译优化等方面的技术,而是将这些具体优化细节移交给 Hotspot的 JIT 编译器负责
如定义一个类:class HelloWorld{},可以使用 javac HelloWorld.java 进行前端编译
1.1.3、透过字节码指令看代码细节
1、BAT 面试题
①、类文件结构有几个部分?
②、知道字节码吗?字节码都有哪些?Integer x=5; int y = 5; 比较 x == y 都经过哪些步骤?
2、代码举例
代码举例1:
public static void main(String[] args) {
Integer x = 5;
int y = 5;
System.out.println(x == y); //true
Integer i1 = 10;
Integer i2 = 10;
System.out.println(i1 == i2); //true
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4); //false
}
代码举例2:
public static void main(String[] args) {
String str = new String("hello") + new String("world");
String str1 = "helloworld";
System.out.println(str == str1); //false
String str2 = new String("helloworld");
System.out.println(str == str2); //false
System.out.println(str1 == str2); //false
}
代码举例3:
package com.pengtxyl.two.chapter01;
/*
* 成员变量(非静态的)的赋值过程:1 默认初始化 - 2 显式初始化/代码块中初始化 - 3 构造器中初始化 - 4 有了对象之后,可以“对象.属性" 或 “对象.方法”的方式对成员变量进行赋值
* */
class Father {
int x = 10; //显式初始化
public Father() {
this.print();
x = 20;
}
public void print() {
System.out.println("Father.x = " + x);
}
}
class Son extends Father {
int x = 30;
public Son() {
this.print();
x = 40;
}
public void print() {
System.out.println("Son.x = " + x);
}
}
public class SonTest extends Father {
public static void main(String[] args) {
Father f = new Son();
System.out.println(f.x); //属性不存在多态性
}
}
输出结果:
Son.x = 0
Son.x = 30
20
1.2、虚拟机的基石:Class文件
1、字节码文件里是什么
源代码经过编译器编译之后便会生成一个字节码文件,字节码是一种二进制的类文件,它的内容是JWM的指令,而不像C、C++经由编译器直接生成机器码
2、什么是字节码指令(byte code)
Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的操作码( opcode)以及跟随其后的零至多个代表此操作所需参数的操作数( operand)所构成。虚拟机中许多指令并不包含操作数,只有一个操作码
比如:操作码 (操作数)

3、如何解读供虚拟机解释执行的二进制字节码?
■ 方式一:一个一个二进制的看。这里用到的是 Notepad++,需要安装一个 HEX-Editor 插件,或者使用 Binary Viewer

■ 方式二:使用 javap 指令:jdk 自带的反解析工具
可以在 IDEA 中使用 javap,右键点击 class 字节码文件,使用 javap -v 命令。也可以使用
javap -v IntegerTest.class > IntegerTest.txt 用于保存到指定文件中

■ 方式三:使用 IDEA 插件 jclasslib 或 jclasslib bytecode viewer 客户端工具(可视化更好,推荐使用)
或
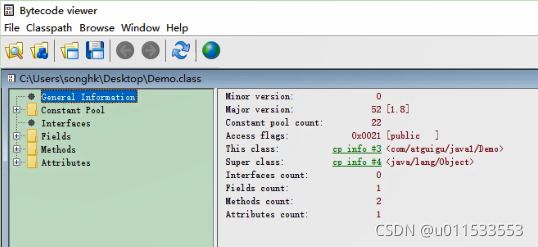
1.3、Class文件结构
如下图的这种二进制字节码,怎么导入到 excel 中呢?
1、复制二进制字节码,创建一个 txt 文档,将字节码保存到 txt 文档中
2、在 txt 文档中,按照下面这种格式一行一行分割开
3、将空格用逗号替换
4、将 txt 文档的后缀格式改成 csv 格式
5、复制 csv 格式中的文字,保存到excel 中
6、在 excel 中,将 0 开始的那些数字添加 0,注意:里面的 20 要使用 00 替换

■ 官方文档位置
https://docs.oracle.com/javase/specs/jvms/se8/htm1/jvms-4.html
■ Class类的本质
任何一个c1ass文件都对应着唯一一个类或接口的定义信息,但反过来说,C1ass文件实际上它并不一定以磁盘文件的形式存在。Class 文件是一组以8位字节为基础单位的二进制流。
■ Class文件格式
Class的结构不像 XML等描述语言,由于它没有任何分隔符号。所以在其中的数据项,无论是字节顺序还是数量,都是被严格限定的,哪个字节代表什么含义,长度是多少,先后顺序如何,都不允许改变
■ Class文件格式采用一种类似于c语言结构体的方式进行数据存储,这种结构中只有两种数据类型:无符号数和表
● 无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值
● 表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以“info”结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质上就是一张表。由于表没有固定长度,所以通常会在其前面加上个数说明
● 代码举例:
public class Demo {
private int num = 1;
public int add() {
num = num + 2;
return num;
}
}
对应的字节码文件:

换句话说:充分理解了每一个字节码文件的细节,自己也可以反编译出 Java 源文件来
■ Class 文件的结构概述
Class 文件的结构并不是一成不变的,随着 Java 虚拟机的不断发展,总是不可避免地会对 Class 文件结构做出一些调整,但是其基本结构和框架是非常稳定的
Class 文件的总体结构如下:
● 魔数
● Class 文件版本
● 常量池
● 访问标志
● 类索引、父类索引、接口索引集合
● 字段表集合
● 方法表集合
● 属性表集合


这是一张 Java 字节码总的结构表,我们按照上面的顺序逐一进行解读就可以了
1.3.1、魔数:Class文件的标志
Magic Number(魔数)
■ 每个C1ass文件开头的4个字节的无符号整数称为魔数( Magic Number)
■ 它的唯一作用是确定这个文件是否为一个能被虚拟机接受的有效合法的C1ass文件。即:魔数是 Class文件的标识符
■ 魔数值固定为 0xCAFEBABE。不会改变
■ 如果一个c1ass文件不以θ XCAFEBABE开头,虚拟机在进行文件校验的时候就会直接抛出以下错误
Error: A JNI error has occurred, please check your installation and try again
Exception in thread java. lang. ClassFormatError: Incompatible magic value 1885430635 in class file StringIest
■ 使用魔数而不是扩展名来进行识别主要是基于安全方面的考虑,因为文件扩展名可以随意地改动
1.3.2、Class文件版本号
■ 紧接着魔数的4个字节存储的是Class文件的版本号。同样也是4个字节。第5个和第6个字节所代表的含义就是编译的副版本号 minor_ version,而第7个和第8个字节就是编译的主版本号 major-version
■ 它们共同构成了class文件的格式版本号。譬如某个 Class文件的主版本号为M,副版本号为m,那么这个C1ass文件的格式版本号就确定为M.m
■ 版本号和 Java 编译器的对应关系如下表
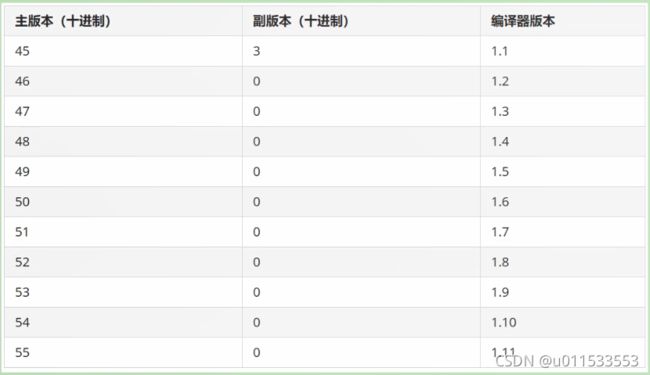
■ Java的版本号是从45开始的,JDK1.1之后的每个]DK大版本发布主版本号向上加1
■ 不同版本的]ava编译器编译的C1ass文件对应的版本是不一样的。目前,高版本的Java虚拟机可以执行由低版本编译器生成的Class文件,但是低版本的Java虚拟机不能执行由高版本编译器生成的c1ass文件。否则JW会抛出java.lang. UnsupportedclassVersionError异常
■ 在实际应用中,由于开发环境和生产环境的不同,可能会导致该问题的发生。因此,需要我们在开发时,特别注意开发编译的DK版本和生产环境中的DK版本是否一致
● 虚拟机JDK版本为1.k(k>=2)时,对应的c1ass文件格式版本号的范围为45.0-44+k.0(含两端)
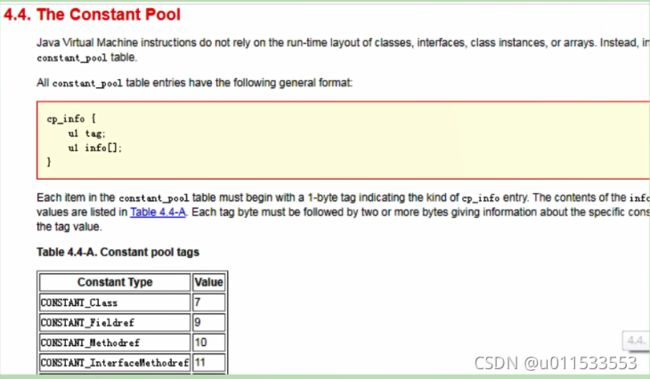
1.3.3、常量池:存放所有常量
■ 常量池是Class文件中内容最为丰富的区域之一。常量池对于 Class 文件中的字段和方法解析也有着至关重要的作用
■ 随着 Java 虚拟机的不断发展,常量池的内容也日渐丰富。可以说,常量池是整个 Class 文件的基石
■ 在版本号之后,紧跟着的是常量池的数量,以及若干常量池表项
■ 常量池中常量的数量是不固定的,所有在常量池的入口需要放置一项u2类型的无符号数,代表常量池容量技术值(constant_pool_count)。与 java 中语言习惯不一样的是,这个容量技术是从1而不是0开始的

由上表可见,Class文件使用了一个前置的容量计数器(constant_pool_count)加若干个连续的数据项(constant_pool)的形式来描述常量池内容。我们把这一系列连续常量池数据称为常量池集合
■ 常量池表项中,用于存放编译时期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放
①、常量池计数器
constant_ pool count(常量池计数器)
■ 由于常量池的数量不固定,时长时短,所以需要放置两个字节来表示常量池容量计数值
■ 常量池容量计数值(u2类型):从1开始,表示常量池中有多少项常量。即 constant_ pool count=1表示常量池中有个常量项
■ Demo的值为:

其值为0x0016,掐指一算,也就是22。
需要注意的是,这实际上只有21项常量。索引为范围是1–21。为什么呢?
通常我们写代码时都是从0开始的,但是这里的常量池却是丛1开始,因为它把第0项常量空出来了。这是为了满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用仼何一个常量池项目的含义,这种情况可用索引值0来表示
②、常量池表
constant_pool [] (常量池)
■ constant_poo1是一种表结构,以1~ constant_pol_count - 1为索引。表明了后面有多少个常量项
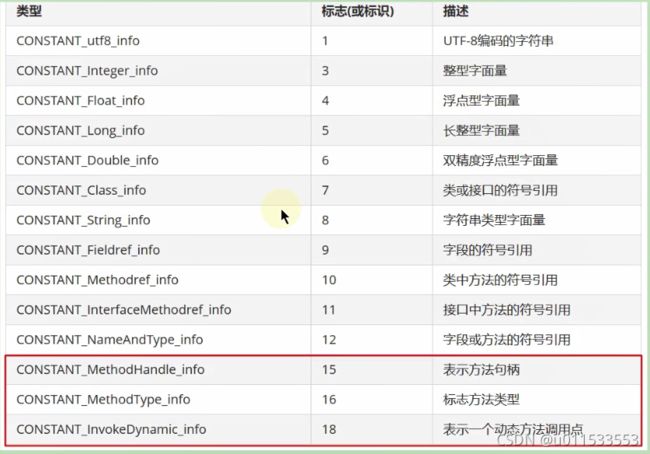
■ 常量池主要存放两大类常量:字面量( Literal)和符号引用( Symbolic References)
■ 它包含了 class文件结构及其子结构中引用的所有字符串常量、类或接口名、字段名和其他常量。常量池中的每一项都具备相同的特征。第1个字节作为类型标记,用于确定该项的格式,这个字节称为 tag byte(标记字节、标签字节)
2-1、字面量和符号引用
在对这些常量解读前,我们需要搞清楚几个概念。
常量池主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。如下表:

■ 全限定名
com/atguigu/test/Demo这个就是类的全限定名,仅仅是把包名的”.”替换成”/”,为了使连续的多个全限定名之间不产生混淆,在使用时最后一般会加入一个“;”表示全限定名结束
■ 简单名称
简单名称是指没有类型和参数修饰的方法或者字段名称,上面例子中的类的add()方法和num字段的简单名称分别是add和num
■ 描述符
描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,详见下表:
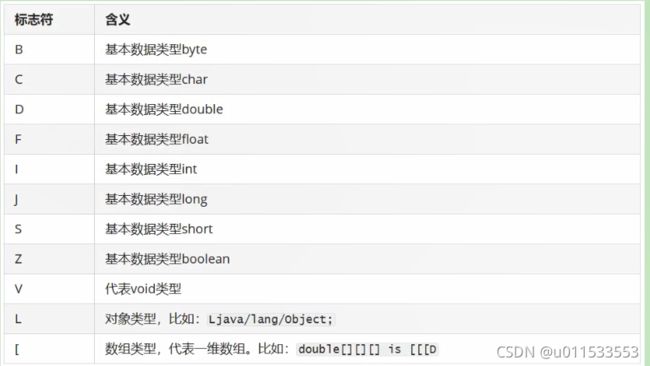
用描述符来描述方法时,按照先参数列表,后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法ava.lang. String tostring()的描述符为() Ljava/lang/ String;,方法 int abc(int[] x,int y)的描述符为([II) I。
补充说明:
虚拟机在加载C1ass文件时才会进行动态链接,也就是说,Class文件中不会保存各个方法和字段的最终内存布局信息,因此,这些字段和方法的符号引用不经过转换是无法直接被虚拟机使用的。当虚拟机运行时,需要从常量池中获得对应的符号引用,再在类加载过程中的解析阶段将其替换为直接引用,并翻译到具体的内存地址中
这里说明下符号引用和直接引用的区别与关联:
● 符号引用:符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到了内存中
● 直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是与虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那说明引用的目标必定已经存在于内存之中了
2-2、常量类型和结构
常量池中每一项常量都是一个表,JDK1.7之后共有14种不同的表结构数据。如下表格所示:

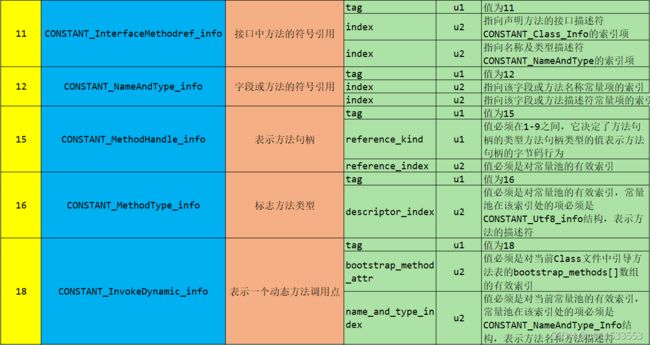
■ 根据上图每个类型的描述我们也可以知道每个类型是用来描述常量池中哪些内容(主要是字面量、符号引用)的。比如:CONSTANT_Integer_info是用来描述常量池中字面量信息的,而且只是整型字面量信息
■ 标志为15、16、18的常量项类型是用来支持动态语言调用的(jdk1.7时才加入的)
■ 细节说明:
● CONSTANT_Class info结构用于表示类或接口
● CONSTANT_Fieldref_info、 CONSTANT_Methodref_info和 CONSTANT_InterfaceMethodref_info结构表示字段、方法和接口方法
● CONSTANT_String_info结构用于表示 string类型的常量对象
● CONSTANT_Integer_info和 CONSTANT_Float_info表示4字节(int和float)的数值常量
● CONSTANT_Long _info和 CONSTANT_Double_info结构表示8字节(long和 double)的数值常量
○ 在class文件的常量池表中,所有的8字节常量均占两个表成员(项)的空间。如果一个 CONSTANT_Long_info或 CONSTANT_Double_info结构的项在常量池表中的索引位n,则常量池表中一个可用项的索引位n+2,此时常量池表中索引为n+1的项仍然有效但必须视为不可用的
● CONSTANT_NameAndType_info结构用于表小字段或方法,但是和之前的3个结构不同, CONSTANT_NameAndType_info结构没有指明该字段或方法所属的类或接口
● CONSTANT_Utf8_info用于表示字符常量的值
● CONSTANT_MethodHandle_info结构用于表示方法句柄
● CONSTANT_MethodType_info结构表示方法类型
● CONSTANT_InvokeDynamic_info结构用于表示 invokedynamic指令所用到的引导方法( bootstrap method)、引导方法所用到的动态调用名称( dynamic invocation name)、参数和返回类型,并可以给引导方法传入一系列称为静态参数( static argument)的常量
■ 解析方式:
● 一个字节一个字节的解析
● 使用 javap 命令解析:javap -verbose Demo.class 或 jclasslib 工具会更方便
总结
总结1:
■ 这14种表(或者常量项结构)的共同点是:表开始的第一位是一个u1类型的标志位(tag),代表当前这个常量项使用的是哪种表结构,即哪种常量类型
■ 在常量池列表中, CONSTANT_Utf8_info常量项是一种使用改进过的UTF-8编码格式来存储诸如文字字符串、类或者接口的全限定名、字段或者方法的简单名称以及描述符等常量字符串信息
■ 这14种常量项结构还有一个特点是,其中13个常量项占用的字节固定,只有 CONSTANT_Utf8_info占用字节不固定,其大小由1 ength决定。为什么呢?因为从常量池存放的内容可知,其存放的是字面量和符号引用,最终这些内容都会是一个字符串,这些字符串的大小是在编写程序时才确定,比如你定义一个类,类名可以取长取短,所以在没编译前,大小不固定,编译后,通过utf-8编码,就可以知道其长度
总结2:
■ 常量池:可以理解为 Class文件之中的资源仓库,它是las文件结构中与其他项目关联最多的数据类型(后面的很多数据类型都会指向此处),也是占用Class文件空间最大的数据项目之一
■ 常量池中为什么要包含这些内容
Java代码在进行 Javac编译的时候,并不像C和C++那样有“连接”这一步骤,而是在虚拟机加载Class文件的时候进行动态链接。也就是说,在Class文件中不会保存各个方法、字段的最终内存布局信息,因此这些字段、方法的符号引用不经过运行期车换的话无法得到真正的內存入口地址,也就无法直接被虚拟机使用。当虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析、翻译到具体的内存地址之中。关于类的创建和动态链接的内容,在虚拟机类加载过程时再进行详细讲解
1.3.4、访问标识
访问标识( access_flag、访问标志、访问标记)
■ 在常量池后,紧跟着访问标记。该标记使用两个字节表示,用于识别一些类或者接口层次的访问信息,包括:这个Class 是类还是接口;是否定义为 public类型;是否定义为 abstract类型;如果是类的话,是否被声明为final等。各种访问标记如下所示:

■ 类的访问权限通常为 ACC_ 开头的常量
■ 每一种类型的表示都是通过设置访问标记的32位中的特定位来实现的。比如,若是public final的类,则该标记为ACC_PUBLIC | ACC_FINAL
■ 使用ACC_SUPER可以让类更准确地定位到父类的方法 super.method(),现代编译器都会设置并且使用这个标记
补充说明:
1、带有 ACC_INTERFACE标志的class文件表示的是接口而不是类,反之则表示的是类而不是接口
①、如果一个c1ass文件被设置了 ACC INTERFACE标志,那么同时也得设置 ACC_ABSTRACT标志。同时它不能再设置 ACC_FINAL、ACC_SUPER 或 ACC_ENUM标志
②、如果没有设置 ACC_INTERFACE标志,那么这个class文件可以具有上表中除 ACC_ANNOTATION外的其他所有标志。当然, ACC_FINAL和ACC_ABSTRACT这类互斥的标志除外。这两个标志不得同时设置
2、ACC_ SUPER标志用于确定类或接口里面的 invokespecial指令使用的是哪一种执行语义。针对Java虚拟机指令集的编译器都应当设置这个标志。对于 javase8及后续版本来说,无论 class文件中这个标志的实际值是什么,也不管class文件的版本号是多少,Java虚拟机都认为每个c1ass文件均设置了 ACC_SUPER标志
①、ACC_SUPER标志是为了向后兼容由旧 java编译器所编译的代码而设计的。目前的 ACC_SUPER标志在由JDK1.0.2之前的编译器所生成的 access_fags中是没有确定含义的,如果设置了该标志,那么 Oracle的Java虚拟机实现会将其忽略
3、 ACC_SYNTHETIC标志意味着该类或接口是由编译器生成的,而不是由源代码生成的
4、注解类型必须设置 ACC_ANNOTATION标志。如果设置了 ACC_ANNOTATION标志,那么也必须设置 ACC_INTERFACE标志
5、ACC_ENUM标志表明该类或其父类为枚举类型
6、表中没有使用的 access_flags标志是为未来扩充而预留的,这些预留的标志在编译器中应该设置为0,Java虚拟机实现也应该忽略它们
1.3.5、类索引、父类索引、接口索引集合
■ 在访问标记后,会指定该类的类别、父类类别以及实现的接口,格式如下:
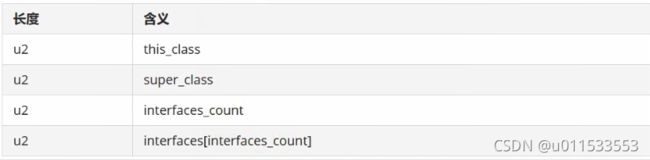
■ 这三项数据来确定这个类的继承关系
● 类索引用于确定这个类的全限定名
● 父类索引用于确定这个类的父类的全限定名。由于Java语言不允许多重继承,所以父类索引只有一个,除了ava.lang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不为 0
● 接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按 implements语句(如果这个类本身是一个接口,则应当是 extends语句)后的接口顺序从左到右排列在接口索引集合中
1、this_class(类索引)
2字节无符号整数,指向常量池的索引。它提供了类的全限定名,如com/ atguigu/java1/Demo。this_class的值必须是对常量池表中某项的一个有效索引值。常量池在这个索引处的成员必须为 CoNSTANT_Class_info类型结构体,该结构体表示这个class文件所定义的类或接口
2、super_class(父类索引)
● 2字节无符号整数,指向常量池的索引。它提供了当前类的父类的全限定名。如果我们没有继承任何类,其默认继承的是java/lang/ Object类。同时,由于Java不支持多继承,所以其父类只有一个·
● superclass指向的父类不能是final
3、interface
● 指向常量池索引集合,它提供了一个符号引用到所有已实现的接口
● 由于一个类可以实现多个接口,因此需要以数组形式保存多个接口的索引,表示接口的每个索引也是一个指向常量池的CONSTANT_Class(当然这里就必须是接口,而不是类)
3.1、 interfaces_count(接口计数器)
interfaces_count项的值表示当前类或接口的直接超接口数量
3.2、interfaces[] (接口索引集合)
interfaces[] 中每个成员的值必须是对常量池表中某项的有效索引值,它的长度为 interfaces_count。每个成员 interfaces[i] 必须为 CONSTANT_ Class_info结构,其中 0<=i< interfaces_count。在 interfaces[]中,各成员所表示的接口顺序和对应的源代码中给定的接口顺序(从左至右)一样,即 interfaces[0]对应的是源代码中最左边的接口
1.3.6、字段表集合
field
■ 用于描述接口或类中声明的变量。字段(fie1d)包括类级变量以及实例级变量,但是不包括方法内部、代码块内部声明的局部变量
■ 字段叫什么名字、字段被定义为什么数据类型,这些都是无法固定的,只能引用常量池中的常量来描述
■ 它指向常量池索引集合,它描述了每个字段的完整信息。比如字段的标识符、访问修饰符(public、 private或protected)、是类变量还是实例变量( static修饰符)、是否是常量(final修饰符)等
注意事项
■ 字段表集合中不会列出从父类或者实现的接口中继承而来的字段,但有可能列出原本 Java代码之中不存在的字段。譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段
■ 在Java语言中字段是无法重载的,两个字段的数据类型、修饰符不管是否相同,都必须使用不一样的名称,但是对于字节码来讲,如果两个字段的描述符不一致,那字段重名就是合法的
①、字段计数器
fields_count(字段计数器)
fields_count 的值表示当前 class 文件 fields 表的成员个数。使用两个字节表示。
fields 表中每个成员都是一个 field_info 结构,用于表示该类或接口所声明的所有类字段或者实例字段,不包括方法内部声明的变量,也不包括从父类或父接口继承的那些字段
②、字段表
fields[] (字段表)
■ fields表中的每个成员都必须是一个 fields_info结构的数据项,用于表示当前类或接口中某个字段的完整描述
■ 一个字段的信息包括如下这些信息。这些信息中,各个修饰符都是布尔值,要么有,要么没有
● 作用域(public、 private、 protected修饰符
● 是实例变量还是类变量( static修饰符)
● 可变性(final )
● 并发可见性( volatile修饰符,是否强制从主内存读写)
● 可否序列化( transient修饰符)
● 字段数据类型(基本数据类型、对象、数组)
● 字段名称
■ 字段表结构
字段表作为一个表,同样有他自己的结构

2-1、字段表访问标识
我们知道,一个字段可以被各种关键字去修饰,比如:作用域修饰符(public、 private、 protected)、 static修饰符、fina修饰符、 volatile修饰符等等。因此,其可像类的访问标志那样,使用一些标志来标记字段。字段的访问标志有如下这些:
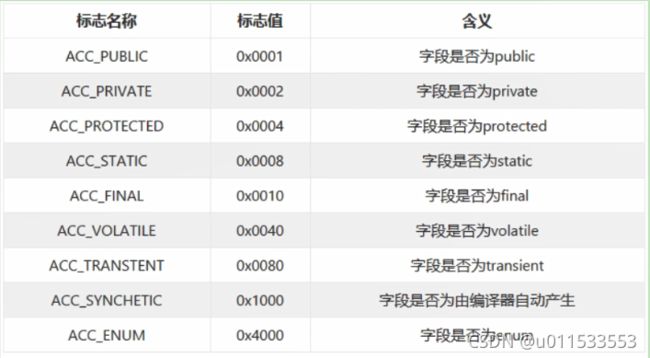
2-2、字段名索引
根据字段名索引的值,查询常量池中的指定索引项即可
2-3、描述符索引
描述符的作用是用来描述字段的数据类型方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte,char, double,f1oat,int,long, short, boolean)及代表无返回值的void类型都用一个大写字符来表示,而对象则用字符L加对象的全限定名来表示,如下所示:

2-4、属性表集合
一个字段还可能拥有一些属性,用于存储更多的额外信息。比如初始化值、一些注释信息等。属性个数存放在 attribute_count 中,属性具体内容存放在 attributes 数组中
以常量属性为例,结构为:
ConstantValue_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 constantvalue_index;
}
说明:对于常量属性而言,attribute_length 值恒为2
1.3.7、方法表集合
methods:指向常量池索引集合,它完整描述了每个方法的签名
■ 在字节码文件中,每一个 method info项都对应着一个类或者接口中的方法信息。比如方法的访问修饰符(public、private或 protected),方法的返回值类型以及方法的参数信息等
■ 如果这个方法不是抽象的或者不是 native的,那么字节码中会体现出来
■ 一方面, methods表只描述当前类或接口中声明的方法,不包括从父类或父接口继承的方法。另一方面, methods表有可能会出现由编译器自动添加的方法,最典型的便是编译器产生的方法信息(比如:类(接口)初始化方法()和实例初始化方法()
使用注意事项:
在Java语言中,要重载( Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名,特征签名就是一个方法中各个参数在常量池中的字段符号引用的集合,也就是因为返回值不会包含在特征签名之中因此Java语言里无法仅仅依靠返回值的不同来对一个已有方法进行重载。但在C1ass文件格式中,特征签名的范围更大一些,只要描述符不是完全一致的两个方法就可以共存。也就是说,如果两个方法有相同的名称和特征签名,但返回值不同,那么也是可以合法共存于同一个c1ass文件中
也就是说,尽管Java语法规范并不允许在一个类或者接口中声明多个方法签名相同的方法,但是和Java语法规范相反,字节码文件中却恰恰允许存放多个方法签名相同的方法,唯一的条件就是这些方法之间的返回值不能相同
①、方法计数器
methods_count(方法计数器)
methods_count 的值表示当前 class 文件 methods 表的成员个数。使用两个字节来表示
methods 表中每个成员都是一个 method_info 结构
②、方法表
methods[] (方法表)
■ methods表中的每个成员都必须是一个 method_info结构,用于表示当前类或接口中某个方法的完整描述。如果某个method_info结构的 access_flags项既没有设置 ACC_NATIVE标志也没有设置 ACC_ABSTRACT标志,那么该结构中也应包含实现这个方法所用的Java虚拟机指令
■ method_info结构可以表示类和接口中定义的所有方法,包括实例方法、类方法、实例初始化方法和类或接口初始化方法
■ 方法表的结构实际跟字段表是一样的,方法表结构如下

2-1、方法表访问标志
跟字段表一样,方法表也有访问标志,而且他们的标志有部分相同,部分则不同,方法表的具体访问标志如下:

1.3.8、属性表集合
属性表集合( attributes)
■ 方法表集合之后的属性表集合,指的是 class文件所携带的辅助信息,比如该c]ass文件的源文件的名称。以及任何带有Retention Policy. CLASS或者 Retention Policy. RUNTII№E的注解。这类信息通常被用于Java虚拟机的验证和运行,以及Java程序的调试,一般无须深入了解
■ 此外,字段表、方法表都可以有自己的属性表。用于描述某些场景专有的信息
■ 属性表集合的限制没有那么严格,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息,但Java虚拟机运行时会忽略掉它不认识的属性
①、属性计数器
②、属性表
attributes[] (属性表)
属性表的每个项的值必须是 attribute_info 结构。属性表的结构比较灵活,各种不同的属性只要满足以下结构即可
2-1、属性的通用格式
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u4 | attribute_length | 1 | 属性长度 |
| u1 | info | attribute_length | 属性表 |
即只需说明属性的名称以及占用位数的长度即可,属性表具体的结构可以去自定义
2-2、属性类型
属性表实际上可以有很多类型,上面看到的 Code 属性只是其中一种,Java8里面定义了23中属性。下面这些是虚拟机中预定义的属性
| 属性名称 | 使用位置 | 含义 |
|---|---|---|
| Code | 方法表 | Java代码编译成的字节码指令 |
| ConstantValue | 字段表 | final关键字定义的常量池 |
| Deprecated | 类,方法,字段表 | 被声明为deprecated的方法和字段 |
| Exceptions | 方法表 | 方法抛出的异常 |
| EnclosingMethod | 类文件 | 仅当一个类为局部类或者匿名类时才能有这个属性,这个属性用于标识这个类所在的外围方法 |
| InnerClass | 类文件 | 内部类列表 |
| LineNumberTable | Code属性 | Java源码的行号与字节码指令的对应关系 |
| LocalVariableTable | Code属性 | 方法的局部变量描述 |
| StackMapTable | Code属性 | JDK1.6中新增的属性,供新的类型检查检验器检验和处理目标方法的局部变量和操作数有所需要的类是否匹配 |
| Signature | 类,方法表,字段表 | 用于支持泛型情况下的方法签名 |
| SourceFile | 类文件 | 记录源文件名称 |
| SourceDebugExtension | 类文件 | 用于存储额外的调试信息 |
| Synthetic | 类,方法表,字段表 | 标志方法或字段为编译器自动生成的 |
| LocalVariableTypeTable | 类 | 使用特征前面代替描述符,是为了引入泛型语法之后能描述泛型参数化类型而添加 |
| RuntimeVisibleAnnotations | 类,方法表,字段表 | 为动态注解提供支持 |
| RuntimeInvisibleAnnotations | 表,方法表,字段表 | 用于指明哪些注解是运行时不可见的 |
| RuntimeVisibleParameterAnnotation | 方法表 | 作用与RuntimeVisibleAnnotations属性类似,只不过作用对象为方法 |
| RuntimeInvisibleParameterAnnotation | 方法表 | 作用与RuntimeInvisibleAnnotations属性类似,只不过作用对象为方法 |
| AnnotationDefault | 方法表 | 用于记录注解类元素的默认值 |
| BootstrapMethods | 类文件 | 用于保存invokeddynamic指令引用的引导方式限定符 |
或查看官网:

2-3、部分属性详解
①、ConstantValue 属性
ConstantValue 属性表示一个常量字段的值。位于 field_info 结构的属性表中
ConstantValue_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 constantvalue_index; //字段值在常量池中的索引,常量池在该索引处的项给出该属性表示的常量值。(例如:值是 long 型的,在常量池中便是 CONSTANT_Long)
}
②、Deprecated 属性
Deprecated 属性是在 JDK1.1为了支持注释中的关键词@deprecated 而引入的
Deprecated_attribute{
u2 attribute_name_index;
u4 attribute_length;
}
③、Code 属性
Code 属性就是存放方法体里面的代码。但是,并非所有方法表都有 Code 属性。像接口或者抽象方法,他们没有具体的方法体,因此也就不会有 Code 属性了。
Code 属性表的结构,如下图:
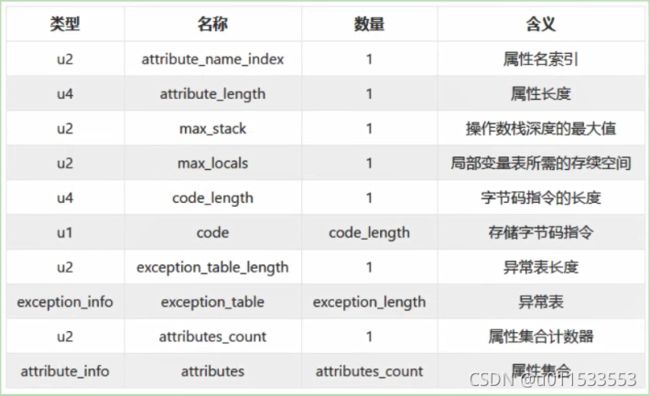
可以看到:Code 属性表的前两项跟属性表是一致的,即 Code 属性表遵循属性表的结构,后面那些则是他自定义的结构
④、InnerClasses 属性
为了方便说明特别定义一个表示类或接口的Class格式为C。如果C的常量池中包含某个 CONSTANT_Class_info成员,且这个成员所表示的类或接口不属于任何一个包,那么C的ClassFile结构的属性表中就必须含有对应的 InnerClasses属性。 InnerClasses属性是在JDK1.1中为了支持内部类和内部接口而引入的,位于 ClassFile结构的属性表
⑤、LineNumberTable 属性
LineNumbertable属性是可选变长属性,位于code结构的属性表。
LineNumberτable属性是用来描述Java源码行号与字节码行号之间的对应关系。这个属性可以用来在调试的时候定位代码执行的行数
● start_pc,即字节码行号;line_number,即Java源代码行号
在Code属性的属性表中, LineNumbertable属性可以按照任意顺序出现,此外,多个 LineNumbertable属性可以共同表示个行号在源文件中表示的内容,即 LineNumbeTable属性不需要与源文件的行一一对应
LineNumberTable 属性表结构:
LineNumberTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 line_number_table_length;
{
u2 start_pc;
u2 line_number;
} line_number_table[line_number_table_length];
}
⑥、LocalVariableTable 属性
LocalVariableTable 是可选变长属性,位于Code属性的属性表中。它被调试器用于确定方法在执行过程中局部变量的信息在Code属性的属性表中, LocalVariableTable 属性可以按照仼意顺序出现。Code属性中的每个局部变量最多只能有一个LocalVariableTable 属性
● start pc+ length表示这个变量在字节码中的生命周期起始和结束的偏移位置(this生命周期从头0到结尾10)
● index就是这个变量在局部变量表中的槽位(槽位可复用)
● name就是变量名称
● Descriptor表示局部变量类型描述
LocalVariableTable 属性表结构:
LocalVariableTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 local_variable_table_length;
{
u2 start_pc;
u2 length;
u2 name_index;
u2 descriptor_index;
u2 index;
} local_variable_table[local_variable_table_length];
}
⑦、Signature 属性
Signature 属性时可选的定长属性,位于 ClassFile,field_info 或 method_info 结构的属性表中。在 Java 语言中,任何类、接口、初始化方法或成员的泛型签名如果包含了类型变量(Type Variables) 或参数化类型(Parameterized Types),则 Signature 属性会为它记录泛型签名信息
⑧、SourceFile 属性
SourceFile 属性结构:
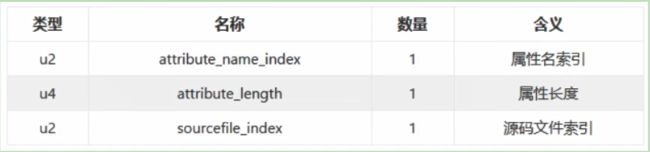
可以看到,其长度总是固定的8个字节
⑨、其他属性
Java 虚拟机中预定义的属性有 20 多个,这里就不一一介绍了,通过上面几个属性的介绍,只要领会其精髓,其他属性的解读也是易如反掌
1.3.9、小结
■ 本章主要介绍了Class文件的基本格式
■ 随着Java平台的不断发展,在将来, Class文件的内容也一定会做进一步的扩充,但是其基本的格式和结构不会做重大调整
■ 从Java虚拟机的角度看,通过Class文件,可以让更多的计算机语言支持]ava虚拟机平台。因此,Class文件结构不仅仅是Java虚拟机的执行入口,更是Java生态圈的基础和核心。
1.4、使用javap指令解析Class文件
14.1、解析字节码的作用
■ 通过反编译生成的字节码文件,我们可以深入的了解java代码的工作机制。但是,自己分析类文件结构太麻烦了!除了使用第三方的 jclasslib 工具之外,orac1e官方也提供了工具: Javap
■ Javap是jdk自带的反解析工具。它的作用就是根据c]ass字节码文件,反解析出当前类对应的code区(字节码指令)、局部变量表、异常表和代码行偏移量映射表、常量池等信息
■ 通过局部变量表,我们可以查看局部变量的作用域范围、所在槽位等信息,甚至可以看到槽位复用等信息
14.2、javac -g 操作
■ 解析字节码文件得到的信息中,有些信息(如局部变量表、指令和代码行偏移量映射表、常量池中方法的参数名称等等)需要在使用 Javac编译成class文件时,指定参数才能输出
■ 比如,你直接 Javac XX.java,就不会在生成对应的局部变量表等信息,如果你使用 Javac -g xx.java就可以生成所有相关信息了。如果你使用的 eclipse或IDEA,则默认情况下, eclipse、IDEA在编译时会帮你生成局部变量表、指令和代码行偏移量映射表等信息的
1.4.3、javap的用法
■ javap 的用法格式:
javap
其中 classes 就是你要反编译的 class 文件
在命令行中直接输入 javap 或 javap -help 可以看到 javap 的 options 有如下选项
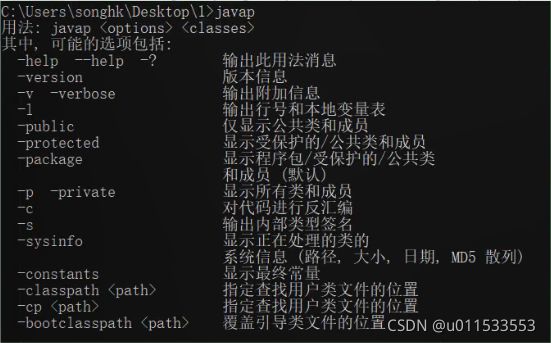
这里重组一下:

一般常用的是 -v -l -c 三个选项。
javap -l 会输出行号和本地变量表信息
javap -c 会对当前 class 字节码进行反编译生成汇编代码
javap -v classxx 除了包含 -c 内容外,还会输出行号、局部变量表信息、常量池等信息。但是不包括私有信息,要想包含私有信息,可以使用 javap -v -p classxx
1.4.4、使用举例
1.4.5、总结
1、通过 Javap命令可以查看一个java类反汇编得到的 Class文件版本号、常量池、访问标识、变量表、指令代码行号表等等信息。不显示类索引、父类索引、接口索引集合、()、()等结构
2、通过对前面例子代码反汇编文件的简单分析,可以发现,一个方法的执行通常会涉及下面几块内存的操作
①、java栈中:局部变量表、操作数栈
②、java堆。通过对象的地址引用去操作
③、常量池
④、其他如帧数据区、方法区的剩余部分等情况,测试中没有显示出来,这里说明一下
3、平常,我们比较关注的是java类中每个方法的反汇编中的指令操作过程,这些指令都是顺序执行的,可以参考官方文档查看每个指令的含义,很简单:
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-6.html
2、字节码指令集与解析举例
2.1、概述
■ Java字节码对于虚拟机,就好像汇编语言对于计算机,属于基本执行指令
■ Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码, Opcode)以及跟随其后的零至多个代表此操作所需参数(称为操作数, Operands)而构成。由于ava虚拟机釆用面向操作数栈而不是寄存器的结构,所以大多数的指令都不包含操作数,只有一个操作码
■ 由于限制了Java虚拟机操作码的长度为一个字节(即0~255),这意味着指令集的操作码总数不可能超过256条
■ 官方文档:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html
■ 熟悉虚拟机的指令对于动态字节码生成、反编译Class文件、 Class文件修补都有着非常重要的价值。因此,阅读字节码作为了解Java虚拟机的基础技能,需要熟练掌握常见指令
2.1.1、执行模型
如果不考虑异常处理的话,那么Java虚拟机的解释器可以使用下面这个伪代码当做最基本的执行模型来理解
do {
自动计算PC寄存器的值加1;
根据PC寄存器的指示位置,从字节码流中取出操作码;
if(字节码存在操作数)从字节码流中取出操作数;
执行操作码所定义的操作;
}while(字节码长度>0);
2.1.2、字节码与数据类型
■ 在Java虚拟机的指令集中,大多数的指令都包含了其操作所对应的数据类型信息。例如,iload指令用于从局部变量表中加载int型的数据到操作数栈中,而fload指令加载的则是float类型的数据
■ 对于大部分与数据类型相关的字节码指令,它们的操作码助记符中都有特殊的字符来表明专门为哪种数据类型服务
● i 代表对int类型的数据操作
● l 代表 long
● s 代表 short
● b 代表 byte
● c 代表 char
● f 代表 float
● d 代表 double
■ 也有一些指令的助记符中没有明确地指明操作类型的字母,如 arraylength指令,它没有代表数据类型的特殊字符,但操作数永远只能是一个数组类型的对象
■ 还有另外一些指令,如无条件跳转指令goto则是与数据类型无关的
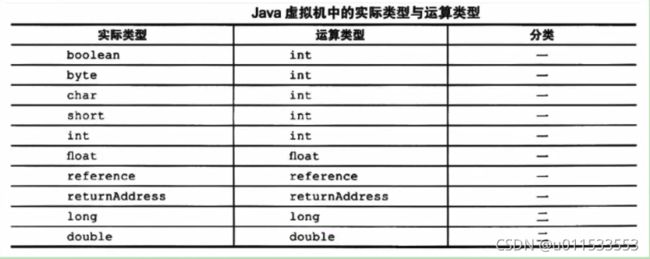
■ 大部分的指令都没有支持整数类型byte、char和 short,甚至没有任何指令支持 boolean类型。编译器会在编译期或运行期将byte和 short类型的数据带符号扩展(sign- Extend)为相应的int类型数据,将 boolean和char类型数据零位扩展(Zero- Extend)为相应的int类型数据。与之类似,在处理 boolean、byte、 short和char类型的数组时,也会转换为使用对应的int类型的字节码指令来处理。因此,大多数对于 boolean、byte、 short和char类型数据的操作,实际上都是使用相应的 int 类型作为运算类型
2.1.3、指令分类
■ 由于完全介绍和学习这些指令需要花费大量时间。为了让大家能够更快地熟悉和了解这些基本指令,这里将JWM中的字节码指令集按用途大致分成9类
● 加载与存储指令
● 算术指令
● 类型转换指令
● 对象的创建与访问指令
● 方法调用与返回指令
● 操作数栈管理指令
● 比较控制指令
● 异常处理指令
● 同步控制指令
■ (说在前面)在做值相关操作时:
● 一个指令,可以从局部变量表、常量池、堆中对象、方法调用、系统调用中等取得数据,这些数据(可能是值可能是对象的引用)被压入操作数栈
● 一个指令,也可以从操作数栈中取出一到多个值(pop多次),完成赋值、加减乘除、方法传参、系统调用等等操作
2.2、加载与存储指令
1、作用
加载和存储指令用于将数据从栈帧的局部变量表和操作数栈之间来回传递
2、常用指令
| 常用指令 |
|---|
| 1、【局部变量压栈指令】将一个局部变量加载到操作数栈:xload、xload_(其中 x 为i、l、f、d、a,n 为0 到 3) |
| 2、【常量入栈指令】将一个常量加载到操作数栈: bipush、 sipush、ldc、ldc_w、ldc2_w、aconst_null、 iconst_m1、iconst_、 lconst_、 fconst_、 dconst_ |
| 3、【出栈装入局部变量表指令】将一个数值从操作数栈存储到局部变量表:ⅹ_store、xstore_(其中x为 i、l、f、d、a,n为0到3); xastore(其中x为 i、l、f、d、a、b、c、s) |
| 4、扩充局部变量表的访问索引的指令:wide |
上面所列举的指令助记符中,有一部分是以尖括号结尾的(例如iload_)。这些指令助记符实际上代表了一组指令(例如 iload_代表了 iload_0、 iload_1、 iload_2和 iload_3这几个指令)。这几组指令都是某个带有一个操作数的通用指令(例如 iload)的特殊形式,对于这若干组特殊指令来说,它们表面上没有操作数,不需要进行取操作数的动作,但操作数都隐含在指令中
比如:
iload_0/iload 0:将局部变量表中索引为 0 位置上的数据压入操作数栈中
除此之外,它们的语义与原生的通用指令完全一致(例如iload_0的语义与操作数为0时的iload指令语义完全一致)。在尖括号之间的字母指定了指令隐含操作数的数据类型,代表非负的整数,代表是int类型数据,代表long类型,代表float类型,代表 double类型
操作 byte、char、short和boolean类型数据时,经常用int类型的指令来表示
复习:再谈操作数栈与局部变量表
1、操作数栈(Operand Stacks)
我们知道,Java字节码是Java虚拟机所使用的指令集。因此,它与Java虚拟机基于栈的计算模型是密不可分的在解释执行过程中,每当为Java方法分配栈桢时,Java虚拟机往往需要开辟一块额外的空间作为操作数栈,来存放计算的操作数以及返回结果
具体来说便是:执行每一条指令之前,Java虚拟机要求该指令的操作数已被压入操作数栈中。在执行指令时,Java虚拟机会将该指令所需的操作数弹出,并且将指令的结果重新压入栈中

以加法指令 iadd 为例。假如在执行该指令前,栈顶的两个元素分别为 int 值 1 和 int 值 2,那么 iadd 指令将弹出这两个 int,并将求得的和 int 值 3 压入栈中

2、局部变量表(Local Variables)
Java方法栈桢的另外一个重要组成部分则是局部变量区,字节码程序可以将计算的结果缓存在局部变量区之中。
实际上,Java虚拟机将局部变量区当成一个数组,依次存放this指针(仅非静态方法),所传入的参数,以及字节码中的局部变量
和操作数栈一样,long类型以及 double类型的值将占据两个单元,其余类型仅占据一个单元
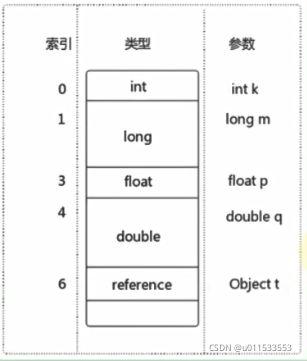
举例:
public void foo(long l, float f) {
{
int i = 0;
}
{
String s = "Hello, World";
}
}
对应的图示:

在栈帧中,与性能调优关系最为密切的部分就是局部变量表。局部变量表中的变量也是重要的垃圾回收根节点,只要被局部变量表中直接或间接引用的对象都不会被回收
在方法执行时,虚拟机使用局部变量表完成方法的传递
2.2.1、局部变量压栈指令
局部变量压栈指令将给定的局部变量表中的数据压入操作数栈。
这类指令大体可以分为:
● xload_(x为 i、l、f、d、a,n为0到3)
● xload(x为 i、l、f、d、a)
说明:在这里,x的取值表示数据类型
指令 xload_n表示将第n个局部变量压入操作数栈,比如 iload_1、 fload_0、 aload_0等指令。其中 aload_n表示将个对象引用压栈
指令xload通过指定参数的形式,把局部变量压入操作数栈,当使用这个命令时,表示局部变量的数量可能超过了4个,比如指令iload、fload等
2.2.2、常量入栈指令
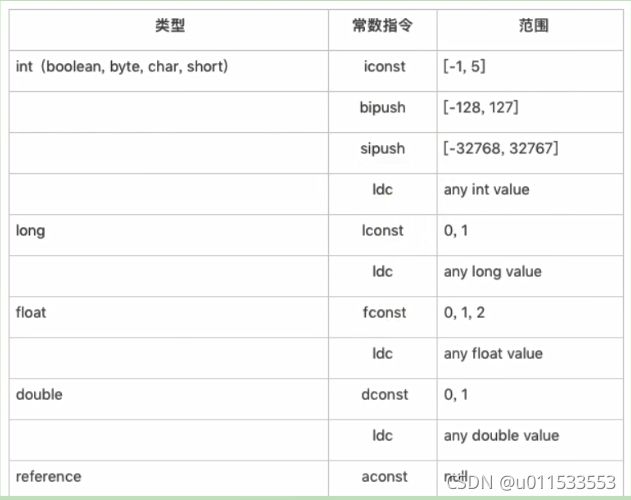
■ 常量入栈指令的功能是将常数压入操作数栈,根据数据类型和入栈内容的不同,又可以分为 const系列、push系列和ldc指令
■ 指令 const系列:用于对特定的常量入栈,入栈的常量隐含在指令本身里。指令有: iconst_(i从-1到5)、lconst_(l从0到1)、fconst_(f从0到2)、 dconst_(d从0到1)、 aconst_null,比如:
iconst_m1将-1压入操作数栈
iconst_x(x为0到5)将x压入栈
lconst_0、lcons_1分别将长整数0和1压入栈
fconst_0、 fconst_1、 fconst_2分别将浮点数0、1、2压入栈
dconst_0和 dconst_1分别将double型0和1压入栈
aconst_null将null压入操作数栈
从指令的命名上不难找出规律,指令助记符的第一个字符总是喜欢表示数据类型,i 表示整数,l 表示长整数,f表示浮点数,d表示双精度浮点,习惯上用a表示对象引用。如果指令隐含操作的参数,会以下划线形式给出
■ push系列:主要包括 bipush和 sipush。它们的区别在于接收数据类型的不同, bipush接收8位整数作为参数sipush接收16位整数,它们都将参数压入栈
■ 指令ldc系列:如果以上指令都不能满足需求,那么可以使用万能的ldc指令,它可以接收一个8位的参数,该参数指向常量池中的int、float或者 String的索引,将指定的内容压入堆栈。
类似的还有 ldc_w,它接收两个 8 为参数,能支持的所有范围大于 ldc。
如果要压入的元素是 long 或者 double 类型的,则使用 ldc2_w 指令,使用方式都是类似的
■ 总结如下:
2.2.3、出栈装入局部变量表指令
■ 岀栈装入局部变量表指令用于将操作数栈中栈顶元素弹岀后,装入局部变量表的指定位置,用于给局部变量赋值
■ 这类指令主要以 store的形式存在,比如 xstore(x为 i、l、f、d、a)、 xstore_n(x为 i、l、f、d、a,n为0至3)
● 其中,指令 istore_n将从操作数栈中弹岀一个整数,并把它赋值给局部变量索引n位置
● 指令 xstore由于没有隐含参数信息,故需要提供一个byte类型的参数类指定目标局部变量表的位置
说明
■ 一般说来,类似像 store这样的命令需要带一个参数,用来指明将弹岀的元素放在局部变量表的第几个位置。但是,为了尽可能压缩指令大小,使用专门的 istore1指令表示将弹出的元素放置在局部变量表第1个位置。类似的还有istore_0、 istore_2、 istore_3,它们分别表示从操作数栈顶弹出一个元素,存放在局部变量表第0、2、3个位置
■ 由于局部变量表前几个位置总是非常常用,因此这种做法虽然增加了指令数量,但是可以大大压缩生成的字节码的体积。如果局部变量表很大,需要存储的槽位大于3,那么可以使用 istore指令,外加一个参数,用来表示需要存放的槽位位置
2.3、算术指令
1、作用:
算术指令用于对两个操作数栈上的值进行某种特定运算,并把结果重新压入操作数栈
2、分类:
大体上算术指令可以分为两种:对整型数据进行运算的指令与对浮点类型数据进行运算的指令
3、byte、short、char和boolean类型说明
在每一大类中,都有针对Java虚拟机具体数据类型的专用算术指令。但没有直接支持byte、 short、char和 boolean-类型的算术指令,对于这些数据的运算,都使用int类型的指令来处理。此外,在处理 boolean、byte、 short和char类型的数组时,也会转换为使用对应的主nt类型的字节码指令来处理
4、运算时的溢出
数据运算可能会导致溢岀,例如两个很大的正整数相加,结果可能是一个负数。其实Java虛拟机规范并无明确规定过整型数据溢岀的具体结果,仅规定了在处理整型数据时,只有除法指令以及求余指令中当出现除数为θ时会导致虚拟机抛出异常 ArithmeticException
5、运算模式
● 向最接近数舍入模式:Jw要求在进行浮点数计算时,所有的运算结果都必须舍入到适当的精度,非精确结果必须舍入为可被表示的最接近的精确值,如果有两种可表示的形式与该值一样接近,将优先选择最低有效位为零的
● 向零舍入模式:将浮点数转换为整数时,采用该模式,该模式将在目标数值类型中选择一个最接近但是不大于原值的数字作为最精确的舍入结果
6、NaN值使用
当一个操作产生溢出时,将会使用有符号的无穷大表示,如果某个操作结果没有明确的数学定义的话,将会使用NaN值来表示。而且所有使用NaN值作为操作数的算术操作,结果都会返回NaN
2.3.1、所有算术指令
所有的算术指令包括:
加法指令:iadd、ladd、fadd、dadd
减法指令:isub、lsub、fsub、dsub
乘法指令:imul、lmul、fmul、dmul
除法指令:idiv、ldiv、fdiv、ddiv
求余指令:irem、lrem、frem、drem //remainder:余数
取反指令:ineg、lneg、fneg、dneg //negation:取反
自增指令:iinc
位运算指令,又可分为:
● 位移指令:ishl、ishr、iushr、lshl、lshr、lushr
● 按位或指令:ior、lor
● 按位与指令:iand、land
● 按位异或指令:ixor、lxor
比较指令:dcmpg、dcmpl、fcmpg、fcmpl、lcmp
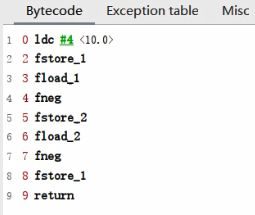
举例1:

举例2:

举例3:
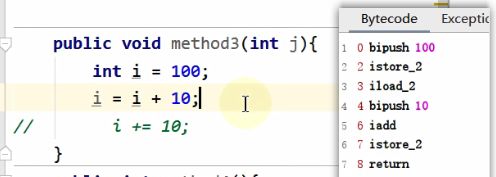
举例4:

①、举例
②、一个曾经的案例1
代码:
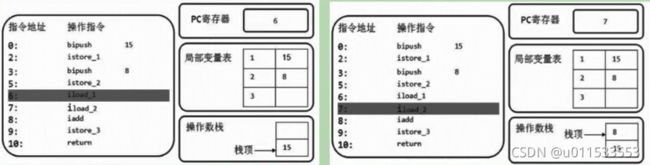
public void add() {
byte i = 15;
int j = 8;
int k = i + j;
}
字节码对应的内存解析:



③、一个曾经的案例2
2.3.2、比较指令的说明
比较指令的说明
● 比较指令的作用是比较栈顶两个元素的大小,并将比较结果入栈
● 比较指令有: dcmpg,dcmpl、 fcmpg、fcmpl、lcmp
○ 与前面讲解的指令类似,首字符d表示double类型,f表示float,l表示long
● 对于 double和 float类型的数字,由于NaN的存在,各有两个版本的比较指令。以float为例,有 fcmpg和fcmpl两个指令,它们的区别在于在数字比较时,若遇到NaN值,处理结果不同
● 指令dcmpl和 dampg也是类似的,根据其命名可以推测其含义,在此不再赘述
● 指令lcmp针对long型整数,由于long型整数没有NaN值,故无需准备两套指令
举例:
指令 fcmpg和fcmpl都从栈中弹出两个操作数,并将它们做比较,设栈顶的元素为v2,栈顶顺位第2位的元素为v1,若v1=v2,则压入0;若v1>v2则压入1;若v1 两个指令的不同之处在于,如果遇到NaN值, fcmpg会压入1,而fcmpl会压入-1 类型转换指令说明 ■ 类型转换指令可以将两种不同的数值类型进行相互转换 ■ 这些转换操作一般用于实现用户代码中的显式类型转换操作,或者用来处理字节码指令集中数据类型相关指令无法与数据类型一一对应的问题 1、转换规则: Java虚拟机直接支持以下数值的宽化类型转换( widening numeric conversion,小范围类型向大范围类型的安全转换)。也就是说,并不需要指令执行,包括: ● 从int类型到long、ffoat或者double类型。对应的指令为:i2l、i2f、i2d ● 从long类型到float、 double类型。对应的指令为:l2f、l2d ● 从float类型到double类型。对应的指令为:f2d 简化为: int–>long–> float–>double 2、精度损失问题 2.1、宽化类型转换是不会因为超过目标类型最大值而丢失信息的,例如,从int转换到long,或者从int转换到double,都不会丢失任何信息,转换前后的值是精确相等的 2.2、从int、long类型数值转换到 float,或者long类型数值转换到 double时,将可能发生精度丢失——可能丢失掉几个最低有效位上的值,转换后的浮点数值是根据IEEE754最接近舍入模式所得到的正确整数值 尽管宽化类型转换实际上是可能发生精度丢失的,但是这种转换永远不会导致Java虚拟机抛出运行时异常 3、补充说明 从byte、char和 short类型到int类型的宽化类型转换实际上是不存在的。对于byte类型转为int,虚拟机并没有做实质性的转化处理,只是简单地通过操作数栈交换了两个数据。而将byte转为long时,使用的是i2l,可以看到在内部byte在这里已经等同于int类型处理,类似的还有 short类型,这种处理方式有两个特点一方面可以减少实际的数据类型,如果为 short和byte都准备一套指令,那么指令的数量就会大增,而虚拟机目前的设计上,只愿意使用一个字节表示指令,因此指令总数不能超过256个,为了节省指令资源,将 short和byte当做int处理也在情理之中 另一方面,由于局部变量表中的槽位固定为32位,无论是byte或者 short存入局部变量表,都会占用32位空间。从这个角度说,也没有必要特意区分这几种数据类型 1、转换规则 Java虚拟机也直接支持以下窄化类型转换 ● 从int类型至byte、 short或者char类型。对应的指令有:i2b、i2c、i2s ● 从long类型到 int类型。对应的指令有:l2i ● 从float类型到int或者long类型。对应的指令有:f2l、f2l ● 从double类型到int、long或者float类型。对应的指令有:d2i、d2l、d2f 2、精度损失问题 窄化类型转换可能会导致转换结果具备不同的正负号、不同的数量级,因此,转换过程很可能会导致数值丢失精度 尽管数据类型窄化转换可能会发生上限溢岀、下限溢岀和精度丢失等情况,但是Java虚拟杋规范中明确规定数值类型的窄化转换指令永远不可能导致虚拟机抛出运行时异常 3、补充说明 3.1、当将一个浮点值窄化转换为整数类型T(T限于int或long类型之一)的时候,将遵循以下转换规则 ● 如果浮点值是NaN,那转换结果就是int或long类型的0 ● 如果浮点值不是无穷大的话,浮点值使用IEEE754的向零舍入模式取整,获得整数值v,如果v在目标类型T(int或long)的表示范围之内,那转换结果就是v。否则,将根据v的符号,转换为T所能表示的最大或者最小正数 3.2、当将一个 double类型窄化转换为 float类型时,将遵循以下转换规则: 通过向最接近数舍入模式舍入一个可以使用float类型表示的数字。最后结果根据下面这3条规则判断: ● 如果转换结果的绝对值太小而无法使用float来表示,将返回 float类型的正负零 ● 如果转换结果的绝对值太大而无法使用float来表示,将返回float类型的正负无穷大 ● 对于double类型的NaN值将按规定转换为float类型的NaN值 Java 是面向对象的程序设计语言,虚拟机平台从字节码层面就对面向对象做了深层次的支持。有一系列指令专门用于对象操作,可进一步细分为创建指令、字段访问指令、数组操作指令、类型检查指令 虽然类实例和数组都是对象,但]ava虚拟机对类实例和数组的创建与操作使用了不同的字节码指令 1、创建类实例的指令 创建类实例的指令:new 它接收一个操作数,为指向常量池的索引,表示要创建的类型,执行完成后,将对象的引用压入栈 2、创建数组的指令 创建数组的指令: newarray、 anewarray、 multianewarray ● newarray:创建基本类型数组 ● anewarray:创建引用类型数组 ● multianewarray:创建多维数组 上述创建指令可以用于创建对象或者数组,由于对象和数组在Java中的广泛使用,这些指令的使用频率也非常高 对象创建后,就可以通过对象访问指令获取对象实例或数组实例中的字段或者数组元素 ● 访问类字段( static字段,或者称为类变量)的指令: getstatic、 putstatic ● 访问类实例字段(非 static字段,或者称为实例变量)的指令: getfield、 putfield 举例: 以 getstatic指令为例,它含有一个操作数,为指向常量池的Fieldref索引,它的作用就是获取 Fieldref指定的对象或者值,并将其压入操作数栈 对应的字节码指令: 1、指令 数组操作指令主要有:xastore和xaload指令。具体为: ● 把一个数组元素加载到操作数栈的指令:baload、caload、saload、iaload、laload、faload、daload、aaload ● 将一个操作数栈的值存储到数组元素中的指令:bastore、castore、sastore、iastore、lastore、fastore、dastore、aastore 即: ● 取数组长度的指令:arraylength ○ 该指令弹出栈顶的数组元素,获取数组的长度,将长度压入栈 2、说明 ● 指令 xaload 表示将数组的元素压栈,比如 saload、caload 分别表示压入 short 数组和 char 数组。指令 xaload 在执行时,要求操作数中栈顶元素为数组索引 i,栈顶顺位第 2 个元素为数组引用 a,该指令会弹出栈顶这两个元素,并将 a[i] 重新压入堆栈 ● xastore 则专门针对数组操作,以 iastore 为例,它用于给一个 int 数组的给定索引赋值。在 iastore 执行前,操作数栈顶需要以此准备 3个元素:值、索引、数组引用,iastore 会弹出这 3 个值,并将值赋给数组中指定索引的位置 检查类实例或数组类型的指令:instanceof、checkcast ● 指令 checkcast 用于检查类型强制转换是否可以进行。如果可以进行,那么 checkcast 指令不会改变操作数栈,否则它会抛出 ClassCastException 异常 ● 指令 instanceof 用来判断给定对象是否是某一个类的实例,它会将判断结果压入操作数栈 1.方法调用指令: invokevirtual、 invokeinterface、 invokespecial、 invokestatic、 invokedynamic 以下5条指令用于方法调用: ● invokevirtual指令用于调用对象的实例方法,根据对象的实际类型进行分派(虚方法分派),支持多态。这也是Java语言中最常见的方法分派方式 ● invokeinterface指令用于调用接口方法,它会在运行时搜索由特定对象所实现的这个接口方法,并找出适合的方法进行调用 ● invokespecial指令用于调用一些需要特殊处理的实例方法,包括实例初始化方法(构造器)、私有方法和父类方法。这些方法都是静态类型绑定的,不会在调用时进行动态派发 ● invokestatic指令用于调用命名类中的类方法( static方法)。这是静态绑定的 ● invokedynamic:调用动态绑定的方法,这个是JDK1.7后新加入的指令。用于在运行时动态解析出调用点限定符所引用的方法,并执行该方法。前面4条调用指令的分派逻辑都固化在java虚拟机内部,而invokedynamic指令的分派逻辑是由用户所设定的引导方法决定的 ■ 方法调用结束前,需要进行返回。方法返回指令是根据返回值的类型区分的 ● 包括ireturn(当返回值是boolean、byte、char、short和int类型时使用)、lreturn、freturn、dreturn和areturn ● 另外还有一条return 指令供声明为void的方法、实例初始化方法以及类和接口的类初始化方法使用 举例: 通过ireturn指令,将当前函数操作数栈的顶层元素弹出,并将这个元素压入调用者函数的操作数栈中(因为调用者非常关心函数的返回值),所有在当前函数操作数栈中的其他元素都会被丢弃 ■ 如果当前返回的是synchronized方法,那么还会执行一个隐含的monitorexit指令,退出临界区。如果当前返回的是 synchronized 方法,那么还会执行一个隐含的 monitorexit 指令,退出临界区。最后,会丢弃当前方法的整个栈,恢复调用者的帧,并将控制权转交给调用者 ■ 如同操作一个普通数据结构中的堆栈那样,JVM提供的操作数栈管理指令,可以用于直接操作操作数栈的指令 ■ 这类指令包括如下内容: ● 将一个或两个元素从栈顶弹出,并且直接废弃:pop,pop2; ● 复制栈顶一个或两个数值并将复制值或双份的复制值重新压入栈顶:dup,dup2,dup_x1,dup2_x1,dup_x2,dup2_x2; ● 将栈最顶端的两个Slot数值位置交换:swap。Java虚拟机没有提供交换两个64位数据类型(long、 double)数值的指令 ● 指令nop,是一个非常特殊的指令,它的字节码为0x00。和汇编语言中的nop一样,它表示什么都不做。这条指令一般可用于调试、占位等 这些指令属于通用型,对栈的压入或者弹出无需指明数据类型 说明 ■ 不带_x的指令是复制栈顶数据并压入栈顶。包括两个指令,dup和dup2。dup的系数代表要复制的Slot个数 ● dup开头的指令用于复制1个Slot的数据。例如1个int或1个 reference类型数据 ● dup2开头的指令用于复制2个Slot的数据。例如1个long,或2个int,或1个int + 1个 float 类型数据 ■ 带 _x 的指令是复制栈顶数据并插入栈顶以下的某个位置。共有4个指令,dup_x1,dup2_x1,dup_x2,dup2_x2。对于带 _x的复制插入指令,只要将指令的dup和x的系数相加,结果即为需要插入的位置。因此 ● dup_x1插入位置:1+1=2,即栈顶2个Slot下面 ● dup_x2插入位置:1+2=3,即栈顶3个Slot下面 ● dup2_x1插入位置:2+1=3,即栈顶3个Slot下面 ● dup2_x2插入位置:2+2=4,即栈顶4个Slot下面 ■ pop:将栈顶的1个Slot数值出栈。例如1个 short类型数值 ■ pop:将栈顶的2个Slot数值出栈。例如1个dub1e类型数值,或者2个int类型数值 程序流程离不开条件控制,为了支持条件跳转,虚拟机提供了大量字节码指令,大体可以分为: 1)、比较指令 2)、条件跳转指令 3)、比较条件跳转指令 4)、多条件分支跳转指令 5)、无条件跳转指令等 比较指令的介绍在 2.3.2 章节 ■ 条件跳转指令通常和比较指令结合使用。在条件跳转指令执行前,一般可以先用比较指令进行栈顶元素的准备,然后进行条件跳转 ■ 条件跳转指令有:ifeq,iflt,ifle,ifne,ifgt,ifge,ifnull, ifnonnull。这些指令都接收两个字节的操作数,用于计算跳转的位置(16位符号整数作为当前位置的offset)。它们的统一含义为:弹出栈顶元素,测试它是否满足某一条件,如果满足条件,则跳转到给定位置 具体说明 注意: 1、与前面运算规则一致: ● 对于 boolean、byte、char、short 类型的条件分支比较操作,都是使用 int 类型的比较指令完成 ● 对于 long、float、double 类型的条件分支比较操作,则会先执行相应类型的比较运算指令,运算指令会返回一个整型值到操作数栈中,随后再执行 int 类型的条件分支比较操作来完成整个分支跳转 2、由于各类型的比较最终都会转为 int 类型的比较操作,所有 Java 虚拟机提供的 int 类型的条件分支指令是最为丰富和强大的 ■ 比较条件跳转指令类似于比较指令和条件跳转指令的结合体,它将比较和跳转两个步骤合二为一 ■ 这类指令有:if_icmpeq、if_icmpne、if_icmplt、if_icmpgt、if_icmple、if_icmpge、if_acmpeq和if_acmpne。其中指令助记符加上“if_”后,以字符“i”开头的指令针对int型整数操作(也包括short和byte类型),以字符“a”开头的指令表示对象引用的比较 具体说明 ■ 这些指令都接收两个字节的操作数作为参数,用于计算跳转的位置。同时在执行指令时,栈顶需要准备两个元素进行比较。指令执行完成后,栈顶的这两个元素被清空,且没有任何数据入栈。如果预设条件成立,则执行跳转,否则,继续执行下一条语句。 ■ 多条件分支跳转指令是专为 switch-case语句设计的,主要有 tableswitch和 lookupswitch ■ 从助记符上看,两者都是 switch语句的实现,它们的区别 ● tableswitch要求多个条件分支值是连续的,它内部只存放起始值和终止值,以及若干个跳转偏移量,通过给定的操作数 index,可以立即定位到跳转偏移量位置,因此效率比较高 ● 指令1 ookupswitch内部存放着各个离散的case- offset对,每次执行都要搜索全部的case- offset对,找到匹配的case值,并根据对应的 offset计算跳转地址,因此效率较低 ■ 指令 tableswitch的示意图如下图所示。由于 tableswitch的case值是连续的,因此只需要记录最低值和最高值,以及每项对应的 offset偏移量,根据给定的 index 值通过简单的计算即可直接定位到offset ■ 指令 lookupswitch 处理的是离散的 case 值,但是出于效率考虑,将 case-offset 对按照 case 值大小排序,给定 index 时,需要查找与 index 相等的 case,获得其 offset,如果找不到则跳转 default。指令 lookupswitch 如下图所示: ■ JDK7 以后对 switch 引入 string 类型 ■ 目前主要的无条件跳转指令为goto。指令goto接收两个字节的操作数,共同组成一个带符号的整数,用于指定指令的偏移量指令执行的目的就是跳转到偏移量给定的位置处 ■ 如果指令偏移量太大,超过双字节的带符号整数的范围,则可以使用指令goto_w,它和goto有相同的作用,但是它接收4个字节的操作数,可以表示更大的地址范围 ■ 指令jsr、jsr_w、ret虽然也是无条件跳转的,但主要用于try-finally语句,且已经被虚拟机逐渐废弃,故不在这里介绍这两个指令 ■ athrow指令 ● 在Java程序中显示抛出异常的操作( throw语句)都是由 athrow指令来实现 ● 除了使用 throw语句显示抛出异常情况之外,jvm 规范还规定了许多运行时异常会在其他Java虚拟机指令检测到异常状况时自动抛出。例如,在之前介绍的整数运算时,当除数为零时,虚拟机会在idiv或 ldiv指令中抛出ArithmeticException异常 ■ 注意 正常情况下,操作数栈的压入弹出都是一条条指令完成的。唯一的例外情况是在抛异常时,Java虚拟机会清除操作数栈上的所有内容,而后将异常实例压入调用者操作数栈上 ■ 异常及异常的处理: 过程一:异常对象的生成过程 —> throw(手动/自动) —> 指令:athrow 过程二:异常的处理:抓抛模型:try - catch - finally —> 使用异常表 1、处理异常 在Java虚拟机中,处理异常( catch语句)不是由字节码指令来实现的(早期使用jsr、ret指令),而是采用异常表来完成的 2、异常表 ■ 如果一个方法定义了一个try- catch或者try-finally的异常处理,就会创建一个异常表。它包含了每个异常处理或者finally块的信息。异常表保存了每个异常处理信息。比如: ● 起始位置 ● 结束位置 ● 程序计数器记录的代码处理的偏移地址 ● 被捕获的异常类在常量池中的索引 ■ 当一个异常被抛岀时,Jvm会在当前的方法里寻找一个匹配的处理,如果没有找到,这个方法会强制结束并弹出当前栈帧并且异常会重新抛给上层调用的方法(在调用方法栈帧)。如果在所有栈帧弹出前仍然没有找到合适的异常处理,这个线程将终止。如果这个异常在最后一个非守护线程里抛出,将会导致Jvm自己终止,比如这个线程是个main线程 ■ 不管什么时候抛出异常,如果异常处理最终匹配了所有异常类型,代码就会继续执行。在这种情况下,如果方法结束后没有抛出异常,仍然执行finally块,在 return前,它直接跳到finally块来完成目标 组成:Java 虚拟机支持两种同步结构:方法级的同步和方法内部一段指令序列的同步,这两张同步都是使用 monitor 来支持的 ■ 方法级的同步:是隐式的,即无须通过字节码指令来控制,它实现在方法调用和返回操作之中。虚拟机可以从方法常量池的方法表结构中的 ACC_SYNCHRONIZED访问标志得知一个方法是否声明为同步方法 ■ 当调用方法时,调用指令将会检查方法的 ACC_SYNCHRONIZED访问标志是否设置 ● 如果设置了,执行线程将先持有同步锁,然后执行方法。最后在方法完成(无论是正常完成还是非正常完成)时释放同步锁 ● 在方法执行期间,执行线程持有了同步锁,其他任何线程都无法再获得同一个锁 ● 如果一个同步方法执行期间抛出了异常,并且在方法内部无法处理此异常,那这个同步方法所持有的锁将在异常抛到同步方法之外时自动释放 ■ 举例: 说明:这段代码和普通的无同步操作的代码没有什么不同,没有使用 monitorenter和 monitorexit 进行同步区控制。这是因为对于同步方法而言,当虚拟机通过方法的访问标示符判断是一个同步方法时,会自动在方法调用前进行加锁,当同步方法执行完毕后,不管方法是正常结束还是有异常抛出,均会由虚拟机释放这个锁。因此,对于同步方法而言, monitorenter和monitorexit指令是隐式存在的,并未直接出现在字节码中 ■ 同步一段指令集序列:通常是由java中的 synchronized语句块来表示的。jvm的指令集有 monitorenter和monitorexit两条指令来支持 synchronized关键字的语义 ■ 当一个线程进入同步代码块时,它使用 monitorenter指令请求进入。如果当前对象的监视器计数器为0,则它会被准许进入,若为1,则判断持有当前监视器的线程是否为自己,如果是,则进入,否则进行等待,直到对象的监视器计数器为,才会被允许进入同步块 ■ 当线程退岀同步块时,需要使用 monitorexit声明退岀。在]ava虚拟机中,任何对象都有一个监视器与之相关联,用来判断对象是否被锁定,当监视器被持有后,对象处于锁定状态 ■ 指令 monitorenter和 monitorexit在执行时,都需要在操作数栈顶压入对象,之后 monitorenter和 monitorexit的锁定和释放都是针对这个对象的监视器进行的 ■ 下图展示了监视器如何保护临界区代码不同时被多个线程访问,只有当线程4离开临界区后,线程1、2、3才有可能进入。 ■ 举例: 代码: 说明: ● 编译器必须确保无论方法通过何种方式完成,方法中调用过的每条monitorenter指令都必须执行其对应的 monitorexit指令,而无论这个方法是正常结束还是异常结束 ● 为了保证在方法异常完成时 monitorenter和 monitorexit指令依然可以正确配对执行,编译器会自动产生一个异常处理器这个异常处理器声明可处理所有的异常,它的目的就是用来执行 monitorexit 指令 ■ 在 Java 中数据类型分为基本数据类型和引用数据类型。基本数据类型由虚拟机预先定义,引用数据类型则需要进行类的加载。 ■ 按照Java 虚拟机规范,从 class文件加载到内存中的类,到类卸载出内存为止,它的整个生命周期包括如下7个阶段: 其中,验证、准备、解析 3 个部分统称为链接(Linking) ■ 从程序中类的使用过程看 加载的理解 所谓加载,简而言之就是将Java类的字节码文件加载到机器内存中,并在内存中构建出Java类的原型----类模板对象。所谓类模板对象,其实就是Java类在Jvm内存中的一个快照,Jvm将从字节码文件中解析岀的常量池、类字段、类方法等信息存储到类模板中,这样Jvm在运行期便能通过类模板而获取Java类中的任意信息,能够对Java类的成员变量进行遍历,也能进行Java方法的调用 反射的机制即基于这一基础。如果Jvm没有将Java类的声明信息存储起来,则Jvm在运行期也无法反射 加载完成的操作 加载阶段,简言之,查找并加载类的二进制数据,生成Class的实例 在加载类时,Java虚拟机必须完成以下3件事情 ● 通过类的全名,获取类的二进制数据流 ● 解析类的二进制数据流为方法区内的数据结构(Java类模型) ● 创建java.lang.Class类的实例,表示该类型。作为方法区这个类的各种数据的访问入口 ■ 对于类的二进制数据流,虚拟机可以通过多种途径产生或获得。(只要所读取的字节码符合JVM规范即可) ● 虚拟机可能通过文件系统读入一个class后缀的文件(最常见) ● 读入jar、zip等归档数据包,提取类文件 ● 事先存放在数据库中的类的二进制数据 ● 使用类似于HTTP之类的协议通过网络进行加载 ● 在运行时生成一段class的二进制信息等 ■ 在获取到类的二进制信息后,Java虚拟机就会处理这些数据,并最终转为一个java.lang.Class的实例 ■ 如果输入数据不是ClassFile的结构,则会抛出 ClassFormatError 1、类模型的位置 加载的类在JVM中创建相应的类结构,类结构会存储在方法区(DK1.8之前:永久代;JDK1.8及之后:元空间) 2、Class实例的位置 类将 .class文件加载至元空间后,会在堆中创建一个java.lang.Class对象,用来封装类位于方法区内的数据结构,该class对象是在加载类的过程中创建的,每个类都对应有一个Class类型的对象 3、图示 外部可以通过访问代表 Order 类的 Class 对象来获取 Order 的类数据结构 4、再说明 Class 类的构造器方法是私有的,只有 JVM 能够创建 java.lang.Class 实例是访问类型元数据的接口,也是实现反射的关键数据、入口。通过 Class 类提供的接口,可以获取目标类所关联的 .class 文件中具体的数据结构:方法、字段等信息 ■ 创建数组类的情况稍微有些特殊,因为数组类本身并不是由类加载器负责创建,而是由JVM在运行时根据需要而直接创建的,但数组的元素类型仍然需要依靠类加载器去创建。创建数组类(下述简称A)的过程: 1、如果数组的元素类型是引用类型,那么就遵循定义的加载过程递归加载和创建数组A的元素类型 2、JVM使用指定的元素类型和数组维度来创建新的数组类 ■ 如果数组的元素类型是引用类型,数组类的可访问性就由元素类型的可访问性决定。否则数组类的可访问性将被缺省定义为public 当类加载到系统后,就开始连接操作,验证是连接操作的第一步; 它的目的是保证加载字节码是合法、合理并符合规范的; 验证的步骤比较复杂,实际要验证的项目也很繁多,大体上Java虚拟机需要做以下检查,如图所示: 整体说明 验证的内容则涵盖了类数据信息的格式验证、语义检査、字节码验证,以及符号引用验证等 ● 其中格式验证会和加载阶段一起执行。验证通过之后,类加载器才会成功将类的二进制数据信息加载到方法 区中 ● 格式验证之外的验证操作将会在方法区中进行 链接阶段的验证虽然拖慢了加载速度,但是它避免了在字节码运行时还需要进行各种检查。(磨刀不误砍柴工) 具体说明 1、格式验证:是否以魔数 OXCAFEBABE开头,主版本和副版本号是否在当前Java虚拟机的支持范围内,数据中每一个项是否都拥有正确的长度等 2、Java虚拟机会进行字节码的语义检査,但凡在语义上不符合规范的,虚拟机也不会给予验证通过。比如 ● 是否所有的类都有父类的存在(在Java里,除了 Object外,其他类都应该有父类) ● 是否一些被定义为fina1的方法或者类被重写或继承了 ● 非抽象类是否实现了所有抽象方法或者接口方法 ● 是否存在不兼容的方法(比如方法的签名除了返回值不同,其他都一样,这种方法会让虚拟机无从下手调度; abstract情况下的方法,就不能是final的了) 3、Java虚拟机还会进行字节码验证,字节码验证也是验证过程中最为复杂的一个过程。它试图通过对字节码流的分析,判断字节码是否可以被正确地执行。比如 ● 在字节码的执行过程中,是否会跳转到一条不存在的指令 ● 函数的调用是否传递了正确类型的参数 ● 变量的赋值是不是给了正确的数据类型等 栈映射帧( StackMapTable)就是在这个阶段,用于检测在特定的字节码处,其局部变量表和操作数栈是否有着正确的数据类型但遗憾的是,100%准确地判断一段字节码是否可以被安全执行是无法实现的,因此,该过程只是尽可能地检查出可以预知的明显的问题。如果在这个阶段无法通过检査,虚拟机也不会正确装载这个类。但是,如果通过了这个阶段的检查,也不能说明这个类是完全没有问题的 在前面3次检查中,已经排除了文件格式错误、语义错误以及字节码的不正确性。但是依然不能确保类是没有问题的 4、校验器还将进行符号引用的验证。 Class文件在其常量池会通过字符串记录自己将要使用的其他类或者方法。因此,在验证阶段,虚拟机就会检査这些类或者方法确实是存在的,并且当前类有权限访问这些数据,如果一个需要使用类无法在系统中找到,则会抛出 NoClassDefFoundError,如果一个方法无法被找到,则会抛出 NoSuchMethodError 此阶段在解析环节才会执行 准备阶段(Preparation),简言之,为类的静态变量分配内存,并将其初始化为默认值 当一个类验证通过时,虚拟机就会进入准备阶段。在这个阶段,虚拟机就会为这个类分配相应的内存空间,并设置默认初始值。Java 虚拟机为各类型变量默认的初始值如表所示: 注意:Java并不支持 boolean 类型,对于 boolean 类型,内部实现是 int,由于 int 的默认值是 0,故对应的 boolean 的默认值就是 false 注意: 1、这里不包含基本数据类型的字段用 static final 修饰的情况,因为 final 在编译的时候就会分配了,准备阶段会显式赋值 2、注意这里不会为实例变量分配初始化,类变量会分配在方法区中,而实例变量是会随着对象一起分配到Java堆中 3、在这个阶段并不会像初始化阶段中那样会有初始化或者代码被执行 在准备阶段完成后,就进入了解析阶段。 解析阶段( Resolution),简言之,将类、接口、字段和方法的符号引用转为直接引用 1、具体描述 符号引用就是一些字面量的引用,和虚拟机的内部数据结构和和内存布局无关。比较容易理解的就是在 Class类文件中通过常量池进行了大量的符号引用。但是在程序实际运行时,只有符号引用是不够的,比如当如下 println()方法被调用时,系统需要明确知道该方法的位置 举例:输出操作 System.out. print1n()对应的字节码 invokevirtual #24 以方法为例,Java虚拟机为每个类都准备了一张方法表,将其所有的方法都列在表中,当需要调用一个类的方法的时候只要知道这个方法在方法表中的偏移量就可以直接调用该方法。通过解析操作,符号引用就可以转变为目标方法在类中方法表中的位置,从而使得方法被成功调用 2、小结 所谓解析就是将符号引用转为直接引用,也就是得到类、字段、方法在内存中的指针或者偏移量。因此,可以说,如果直接引用存在,那么可以肯定系统中存在该类、方法或者字段。但只存在符号引用,不能确定系统中一定存在该结构 不过Java虚拟机规范并没有明确要求解析阶段一定要按照顺序执行。在 HotSpot VM中,加载、验证、准备和初始化会按照顺序有条不紊地执行,但链接阶段中的解析操作往往会伴随着JVM在执行完初始化之后再执行 3、字符串的复习 最后,再来看一下 CONSTANT_String的解析。由于字符串在程序开发中有着重要的作用,因此,读者有必要了解一下String在Java虚拟机中的处理。当在Java代码中直接使用字符串常量时,就会在类中出现 CONSTANT_String,它表示字符串常量,并且会引用一个 CONSTANT_UTF8的常量项。在Java虚拟机内部运行中的常量池中,会维护一张字符串拘留表( intern),它会保存所有出现过的字符串常量,并且没有重复项。只要以 CONSTANT_String形式出现的字符串也都会在这张表中。使用 String. intern()方法可以得到一个字符串在拘留表中的引用,因为该表中没有重复项,所以任何字面相同的字符串的 String. intern()方法返回总是相等的 初始化阶段,简言之,为类的静态变量赋予正确的初始值 1、具体描述 类的初始化是类装载的最后一个阶段。如果前面的步骤都没有问题,那么表示类可以顺利装载到系统中。此时,类才会开始执行Java字节码。(即:到了初始化阶段,才真正开始执行类中定义的Java程序代码。) 初始化阶段的重要工作是执行类的初始化方法:()方法 ● 该方法仅能由Java编译器生成并由JVM调用,程序开发者无法自定义一个同名的方法,更无法直接在Java程序中调用该方法,虽然该方法也是由字节码指令所组成 ● 它是由类静态成员的赋值语句以及 static语句块合并产生的 2、说明 2.1、在加载一个类之前,虚拟机总是会试图加载该类的父类,因此父类的总是在子类之前被调用也就是说,父类的 static块优先级高于子类。 口诀:由父及子,静态先行 2.2、Java编译器并不会为所有的类都产生< clinit>()初始化方法。哪些类在编译为字节码后,字节码文件中将不会包含()方法? ● 一个类中并没有声明任何的类变量,也没有静态代码块时 ● 一个类中声明类变量,但是没有明确使用类变量的初始化语句以及静态代码块来执行初始化操作时 ● 一个类中包含 static final 修饰的基本数据类型的字段,这些类字段初始化语句采用编译时常量表达式,如: public static final int num = 1; ■ 对于()方法的调用,也就是类的初始化,虚拟机会在内部确保其多线程环境中的安全性 ■ 虚拟机会保证一个类的()方法在多线程环境中被正确地加锁、同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的()方法,其他线程都需要阻塞等待,直到活动线程执行< clinit>()方法完毕 ■ 正是因为函数()带锁线程安全的,因此,如果在一个类的()方法中有耗时很长的操作,就可能造成多个线程阻塞,引发死锁。并且这种死锁是很难发现的,因为看起来它们并没有可用的锁信息 ■ 如果之前的线程成功加载了类,则等在队列中的线程就没有机会再执行()方法了。那么,当需要使用这个类时,虚拟机会直接返回给它已经准备好的信息 Java程序对类的使用分为两种:主动使用和被动使用 一、主动使用 Class只有在必须要首次使用的时候才会被装载,Java虚拟机不会无条件地装载C1ass类型。Java虚拟机规定,一个类或接口在初次使用前,必须要进行初始化。这里指的“使用”,是指主动使用,主动使用只有下列几种情况:(即:如果出现如下的情况,则会对类进行初始化操作。而初始化操作之前的加载、验证、准备已经完成。) 1、当创建一个类的实例时,比如使用new关键字,或者通过反射、克隆、反序列化 2、当调用类的静态方法时,即当使用了字节码 invokestatic指令 3、当使用类、接口的静态字段时( final修饰特殊考虑),比如,使用 getstatic或者 putstatic指令。(对应访问变量值变量操作) 4、当使用java.lang. reflect包中的方法反射类的方法时。比如: Class. forName(“com. atguigu.java.Test”) 5、当初始化子类时,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化 6、如果一个接口定义了 default方法,那么直接实现或者间接实现该接口的类的初始化,该接口要在其之前被初始化 7、当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类 8、当初次调用 MethodHandle实例时,初始化该 MethodHandle指向的方法所在的类。(涉及解析REF getstatic、REF_ putstatic、 REF invokestatic方法句柄对应的类) 针对5,补充说明: 当Java虚拟机初始化一个类时,要求它的所有父类都已经被初始化,但是这条规则并不适用于接口 > 在初始化一个类时,并不会先初始化它所实现的接口 > 在初始化一个接口时,并不会先初始化它的父接口 因此,一个父接口并不会因为它的子接口或者实现类的初始化而初始化。只有当程序首次使用特定接口的静态字段时,才会导致该接口的初始化 针对7,说明: JVM启动的时候通过引导类加载器加载一个初始类。这个类在调用public static void main( String[])方法之前被链接和初始化。这个方法的执行将依次导致所需的类的加载,链接和初始化 二、被动使用 除了以上的情况属于主动使用,其他的情况均属于被动使用。被动使用不会引起类的初始化 也就是说:并不是在代码中出现的类,就一定会被加载或者初始化。如果不符合主动使用的条件,类就不会初始化 1、当访问一个静态字段时,只有真正声明这个字段的类才会被初始化 ● 当通过子类引用父类的静态变量,不会导致子类初始化 2、通过数组定义类引用,不会触发此类的初始化 3、引用常量不会触发此类或接口的初始化。因为常量在链接阶段就已经被显式赋值了 4、调用Classloader类的loadClass()方法加载一个类,并不是对类的主动使用,不会导致类的初始化 如果针对代码,设置参数 -XX:+TranceClassLoading,可以追踪类的加载信息并打印出来 ■ 任何一个类型在使用之前都必须经历过完整的加载、链接和初始化3个类加载步骤。一旦一个类型成功经历过这3个步骤之后,便“万事俱备,只欠东风”,就等着开发者使用了 ■ 开发人员可以在程序中访问和调用它的静态类成员信息(比如:静态字段、静态方法),或者使用new关键字为其创建对象实例 一、类、类的加载器、类的实例之间的引用关系 在类加载器的内部实现中,用一个Java集合来存放所加载类的引用。另一方面,一个Class对象总是会引用它的类加载器调用Clas对象的getClassLoader()方法,就能获得它的类加载器。由此可见,代表某个类的Class实例与其类的加器之间为双向关联关系 一个类的实例总是引用代表这个类的Class对象。在 Object类中定义了 getclass()方法,这个方法返回代表对象所属类的Class对象的引用。此外,所有的Java类都有一个静态属性class,它引用代表这个类的Class对象 二、类的生命周期 当 Sample类被加载、链接和初始化后,它的生命周期就开始了。当代表 Sample类的c]ass对象不再被引用,即不可触及时, Class对象就会结束生命周期, Sample类在方法区内的数据也会被卸载,从而结束sample类的生命周期 一个类何时结束生命周期,取决于代表它的Class对象何时结束生命周期 三、具体例子 loader1变量和obj变量间接应用代表sample类的 Class对象,而objClass变量则直接引用它 如果程序运行过程中,将上图左侧三个引用变量都置为null,此时 Sample对象结束生命周期, MyClassLoader对象结束生命周期,代表Sample类的 Class对象也结束生命周期, Sample类在方法区内的二进制数据被卸载 当再次有需要时,会检查Sample类的Class对象是否存在,如果存在会直接使用,不再重新加载;如果不存在 Sample类会被重新加载,在Java虚拟机的堆区会生成一个新的代表Sample类的 Class实例(可以通过哈希码查看是否是同一个实例) 四、类的卸载 1、启动类加载器加载的类型在整个运行期间是不可能被卸载的(jvm和jls规范) 2、被系统类加载器和扩展类加载器加载的类型在运行期间不太可能被卸载,因为系统类加载器实例或者扩展类的实例基本上在整个运行期间总能直接或者间接的访问的到,其达到 unreachable的可能性极小 3、被开发者自定义的类加载器实例加载的类型只有在很简单的上下文环境中才能被卸载,而且一般还要借助于强制调用虚拟机的垃圾收集功能才可以做到。可以预想,稍微复杂点的应用场景中(比如:很多时候用户在开发自定义类加载器实例的时候采用缓存的策略以提高系统性能),被加载的类型在运行期间也是几乎不太可能被卸载的(至少卸载的时间是不确定的) 综合以上三点,一个已经加载的类型被卸载的几率很小至少被卸载的时间是不确定的。同时我们可以看的出来,开发者在开发代码时候,不应该对虚拟机的类型卸载做任何假设的前提下,来实现系统中的特定功能 回顾:方法区的垃圾回收 方法区的垃圾收集主要回收两部分内容:常量池中废弃的常量和不再使用的类型 Hotspot虚拟机对常量池的回收策略是很明确的,只要常量池中的常量没有被任何地方引用,就可以被回收 判定一个常量是否“废弃”还是相对简单,而要判定一个类型是否属于“不再被使用的类”的条件就比较苛刻了。需要同时满足下面三个条件: 1、该类所有的实例都已经被回收。也就是Java堆中不存在该类及其任何派生子类的实例 2、加载该类的类加载器已经被回收。这个条件除非是经过精心设计的可替换类加载器的场景,如OSGi、JsP的重加载等,否则通常是很难达成的 3、该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法 Java虚拟机被允许对满足上述三个条件的无用类进行回收,这里说的仅仅是“被允许”,而并不是和对象一样,没有引用了就必然会回收 类加载器是JVM执行类加载机制的前提; ClassLoader的作用 ClassLoader是Java的核心组件,所有的class都是由ClassLoader进行加载的, ClassLoader负责通过各种方式将Class信息的二进制数据流读入 JVM 内部,转换为一个与目标类对应的java.lang. Class对象实例。然后交给Java虚拟机进行链接、初始化等操作。因此,Classloader在整个装载阶段,只能影响到类的加载,而无法通过 ClassLoader去改变类的链接和初始化行为。至于它是否可以运行,则由 Execution Engine决定 类加载器最早出现在 Java1.0 版本中,那个时候只是单纯地为了满足 Java Applet 应用而被研发出来。但如今类加载器却在 OSGi、字节码加解密领域大放异彩。这主要归功于 Java 虚拟机的设计者们当初在设计类加载器的时候,并没有考虑将它绑定在 JVM 内部,这样做的好处就是能够更加灵活和动态地执行类加载操作 类的加载分类:显式加载vs隐式加载 class文件的显式加载与隐式加载的方式是指 jvm 加载class文件到内存的方式 ● 显式加载指的是在代码中通过调用 ClassLoader加载class对象,如直接使用Class. forName(name)或this. getclass().getClassloader().loadClass()加载class对象 ● 隐式加载则是不直接在代码中调用 Classloader的方法加载 class对象,而是通过虚拟机自动加载到内存中,如在加载某个类的class文件时,该类的class文件中引用了另外一个类的对象,此时额外引用的类将通过 JVM 自动加载到内存中 在日常开发以上两种方式一般会混合使用 一般情况下,Java开发人员并不需要在程序中显式地使用类加载器,但是了解类加载器的加载机制却显得至关重要。从以下几个方面说 ● 避免在开发中遇到java.lang. ClassNotFoundException异常或java.lang,NoClassDefFoundError异常时手足无措。只有了解类加载器的加载杋制才能够在岀现异常的时候快速地根据错误异常日志定位问题和解决问题 ● 需要支持类的动态加载或需要对编译后的字节码文件进行加解密操作时,就需要与类加载器打交道了 ● 开发人员可以在程序中编写自定义类加载器来重新定义类的加载规则,以便实现一些自定义的处理逻辑 1、何为类的唯一性 对于任意一个类,都需要由加载它的类加载器和这个类本身一同确认其在]ava虚拟机中的唯一性。每一个类加载器,都拥有一个独立的类名称空间:比较两个类是否相等,只有在这两个类是由同一个类加载器加载的前提下才有意义。否则,即使这两个类源自同一个Class文件,被同一个虚拟机加载,只要加载他们的类加载器不同,那这两个类就必定不相等 2、命名空间 ● 每个类加载器都有自己的命名空间,命名空间由该加载器及所有的父加载器所加载的类组成 ● 在同一命名空间中,不会出现类的完整名字(包括类的包名)相同的两个类 ● 在不同的命名空间中,有可能会出现类的完整名字(包括类的包名)相同的两个类 在大型应用中,我们往往借助这一特性,来运行同一个类的不同版本 通常类加载机制有三个基本特征: ■ 双亲委派模型。但不是所有类加载都遵守这个模型,有的时候,启动类加载器所加载的类型,是可能要加载用户代码的,比如 JDK内部的 Serviceprovider/ Serviceloader机制,用户可以在标准API框架上,提供自己的实现JDK也需要提供些默认的参考实现。例如,Java中JNDI、JDBC、文件系统、 Cipher等很多方面,都是利用的这种机制,这种情况就不会用双亲委派模型去加载,而是利用所谓的上下文加载器 ■ 可见性,子类加载器可以访问父加载器加载的类型,但是反过来是不允许的。不然,因为缺少必要的隔离,我们就没有办法利用类加载器去实现容器的逻辑 ■ 单一性,由于父加载器的类型对于子加载器是可见的,所以父加载器中加载过的类型,就不会在子加载器中重复加载。但是注意,类加载器“邻居”间,同一类型仍然可以被加载多次,因为互相并不可见 JWM支持两种类型的类加载器,分别为引导类加载器( Bootstrap ClassLoader)和自定义类加载器(User-Defined Classloader,由Java语言开发的) 从概念上来讲,自定义类加载器一般指的是程序中由开发人员自定义的一类类加载器,但是Java虚拟机规范却没有这么定义,而是将所有派生于抽象类C1 assloader的类加载器都划分为自定义类加载器。无论类加载器的类型如何划分,在程序中我们最常见的类加载器结构主要是如下情况: ● 除了顶层的启动类加载器外,其余的类加载器都应当有自己的 “父类” 加载器 ● 不同类加载器看似是继承(Inheritance) 关系,实际上是包含关系。在下层加载器中,包含着上层加载器的引用 对于包含关系如下: 启动类加载器(引导类加载器, Bootstrap ClassLoader) ■ 这个类加载使用C/C++语言实现的,嵌套在 JVM 内部 ■ 它用来加载Java的核心库( JAVA HOME/jre/lib/rt.jar或sun.boot. class path路径下的内容)。用于提供JW自身需要的类 ■ 并不继承自java.lang.Classloader,没有父加载器 ■ 出于安全考虑, Bootstrap启动类加载器只加载包名为java、 Javax、sun等开头的类 ■ 加载扩展类和应用程序类加载器,并指定为他们的父类加载器 使用 -XX:TraceClassLoading 参数得到。 启动类加载器使用 C++ 编写的?Yes! ● C/C++:指针函数&函数指针、C++支持多继承、更加高效 ● Java:由 C++ 演变而来,(C++)–版本,单继承 扩展类加载器(Extension ClassLoader) ● Java 语言编写,由 sun.misc.Launcher$ExtClassLoader 实现 ● 继承于 ClassLoader 类 ● 父类加载器为启动类加载器 ● 从 java.ext.dirs 系统属性所指定的目录中加载类库,或从 JDK 的安装目录的 jre/lib/ext 子目录下加载类库。如果用户创建的 JAR 放在此目录下,也会自动由扩展类加载器加载 应用程序类加载器(系统类加载器,AppClassLoader) ● java 语言编写,由 sun.misc.Launcher$AppClassLoader 实现 ● 继承于 ClassLoader 类 ● 父类加载器为扩展类加载器 ● 它负责加载环境变量 classpath 或系统属性 java.class.path 指定路径下的类库 ● 应用程序中的类加载器默认是系统类加载器 ● 它是用户自定义类加载器的默认父加载器 ● 通过 ClassLoader 的 getSystemClassLoader() 方法可以获取到该类加载器 用户自定义类加载器 ● 在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的。在必要时,我们还可以自定义类加载器,来定制类的加载方式 ● 体现Java语言强大生命力和巨大魅力的关键因素之一便是,Java开发者可以自定义类加载器来实现类库的动态加载,加载源可以是本地的 JAR包,也可以是网络上的远程资源 ● 通过类加载器可以实现非常绝妙的插件机制,这方面的实际应用案例举不胜举。例如,著名的OSGi组件框架,再如Eclipse的插件机制。类加载器为应用程序提供了一种动态增加新功能的机制,这种机制无须重新打包发布应用程序就能实现 ● 同时,自定义加载器能够实现应用隔离,例如 Tomcat, Spring等中间件和组件框架都在内部实现了自定义的加载器,并通过自定义加载器隔离不同的组件模块。这种机制比C/C++程序要好太多,想不修改C/C++程序就能为其新增功能,几乎是不可能的,仅仅一个兼容性便能阻挡住所有美好的设想 ● 自定义类加载器通常需要继承于 ClassLoader 每个Class对象都会包含一个定义它的Classloader的一个引用; 说明 站在程序的角度看,引导类加载器与另外两种类加载器(系统类加载器和扩展类加载器)并不是同一个层次意义上的加载器,引导类加载器是使用C++语言编写而成的,而另外两种类加载器则是使用]ava语言编写而成的。由于引导类加载器压根儿就不是一个 Java类,因此在Java程序中只能打印出空值 数组类的Cass对象,不是由类加载器去创建的,而是在Java运行期JWM根据需要自动创建的。对于数组类的类加载器来说,是通过Class.getClassLoader()返回的,与数组当中元素类型的类加载器是一样的;如果数组当中的元素类型是基本数据类型,数组类是没有类加载器的 ClassLoader与现有类加载器的关系 除了以上虚拟机自带的加载器外,用户还可以定制自己的类加载器。Java 提供了抽象类 java.lang.ClassLoader,所有用户自定义的类加载器都应该继承 ClassLoader 类 抽象类 Classloader的主要方法:(内部没有抽象方法) ● public final ClassLoader getParent():返回该类加载器的超类加载器 ● public Class loadClass(String name) throws ClassNotFoundException 加载名称为name的类,返回结果为java.lang.Class类的实例。如果找不到类,则返回 ClassNotFoundException 异常。该方法中的逻辑就是双亲委派模式的实现 ● protected Class findClass(String name) throws ClassNot FoundException 查找二进制名称为name的类,返回结果为java.lang.Class类的实例。这是一个受保护的方法,JVM鼓励我们重写此方法,需要自定义加载器遵循双亲委托机制,该方法会在检查完父类加载器之后被loadClass()方法调用 ● protected final Class defineClass(String name, byte[ ] b, int off, int len) 根据给定的字节数组b转换为class的实例,off和len参数表示实际Class信息在byte数组中的位置和长度,其中byte数组b是c1 assLoader从外部获取的。这是受保护的方法,只有在自定义C1 assloader-子类中可以使用 简单举例: ● protected final void resolveClass(Class c) 链接指定的一个 Java 类。使用该方法可以使用类的 Class 对象创建完成的同时也被解析。前面我们说链接阶段主要是对字节码进行验证,为类变量分配内存并设置初始值同时将字节码文件中的符号引用转换为直接引用 ● protected final Class findLoadedClass(String name) 查找名称为 name 的已经被加载过的类,返回结果为 java.lang.Class 类的实例。这个方法是 final 方法,无法被修改 ● private final ClassLoader parent 它也是一个 ClassLoader 的实例,这个字段所表示的 ClassLoader 也称为这个 ClassLoader 的双亲。在类加载的过程中,ClassLoader 可能会将某些请求交予自己的双亲处理 SecureClassLoader 与 URLClassLoader 接着 Secureclassloader扩展了 Classloader,新增了几个与使用相关的代码源(对代码源的位置及其证书的验证)和权限定义类验证(主要指对class源码的访问权限)的方法,一般我们不会直接跟这个类打交道,更多是与它的子类URLClassloader有所关联 前面说过, ClassLoader是一个抽象类,很多方法是空的没有实现,比如 findClass()、 findResource()等。而URLClassLoader这个实现类为这些方法提供了具体的实现。并新增了 URLClassPath类协助取得 Class字节码流等功能在编写自定义类加载器时,如果没有太过于复杂的需求,可以直接继承URLClassloaden类,这样就可以避免自己去编写 findClass()方法及其获取字节码流的方式,使自定义类加载器编写更加简洁 ExtClassLoader与 AppClalssLoader 了解完URLClassloader后接着看看剩余的两个类加载器,即拓展类加载器 ExtClassloader和系统类加载器AppClassLoader,这两个类都继承自URLClassloader,是sun.misc. Launcher的静态内部类sun.misc. Launcher主要被系统用于启动主应用程序,ExtClassloader和AppClassLoader都是由sun.misc. Launcher创建的,其类主要类结构如下 我们发现 ExtClassLoader 并没有重写 loadClass() 方法,这足以说明其遵循双亲委派模式,而 AppClassLoader 重载了 loadClass() 方法,但最终调用的还是父类 loadClass() 方法,因此依然遵守双亲委派模式 ■ Class. forName():是一个静态方法,最常用的是 Class. forName( String className);根据传入的类的全限定名返回一个Class对象。该方法在将 Class文件加载到内存的同时,会执行类的初始化。如: Class.forName(“com. atguigu.java.HelloWorld”) ■ Classloader.loadClass():这是一个实例方法,需要一个Classloader对象来调用该方法。该方法将class文件加载到内存时,并不会执行类的初始化,直到这个类第一次使用时才进行初始化。该方法因为需要得到个 ClassLoader对象,所以可以根据需要指定使用哪个类加载器。如: ClassLoader cl = …;cl.loadClass(“com. atguigu.java.Helloworld”) 类加载器用来把类加载到Java虚拟机中。从JDK1.2版本开始,类的加载过程采用双亲委派机制,这种机制能更好地保证Java平台的安全 1、定义 如果一个类加载器在接到加载类的请求时,它首先不会自己尝试去加载这个类,而是把这个请求任务委托给父类加载器去完成,依次递归,如果父类加载器可以完成类加载任务,就成功返回。只有父类加载器无法完成此加载任务时,才自己去加载 2、本质 规定了类加载的顺序是:引导类加载器先加载,若加载不到,由扩展类加载器加载,若还加载不到,才会由系统类加载器或自定义的类加载器进行加载 1、双亲委派机制优势 ■ 避免类的重复加载,确保一个类的全局唯一性 Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子Classloader再加载一次 ■ 保护程序安全,防止核心API被随意篡改 2、代码支持 双亲委派机制在java.lang. Classloader. loadclass( String, boolean)接口中体现。该接口的逻辑如下: ①、先在当前加载器的缓存中查找有无目标类,如果有,直接返回 ②、判断当前加载器的父加载器是否为空,如果不为空,则调用 parent.loadClass(name,false)接口进行加载 ③、反之,如果当前加载器的父类加载器为空,则调用 findBootstrapClassOrNull(name)接口,让引导类加载器进行加载 ④、如果通过以上3条路径都没能成功加载,则调用 findClass(name)接口进行加载。该接口最终会调用ava.lang. Classloader接口的 defineClass系列的 native接口加载目标Java类 双亲委派的模型就隐藏在这第2和第3步中 3、举例 假设当前加载的是java.lang. Object这个类,很显然,该类属于JDK中核心得不能再核心的一个类,因此一定只能由引导类加载器进行加载。当JWM准备加载 java.lang. object时,JVM默认会使用系统类加载器去加载,按照上面4步加载的逻辑,在第1步从系统类的缓存中肯定查找不到该类,于是进入第2步。由于从系统类加载器的父加载器是扩展类加载器,于是扩展类加载器继续从第1步开始重复。由于扩展类加载器的缓存中也一定査找不到该类,因此进入第2步。扩展类的父加载器是null,因此系统调用 findClass( String),最终通过引导类加载器进行加载 4、思考 如果在自定义的类加载器中重写java.lang.ClassLoader. loadClass(String)或java.lang. Classloader. loadClass( String, boolean)方法,抹去其中的双亲委派机制,仅保留上面这4步中的第1步与第4步,那么是不是就能够加载核心类库了呢? 这也不行!因为JDK还为核心类库提供了一层保护机制。不管是自定义的类加载器,还是系统类加载器抑或扩展类加载器,最终都必须调用java.lang. ClassLoader. defineClass( String,byte[],int,int,Protectiondomain)方法,而该方法会执行 preDefineClass()接口,该接口中提供了对JDK核心类库的保护 5、双亲委托模式的弊端 检査类是否加载的委托过程是单向的,这个方式虽然从结构上说比较清晰,使各个Classloader的职责非常明确,但是同时会带来一个问题,即顶层的ClassLoader无法访问底层的ClassLoader所加载的类 通常情况下,启动类加载器中的类为系统核心类,包括一些重要的系统接口,而在应用类加载器中,为应用类。按照这种模式,应用类访问系统类自然是没有问题,但是系统类访问应用类就会出现问题。比如在系统类中提供了一个接口该接口需要在应用类中得以实现,该接口还绑定一个工厂方法,用于创建该接口的实例,而接口和工厂方法都在启动类加载器中。这时,就会出现该工厂方法无法创建由应用类加载器加载的应用实例的问题 6、结论 由于Java虚拟机规范并没有明确要求类加载器的加载机制一定要使用双亲委派模型,只是建议采用这种方式而已比如在 Tomcat中,类加载器所采用的加载机制就和传统的双亲委派模型有一定区别,当缺省的类加载器接收到一个类的加载任务时,首先会由它自行加载,当它加载失败时,才会将类的加载任务委派给它的超类加载器去执行,这同时也是Servlet规范推荐的一种做法 ■ 双亲委派模型并不是一个具有强制性约束的模型,而是Java设计者推荐给开发者们的类加载器实现方式 ■ 在Java的世界中大部分的类加载器都遵循这个模型,但也有例外的情况,直到Java模块化岀现为止,双亲委派模型主要出现过3次较大规模“被破坏”的情况 ■ 第一次破坏双亲委派机制: 双亲委派模型的第一次“被破坏”其实发生在双亲委派模型出现之前-----即 JDK1.2面世以前的“远古”时代由于双亲委派模型在 JDK1.2之后才被引入,但是类加载器的概念和抽象类java.lang.Classloader则在Java的第个版本中就已经存在,面对己经存在的用户自定义类加载器的代码,Java设计者们引入双亲委派模型时不得不做出一些妥协,为了兼容这些已有代码,无法再以技术手段避免 loadClass()被子类覆盖的可能性,只能在JDK1.2之后的java.lang.Classloader中添加一个新的 protected方法 findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在loadClass()中编写代码。上节我们已经分析过loadClass()方法,双亲委派的具体逻辑就实现在这里面,按照loadClass()方法的逻辑,如果父类加载失败,会自动调用自己的 findClass()方法来完成加载,这样既不影响用户按照自己的意愿去加载类,又可以保证新写出来的类加载器是符合双亲委派规则的 ■ 第二次破坏双亲委派机制:线程上下文类加载器 ■ 双亲委派模型的第二次“被破坏”是由这个模型自身的缺陷导致的,双亲委派很好地解决了各个类加载器协作时基础类型的一致性问题(越基础的类由越上层的加载器进行加载),基础类型之所以被称为“基础”,是因为它们总是作为被用户代码继承、调用的API存在,但程序设计往往没有绝对不变的完美规则,如果有基础类型又要调用回用户的代码那该怎么办呢? ■ 这并非是不可能出现的事情,一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器来完成加载(在JDK1.3时加入到rt.jar的),肯定属于Java中很基础的类型了。但JNDI存在的目的就是对资源进行査找和集中管理,它需要调用由其他厂商实现并部署在应用程序的ClassPath下的JNDI服务提供者接口(Service Provider Interface,SPI)的代码,现在问题来了,启动类加载器是绝不可能认识、加载这些代码的,那该怎么办?(SPI:在Java平台中,通常把核心类rt.jar中提供外部服务、可由应用层自行实现的接口称为SPI) ■ 为了解决这个困境,Java的设计团队只好引入了一个不太优雅的设计:线程上下文类加载器( Thread Context Classloader)。这个类加载器可以通过java.lang. Thread类的 setContextClassloader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器 ■ 有了线程上下文类加载器,程序就可以做一些“舞弊”的事情了。JNDI服务使用这个线程上下文类加载器去加载所需的sPI服务代码,这是一种父类加载器去请求子类加载器完成类加载的行为,这种行为实际上是打通了双亲委派模型的层次结构来逆向使用类加载器,已经违背了双亲委派模型的一般性原则,但也是无可奈何的事情。Java中涉及SPI 的加载基本上都采用这种方式来完成,例如JNDI、JDBC、JCE、JAXB和JBI等。不过,当SPI的服务提供者多于一个的时候,代码就只能根据具体提供者的类型来硬编码判断,为了消除这种极不优雅的实现方式,在JDK6时,JDK提供了 java.util.ServiceLoader 类,以 META-INF/service 中的配置信息,辅以责任链模式,这才算是给 SPI 的加载提供了一种相对合理的解决方案 默认上下文加载器就是应用类加载器,这样以上下文加载器为中介,使得启动类加载器中的代码也可以访问应用类加载器中的类 第三次破坏双亲委派机制: ■ 双亲委派模型的第三次“被破坏”是由于用户对程序动态性的追求而导致的。如:代码热替换( Hot Swap)、模块热部署( Hot Deployment)等 ■ IBM公司主导的 JSR-291(即OSGi R4.2)实现模块化热部署的关键是它自定义的类加载器机制的实现,每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi环境下,类加载器不再双亲委派模型推荐的树状结构,而是进一步发展为更加复杂的网状结 ■ 当收到类加载请求时,OSGi将按照下面的顺序进行类搜索: ● 将以java.*开头的类,委派给父类加载器加载 ● 否则,将委派列表名单内的类,委派给父类加载器加载 ● 否则,将 Import列表中的类,委派给 Export这个类的 Bundle的类加载器加载 ● 否则,查找当前 Bundle的ClassPath,使用自己的类加载器加载 ● 否则,查找类是否在自己的 Fragment Bundle中,如果在,则委派给 Fragment Bundle的类加载器加载 ● 否则,查找 Dynamic Import列表的Bundle,委派给对应 Bundle的类加载器加载 ● 否则,类查找失败。 说明:只有开头两点仍然符合双亲委派模型的原则,其余的类查找都是在平级的类加载器中进行的 ■ 小结: 这里,我们使用了“被破坏”这个词来形容上述不符合双亲委派模型原则的行为,但这里“被破坏”并不一定是带有贬义的。只要有明确的目的和充分的理由,突破旧有原则无疑是一种创新 正如:OSGi 中的类加载器的设计不符合传统的双亲委派的类加载器架构,且业界对其为了实现热部署而带来的额外的高复杂度还存在不少争议,但对这方面有了解的技术人员基本还是能达成一个共识,认为OSGi 中对类加载器的运用是值得学习的,完全弄懂了 OSGi 的实现,就算是掌握了类加载器的精辟 ■ 热替换是指在程序的运行过程中,不停止服务,只通过替换程序文件来修改程序的行为。热替换的关键需求在于服务不能中断,修改必须立即表现正在运行的系统之中。基本上大部分脚本语言都是天生支持热替换的,比如:PHP,只要替换了PHP源文件,这种改动就会立即生效,而无需重启Web服务器 ■ 但对Java来说,热替换并非天生就支持,如果一个类已经加载到系统中,通过修改类文件,并无法让系统再来加载并重定义这个类。因此,在Java中实现这一功能的一个可行的方法就是灵活运用 ClassLoader ■ 注意:由不同c1 assloader加载的同名类属于不同的类型,不能相互转换和兼容。即两个不同的 Classloader加载同个类,在虚拟机内部,会认为这2个类是完全不同的 ■ 根据这个特点,可以用来模拟热替换的实现,基本思路如下图所示 ■ 沙箱安全机制 ● 保证程序安全 ● 保护Java原生的JDK代码 ■ Java安全模型的核心就是Java沙箱( sandbox)。什么是沙箱?沙箱是一个限制程序运行的环境 ■ 沙箱机制就是将]ava代码限定在虚拟杋(JVM)特定的运行范围中,并且严格限制代码对本地系统资源访问。通过这样的措施来保证对代码的有限隔离,防止对本地系统造成破坏 ■ 沙箱主要限制系统资源访问,那系统资源包括什么? CPU、内存、文件系统、网络。不同级别的沙箱对这些资源访问的限制也可以不一样 ■ 所有的 Java程序运行都可以指定沙箱,可以定制安全策略 在Java中将执行程序分成本地代码和远程代码两种,本地代码默认视为可信任的,而远程代码则被看作是不受信的。对于授信的本地代码,可以访问一切本地资源。而对于非授信的远程代码在早期的Java实现中,安全依赖于沙箱Sandbox)机制。如下图所示]DK1.8安全模型 JDK1.0中如此严格的安全机制也给程序的功能扩展带来障碍,比如当用户希望远程代码访问本地系统的文件时候,就无法实现 因此在后续的Java1.1版本中,针对安全机制做了改进,增加了安全策略。允许用户指定代码对本地资源的访问权限。如下图所示DK1.1安全模型: 在Java1.2版本中,再次改进了安全机制,增加了代码签名。不论本地代码或是远程代码,都会按照用户的安全策略设定,由类加载器加载到虚拟机中权限不同的运行空间,来实现差异化的代码执行权限控制。如下图所示JDK1.2安全模型 当前最新的安全机制实现,则引入了域( Domain)的概念 虚拟机会把所有代码加载到不同的系统域和应用域。系统域部分专门负责与关键资源进行交互,而各个应用域部分则通过系统域的部分代理来对各种需要的资源进行访问。虚拟机中不同的受保护域(Protected domain),对应不一样的权限( Permission)。存在于不同域中的类文件就具有了当前域的全部权限,如下图所示,最新的安全模型(jdk 6) 1、为什么要自定义类加载器? ■ 隔离加载类 在某些框架内进行中间件与应用的模块隔离,把类加载到不同的环境。比如:阿里内某容器框架通过自定义类加载器确保应用中依赖的jar包不会影响到中间件运行时使用的jar包。再比如: Tomcat这类web应用服务器,内部自定义了好几种类加载器,用于隔离同一个Web应用服务器上的不同应用程序 ■ 修改类加载的方式 类的加载模型并非强制,除 Bootstrap外,其他的加载并非一定要引入,或者根据实际情况在某个时间点进行按需进行动态加载 ■ 扩展加载源 比如从数据库、网络、甚至是电视机机顶盒进行加载 ■ 防止源码泄漏 Java代码容易被编译和篡改,可以进行编译加密。那么类加载也需要自定义,还原加密的字节码 2、常见的场景 ■ 实现类似进程内隔离,类加载器实际上用作不同的命名空间,以提供类似容器、模块化的效果。例如,两个模块依赖于某个类库的不同版本,如果分别被不同的容器加载,就可以互不干扰。这个方面的集大成者是 Java EE和OSGi、JPMS等框架 ■ 应用需要从不同的数据源获取类定义信息,例如网络数据源,而不是本地文件系统。或者是需要自己操纵字节码动态修改或者生成类型 3、注意 在一般情况下,使用不同的类加载器去加载不同的功能模块,会提高应用程序的安全性。但是,如果涉及 Java 类型转换,则加载器反而容易产生不美好的事情。在做 Java 类型转换时,只有两个类型都是由同一个加载器所加载,才能进行类型转换,否则转换时会发生异常 用户通过定制自己的类加载器,这样可以重新定义类的加载规则,以便实现一些自定义的处理逻辑 1、实现方式 ■ Java提供了抽象类java.lang.Classloader,所有用户自定义的类加载器都应该继承Classloader类 ■ 在自定义 Classloader的子类时候,我们常见的会有两种做法 ● 方式一: 重写1oadC1ass()方法 ● 方式二: 重写 findc1ass()方法 2、对比 这两种方法本质上差不多,毕竟 loadClass()也会调用 findClass(),但是从逻辑上讲我们最好不要直接修改loadClass()的内部逻辑。建议的做法是只在 findClass()里重写自定义类的加载方法,根据参数指定类的名字,返回对应的Class对象的引用 ■ loadClass()这个方法是实现双亲委派模型逻辑的地方,擅自修改这个方法会导致模型被破坏,容易造成问题。因此我们最好是在双亲委派模型框架内进行小范围的改动,不破坏原有的稳定结构。同时,也避免了自己重写loadClass()方法的过程中必须写双亲委托的重复代码,从代码的复用性来看,不直接修改这个方法始终是比较好的选择 ■ 当编写好自定义类加载器后,便可以在程序中调用 loadClass()方法来实现类加载操作 3、说明 ■ 其父类加载器是系统类加载器 ■ JVM中的所有类加载都会使用 java.lang.Classloader. loadClass(String)接口(自定义类加载器并重写 java.lang.ClassLoader.loadClass(String) 接口除外),连 JDK 的核心类库也不能例外 自定义类加载器: 测试类: (22-26章) ①、生产环境发生了内存溢出该如何处理? ②、生产环境应该给服务器分配多少内存合适? ③、如何对垃圾回收器的性能进行调优? ④、生产环境CPU负载飙高该如何处理? ⑤、生产环境应该给应用分配多少线程合适? ⑥、不加log,如何确定请求是否执行了某一行代码? ⑦、不加log,如何实时查看某个方法的入参与返回值? ①、防止出现OOM ②、解决OOM ③、减少Full GC 出现的频率 ①、上线前 ②、项目运行阶段 ③、线上出现OOM ①、运行日志 ②、异常堆栈 ③、GC日志 ④、线程快照 ⑤、堆转储快照 ①、合理地编写代码 ②、充分并合理地使用硬件资源 ③、合理地进行JVM调优 ■ 一种以非强行或者入侵方式收集或查看应用运营性能数据的活动 ■ 监控通常是指一种在生产、质量评估或者开发环境下实施的带有预防或主动性的活动 ■ 当应用相关干系人提出性能问题却没有提供足够多的线索时,首先我们需要进行性能监控,随后是性能分析 问题: ①、GC频繁 ②、cpu load过高 ③、OOM ④、内存泄漏 ⑤、死锁 ⑥、程序响应时间较长 ■ 一种以侵入方式收集运行性能数据的活动,它会影响应用的香吐量或响应性 ■ 性能分析是针对性能问题的答复结果,关注的范围通常比性能监控更加集中 ■ 性能分析很少在生产环境下进行,通常是在质量评估、系统测试或者开发环境下进行,是性能监控之后的步骤 分析问题: ①、打印GC日志,通过 GCView 或者 http://gceasy.io 来分析日志信息 ②、灵活运用命令行工具,jstack,jmap,jinfo等 ③、dump出堆文件,使用内存分析工具分析文件 ④、使用阿里 Arthas 或 jconsole,JVisualVM 来实时查看 JVM 状态 ⑤、jstack查看堆栈信息 ■ 一种为改善应用响应性或吐吞量而更改参数、源代码、属性配置的活动,性能调优是在性能监控、性能分析之后的活动 调优: ①、适当增加内存,根据业务背景选择垃圾回收器 ②、优化代码,控制内存使用 ③、增加机器,分散节点压力 ④、合理设置线程池线程数量 ⑤、使用中间件提高程序效率,比如缓存,消息队列等 ■ 提交请求和返回该请求的响应之间使用的时间,一般比较关注平均响应时间 ■ 常用操作的响应时间列表: ■ 在垃圾回收环节中: 暂停时间:执行垃圾收集时,程序的工作线程被暂停的时间 -XX:MaxGCPauseMillis 1、对单位事件内完成的工作量(请求)的量度 2、在GC中:运行用户代码的时间占总运行时间的比例(总运行时间:程序的运行时间 + 内存回收的时间) 吐吞量为:1 - 1/(1 + n)。-XX:GCTimeRatio=n 同一时刻,堆服务器有交际交互的请求数 Java 堆区所占的内存大小 以高速公路通行状况为例 ■ 性能诊断是软件工程师在日常工作中需要经常面对取解决的问题,在用户体验至上的今天,解决好应用的性能问题能带来非常大的收益 ■ Java作为最流行的编程语言之一,其应用性能诊断一直受到业界广泛关注。可能造成Java应用岀现性能问题的因素非常多,例如线程控制、磁盘读写、数据库访问、网络 I/O、垃圾收集等。想要定位这些问题,一款优秀的性能诊断工具必不可少 ■ 体会1:使用数据说明问题,使用知识分析问题,使用工具处理问题 ■ 体会2:无监控、不调优! 简单命令行工具 在我们刚接触java学习的时候,大家肯定最先了解的两个命令就是 Javac,java,那么除此之外,还有没有其他的命令可以供我们使用呢?我们进入到安装jdk的bin目录,发现还有一系列辅助工具。这些辅助工具用来获取目标JVM不同方面、不同层次的信息,帮助开发人员很好地解决 Java 应用程序的一些疑难杂症 工具源码:https://hg.openjdk.java.net/jdk/jdk11/file/1ddf9a99e4ad/src/jdk.jcmd/share/classes/sun/tools JPS(Java Process Status): ■ 显示指定系统内所有的HotSpot虚拟机进程(查看虚拟机进程信息),可用于查询正在运行的虚拟机进程 ■ 说明:对于本地虚拟机进程来说,进程的本地虚拟机ID与操作系统的进行ID是一致的,是惟一的 直接使用 jps 命令即可 ■ options参数 它的基本使用语法为: jps [options] [hostid] 我们还可以通过追加参数,来打印额外的信息 ■ hostid 参数 ①、options 参数 ■ -q:仅仅显示LVMID(local virtual machine id),即本地虚拟机唯一id。不显示主类的名称等 ■ -l:输出应用程序主类的全类名或如果进程执行的是jar包,则输出jar完整路径 ■ -m:输出虚拟机进程启动时传递给主类main()的参数 ■ -v:列出虚拟机进程启动时的JVM参数。比如:-Xms28m -Xmx50m是启动程序指定的jvm参数 ■ 说明:以上参数可以综合使用 ■ 补充: 如果某Java进程关闭了默认开启的 UsePerfData参数(即使用参数 -XX:- UsePerfData),那么jps命令(以及下面介绍的 jstat)将无法探知该Java进程 ②、hostid 参数 ■ RMI注册表中注册的主机名。如果想要远程监控主机上的java程序,需要安装 jstatd ■ 对于具有更严格的安全实践的网络场所而言,可能使用一个自定义的策略文件来显示对特定的可信主机或网络的访问,尽管这种技术容易受到IP地址欺诈攻击 ■ 如果安全问题无法使用一个定制的策略文件来处理,那么最安全的操作是不运行jstatd服务器,而是在本地使用 jstat和jps工具 ■ jstat( JVM Statistics Monitoring Tool):用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据 ■ 在没有GUI 图形界面,只提供了纯文本控制台环境的服务器上,它将是运行期定位虚拟机性能问题的首选工具。常用于检测垃圾回收问题以及内存泄漏问题 ■ 官方文档: https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html 它的基本使用语法为: 查看命令相关参数: jstat -h 或 jstat -help ①、option参数 选项 option 可以由以下值构成 ■ 类装载相关的 ● -class:显示Classloader的相关信息:类的装载、卸载数量、总空间、类装载所消耗的时间等 举例: ■ 垃圾回收相关的 ● -gc:显示与GC相关的堆信息。包括Eden区、两个 Survivor区、老年代、永久代等的容量、已用空间、GC时间合计等信息 各个参数代表的意思: ● -gccapacity:显示内容与-gc基本相同,但输出主要关注Java堆各个区均使用到的最大、最小空间 ● - gutil:显示内容与-gc基本相同,但输出主要关注已使用空间占总空间的百分比 ● -gccause:-gcutil 功能一样,但是会额外输出导致最后一次或当前正在发生的GC产生的原因 ● - gcnew:显示新生代GC状况 ● gcnewcapacity:显示内容与 -gcnew基本相同,输出主要关注使用到的最大、最小空间 ● -geold:显示老年代GC状况 ● -gcoldcapacity:显示内容与 -gcold 基本相同,输出主要关注使用到的最大、最小空间 ● -gcpermcapacity:显示永久代使用到最大、最小空间 ■ JIT 相关的 ● -compiler:显示 JIT 编译器编译过的方法、耗时等信息 ● -printcompilation:输出已经被 JIT 编译的方法 ②、interval参数 用于指定输出统计数据的周期,单位为毫秒。即:查询间隔。如下所示,表示每隔1秒打印一次 -class 信息 ③、count参数 用于指定查询的总次数。如下所示,表示每隔1秒打印一次 -class 信息,总共打印5次 ④、-t参数 可以在输出信息前加上一个 Timestamp 列,显示程序的运行时间。单位:秒。如下所示,在第一列上打印了一个时间,这个时间表示程序从开始到执行完成或程序从开始到执行到现在(如果程序没有还没有执行完成)所花费的时间,并且每秒打印一次,总共打印5次。注意 -t 的位置,只能在 -option 后面 经验: 我们可以比较 Java 进程的启动时间以及总 GC 时间(GCT列),或者两次测量的间隔时间以及总 GC 时间的增量,来得出 GC 时间占运行时间的比例 如果该比例超过 20%,则说明目前堆的压力比较大;如果该比例超过 90%,则说明堆里几乎没有可用空间,随时都可能抛出 OOM 异常 ⑤、-h参数 可以在周期性数据输出时,输出多少行数据后输出一个表头信息 ■ jstat还可以用来判断是否出现内存泄漏 ■ 第一步: 在长时间运行的Java程序中,我们可以运行 jstat命令连续获取多行性能数据,并取这几行数据中OU列(即已占用的老年代内存)的最小值 ■ 第二步: 然后,我们每隔一段较长的时间重复一次上述操作,来获得多组OU最小值。如果这些值呈上涨趋势,则说明该Java程序的老年代内存已使用量在不断上涨,这意味着无法回收的对象在不断增加,因此很有可能存在内存泄漏 jinfo(Configuration Info for Java) ■ 查看虚拟机配置参数信息,也可用于调整虚拟机的配置参数 ■ 在很多情况下,Java应用程序不会指定所有的Java虚拟机参数。而此时,开发人员可能不知道某一个具体的Java虚拟机参数的默认值。在这种情况下,可能需要通过查找文档获取某个参数的默认值。这个查找过程可能是非常艰难的。但有了jinfo工具,开发人员可以很方便地找到 Java虚拟机参数的当前值 ■ 官方帮助文档 https://docs.oracle.com/en/java/javase/11/tools/jinfo.html 它的基本使用语法为: jinfo [option] pid 说明:java 进程 ID 必须要加上 【options]: ①、查看 ■ jinfo -sysprops PID 可以查看由 System.getProperties() 取得的参数 ■ jinfo -flags PID 查看曾经赋值过的一些参数 ■ jinfo -flag 具体参数 PID 查看某个 java 进程的具体参数的值 ②、修改 jinfo 不仅可以查看运行时某一个 Java 虚拟机参数的实际取值,甚至可以在运行时修改部分参数,并使之立即生效。但是,并非所有参数都支持动态修改。参数只有被标记为 manageable 的 flag 可以被实时修改。其实,这个修改能力是极其有限的。注意:如果使用这个命令修改了参数,然后将 Java 应用停掉后再启动,之前修改的参数又会回到原来的样子,即这只是一个临时修改 可以使用下面命令查看被标记为 manageable 的参数 java -XX:+PrintFlagsFinal -version | grep manageable ■ 针对 boolean 类型: jinfo -flag [+|-] 具体参数 PID,如下修改:jinfo -flag +PrintGCDetails 16172 ■ 针对非 boolean 类型: jinfo -flag 具体参数=具体参数值 PID ■ java -XX:+PrintFlagsInitial:查看所有 JVM 参数启动的初始值 ■ java -XX:+PrintFlagsFinal:查看所有 JVM 参数的最终值 ■ java -XX+PrintCommandLineFlags:查看那些已经被用户或者 JVM 设置过的详细的 XX 参数的名称和值 ■ jmap( JVM Memory Map):作用一方面是获取dump文件(堆转储快照文件,二进制文件)它还可以获取目标Java进程的内存相关信息,包括Java堆各区域的使用情况、堆中对象的统计信息、类加载信息等 ■ 开发人员可以在控制台中输入命令“jmap -help”查阅 jmap工具的具体使用方式和一些标准选项配置 ■ 官方帮助文档 https://docs.oracle.com/en/java/javase/11/tools/jmap.html 它的基本使用语法为: ● jmap [option] ● jmap [option] ● jmap [option] [server_id@] 其中 option 包括: 说明:这些参数和 linux 下输入显示的命令多少会有不同,包括也受 jdk 版本影响 ■ -dump ● 生成 Java 堆转储快照:dump 文件 ● 特别的:-dump:live 只保存堆中的存活对象 ■ -heap ● 输出整个堆空间的详细信息,包括 GC 的使用、堆配置信息,以及内存的使用信息等 ■ -histo ● 输出堆中对象的统计信息,包括类、实例数量和合计容量 ● 特别的:-histo:live 只统计堆中的存活对象 ■ -permstat ● 以 ClassLoader 为统计口径输出永久的内存状态信息 ● 仅 linux/solaris 平台有效 ■ -finalizerinfo ● 显示在 F-Queue中等待 Finalizer 线程执行 finalize 方法的对象 ● 仅 linux/solaris 平台有效 ■ -F ● 当虚拟机进程对 -dump 选项没有任何响应时,可使用此选项强制执行生成 dump 文件 ● 仅 linux/solaris 平台有效 ■ -h | -help ● jmap 工具使用的帮助命令 ■ -J ● 传递参数给 jmap 启动的 jvm ■ 一般来说,使用 jmap 指令生成 dump 文件的操作算得上是最常用的 jmap 命令之一,将堆中所有存活对象导出至一个文件之中 ■ Heap Dump 又叫做堆存储文件,指一个 Java 进程在某个时间点的内存快照。Heap Dump 在触发内存快照的时候会保存此刻信息如下: ● All Objects Class,fields,primitive value and references ● All Classes ClassLoader,name,super class,static fields ● Garbage Collection Roots Objects defined to be reachable by the JVM ● Thread Stacks and Local Variables The call-stacks of threads at the moment of the snapshot,and per-frame information about local objects ■ 说明: 1、通常在写 Heap Dump 文件前会触发一次 Full GC,所以 heap dump 文件里保存的都是 Full GC 后留下的对象信息 2、由于生成 dump 文件比较耗时,因此大家需要耐心等待,尤其是大内存镜像生成 dump 文件则需要耗费更长的时间来完成 ■ jmap -dump:format=b,file= ■ jmap -dump:live,format=b,file= 参数说明: format=b:表示以标准格式写入文件 ■ -XX:+HeapDumpOnOutOfMemoryError ■ -XX:HeapDumpPath= ■ 说明: ● 当程序发生M退出系统时,一些瞬时信息都随着程序的终止而消失,而重现oM问题往往比较困难或者耗时。此时若能在OOM时,自动导出dump文件就显得非常迫切 ● 这里介绍一种比较常用的取得堆快照文件的方法,即使用: -XX:+HeapDumpOnOutOfMemoryError:在程序发生 OOM 时,导出应用程序的当前堆快照 -XX:HeapDumpPath:可以指定堆快照的保存位置 比如: -Xms100m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\m.hprof 查看当前时间点的堆的各个信息 查看系统的 ClassLoader 信息 查看堆积在 finalizer 队列中的对象 ● 由于jmap将访问堆中的所有对象,为了保证在此过程中不被应用线程干扰,jmap需要借助安全点机制,让所有线程停留在不改变堆中数据的状态。也就是说,由jmap导出的堆快照必定是安全点位置的。这可能导致基于该堆快照的分析结果存在偏差 ● 举个例子,假设在编译生成的机器码中,某些对象的生命周期在两个安全点之间,那么 :live选项将无法探知到这些对象 ● 另外,如果某个线程长时间无法跑到安全点,jmap将一直等下去。与前面讲的 jstat则不同,垃圾回收器会主动将 jstat所需要的摘要数据保存至固定位置之中,而 jstat只需直接读取即可 jhat(JVM Heap Analysis Tool) ■ Sun JDK提供的jhat命令与jmap命令搭配使用,用于分析jmap生成的 heap dump文件(堆转储快照)。jhat内置了一个微型的HTTP/HTML服务器,生成dump文件的分析结果后,用户可以在浏览器中査看分析结果(分析虚拟机转储快照信息) ■ 使用了jhat命令,就启动了一个http服务,端口是7000,即http://localhost:7000/就可以在浏览器里分析 ■ 说明:jhat命令在 JDK9、JDK10中已经被删除,官方建议用 VisualVM代替 它的基本使用语法为: jhat [option] [dumpfile] option参数: ■ -stack false|true:关闭|打开对象分配调用栈跟踪 ■ -refs false|true:关闭|打开对象引用跟踪 ■ -port port-number:设置 jhat HTTP Server 的端口号,默认 7000 ■ -exclude exclude-file:执行对象查询时需要排除的数据成员 ■ -baseline exclude-file:指定一个基准堆转储 ■ -debug int:设置 debug 级别 ■ -version:启动后显示版本信息就退出 ■ -J:传入启动参数,比如:-J -Xmx512m ■ jstack( JVM Stack Trace):用于生成虚拟机指定进程当前时刻的线程快照(虚拟机堆栈跟踪)。线程快照就是当前虚拟机内指定进程的每一条线程正在执行的方法堆栈的集合 ■ 生成线程快照的作用:可用于定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等问题。这些都是导致线程长时间停顿的常见原因。当线程出现停顿时,就可以用 stack显示各个线程调用的堆栈情况 ■ 官方帮助文档:https://docs.oracle.com/en/java/javase/11/tools/istack.html ■ 在 thread dump中,要留意下面几种状态 ● 死锁, Deadlock(重点关注) ● 等待资源, Waiting on condition(重点关注) ● 等待获取监视器,Waiting on monitor entry(重点关注) ● 阻塞,Blocked(重点关注) ● 执行中, Runnable ● 暂停, Suspended ● 对象等待中,Object.wait() 或 TIMED_WAITING ● 停止,Parked ■ 它的基本使用语法: jstack [option] pid ■ jstack 管理远程进程的话,需要在远程程序的启动参数中增加: -Djava.rmi.server.hostname=… -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8888 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false ■ option 选项: ● -F:当正常输出的请求不被响应时,强制输出线程堆栈 ● -l:除堆栈外,显示关于锁的附加信息 ● -m:如果调用到本地方法的话,可以显示 C/C++ 的堆栈 ● -h:帮助操作 ■ 在JDK1.7以后,新增了一个命令行工具jcmd ■ 它是一个多功能的工具,可以用来实现前面除了 jstat之外所有命令的功能。比如:用它来导出堆、内存使用、查看Java进程、导出线程信息、执行GC、JVM运行时间等 ■ 官方帮助文档:https://docs.oracle.com/en/java/javase/11/tools/jcmd.html ■ jcmd拥有jmap的大部分功能,并且在Oracle的官方网站上也推荐使用jcmd命令代jmap命令 ■ jcmd -l:列出所有的 JVM 进程。类似 jps ■ jcmd pid help:针对指定的进程,列出支持的所有命令 ■ jcmd pid 具体命令:显示指定进程的指令命令的数据,其中具体命令是通过上一个命令查出来的命令(jcmd pid help)。这些命令的执行结果类似于之前学过的命令 ■ 之前的指令只涉及到监控本机的Java应用程序,而在这些工具中,一些监控工具也支持对远程计算机的监控(如jps、 jstat)。为了启用远程监控,则需要配合使用 jstatd工具 ■ 命令 jstatd是一个RM服务端程序,它的作用相当于代理服务器,建立本地计算机与远程监控工具的通信。 jstatd服务器将本机的Java应用程序信息传递到远程计算机 ■ 使用上一章命令行工具或组合能帮您获取目标Java应用性能相关的基础信息,但它们存在下列局限: 1、无法获取方法级别的分析数据,如方法间的调用关系、各方法的调用次数和调用时间等(这对定位应用性能瓶颈至关重要) 2、要求用户登录到目标Java应用所在的宿主机上,使用起来不是很方便 3、分析数据通过终端输出,结果展示不够直观 ■ 为此,JDK提供了一些内存泄漏的分析工具,如 jconsole, jvisualvm等,用于辅助开发人员定位问题,但是这些工具很多时候并不足以满足快速定位的需求。所以这里我们介绍的工具相对多一些、丰富一些 ■ 图形化综合诊断工具 ● JDK自带的工具 ○ jconsole:JDK自带的可视化监控工具。査看Java应用程序的运行概况、监控堆信息、永久区(或元空间)使用情况、类加载情况等 --> 位置:jdk\bin\jconsole.exe ○ Visual VM: Visual VM 是一个工具,它提供了一个可视界面,用于查看Java虚拟机上运行的基于 Java技术的应用程序的详细信息 --> 位置:jdk\bin\jvisualvm.exe ○ JMC: Java Mission Control,内置 Java Flight Recorder。能够以极低的性能开销收集Java虚拟机的性能数据 ● 第三方工具 ○ MAT:MAT( Memory Analyzer Tool)是基于Eclipse的内存分析工具,是一个快速、功能丰富的 Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗 --> Eclipse的插件形式 ○ JProfiler:商业软件,需要付费。功能强大 --> 与 Visual VM类似 ○ Arthas:Alibaba开源的 Java诊断工具。深受开发者喜爱 ○ Btrace:Java运行时追踪工具。可以在不停机的情况下,跟踪指定的方法调用、构造函数调用和系统内存等信息 ■ 从 Java5 开始,在 JDK 中自带的 java 监控和管理控制台 ■ 用于对 JVM 中内存、线程和类等的监控,是一个基于 JMX(java management extensions) 的 GUI 性能监控工具 ■ 官方教程:https://docs.oracle.com/javase/7/docs/technotes/guides/management/jconsole.html ■ jdk/bin 目录下,启动 jconsole.exe 命令即可 ■ 不需要使用 jps 命令来查询 ■ Local 使用 JConsole 连接一个正在本地系统运行的JVM,并且执行程序的和运行JConsole的需要是同一个用户。JConsole使用文件系统的授权通过RMI连接器连接到平台的MBean服务器上。这种从本地连接的监控能力只有Sun的JDK具有 ■ Remote 使用下面的 URL 通过RMI连接器连接到一个JMX代理, service:jmx:rmi///jndi/rmi://hostName:portNum/jmxrmi JConsole为建立连接,需要在环境变量中设置 mx.remote.credentials来指定用户名和密码,从而进行授权 ■ Advanced 使用一个特殊的URL连接JMX代理。一般情况使用自己定制的连接器而不是RMI提供的连接器来连接JMX代理,或者是一个使用JDK1.4的实现了JMX和JMX Rmote的应用 ■ Visual VM 是一个功能强大的多合一故障诊断和性能监控的可视化工具 ■ 它集成了多个 JDK命令行工具,使用 Visual VM 可用于显示虚拟机进程及进程的配置和环境信息(jps,jinfo),监视应用程序的 CPU、GC、堆、方法区及线程的信息( jstat、 jstack)等,甚至代替 JConsole ■ 在 JDK6 Update 7以后, Visual VM 便作为 JDK的一部分发布( Visual VM 在 JDK/bin目录下),即:它完全免费 ■ 此外,Visual VM 也可以作为独立的软件安装 ■ 首页:https://visualvm.github.io/index.html ■ Visual VM的一大特点是支持插件扩展,并且插件安装非常方便。我们既可以通过离线下载插件文件 *.nbm,然后在 Plugin对话框的已下载页面下,添加已下载的插件。也可以在可用插件页面下,在线安装插件。(这里建议安装上: VisualGC) ■ 插件地址:https://visualvm.github.io/pluginscenters.html ■ IDEA 安装 VisualVM Launcher 插件 Preferences --> Plugins --> 搜索 VisualVM Launcher,安装重启即可 ①、本地连接 监控本地 java 进程的 CPU、类、线程等 ②、远程连接 ■ 确定远程服务器的 ip 地址 ■ 添加 JMX(通过 JMX 技术具体监控远端服务器哪个 java 进程) ■ 修改 bin/catalina.sh 文件,连接远程的 tomcat ■ 在 …/conf 中添加 jmxremote.access 和 jmxremote.password 文件 ■ 将服务器地址改为公网 ip 地址 ■ 设置阿里云安全策略和防火墙策略 ■ 启动 tomcat,查看 tomcat 启动日志和端口监听 ■ JMX 中输入端口号、用户名、密码 登录 1、生成/读取堆内存快照 2、查看 JVM 参数和系统属性 3、查看运行中的虚拟机进程 4、生成/读取线程快照 5、程序资源的实时监控 6、其他功能 ■ JMX代理连接 ■ 远程环境监控 ■ CPU 分析和内存分析 ■ MAT( Memory Analyzer Tool)工具是一款功能强大的ava堆内存分析器。可以用于查找内存泄漏以及查看内存消耗情况 ■ MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用。是款免费的性能分析工具,使用起来非常方便。大家可以在https://www.eclipse.org/mat/downloads.php下载并使用MAT。 ■ 只要确保机器上装有 JDK 并配置好相关的环境变量,MAT 可正常启动。还可以在 Eclipse 中以插件的方式安装 ①、dump文件内容 ■ MAT可以分析 heap dump文件。在进行内存分析时,只要获得了反映当前设备内存映像的 hprof 文件,通过MAT 打开就可以直观地看到当前的内存信息 ■ 一般说来,这些内存信息包含 ● 所有的对象信息,包括对象实例、成员变量、存储于栈中的基本类型值和存储于堆中的其他对象的引用值 ● 所有的类信息,包括classloader、类名称、父类、静态变量等 ● GCRoot到所有的这些对象的引用路径 ● 线程信息,包括线程的调用栈及此线程的线程局部变量(TLS) ②、两点说明 说明1:缺点: MAT 不是一个万能工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,例如Sun,HP,SAP所采用的 HPROF二进制堆存储文件,以及 IBM 的 PHD 堆存储文件等都能被很好的解析 说明2: 最吸引人的还是能够快速为开发人员生成内存泄漏报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析也没有简单到一键完成的程度,很多内存问题还是需要我们从MAT展现给我们的信息当中通过经验和直觉来判断才能发现 ③、获取dump文件 ■ 方法一:通过前一章介绍的jmap工具生成,可以生成任意一个java进程的dump文件 ■ 方法二:通过配置JM参数生成 ● 选项”-XX:+HeapDumpOnOutOfMemoryError"或 “-XX:+HeapDumpBeforeFullGC” ● 选项”-XX:HeapDumpPath"所代表的含义就是当程序出现 OutOfMemory时,将会在相应的目录下生成一份dump文件。如果不指定选项"-XX:HeapDumpPath”则在当前目录下生成dump文件 ■ 对比:考虑到生产环境中几乎不可能在线对其进行分析,大都是采用离线分析,因此使用jmap+MAT工具是最常见的组合 ■ 方法三:使用 VisualVM可以导出堆dump文件 ■ 方法四:使用MAT既可以打开一个已有的堆快照,也可以通过MAT直接从活动Java程序中导出堆快照。该功能将借助jps列出当前正在运行的Java进程,以供选择并获取快照 ①、histogram ■ 展示了各个类的实例数目以及这些实例的 Shallow heap 或 Retained heap 的总和 ■ MAT的直方图和 jmap的 -histo子命令一样,都能够展示各个类的实例数目以及这些实例的 Shallow heap总和。但是,MAT的直方图还能够计算 Retained heap,并支持基于实例数目或 Retained heap的排序方式(默认为Shallow heap) ■ 此外,MAT还可以将直方图中的类按照超类、类加载器或者包名分组 ■ 当选中某个类时,MAT界面左上角的 Inspector窗口将展示该类的 Class 实例的相关信息,如类加载器等 ②、thread overview ■ 查看系统中的 Java 线程 ■ 查看局部变量的信息 ③、获得对象相互引用的关系 ■ with outgoing references ■ with incoming references ④、浅堆与深堆 ■ shallow heap ● 浅堆( Shallow Heap)是指一个对象所消耗的内存。在32位系统中,一个对象引用会占据4个字节,一个int类型会占据4个字节,long型变量会占据8个字节,每个对象头需要占用8个字节。根据堆快照格式不同,对象的大小可能会向8字节进行对齐 ● 以 String为例:2个int值共占8字节,对象引用占用4字节,对象头8字节,合计20字节,向8字节对齐,故占24字节。(jdk7中) ● 这24字节为 String对象的浅堆大小。它与 String的value实际取值无关,无论字符串长度如何,浅堆大小始终是24字节 ■ retained heap ● 保留集( Retained Set): 对象A的保留集指当对象A被垃圾回收后,可以被释放的所有的对象集合(包括对象A本身),即对象A的保留集可以被认为是只能通过对象A被直接或间接访问到的所有对象的集合。通俗地说,就是指仅被对象A所持有的对象的集合 ● 深堆( Retained Heap): 深堆是指对象的保留集中所有的对象的浅堆大小之和 ● 注意:浅堆指对象本身占用的内存,不包括其内部引用对象的大小。一个对象的深堆指只能通过该对象访问到的(直接或间接)所有对象的浅堆之和,即对象被回收后,可以释放的真实空间 ■ 补充:对象实际大小 ● 另外一个常用的概念是对象的实际大小。这里,对象的实际大小定义为一个对象所能触及的所有对象的浅堆大小之和,也就是通常意义上我们说的对象大小。与深堆相比,似乎这个在日常开发中更为直观和被人接受,但实际上,这个概念和垃圾回收无关 ● 下图显示了一个简单的对象引用关系图,对象A引用了C和D,对象B引用了C和E。那么对象A的浅堆大小只是A本身,不含C和D,而A的实际大小为A、C、D三者之和。而A的深堆大小为A与D之和,由于对象C还可以通过对象B访问到,因此不在对象A的深堆范围内 ■ 练习 看图理解 Retained Size 上图中,GC Roots 直接引用了 A 和 B 两个对象 A对象的 Retained Size = A 对象的 Shallow Size B对象的 Retained Size = B 对象的 Shallow Size + C 对象的 Shallow Size 这里不包括D对象,因为D对象被 GC Roots 直接引用 ■ 案例分析:StudentTrance ⑤、支配树 支配树( Dominator Tree) 支配树的概念源自图论 ■ MAT提供了一个称为支配树( Dominator Tree)的对象图。支配树体现了对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B。如果对象A是离对象B最近的一个支配对象,则认为对象A为对象B的直接支配者。支配树是基于对象间的引用图所建立的,它有以下基本性质: ● 对象A的子树(所有被对象A支配的对象集合)表示对象A的保留集( retained set),即深堆 ● 如果对象A支配对象B,那么对象A的直接支配者也支配对象B ● 支配树的边与对象引用图的边不直接对应 ■ 如下图所示:左图表示对象引用图,右图表示左图所对应的支配树。对象A和B由根对象直接支配,由于在到对象C的路径中,可以经过A,也可以经过B,因此对象C的直接支配者也是根对象。对象F与对象D相互引用,因为到对象F的所有路径必然经过对象D,因此,对象D是对象F的直接支配者。而到对象D的所有路径中,必然经过对象C,即使是从对象F到对象D的引用,从根节点出发,也是经过对象C的所以,对象D的直接支配者为对象C ■ 同理,对象E支配对象G。达到对象H的key通过对象D,也可以通过对象E,因此对象D和对象E都不能支配对象H,而经过对象C既可以到达D也可以到达E,因此对象C为对象H的直接支配者 ■ 在 MAT 中,单击工具栏上的对象支配树按钮,可以打开对象支配树视图 ■ 下图显示了对象支配树视图的一部分。该截图显示部分 Lily 学生的 history 队列的直接支配对象。即当 Lily 对象被回收,也会一并回收的所有对象。显然能被 3 或者 5 整除的网页不会出现在该列表中,因为他们同时被另外两名学生对象引用 ①、说明 Tomcat是最常用的 Java Servlet容器之一,同时也可以当做单独的Web服务器使用。 Tomcat本身使用Java实现,并运行于Java虚拟机之上。在大规模请求时, Tomcat有可能会因为无法承受压力而发生内存溢岀错误。这里根据一个被压垮的 Tomcat的堆快照文件,来分析 Tomcat在崩溃时的内部情况 ②、分析过程 图1: 图2: 图3: 图4:可以看到 sessions 对象为 ConcurrentHashMap,其内部分为 16 个 Segment。从深堆大小看,每个 Segment 都比较平均,大约为 1MB,合计 17MB 图5: 图6:当前堆中含有 9941 个 session,并且每一个 session 的深堆为 1592 字节,合计约 15MB,达到当前堆大小的 50% 图7: 图8:使用 OQL 语句查出创建的最初的一个 session 和创建的最后一个 session 的时间 根据当前的 session 总是,可以计算每秒的平均压力为 9941/(1403324677648 - 1403324645728) / 1000 = 311次/秒 由此推断,在发生 Tomcat 堆溢出时,Tomcat在连续30秒的时间内,平均每秒接收了约 311 次不同客户端的请求,创建了合计 9941 个 session 内存泄漏的理解与分类 ■ 何为内存泄漏 可达性分析算法来判断对象是否是不再使用的对象,本质都是判断一个对象是否还被引用。那么对于这种情况下,由于代码的实现不同就会出现很多种内存泄漏问题(让JWM误以为此对象还在引用中,无法回收,造成内存泄漏) ■ 内存泄漏的理解 严格来说,只有对象不会再被程序用到了,但是GC又不能回收他们的情况,才叫内存泄漏但实际情况很多时候一些不太好的实践(或疏忽)会导致对象的生命周期变得很长甚至导致 OOM,也可以叫做宽泛意义上的”内存泄漏“ 对象 X 引用对象 Y,X 的生命周期比 Y 的生命周期长,那么当 Y 生命周期结束的时候,X 依然引用着 Y,这时候,垃圾回收是不会回收对象 Y 的;如果对象 X 还引用着生命周期比较短的 A、B、C,对象 A 又引用着对象 a,b,c,这样就可能造成大量无用的对象不能被回收,进而占据了内存资源,造成内存泄漏,直到内存溢出 ■ 内存泄漏与内存溢出的关系 1、内存泄漏( memory leak) 申请了内存用完了不释放,比如一共有1024M的内存,分配了512M的内存一直不回收,那么可以用的内存只有512M了,仿佛泄露掉了一部分通俗一点讲的话,内存泄漏就是【占着茅坑不拉shi】 2、内存溢出( out of memory) 申请内存时,没有足够的内存可以使用; 通俗一点儿讲,一个厕所就三个坑,有两个站着茅坑不走的(内存泄漏),剩下最后一个坑,厕所表示接待压力很大,这时候一下子来了两个人,坑位(内存)就不够了,内存泄漏变成内存溢出了 可见,内存泄漏和内存溢出的关系:内存泄漏的增多,最终会导致内存溢出 ■ 泄漏的分类 经常发生:发生内存泄露的代码会被多次执行,每次执行,泄露一块内存 偶然发生:在某些特定情况下才会发生 一次性:发生内存泄露的方法只会执行一次 隐式泄漏:一直占着内存不释放,直到执行结束;严格的说这个不算内存泄漏,因为最终释放掉了但是如果执行时间特别长,也可能会导致内存耗尽 Java中内存泄漏的8中情况 1、静态集合类 静态集合类,如 HashMap、 LinkedList等等。如果这些容器为静态的,那么它们的生命周期与JN程序一致,则容器中的对象在程序结束之前将不能被释放,从而造成内存泄漏。简单而言长生命周期的对象持有短生命周期对象的引用,尽管短生命周期的对象不再使用,但是因为长生命周期对象持有它的引用而导致不能被回收 2、单例模式 单例模式,和静态集合导致内存泄露的原因类似,因为单例的静态特性,它的生命周期和WM的生命周期一样长,所以如果单例对象如果持有外部对象的引用,那么这个外部对象也不会被回收,那么就会造成内存泄漏 3、内部类持有外部类 内部类有外部类,如果一个外部类的实例对象的方法返回了一个内部类的实例对象。这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但由于内部类持有外部类的实例对象,这个外部类对象将不会被垃圾回收,这也会造成内存泄漏 4、各种连接,如数据库连接、网络连接和 IO 连接等 各种连接,如数据库连接、网络连接和 IO 连接等 在对数据库进行操作的过程中,首先需要建立与数据库的连接,当不再使用时,需要调用c1ose方法来释放与数据库的连接。只有连接被关闭后,垃圾回收器才会回收对应的对象 否则,如果在访问数据库的过程中,对 Connection、 Statement或 Resultset不显性地关闭,将会造成大量的对象无法被回收,从而引起内存泄漏 5、变量不合理的作用域 变量不合理的作用域。一般而言,一个变量的定义的作用范围大于其使用范围,很有可能会造成内存泄漏。另一方面,如果没有及时地把对象设置为null,很有可能导致内存泄漏的发生 如上面这个伪代码,通过 readFromNet方法把接受的消息保存在变量msg中,然后调用 saveDB方法把msg的内容保存到数据库中,此时msg已经就没用了,由于msg的生命周期与对象的生命周期相同,此时msg还不能回收,因此造成了内存泄漏 实际上这个msg变量可以放在 receiveMsg方法内部,当方法使用完,那么msg的生命周期也就结束此时就可以回收了。还有一种方法,在使用完msg后,把msg设置为null,这样垃圾回收器也会回收msg的内存空间 6、改变哈希值 改变哈希值,当一个对象被存储进 HashSet集合中以后,就不能修改这个对象中的那些参与计算哈希值的字段了。否则,对象修改后的哈希值与最初存储进 HashSet集合中时的哈希值就不同了,在这种情况下,即使在contains方法使用该对象的当前引用作为的参数去 Hashset集合中检索对象,也将返回找不到对象的结果,这也会导致无法从 HashSet集合中单独删除当前对象,造成内存泄漏 这也是 String为什么被设置成了不可变类型,我们可以放心地把 String存入 HashSet,或者把String当做 HashMap的key值 当我们想把自己定义的类保存到散列表的时候,需要保证对象的 hashCode不可变 举例1: 案例2: 7、缓存泄漏 内存泄漏的另一个常见来源是缓存,一旦你把对象引用放入到缓存中,他就很容易遗忘。比如:之前项目在一次上线的时候,应用启动奇慢直到夯死,就是因为代码中会加载一个表中的数据到缓存(内存)中,测试环境只有几百条数据,但是生产环境有几百万的数据 对于这个问题,可以使用 WeakHashMap代表缓存,此种Map的特点是,当除了自身有对key的引用外,此key没有其他引用那么此map会自动丢弃此值 8、监听器和回调 内存泄漏第三个常见来源是监听器和其他回调,如果客户端在你实现的 API 中注册回调,却没有显示的取消,那么就会积聚 需要确保回调立即被当做垃圾回收的最佳方法时只保存它的弱引用,例如将他们保存称为 WeakHashMap 中的键 内存泄漏案例分析 案例1: ■ 案例代码: ■ 分析: 上述程序并没有明显的错误,但是这段程序有一个内存泄漏,随着GC活动的增加,或者内存占用的不断增加,程序性能的降低就会表现出来,严重时可导致内存泄漏,但是这种失败情况相对较少 代码的主要问题在pop函数,下面通过这张图示展现假设这个栈一直增长,增长后如下图所示 当进行大量的 pop 操作时,由于引用未进行置空,gc是不会释放的,如下图所示: 从上图可以看出,如果栈先增长,再收缩,那么从栈中弹出的对象将不会被当做垃圾回收,即使程序不再使用栈中的这些对象,他们也不会回收,因为栈中仍然保存着对象的引用,俗称过期引用,这个内存泄漏很隐蔽 ■ 解决办法: 改写上面代码中的 pop 方法,如下: 案例2: ■ 案例代码: ■ 分析: 上述代码是安卓应用代码,代码是创建的一个页面。当页面打开时,会调用 onCreate 方法,然后运行线程;然而,当用户点击返回按钮时,此页面应该在适当的时机被销毁,即 TestActivity 类被 GC 回收,而类中的线程会一直占用着,导致 TestActivity 类无法被 GC,导致内存溢出 ■ 解决办法: 1、使用线程时,一定要确保线程在周期性对象(如 Activity)销毁时能正常结束,如能正常结束,但是 Activity销毁后还需执行一段时间,也可能造成泄露,此时可采用 WeakReference方法来解决,另外在使用 Handler的时候,如存在Delay操作,也可以采用 WeakReference 2、使用 Handler+ HandlerThread时,记住在周期性对象销毁时调用 looper.quit()方法 MAT 支持一种类似 SQL 的查询语言(Object Query Language)。OQL 使用类 SQL 语法,可以在堆中进行对象的查找和筛选 ①、SELECT子句 ■ Select 子句: 在 MAT 中,Select 子句的格式与 SQL 基本一致,用于指定要显示的列。Select 子句中可以使用 “*”,查看结果对象的引用实例(相当于 outgoing reference) SELECT * FROM java.util.Vector v ■ 使用 “OBJECTS” 关键字,可以将返回结果集中的项以对象的形式显示 SELECT objects v.elementData FROM java.util.Vector v SELECT OBJECTS s.value FROM java.lang.String s ■ 在 Select 子句中,使用 “AS RETAINED SET” 关键字可以得到所得对象的保留集 SELECT AS RETAINED SET * FROM com.atguigu.mat.Student ■ “DISTINCT” 关键字用于在结果集中去除重复对象 SELECT DISTINCT OBJECTS classof(s) FROM java.lang.String s ②、FROM子句 ■ From 子句 From 子句用于指定查询范围,它可以指定类名、正则表达式或者对象地址 SELECT * FROM java.lang.String s ■ 下列使用正则表达式,限定搜索范围,输出所有 com.atguigu 包下所有类的实例 ■ 也可以直接使用类的地址进行搜索。使用类的地址的好处是可以区分被不同 ClassLoader 加载的同一种类型 select * from 0x37a0b4d ③、WHERE子句 ■ Where 子句 Where 子句用于指定 OQL 的查询条件。OQL 查询将只返回满足 Where 子句指定条件的对象。Where 子句的格式与传统 SQL 极为相似 ■ 下列返回长度大于10的char数组 SELECT * FROM char[] s WHERE s.@length > 10 ■ 下列返回包含 “java” 子字符串的所有字符串,使用 “LIKE” 操作符,“LIKE” 操作符的操作参数为正则表达式 ■ 下列返回所有 value 域不为 null 的字符串,使用 “=” 操作符 SELECT * FROM java.lang.String s where s.value != null ■ Where 子句支持多个条件的 AND、OR 运算。下列返回数组长度大于 15,并且深堆大于 1000 字节的所有 Vector 对象 SELECT * FROM java.util.Vector v WHERE v.elementData.@length>15 AND v.@retainedHeapSize > 1000 ④、内置对象与方法 ■ OQL中可以访问堆内对象的属性,也可以访问堆内代理对象的属性。访问堆内对象的属性时,格式如下: 其中 alias 为对象名称 ■ 访问 java.io.File 对象的 path 属性,并进一步访问 path 的 value 属性 SELECT toString(f.path.value) FROM java.io.File f ■ 下列显示了 String 对象的内容、objectid 和 objectAddress SELECT s.toString(), s.@objectId, s.@objectAddress FROM java.lang.String s ■ 下列显示 java.util.Vector 内部数组的长度 SELECT v.elementData.@length FROM java.util.Vector v ■ 下列显示了所有的 java.util.Vector 对象及其子类型 select * from INSTANCEOF java.util.Vector ①、介绍 ■ 在运行 Java的时候有时候想测试运行时占用内存情况,这时候就需要使用测试工具查看了。在eclipse里面有 Eclipse Memory Analyzer tool(MAT)插件可以测试,而在 IDEA中也有这么一个插件,就是 JProfiler ■ JProfiler是由ej-technologies公司开发的一款Java应用性能诊断工具。功能强大,但是收费 ■ 官网下载地址:https://www.ej-technologies.com/products/jprofiler/overview.html ②、特点 ■ 使用方便、界面操作友好(简单且强大) ■ 对被分析的应用影响小(提供模板) ■ CPU, Thread, Memory分析功能尤其强大 ■ 支持对 jdbc,noSql, jsp, servlet, socket等进行分析 ■ 支持多种模式(离线,在线)的分析 ■ 支持监控本地、远程的JVM ■ 跨平台,拥有多种操作系统的安装版本 ③、主要功能 ■ 方法调用 对方法调用的分析可以帮助您了解应用程序正在做什么,并找到提高其性能的方法 ■ 内存分配 通过分析堆上对象、引用链和垃圾收集能帮您修复内存泄漏问题,优化内存使用 ■ 线程和锁 JProfiler 提供多种针对线程和锁的分析视图助您发现多线程问题 ■ 高级子系统 许多性能问题都发生在更高的语义级别上。例如,对于 JDBC 调用,您可能希望找出执行最慢的 SQL 语句。JProfiler 支持堆这些子系统进行集成分析 ①、下载与安装 ■ 下载地址如下。根据不同系统以及不同版本下载 https://www.ej-technologies.com/download/jprofiler/version_100 ②、JProfiler中配置IDEA ■ 步骤: 在 JProfiler 菜单栏点击 Session → 点击 IDE Integrations → 选择自己安装的 IDEA 的版本 → 点击 Integrate → 点击 Proceed → 选择C盘下面,当前用户下面的 .IntelliJIdeaxxx 文件夹 ③、IDEA集成JProfiler ■ 第一步:在 IDEA 中安装 JProfiler 插件。插件离线下载地址:https://plugins.jetbrains.com/plugin/253-jprofiler。根据 IDEA 版本号下载对应的版本号 ■ 第二步:在 IDEA 的 Settings 下面的 Tools 下面点击 JProfiler,选中自己下载的 JProfiler 软件,点击 OK ■ 使用,在 IDEA 点击 JProfiler 的图标,即启动对应的类 ①、数据采集方式 ■ 如上图, ● Quick start:快速启动 ● Profile a demo…:表示当 JProfiler 关闭后,会报存一个 session,点击这个选项,可以打开保存的那个 session ● Attach to a ru…:表示可以运行一个当前正在运行的一个 Java 程序 ● Profile an appli…:表示可以运行一个远程的程序 ● Open a sna…:打开一个快照,比如堆快照 ■ JProfier数据采集方式分为两种: Sampling(样本采集)和 Instrumentation(重构模式),这两种模式是在上面的 Attach to a run… 打开的。也可以在 JProfile 中点击 Start Center(第一个按钮) 去打开 ● Instrumentation:这是 JProfiler全功能模式。在 class加载之前,JProfiler把相关功能代码写入到需要分析的class的by中,对正在运行的jvm有一定影响 ○ 优点:功能强大。在此设置中,调用堆栈信息是准确的 ○ 缺点:若要分析的 class较多,则对应用的性能影响较大,CPU开销可能很高(取决于Filter的控制)。因此使用此模式一般配合Filter使用,只对特定的类或包进行分析 ● Sampling:类似于样本统计,每隔一定时间(5ms)将每个线程栈中方法栈中的信息统计出来 ○ 优点:对CPU的开销非常低,对应用影响小(即使你不配置任何Filter) ○ 缺点:一些数据/特性不能提供(例如:方法的调用次数、执行时间) ■ 注: JProfiler本身没有指出数据的采集类型,这里的采集类型是针对方法调用的采集类型因为 JProfiler的绝大多数核心功能都依赖方法调用采集的数据,所以可以直接认为是JProfiler的数据采集类型 ②、遥感监测Telemetries 遥感监测 Telemetries(查看 JVM 的运行信息) ■ 整体视图 Overview:显示堆内存、cpu、线程以及 GC 等活动视图 ■ 内存 Memory:显示一张关于内存变化的活动时间表 ■ 记录的对象 Recorded objects:显示一张关于活动对象与数组的图表的活动时间表 ■ 记录吞吐量 Record Throughput:显示一段时间累计的W生产和释放的活动时间表 ■ 垃圾回收活动 GC Activity:显示一张关于垃圾回收活动的活动时间表 ■ 类Classes:显示一个与已装载类的图表的活动时间表 ■ 线程 Threads:显示一个与动态线程图表的活动时间表 ■ CPU负载 CPU Load:显示一段时间中cpU的负载图表 ③、内存视图Live Memory Live memory内存剖析:class/class instance的相关信息。例如对象的个数,大小,对象创建的方法执行栈,对象创建的热点 ■ 所有对象All Objects:显示所有加载的类的列表和在堆上分配的实例数。只有Java1.5(JVMTI)才会显示此视图 ■ 记录对象 Record Objects:查看特定时间段对象的分配,并记录分配的调用堆栈 ■ 分配访问树Allocation Call Tree:显示一棵请求树或者方法、类、包或对已选择类有带注释的分配信息的J2EE组件 ■ 分配热点Allocation Hot Spots:显示一个列表,包括方法、类、包或分配已选类的]2EE组件。你可以标注当前值并且显示差异值。对于每个热点都可以显示它的跟踪记录树 ■ 类追踪器 Class Tracker:类跟踪视图可以包含任意数量的图表,显示指定的类和包的实例与时间 ④、堆遍历heap walker ■ 类 Classes:显示所有类和它们的实例,可以右击具体的类" Used Selected Instance"实现进一步跟踪 ■ 分配 Allocations:为所有记录对象显示分配树和分配热点 ■ 索引 References:为单个对象和“显示到垃圾回收根目录的路径”提供索引图的显示功能。还能提供合并输入视图和输出视图的功能 ■ 时间 Time:显示一个对已记录对象的解决时间的柱状图 ■ 检查 Inspections:显示了一个数量的操作,将分析当前对象集在某种条件下的子集,实质是一个筛选的过程 ■ 图表 Graph:你需要在 references视图和 biggest视图手动添加对象到图表,它可以显示对象的传入和传出引用能方便的找到垃圾收集器根源 PS:在工具栏点击" Go To Start"可以使堆内存重新计数,也就是回到初始状态 ⑤、cpu视图cpu views ■ Profiler提供不同的方法来记录访问树以优化性能和细节。线程或者线程组以及线程状况可以被所有的视图选择。所有的视图都可以聚集到方法、类、包或J2EE组件等不同层上 ■ 访问树 Call Tree:显示一个积累的自顶向下的树,树中包含所有在W中已记录的访问队列。JDBC,JMS和JNDI服务请求都被注释在请求树中。请求树可以根据 Servlet和JSP对URL的不同需要进行拆分 ■ 热点 Hot Spots:显示消耗时间最多的方法的列表。对每个热点都能够显示回溯树。该热点可以按照方法请求,JDBC、JMS和JNDI服务请求以及按照URL请求来进行计算 ■ 访问图 Call Graph:显示一个从已选方法、类、包或 J2EE组件开始的访问队列的图 ■ 方法统计 Method statistis:显示一段时间内记录的方法的调用时间细节 ⑥、线程视图threads ■ JProfiler通过对线程历史的监控判断其运行状态,并监控是否有线程阻塞产生,还能将一个线程所管理的方法以树状形式呈现。对线程剖析 ■ 线程历史 Thread History 显示一个与线程活动和线程状态在一起的活动时间表 ■ 线程监控 Thread Monitor 显示一个列表,包括所有的活动线程以及它们目前的活动状况 ■ 线程转储 Thread Dumps 显示所有线程的堆栈跟踪 ■ 线程分析主要关系三个方面: ● web 容器的线程最大数。比如:Tomcat的线程容量应该略大于最大并发数 ● 线程阻塞 ● 线程死锁 ⑦、监视器&锁 Monitors&locks 监控和锁 Monitors& Locks所有线程持有锁的情况以及锁的信息。 观察JVM的内部线程并查看状态 ● 死锁探测图表 Current Locking Graph:显示JVM中的当前死锁图表 ● 目前使用的监测器 Current monitors:显示目前使用的监测器并且包括它们的关联线程 ● 锁定历史图表 Locking History Graph:显示记录在JVM中的锁定历史 ● 历史检测记录 Monitor History:显示重大的等待事件和阻塞事件的历史记录 ● 监控器使用统计 Monitor Usage Statistics:显示分组监测,线程和监测类的统计监测数据 **案例1:**这个程序会正常运行 **案例2:**由于 Bean 类中有一个 static 的 list,所以内存会越来越大,最后导致内存溢出 ①、背景 ■ 前面我们介绍了jdk自带的jvisualvm等免费工具以及商业化工具 JProfiler ■ 这两款工具在业界知名度也比较高,他们的优点是可以图形界面上看到各维度的性能数据,使用者根据这些数据进行综合分析,然后判断哪里出现了性能问题 ■ 但是这两款工具也有个缺点,都必须在服务端项目进程中配置相关的监控参数。然后工具通过远程连接到项目进程,获取相关的数据。这样就会带来一些不便,比如线上环境的网络是隔离的,本地的监控工具根本连不上线上环境。并且类似于 JProfiler这样的商业工具,是需要付费的 那么有没有一款工具不需要远程连接,也不需要配置监控参数,同时也提供了丰富的性能监控数据呢 ■ 今天跟大家介绍一款阿里巴巴开源的性能分析神器 Arthas(阿尔萨斯) ②、概述 ■ Arthas(阿尔萨斯)是 Alibaba开源的Java诊断工具,深受开发者喜爱。在线排查问题,无需重启;动态跟踪Java代码;实时监控JVM状态 ■ Arthas支持]DK6+,支持 Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的Tab自动补全功能,进一步方便进行问题的定位和诊断 ■ 当你遇到以下类似问题而束手无策时, Arthas可以帮助你解决 ● 这个类从哪个jar包加载的?什么会报各种类相关的 Exception? ● 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了? ● 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗? ● 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现! ● 是否有一个全局视角来查看系统的运行状况? ● 有什么办法可以监控到 JVM的实时运行状态? ● 怎么快速定位应用的热点,生成火焰图? ③、基于哪些工具开发而来 ■ greys- anatomy: Arthas代码基于 Greys二次开发而来,非常感谢 Greys之前所有的工作,以及 Greys原作者对 Arthas提出的意见和建议! ■ termd: Arthas的命令行实现基于 termd开发,是一款优秀的命令行程序开发框架,感谢termd提供了优秀的框架 ■ crash: Arthas的文本渲染功能基于 crash中的文本渲染功能开发,可以从这里看到源码,感谢crash在这方面所做的优秀工作 ■ cli: Arthas的命令行界面基于vert.x提供的cli库进行开发,感谢vert.x在这方面做的优秀工作 ■ compiler Arthas里的内存编绎器代码来源 ■ Apache Commons Net Arthas里的 Telnet client代码来源 ■ JavaAgent:运行在main方法之前的拦截器,它内定的方法名叫 premaIn,也就是说先执行premain方法然后再执行main方法 ■ ASM:一个通用的Java字节码操作和分析框架。它可以用于修改现有的类或直接以二进制形式动态生成类。ASM提供了一些常见的字节码转换和分析算法,可以从它们构建定制的复杂转换和代码分析工具。ASM提供了与其他Java字节码框架类似的功能,但是主要关注性能。因为它被设计和实现得尽可能小和快,所以非常适合在动态系统中使用(当然也可以以静态方式使用,例如在编译器中) ④、官方使用文档 https://arthas.aliyun.com/zh-cn/ ①、安装 **安装方式一:**可以直接在 Linux 上通过命令下载 可以在官方 Github 上进行下载,如果速度较慢,可以尝试国内的码云 Gitee 下载 ● github 下载 wget https://alibaba.github.io/arthas/arthas-boot.jar ● Gitee 下载 wget https://arthas.gitee.io/arthas-boot.jar 安装方式二: 也可以在浏览器直接访问https://alibaba.github.io/arthas/arthas-boot.jar,等待下载成功后,上传到 Linux服务器上 卸载: 在 Linux/Unix/Mac 平台,删除下面文件: rm -rf ~/.arthas/ rm -rf ~/logs/arthas Windows 平台直接删除 user home 下面的 .arthas 和 logs/arthas 目录 ②、工程目录:官网的文档涉及的目录结构(github里面的目录) ③、启动 ■ Arthas只是一个java程序,所以可以直接用java -jar运行。 ■ 执行成功后, arthas提供了一种命令行方式的交互方式, arthas会检测当前服务器上的Java进程,并将进程列表展示出来,用户输入对应的编号(1、2、3、4…)进行选择,然后回车,比如: ■ 方式1: java -jar arthas-boot.jar #选择进程(输入[ ]内编号(不是PID)回车),如下面有 4 个进程,输入哪个就监控哪个 [INFO] arthas-boot version: 3.1.4 [INFO] Found existing java process, please choose one and hit RETURN. * [1] : 11616 com.Arthas [2] : 8676 [3] : 16200 org.jetbrains.jps.cmdline.Launcher ■ 方式2:运行时选择 Java 进程 PID java -jar arthas-boot.jar [PID] ④、查看进程 ⑤、查看日志 cat ~/logs/arthas/arthas.log ⑥、参考帮助 java -jar arthas-boot.jar -h ⑦、web console ■ 除了在命令行查看外,Arthas 目前还支持 Web Console。在成功启动连接进程之后就已经自动启动,可以直接访问 http://127.0.0.1:8563/ 访问,页面上的操作模式和控制台完全一样 ⑧、退出 最后一行 [arthas@7457]$,说明打开进入了监控客户端,在这里就可以执行相关命令进行查看了。 ● 使用 quit / exit:退出当前客户端 ● 使用 stop / shutdown:关闭arthas服务端,并退出所有客户端 ①、基础指令 ②、jvm相关 dashboard dashboard -i 500 -n 4:-i 表示间隔多少时间打印一次,这里是500 ms,-n 表示总共打印多少次,这里是4次 thread thread 1:表示查看线程为 1 的情况 thread -b:表示查看当前所有线程中,状态为 block(阻塞) 的线程 thread -i 5000:表示隔5秒钟统计一下线程对 CPU 的利用率 thread -n 5:表示显示线程对 CPU 的占用率的前 5 个 jvm 其他 heapdump /tmp/OOMTest.hprof:打印当前进程的堆转储文件(dump文件)。如果指向获取活跃对象的dump文件,可以加一个 --live 参数,如:heapdump --live /tmp/OOMTest.hprof ③、class/classloader相关 sc sc命令:查看 JVM 已加载的类信息 ● https://arthas.aliyun.com/doc/sc ● 常用参数: class-pattern 类名表达式匹配 -d 输出当前类的详细信息,包括这个类所加载的原始文件来源、类的声明、加载的 ClassLoader 等详细信息。如果一个类被多个 ClassLoader 所加载,则会出现多次 -E 开启正则表达式匹配,默认为通配符匹配 -f 输出当前类的成员变量信息(需要配合参数 -d 一起使用) -x 指定输出静态变量时属性的遍历深度,默认为0,即直接使用 toString 输出 ● 举例: sc com.atguigu.java.Picture sc com.atguigu.java.* sc -d com.atguigu.java.Picture 补充: 1、class-pattern支持全限定名,如 com.test.AAA,也支持 com/test/AAA 这样的格式,这样,我们从异常堆栈里面把类名拷贝过来的时候,不需要再手动把 / 替换成 . 了 2、sc 默认开启了子类匹配功能,也就是说所有当前类的子类也会被搜索出来,想要精确的匹配,请打开 option disable-sub-class true 开关 sm sm 命令:查看已加载类的方法信息 ● https://arthas.aliyun.com/doc/sm ● sm 命令只能看到由当前类所声明(declaring)的方法,父类则无法看到。 ● 常用参数: class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 -d 展示每个方法的详细信息 -E 开启正则表达式匹配,默认为通配符匹配 ● 举例: sm com.atguigu.java.Picture sm com.atguigu.java.Picture getPixels sm -d com.atguigu.java.Picture jad jad 命令:反编译指定已加载类的源码 ● https://arthas.aliyun.com/doc/jad ● 在 Arthas Console上,反编译出来的源码是带语法高亮的,阅读更方便 ● 当然,反编译岀来的java代码可能会存在语法错误,但不影响你进行阅读理解 ● 举例:jad java.lang.String jad java.lang.String compareTo mc、redefine mc命令:Memory Compiler 内存编译器,编译 .java 文件生成 .class https://arthas.aliyun.com/doc/mc 举例:mc /tmp/Test.java redefine命令:加载外部的 .class 文件,redefine jvm 已加载的类。即替换现有 JVM 中已加载的类 https://arthas.aliyun.com/doc/redefine 推荐使用 retransform 命令 举例: redefine /tmp/Test.class redefine -c 327a647b /tmp/Test.class /tmp/Test$Inner.class classloader classloader命令:查看classloader的继承树,urls,类加载信息 ● https://arthas.aliyun.com/doc/classloader ● 了解当前系统中有多少类加载器,以及每个加载器加载的类数量,帮助您判断是否有类加载器泄漏 ● 常用参数 -t:查看 classloader的继承树 -l:按类加载实例查看统计信息 -c:用classloader对应的 hashcode来查看对应的 jar urls ● 举例: classloader ④、monitor/watch/trace相关 monitor monitor命令:方法执行监控 ● 对匹配 class-pattern / method-pattern 的类、方法的调用进行监控。涉及方法的调用次数、执行时间、失败率等 ● https://arthas.aliyun.com/doc/monitor ● monitor 命令是一个非实时返回命令 ● 常用参数 class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 -c 统计周期,默认值为 120 秒 ● 举例:monitor com.atguigu.java.Picture 或 monitor -c 5 com.atguigu.java.Picture trace trace命令:方法内部调用路径,併输出方法路径上的每个节点上耗时 ● https://arthas.aliyun.com/doc/trace 补充说明: ● trace命令能主动搜索 class- pattern/ method- pattern对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路 ● trace 能方便的帮助你定位和发现因RT高而导致的性能问题缺陷,但其每次只能跟踪级方法的调用链路 ● trace在执行的过程中本身是会有一定的性能开销,在统计的报告中并未像 JProfiler一样预先减去其自身的统计开销。所以这统计出来有些许的不准,渲染路径上调用的类、方法越多,性能偏差越大。但还是能让你看清一些事情的 ● 参数说明 class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 condition-express 条件表达式匹配 -n 命令执行次数 #cost 方法执行耗时 ● 举例: trace com.atguigu.java.Picture watch watch命令:方法执行数据观测 ● https://arthas.aliyun.com/doc/watch ● 让你能方便的观察到指定方法的调用情况。能观察到的范围为:返回值、抛出异常、入参,通过编写 groovy表达式进行对应变量的查看 ● 常用参数 class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 express 观察表达式 condltion-express 条件表达式 -b 在方法调用之前观察(默认关闭) -e 在方法异常之后观察(默认关闭) -s 在方法返回之后观察(默认关闭) -f 在方法结束之后(正常返回和异常返回)观察(默认开启) -x 指定输岀结果的属性遍历深度,默认为0 #cost 方法执行耗时 ● 说明:这里重点要说明的是观察表达式,观察表达式的构成主要由ognl表达式组成所以你可以这样写"{ params, returnObj}",只要是一个合法的ognl表达式,都能被正常支持 ● 举例:watch 全限定类名 方法名 returnObj watch com.atguigu.java.Picture watch com.atguigu.java.Picture “{params, returnObj}” -x 2 stack stack 命令:输出当前方法被调用的调用路径 ● https://arthas.aliyun.com/doc/stack ● 常用参数 class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 condition-express 条件表达式 -n 执行次数限制 #cost 方法执行耗时 ● 举例: stack test.arthas.TestStack doGet tt tt命令:方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测 ● https://arthas.aliyun.com/doc/tt ● TimeTunnel的缩写 ● 常用参数 -t 表明希望记录下类 *Test 的 print 方法的每次执行情况 -n 3 指定你需要记录的次数,当达到记录次数时 Arthas会主动中断tt命令的记录过程,避免人工操作无法停止的情况 -s 筛选指定方法的调用信息 -i 参数后边跟着对应的 INDEX 编号查看到它的详细信息 -p 重做一次调用通过 --replay-times指定调用次数,通过 --replay-interval 指定多次调用间隔(单位ms,默认10ms) ● 举例 tt -t org.apache.dubbo.demo.provider.DemoServiceImpl sayHello ⑤、其他 profiler/火焰图 ● https://arthas.aliyun.com/doc/profiler.html options 不是重点 ■ 在 Oracle收购sun之前, Oracle的 JRockit虚拟机提供了一款叫做 JRockit Mission Control的虚拟机诊断工具 ■ 在 Oracle收购sun之后, Oracle公司同时拥有了 Sun Hotspot和 JRockit两款虚拟机。根据Oracle对于Java的战略,在今后的发展中,会将 JRockit的优秀特性移植到 Hotspot上。其中,一个重要的改进就是在Sun的DK中加入了 JRockit的支持 在oracle JDK 7u40之后, Mission Control这款工具已经绑定在oracle JDK中发布 ■ 自Java11开始,本节介绍的 JFR已经开源。但在之前的Java版本,JFR属于Commercial Feature,需要通过Java虚拟机参数 -XX:+UnlockCommercialFeatures 开启 ■ 如果你有兴趣请可以查看 OpenJDK的 Mission Control项目:https://github.com/JDKMissionControl/jmc ■ Mission Control 位于 %JAVA_HOME%/bin/jmc.exe,打开这款软件,即 JDK 安装目录下的 bin 目录下 ■ Java Mission Control(简称 JMC),Java官方提供的性能强劲的工具。是一个用于对Java应用程序进行管理、监视、概要分析和故障排除的工具套件 ■ 它包含一个GUI客户端,以及众多用来收集Java虚拟机性能数据的插件,如JMX Console(能够访问用来存放虚拟机各个子系统运行数据的 MXBeans),以及虚拟机内置的高效profiling工具 Java Flight Recorder(JFR) ■ JMC的另一个优点就是:采用取样,而不是传统的代码植入技术,对应用性能的影响非常非常小完全可以开着JMC来做压测(唯一影响可能是full gc多了) ■ 如果是远程服务器,使用前要开 JMX -Dcom.sun.management.jmxremote.port=${YOUR_PORT} -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${YOUR HOST/IP} ■ 文件 -> 连接 -> 创建新连接,填入上面 JMX 参数的 host 和 port ■ Java Flight Recorder是JMC的其中一个组件 ■ Java Flight Recorder能够以极低的性能开销收集Java虚拟机的性能数据 ■ JFR 的性能开销很小,在默认配置下平均低于1%。与其他工具相比,JFR能够直接访问虚拟机内的数据,并且不会影响虚拟机的优化。因此,它非常适用于生产环境下满负荷运行的Java程序 ■ Java Flight Recorder和 JDK Mission Control共同创建了一个完整的工具链。JDK Mission control可对 Java Flight Recorder连续收集低水平和详细的运行时信息进行高效详细的分析 ①、事件类型 ■ 当启用时,JFR将记录运行过程中发生的一系列事件。其中包括Java层面的事件,如线程事件、锁事件,以及Java虚拟机内部的事件,如新建对象、垃圾回收和即时编译事件 ■ 按照发生时机以及持续时间来划分,JFR的事件共有四种类型,它们分别为以下四种 1、瞬时事件( Instant Event),用户关心的是它们发生与否,例如异常、线程启动事件 2、持续事件( Duration Event),用户关心的是它们的持续时间,例如垃圾回收事件 3、计时事件( Timed Event),是时长超出指定阈值的持续事件 4、取样事件( Sample Event),是周期性取样的事件 取样事件的其中一个常见例子便是方法抽样( Method Sampling),即每隔一段时间统计各个线程的栈轨迹。如果在这些抽样取得的栈轨迹中存在一个反复出现的方法,那么我们可以推测该方法是热点方法 ②、启动方式 ■ 方式1:使用 -XX:StartFlightRecording=参数 ● 第一种是在运行目标Java程序时添加-XX:StartFlightRecording=参数 ● 比如:下面命令中,JFR将会在Java虚拟机启动5s后(对应delay=5s)收集数据,持续20s(对应 duration=20s)。当收集完毕后,JFR会将收集得到的数据保存至指定的文件中(对应filename=myrecording. jfr) java -XX:StartFlightRecording=delay=5s, duration=20s, filename=myrecording. jfr,settings=profile MyApp ● 由于 JFR将持续收集数据,如果不加以限制,那么 JFR可能会填满硬盘的所有空间。因此,我们有必要对这种模式下所收集的数据进行限制。比如: java -XX:StartFlightRecording=maxage=10m, maxsize=100m, name=SomeLabel MyApp ■ 方式2:使用 jcmd 的 JFR.* 子命令 ● 通过jcmd来让 JFR 开始收集数据、停止收集数据,或者堡存所收集的数据,对应的子命令分别为 JFR. start,JFR.stop,以及 JFR.dump ● $ jcmd JFR.start settings=profile maxage=10m maxsize=150m name=SomeLabel ● 上述命令运行过后,目标进程中的 JFR已经开始收集数据。此时,我们可以通过下述命令来导出已经收集到的数据: $ jcmd JFR.dump name=SomeLabel filename=myrecording jfr ● 最后,我们可以通过下述命令关闭目标进程中的 JFR: $ jcmd JFR.stop name=SomeLabel ■ 方式3:JMC 的 JFR 插件 ③、Java Flight Recorder 取样分析 ■ 要采用取样,必须先添加参数: ● -XX:+UnlockCommercialFeatures ● -XX:+FlightRecorder 否则:会报如下错: ■ 取样时间默认1分钟,可自行按需调整,事件设置选为 profiling,然后可以设置取样 profile 哪些信息,比如: ● 加上对象数量的统计: Java Virtual Machine -> GC -> Detailed-> Object Count/object Count after GC ● 方法调用采样的间隔从10ms改为1ms(但不能低于1ms,否则会影响性能了):Java Virtual Machine -> Profiling -> Method Profiling Sample/Method Sampling Information ● Socket 与 File 采样,10ms太久,但即使改为1ms也未必能抓住什么,可以干脆取消掉Java Application->File Read/FileWrite/Socket Read/Socket Write ■ 然后就开始 Profile,到时间后 Profile 结束,会自动把记录下载回来,在 JMC 中展示 从展示中,我们大致可以读到内存和 CPU 信息、代码、线程和IO等比较重要的信息展示 ■ 代码 ■ IO ■ 在追求极致性能的场景下,了解你的程序运行过程中cpu在千什么很重要,火焰图就是一种非常直观的展示cpu在程序整个生命周期过程中时间分配的工具 ■ 火焰图对于现代的程序员不应该陌生,这个工具可以非常直观的显示出调用栈中的CPU消耗瓶颈 ■ 网上的关于java火焰图的讲解大部分来自于 Brendan Gregg的博客: http://www.brendangregg.com/flamegraphs.html 火焰图,简单通过 X 轴横条宽度来度量时间指标,y 轴代表线程栈的层次 ■ 案例: 使用JDK自身提供的工具进行 JVM调优可以将TPS 由2.5提升到28(提升了7倍),并准确定位系统瓶颈; 系统瓶颈有:应用里静态对象不是太多、有大量的业务线程在频繁创建一些生命周期很长的临时对象代码里有问题。 那么,如何在海量业务代码里边准确定位这些性能代码?这里使用阿里开源工具 PRofiler来定位这些性能代码,成功解决掉了GC过于频繁的性能瓶颈,并最终在上次优化的基础上将 TPS再提升了4倍,即提升到100 ■ TProfiler配置部署、远程操作、日志阅读都不太复杂,操作还是很简单的。但是其却是能够起到一针见血、立竿见影的效果,帮我们解决了GC过于频繁的性能瓶颈 ■ TProfiler最重要的特性就是能够统计出你指定时间段内JWM的 top method,这些top method极有可能就是造成你JVM性能瓶颈的元凶。这是其他大多数JVM调优工具所不具备的,包括 JRockit Mission Control。 JRokit首席开发者 Marcus Hirt在其私人博客《Low Overhead Method Profiling with Java Mission Control》下的评论中曾明确指出JRMC并不支持TOP方法的统计 ■ TProfiler 的下载: https://github.com/alibaba/TProfiler Java运行时追踪工具 ■ 常见的动态追踪工具有 BTRace、 HouseMD(该项目已经停止开发)、 Greys-Anatomy(国人开发,个人开发者)、 Byteman( JBoss出品),注意]ava运行时追踪工具并不限于这几种,但是这几个是相对比较常用的 ■ BTRace是 SUN Kenai云计算开发平台下的一个开源项目,旨在为java提供安全可靠的动态跟踪分析工具。先看一下 BTRace的官方定义 ■ BTrace is a safe, dynamic tracing tool for the Java platform. BTrace can be used to dynamically trace a running Java program(similar to DTrace for OpenSolaris applications and OS).BTrace dynamically instruments the classes of the target application to inject tracing code(“bytecode tracing”) ■ 简洁明了,大意是一个Java平台的安全的动态追踪工具。可以用来动态地追踪一个运行的Java程序BTRace动态调整目标应用程序的类以注入跟踪代码(“字节码跟踪”)。 ■ 特点 ● 比较稳定,后续版本基本不会变化 ● 以 - 开头 ■ 各种选项 ● windows 命令窗口下运行 java 或 java -help 可以看到所有的标准选项 ■ 补充内容 ● -server 和 -client ● Hotspot JVM有两种模式,分别是 server 和 client,分别通过- server和- client模式设置: 1、在32位 Windows系统上,默认使用 Client类型的JVM。要想使用Serνer模式,则机器配置至少有2个以上的CPU和2G以上的物理内存。client模式适用于对内存要求较小的桌面应用程序,默认使用 Serial 串行垃圾收集器 2、64位机器上只支持 server模式的 JVM,适用于需要大内存的应用程序,默认使用并行垃圾收集器 ● 关于 server和client的官网介绍为: https://docs.oracle.com/javase/8/docs/technotes/guides/vm/server-class.html ■ 特点 ● 非标准化参数 ● 功能还是比较稳定的,但官方说后续版本可能会变更 ● 以 -X 开头 ■ 各种选项 ● 运行 java -X 命令可以看到所有的 X 选项 ■ JVM的 JIT 编译模式相关的选项 ● -Xint:禁用 JIT,所有的字节码都被解释执行,这个模式的速度最慢的 ● -Xcomp:所有字节码第一次使用就都被编译成本地代码,然后再执行 ● -Xmixed:混合模式,默认模式,让 JIT 根据程序运行的情况,有选择地将某些代码 ■ 特别地 ● -Xmx -Xms -Xss 属于 XX 参数 ● -Xms:设置初始 Java 堆大小,等价于 -XX:InitialHeapSize ● -Xmx:设置最大 Java 堆大小,等价于 -XX:MaxHeapSize ● -Xss:设置 Java 线程堆栈大小,等价于 -XX:ThreadStackSize ■ 特点 ● 非标准化参数 ● 使用的最多的参数类型 ● 这类选项属于实验性,不稳定 ● 以 -XX 开头 ■ 作用 ● 用于开发和调试 JVM ■ 分类 ● Boolean 类型格式 ○ -XX:+:表示启用 option 属性 ○ -XX:-:表示禁用 option 属性 ○ 举例: -XX:+UseParallelGC:选择垃圾收集器为并行收集器 -XX:+UseG1GC:表示启用 G1 收集器 -XX:+UseAdaptiveSizePolicy:自动选择年轻代区大小和相应的 Survivor 区比例 ○ 说明:因为有的指令默认是开启的,所以可以使用 -关闭 ● 非 Boolean 类型格式(key-value类型) ○ 子类:1:数值型格式 -XX:= number 表示数值,number可以带上单位,比如:‘m’,‘M’ 表示兆,‘k’,‘K’ 表示 kb,‘g’,‘G’ 表示 g(例如:32k 跟 32768 是一样的效果) 例如: -XX:NewSize=1024m:表示设置新生代初始大小为 1024 兆 -XX:MaxGCPauseMillis=500:表示设置 GC 停顿时间:500毫秒 -XX:GCTimeRatio=19:表示设置吞吐量 -XX:NewRatio=2:表示新生代与老年代的比例 ○ 子类型2:非数值型格式 -XX:= 例如: -XX:HeapDumpPath=/usr/local/heapdump.hprof:用来指定 heap 转存文件的存储路径 ■ 特别地 ● -XX:+PrintFlagsFinal ○ 输出所有参数的名称和默认值 ○ 默认不包括 Diagnostic 和 Experimental 的参数 ○ 可以配合 -XX:+UnlockDiagnosticVMOptions 和 -XX:UnlockExperimentalVMOptions 使用 ■ 第一步:在 Eclipse 中的类中点右键,选择 Run Configurations… ■ 第二步:选择需要测试的类和方法 ■ 第三步:设置 JVM 参数,上面那个栏目设置的是 main 方法的入参 ■ 第一步:在 IDEA 中的 Run 菜单栏中点击 Edit Configurations… ■ 第二步:选择测试的类以及输入 JVM 参数 ■ Linux 系统下可以在 tomcat/bin/catalina.sh 中添加类似如下配置: JAVA_OPTS=“-XMs12M -Xmx1024M” ■ Windows 系统下在 catalina.bat 中添加类似如下配置: set “JAVA_OPTS=-Xms512M -Xmx1024M” ■ 使用 jinfo -flag = 设置非Boolean类型参数 ■ 使用 jinfo -flag [+|-] 设置 Boolean 类型参数 ■ -XX:+PrintCommandLineFlags:可以让在程序运行前打印出用户手动设置或者 JVM 自动设置的 XX 选项 ■ -XX:+PrintFlagInitial:表示打印出所有 XX 选项的默认值 ■ -XX:+PrintFlagsFinal:表示打印出 XX 选项在运行程序时生效的值 ■ -XX:+PrintVMOptions:打印 JVM 的参数 ■ 栈 -Xss128k:设置每个线程的栈大小为 128k。等价于 -XX:ThreadStackSize=128k ■ 堆内存 -Xms3550m:等价于 -XX:InitialHeapSize,设置 JVM 初始堆内存为 3550M -Xmx3550m:等价于 -XX:MaxHeapSize,设置 JVM 最大堆内存为 3550M -Xmn2g:设置年轻代大小为 2G,官方推荐配置为整个堆大小的 3/8 -XX:NewSize=1024m:设置年轻代初始值为 1024M -XX:MaxNewSize=1024m:设置年轻代最大值为 1024M -XX:SurvivorRatio=8:设置年轻代中 Eden 区与一个 Survivor 区的比值,默认为 8 -XX:+UseAdaptiveSizePolicy:自动选择各区大小比例 -XX:NewRatio=4:设置老年代与年轻代(包括1个Eden和2个Survivor区)的比值 -XX:PretenureSizeThreadshold=1024:设置让大于此阈值的对象直接分配在老年代,单位为字节。只对 Serial、ParNew 收集器有效 -XX:MaxTenuringThreshold:默认值为15。新生代每次 MinorGC 后,还存活的对象年龄 +1,当对象的年龄大于设置的这个值时就进入老年代 -XX:+PrintTenuringDistribution:让 JVM 在每次 MinorGC后打印出当前使用的 Survivor 中对象的年龄分布 -XX:TargetSurvivorRatio:表示 MinorGC 结束后 Survivor 区域中占用空间的期望比例 ■ 方法区 ● 永久代: -XX:PermSize=256m:设置永久代初始值为 256M -XX:MaxPermSize=256m:设置永久代最大值为 256M ● 元空间: -XX:MetaspaceSize:初始空间大小 -XX:MaxMetaspaceSize:最大空间,默认没有限制 -XX:+UseCompressedOops:压缩对象指针 -XX:+UseCompressedClassPointers:压缩类指针 -XX:CompressedClassSpaceSize:设置 Class Metaspace的大小,默认 1G ■ 直接内存 -XX:MaxDirectMemorySize:指定 DirectMemory 容量,若为指定,则默认与 Java 堆最大值一样 ■ -XX:+HeapDumpOnOutOfMemoryError:表示在内存出现 OOM 的时候,把 Heap 转存(Dump) 到文件以便后续分析 ■ -XX:+HeapDumpBeforeFullGC:表示在出现 FullGC 之前,生成 Heap 转储文件 ■ -XX:HeapDumpPath= :指定 heap 转存文件的存储路径 ■ -XX:OnOutOfMemoryError:指定一个可行性程序或者脚本的路径,当发生 OOM 的时候,去执行这个脚本 ● 对 OnOutOfMemoryError 的运维处理,以部署在 linux 系统 /opt/Server 目录下的 Server.jar 为例 1、在 run.sh 启动脚本中添加 jvm 参数: -XX:OnOutOfMemoryError=/opt/Server/restart.sh 2、restart.sh 脚本 linux 环境: Windows 环境: ■ 查看默认垃圾收集器 ● -XX:+PrintCommandLineFlags:查看命令行相关参数(包含使用的垃圾收集器) ● 使用命令行指令:jinfo -flag 相关垃圾回收器参数 进程ID ■ Serial回收器 ● Serial 收集器作为 HotSpot 中 Client 模式下的默认新生代垃圾收集器。Serial Old 是运行在 Client 模式下默认的老年代的垃圾回收器 ● -XX:+UseSerialGC:指定年轻代和老年代都使用串行收集器。等价于新生代用 Serial GC,且老年代用 Serial Old GC。可以获得最高的单线程收集效率 ■ ParNew回收器 ● -XX:+UseParNewGC:手动指定使用 ParNew 收集器执行内存回收任务。它表示年轻代使用并行收集器,不影响老年代 ● -XX:ParallelGCThreads=N:限制线程数量,设置并行的GC的线程数。默认开启和 CPU 数据相同的线程数 ■ Parallel 回收器 ● -XX:+UseParallelGC:手动指定年轻代使用 Parallel 并行收集器执行内存回收任务 ● -XX:+UseParallelOldGC:手动指定老年代都是使用并行回收收集器 ○ 分别适用于新生代和老年代。默认 JDK8 是开启的 ○ 上面两个参数,默认开启一个,另一个也会被开启(相互激活) ● -XX:ParallelGCThreads:设置年轻代并行收集器的线程数。一般地,最好与 CPU 数量相等,以避免过多的线程数影响垃圾收集性能 ○ 在默认情况下,当 CPU 数量小于 8 个,ParallelGCThreads 的值等于 CPU 数量 ○ 当 CPU 数量大于 8 个,ParallelGCThreads 的值等于 3+[5*CPU_Count]/8 ● -XX:MaxGCPauseMillis:设置垃圾收集器最大停顿时间(即STW的时间)。单位是毫秒 ○ 为了尽可能地把停顿时间控制在 MaxGCPauseMills以内,收集器在工作时会调整 Java 堆大小或者其他一些参数 ○ 对于用户来讲,停顿时间越短体验越好。但是在服务器端,我们注重高并发,整体的吞吐量。所以服务器端适合 Parallel,进行控制 ○ 该参数使用需谨慎 -XX:GCTimeRatio:垃圾收集时间占总时间的比例(=1/(N+1))。用于衡量吞吐量的大小。 ○ 取值范围(0, 100)。默认值 99,也就是垃圾回收时间不超过 1% ○ 与前一个 -XX:MaxGCPauseMillis 参数有一定矛盾性。暂停时间越长,Ratio 参数就容量超过设定的比例 ● -XX:+UseAdaptiveSizePolicy:设置 Parallel Scavenge 收集器具有字使用调节策略 ○ 在这种模式下,年轻代的大小、Eden 和 Survivor 的比例、晋升老年代的对象年龄等参数会被自动调整,已达到在堆大小、吞吐量和停顿时间之间的平衡点 ○ 在手动调优比较困难的场合,可以直接使用这种自适应的方式,仅指定虚拟机的最大堆、目标的吞吐量(GCTimeRatio)和停顿时间(MaxGCPauseMills),让虚拟机自己完成调优工作 ■ CMS 回收器 ● -XX:+UseConcMarkSweepGC:手动指定使用 CMS 收集器执行内存回收任务 ○ 开启该参数后会自动将 -XX:+UseParNewGC打开。即:ParNew(Young区用)+CMS(old区用)+ Serial old的组合 ● -XX:CMSInitiatingOccupanyFraction:设置堆内存使用率的阈值,一旦达到该阈值,便开始进行回收 ○ JDK5及以前版本的默认值为68,即当老年代的空间使用率达到68%时,会执行一次 CMS 回收。JDK6及以上版本默认值为92% ○ 如果内存増长缓慢,则可以设置一个稍大的值,大的阙值可以有效降低CMS的触发频率,减少老年代回收的次数可以较为明显地改善应用程序性能。反之,如果应用程序内存使用率增长很快,则应该降低这个阈值,以避免频繁触发老年代串行收集器。因此通过该选项便可以有效降低Full GC的执行次数 ● -XX:+UseCMSCompactAtFullCollection:用于指定在执行完Full GC后对内存空间进行压缩整理以此避免内存碎片的产生。不过由于内存压缩整理过程无法并发执行,所带来的问题就是停顿时间变得更长了 ● -XX:CMSFUllGCsBeforeCompaction:设置在执行多少次Full GC后对内存空间进行压缩整理 ● -XX:ParallelCMSThreads:设置 CMS 的线程数量 ○ CMS 默认启动的线程数是(ParallelGCThreads+3)/4,ParallelGCThreads是年轻代并行收集器的线程数。当CPU资源比较紧张时,受到 CMS 收集器线程的影响,应用程序的性能在垃圾回收阶段可能会非常糟糕 ● 补充参数 另外,CMS 收集器还有如下常用参数: ○ -XX:ConcGCThreads:设置并发垃圾收集的线程数,默认该值是基于ParallelGCThreads计算出来的 ○ -XX:+UseCMSInitiatingOccupancyOnly:是否动态可调,用这个参数可以使CMS 一直按CMSInitiatingOccupancyFraction设定的值启动 ○ -XX:+CMSScavengeBeforeRemark:强制 hotspot虚拟机在 cms remark阶段之前做一次 minor gc,用于提高 remark阶段的速度 ○ -XX:+CMSClassUnloadingEnable:如果有的话,启用回收Perm区(JDK8之前) ○ -XX:+CMSParallelInitialEnabled:用于开启 CMS initial-mark阶段采用多线程的方式进行标记,用于提高标记速度,在 Java8开始已经默认开启 ○ -XX:+CMSParallelRemarkEnabled:用户开启 CMS remark阶段采用多线程的方式进行重新标记默认开启 ○ -XX: +ExplicitGCInvokesConcurrent、-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses:这两个参数用户指定 hotspot虚拟在执行 System.gc()时使用 CMS 周期 ○ -XX:+CMSPrecleaningEnabled:指定CMS 是否需要进行Pre cleaning这个阶段 ● 特别说明 ○ JDK9 新特性:CMS 被标记为 Deprecate 了(JEP291) 如果对 JDK9 及以上版本的 Hotspot虚拟机使用参数 -XX:+UseConcMarkSweepGC来开启 CMS 收集器的话,用户会收到一个警告信息,提示CMS未来将会被废弃。 ○ JDK14新特性:删除CMS 垃圾回收器(JEP363) 移除了CMS垃圾收集器,如果在JDK14中使用 -XX:+UseConcMarkSweepGC的话 JVM 不会报错,只是给出一个 warning信息,但是不会exit。JVM 会自动回退以默认GC方式启动JM OpenJDK 64-Bit Server VM warning: Ignoring option UseConcMarkSweepGC; support was removed in 14.0 and the VM will continue execution using the default collector ■ G1 回收器 ● -XX:+UseG1GC:手动指定使用 G1 收集器执行内存回收任务 ● -XX:G1HeapRegionSize:设置每个 Region 的大小。值是 2 的幂,范围是 1MB 到 32MB之间,目标是根据最小的 Java 堆大小划分出约 2048 个区域。默认是堆内存的 1/2000 ● -XX:MaxGCPauseMillis:设置期望达到的最大 GC 停顿指标(JVM 会尽力实现,但不保证达到)。默认值是 200ms ● -XX:ParallelGCThread:设置 STW 时 GC 线程数的值。最多设置为 8 ● -XX:ConcGCThreads:设置并发标记的线程数。将 n 设置为并行垃圾回收线程数(ParallelGCThreads) 的 1/4 左右 ● -XX:InitialtingHeapOccupancyPercent:设置触发并发 GC 周期的 Java 堆占用率阈值。超过此值,就触发 GC。默认值是 45 ● -XX:G1NewSizePercent、-XX:G1MaxNewSizePercent:新生代占用整个堆内存的最小百分比(默认5%)、最大百分比(默认60%) ● -XX:G1ReservePercent=10:保留内存区域,防止 to space(Survivor中的to区)溢出 ● Mixed GC 调优参数 注意:G1 收集器主要涉及到 Mixed GC,Mixed GC 会回收 young 区和部分 old 区 G1 关于 Mixed GC 调优常用参数: ○ -XX:InitiatingHeapOccupancyPercent:设置堆占用率的百分比(0到100)达到这个数值的时候触发 global concurrent marking(全局并发标记),默认为 45%。值为0表示间断进行全部并发标记 ○ -X:G1MixedGCLiveThresholdPercent:设置old区的 region 被回收时候的对象占比,默认占用率为85%。只有Old区的 region中存活的对象占用达到了这个百分比,才会在 Mixed GC中被回收 ○ -XX:G1HeapwastePercent:在global concurrent marking(全局并发标记)结束之后,可以知道所有的区有多少空间要被回收,在每次 young GC之后和再次发生 Mixed GC之前,会检查垃圾占比是否达到此参数,只有达到了,下次才会发生Mixed GC ○ -XX:G1MixedGCCountTarget:一次 global concurrent marking(全局并发标记)之后,最多执行 Mixed GC 的次数,默认是8 ○ -XX:G1OldCSetRegionThresholdPercent:设置 Mixed GC收集周期中要收集的 Old region数的上限。默认值是 Java堆的10% ■ 怎么选择垃圾回收器 ● 优先调整堆的大小让 JVM 自适应完成 ● 如果内存小于 100MB,使用串行收集器 ● 如果是单核、单机程序,并且没有停顿时间的要求,串行收集器 ● 如果是多 CPU、需要高吞吐量、允许停顿时间超过 1 秒,选择并行或者 JVM 自己选择 ● 如果是多 CPU、追求低停顿时间,需快速响应(比如延迟不能超过1秒,如互联网应用),使用并发收集器。官方推荐 G1,性能高。现在互联网的项目,基本都是使用 G1 特别说明: 1、没有最好的收集器,更没有万能的收集器 2、调优永远是针对特定场景、特定需求,不存在一劳永逸的收集器 ■ 常用参数 -verbose:gc:输出gc日志信息,默认输出到标准输出 -XX:+PrintGC:等同于 -verbose:gc,表示打开简化的 GC 日志 -XX:+PrintGCDetails:在发生垃圾回收时打印内存回收详细的日志,并在进程退出时输出当前内存各区域分配情况 -XX:+PrintGCTimeStamps:输出 GC 发生时的时间戳;不能独立使用,需配合其他的一起使用,比如上面的三个 -XX:+PrintGCDateStamps:输出 GC 发生时的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800);不能独立使用,需配合其他的一起使用,比如上面的三个 -XX:+PrintHeapATGC:每一次 GC 前和 GC 后,都打印堆信息 -Xloggc::把 GC 日志写入到一个文件中去,而不是打印到标准输出中 ■ 其他参数 -XX:+TraceClassLoading:监控类的加载 -XX:+PrintGCApplicationStoppedTime:打印 GC 时线程的停顿时间 -XX:+PrintGCApplicationConcurrentTime:垃圾收集之前打印出引用未中断的执行时间 -XX:+PrintReferenceGC:记录回收了多少种不同引用类型的引用 -XX:+PrintTenuringDistribution:让 JVM 在每次 MinorGC后打印出当前使用的 Survivor 中对象的年龄分布 -XX:+UseGCLogFileRotaion:启用 GC 日志文件的自动转储 -XX:NumberOfGClogFiles=1:GC 日志文件的循环次数 -XX:GCLogFileSize=1M:控制 GC 日志文件的大小 -XX:+DisableExplicitGC:禁止 hotspot 执行 System.gc(),默认禁用 -XX:ReservedCodeCacheSize= [g|m|k]、-XX:InitialCodeCacheSize=[g|m|k]:指定代码缓存的大小 -XX:+UseCodeCacheFlushing:使用该参数让 jvm 放弃一些被编译的代码,避免代码缓存被占满时 JVM 切换到 interpreted-only 的情况 -XX:+DoEscapeAnalysis:开启逃逸分析 -XX:+UseBiasedLocking:开启偏向锁 -XX:+UseLargePages:开启使用大页面 -XX:+UseTLAB:使用 TLAB,默认打开 -XX:+PrintTLAB:打印 TLAB 的使用情况 -XX:TLABSize:设置 TLAB 大小 Java提供了java.ang. management包用于监视和管理Java虚拟机和]ava运行时中的其他组件,它允许本地和远程监控和管理运行的Java虚拟机。其中 ManagementFactory这个类还是挺常用的。另外还有 Runtime类也可以获取一些内存、CPU核数等相关的数据 通过这些 api 可以监控我们的应用服务器的堆内存使用情况,设置一些阈值进行报警等处理 -verbose:gc:输出gc日志信息,默认输出到标准输出 -XX:+PrintGC:等同于 -verbose:gc,表示打开简化的 GC 日志 -XX:+PrintGCDetails:在发生垃圾回收时打印内存回收详细的日志,并在进程退出时输出当前内存各区域分配情况 -XX:+PrintGCTimeStamps:输出 GC 发生时的时间戳;不能独立使用,需配合其他的一起使用,比如上面的三个 -XX:+PrintGCDateStamps:输出 GC 发生时的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800);不能独立使用,需配合其他的一起使用,比如上面的三个 -XX:+PrintHeapATGC:每一次 GC 前和 GC 后,都打印堆信息 -Xloggc::把 GC 日志写入到一个文件中去,而不是打印到标准输出中 对 HotSpot VM的实现,它里面的GC按照回收区域又分为两大种类型:一种是部分收集Partial GC),一种是整堆收集(Full GC) ■ 部分收集:不是完整收集整个Java堆的垃圾收集。其中又分为: ● 新生代收集(Minor GC/ Young GC):只是新生代(Eden\S0,S1)的垃圾收集 ● 老年代收集(Major GC/Old GC):只是老年代的垃圾收集 ○ 目前,只有 CMS GC会有单独收集老年代的行为 ○ 注意,很多时候 Major GC会和Full GC混淆使用,需要具体分辨是老年代回收还是整堆回收 ● 混合收集( Mixed GC):收集整个新生代以及部分老年代的垃圾收集 ○ 目前,只有G1 GC会有这种行为 ■ 整堆收集(Full GC):收集整个java堆和方法区的垃圾收集。 ■ 哪些情况会触发 Full GC? 老年代空间不足; 方法区空间不足; 显示调用 System.gc(); Minor GC 进入老年代的数据的平均大小大于老年代的可用内存; 大对象直接进入老年代,而老年代的可用空间不足; ■ Minor GC Minor GC(或 young GC 或 YGC) 日志: ■ Full GC Full GC 日志介绍: ■ 垃圾收集器 ● 使用 Serial 收集器在新生代的名字是 Default New Generation,因此显示的是"[ DefNew" ● 使用 ParDew收集器在新生代的名字会变成"[ ParDew",意思是"Parallel New Generation" ● 使用Parallel Scavenge收集器在新生代的名字是"[ PSYoungGen",这里的JDK1.7使用的就是 PSYoungGen ● 使用Parallel Old Generation收集器在老年代的名字是"[ParOldGen" ● 使用G1收集器的话,会显示为"garbage-first heap Allocation Failure:表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了 ■ GC前后情况 通过图示,我们可以发现GC日志格式的规律一般都是:GC前内存占用一>GC后内存占用(该区域内存总大小) [ PSYoungGen:5986K->696K(8704K)]5986K->704K(9216K) 中括号内:GC回收前年轻代堆大小,回收后大小,(年轻代堆总大小) 括号外:GC回收前年轻代和老年代大小,回收后大小,(年轻代和老年代总大小) ■ GC时间 GC 日志中有三个时间:user,sys和real ● user – 进程执行用户态代码(核心之外)所使用的时间。这是执行此进程所使用的实际 CPU时间,其他进程和此进程阻塞的时间并不包括在内。在垃圾收集的情况下,表示GC线程执行所使用的CPU总时间 ● sys – 进程在内核态消耗的 CPU时间,即在内核执行系统调用或等待系统事件所使用的CPU时间 ● real – -程序从开始到结束所用的时钟时间。这个时间包括其他进程使用的时间片和进程阻塞的时间(比如等待I/0完成)。对于并行gc,这个数字应该接近(用户时间+系统时间)除以垃圾收集器使用的线程数 由于多核的原因,一般的GC事件中, real time是小于sys + user time的,因为一般是多个线程并发的去做GC,所以real time是要小于sys + user time的。如果real>sys+user的话,则你的应用可能存在下列问题:IO 负载非常重或者是CPU不够用 > 2021-11-20T17:19:43.265-0800:日志打印时间 > 0.822:gc发生时,Java 虚拟机启动以来经过的秒数 > [GC (ALLOCATION FAILURE):发生了一次垃圾回收,这是一次 Minor GC。它不区分新生代 GC 还是老年代 GC,括号里的内容是 gc 发生的原因,这里的 Allocation Failure 的原因是新生代中没有足够区域能够存放需要分配的数据而失败 > [PSYOUNGGEN:76800K->8433K(89600K)]: ● PSYoungGen:表示 GC 发生的区域,区域名称与使用的 GC 收集器时密切相关的 ○ Serial 收集器:Default New Generation 显示 DefNew ○ ParNew 收集器:ParNew ○ Parallel Scanvenge 收集器:PSYoung ○ 老年代和新生代同理,也是和收集器名称相关 ● 76800K->8433K(89600K):GC前该内存区域已使用容量->GC后该区域容量(该区域总容量) ○ 如果是新生代,总容量则会显示整个新生代内存的 9/10,即 eden+from/to 区 ○ 如果是老年代,总容量则是全部内存大小,无变化 > 76800K->8449K(294400K):在显示完区域容量 GC 的情况之后,会接着显示整个堆内存区域的 GC 情况:GC 前堆内存已使用容量 -> GC 堆内存容量(堆内存总容量),堆内存总容量 = 9/10 新生代 + 老年代<初始化的内存大小 > 0.0088371 SECS]:整个 GC 所花费的时间,单位是秒 > [TIMES:USER=0.02 SYS=0.01, REAL=0.01 SECS]: ● user:指的是 CPU 工作在用户态所花费的时间 ● sys:指的是 CPU 工作在内核态所花费的时间 ● real:指的是在此次 GC 事件所花费的总时间 ● 2020-11-20T17:19:43.794-0800:日志打印时间 ● 1.351:gc 发生时,Java 虚拟机启动以来经过的秒数 ● Full GC(Metadata GC Threshold): ○ 发生了一次垃圾回收,这是一次 Full GC。它不区分新生代GC还是老年代GC ○ 括号里的内容是 gc 发生的原因,这里的 Metadata GC Threshold 的原因是 Metaspace 区不够用了 Full GC(Ergonomics):JVM自适应调整导致的 GC; Full GC(System):调用了 System.gc() 方法; ● [PSYOUNGGEN: 10082K->0K(89600K)] 1、PSYoungGen:表示 GC 发生的区域,区域名称与使用的 GC 收集器时密切相关的 ○ Serial 收集器:Default New Generation 显示 DefNew ○ ParNew 收集器:ParNew ○ Parallel Scanvenge 收集器:PSYoung ○ 老年代和新生代同理,也是和收集器名称相关 2、10082K->0K(89600K):GC前该内存区域已使用容量->GC后该区域容量(该区域总容量) ○ 如果是新生代,总容量则会显示整个新生代内存的 9/10,即 eden+from/to 区 ○ 如果是老年代,总容量则是全部内存大小,无变化 ● [PAROLDGEN: 32K->9638K(204800K)]:老年代区域没有发生 GC,因为本次 GC 是 metaspace 引起的 ● 10114K->9638K(29440K):在显示完区域容量 GC 的情况之后,会接着显示整个堆内存区域的 GC 情况:GC 前堆内存已使用容量 -> GC 堆内存容量(堆内存总容量),堆内存总容量 = 9/10 新生代 + 老年代<初始化的内存大小 ● [METASPACE: 20158K->20156K(1067008K)]:metaspace GC 回收 2K 空间 ● 0.0285388 SECS:整个 GC 所花费的时间,单位是秒 ● TIMES: USER=0.11,SYS=0.00, REAL=0.03 SEC] ○ user:指的是 CPU 工作在用户态所花费的时间 ○ sys:指的是 CPU 工作在内核态所花费的时间 ○ real:指的是在此次 GC 事件所花费的总时间 上节介绍了GC日志的打印及含义,但是GC日志看起来比较麻烦,本节将会介绍一下GC日志可视化分析工具 GReasy和 GCviewer等。通过GC日志可视化分析工具,我们可以很方便的看到WM各个分代的内存使用情况、垃圾回收次数、垃圾回收的原因、垃圾回收占用的时间、吞吐量等,这些指标在我们进行JWM调优的时候是很有用的 如果想把Gc日志存到文件的话,是下面这个参数 -Xloggc: /path/to/gc. log 然后就可以用一些工具去分析这些gc日志 ■ 基本概述 GCeasy-----一款超好用的在线分析GC日志的网站 官网地址:https://gceasy.io/,GCeasy 是一款在线的GC日志分析器,可以通过GC日志分析进行内存泄漏检测、GC暂停原因分析、JVM配置建议优化等功能,而且是可以免费使用的(有一些服务是收费的) ■ 基本概述 ● 上面介绍了一款在线的GC日志分析器,下面介绍一个离线版的 GCViewer ● GCVIewer是一个免费的、开源的分析小工具,用于可视化查看由SUN/Oracle,IBM,HP和BEA Java虚拟机产生的垃圾收集器的日志 ● GCViewer用于可视化 Java VM选项 -verbose:gc和 .NET生成的数据 -Xloggc:。它还计算与垃圾回收相关的性能指标(吞吐量,累积的暂停,最长的暂停等)。当通过更改世代大小或设置初始堆大小来调整特定应用程序的垃圾回收时,此功能非常有用 ■ 安装 1、下载 GCViewer 工具 源码下载:https://github.com/chewiebug/GCViewer 运行版本下载:https://github.com/chewiebug/GCViewer/wiki/Changelog 2、只需双击 gcviewer-1.3x.jar或运行 java -jar gcviewer-1.3x.jar(它需要运行 java 1.8 vm),即可启动 GCViewer(gui) ■ GChisto GChisto是一款专业分析gc日志的工具,可以通过gc日志来分析: Minorgc、Full GC的次数、频率、持续时间等,通过列表、报表、图表等不同形式来反应gc的情况 虽然界面略显粗糙,但是功能还是不错的。 官网上没有下载的地方,需要自己从 SVN 上拉下来编译,不过这个工具似乎没怎么维护了,存在不少 bug ■ HPjmeter 工具很强大,但只能打开由以下参数生成的 GC log,-verbose:gc -Xloggc:gc.log。添加其他参数生成的 gc.log 无法打开; HPjmeter 集成了以前的 HPjtune 功能,可以分析在 HP 机器上产生的垃圾回收日志文件2.4、类型转换指令
2.4.1、宽化类型指令
2.4.2、窄话类型指令
2.5、对象的创建与访问指令
2.5.1、创建指令
2.5.2、字段访问指令
public void sayHello() {
System.out.println("hello")
}
0 getstatic #82.5.3、数组操作指令
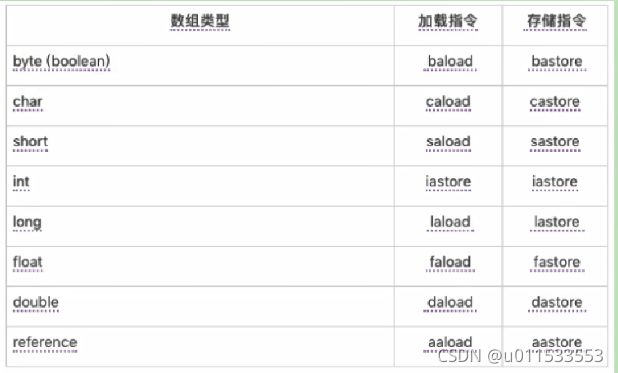
2.5.4、类型检查指令
2.6、方法调用与返回指令
2.6.1、方法调用指令
package com.pengtxyl.two.chapter02;
import java.util.Date;
public class MethodInvokeReturnTest {
//方法调用指令 invokespecial
public void invoke1() {
//情况1:类实例构造器方法:package com.pengtxyl.two.chapter02;
public class InterfaceMethodTest {
public static void main(String[] args) {
AA aa = new BB();
aa.method2(); //invokeinterface
AA.method1(); //invokestatic
}
}
interface AA {
public static void method1() {
}
public default void method2() {
}
}
class BB implements AA {
}
2.6.2、方法返回指令
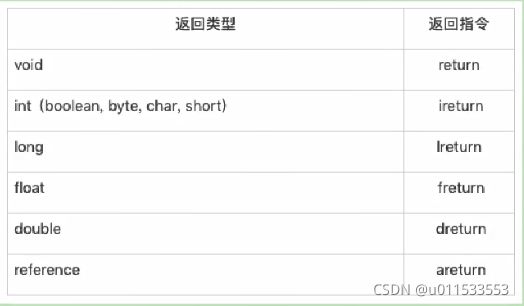
2.7、操作数栈管理指令
2.8、控制转移指令
2.8.1、比较指令
2.8.2、条件跳转指令

2.8.3、比较条件跳转指令

2.8.4、多条件分支跳转

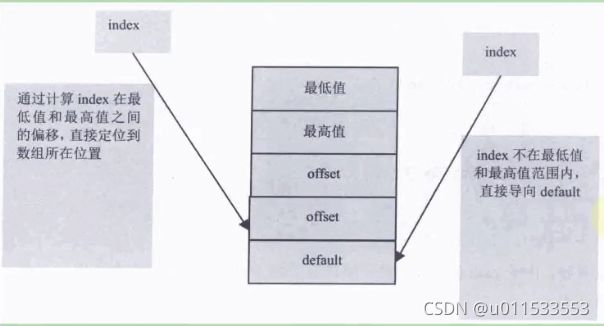

2.8.5、无条件跳转

2.9、异常处理指令
2.9.1、抛出异常指令
2.9.2、异常处理与异常表
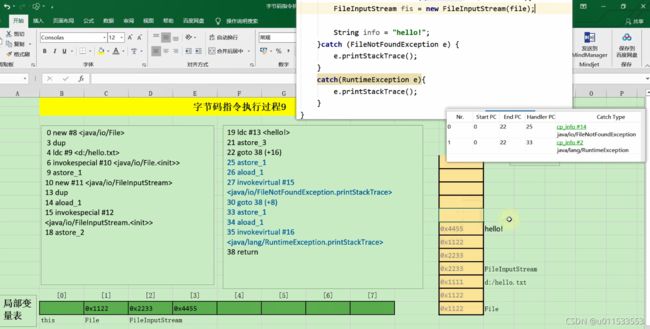
2.10、同步控制指令
2.10.1、方法级的同步
private int i = 0;
public synchronized void add() {
i++;
}
对应的字节码:
0 aload_0
1 dup
2 getfield #2 <com/atguigu/java1/SynchronizedTest.i>
5 iconst_1
6 iadd
7 putfield #2 <com/atguigu/java1/SynchronizedTest.i>
10 return
2.10.2、方法内指定指令序列的同步

private int i = 0;
public void subtract() {
synchronized(this) {
i--;
}
}
对应的字节码:
0 aload_0
1 dup
2 astore_1
3 monitorenter
4 aload_0
5 dup
6 getfield #2 // Field i:I
9 iconst_1
10 isub
11 putfield #2 // Field i:I
14 aload_1
15 monitorexit
16 goto 24
19 astore_2
20 aload_1
21 monitorexit
22 aload_2
23 athrow
24 return
Exception table
from to target type
4 16 19 any
19 22 19 any
3、类的加载过程(类的生命周期)详解
3.1、概述

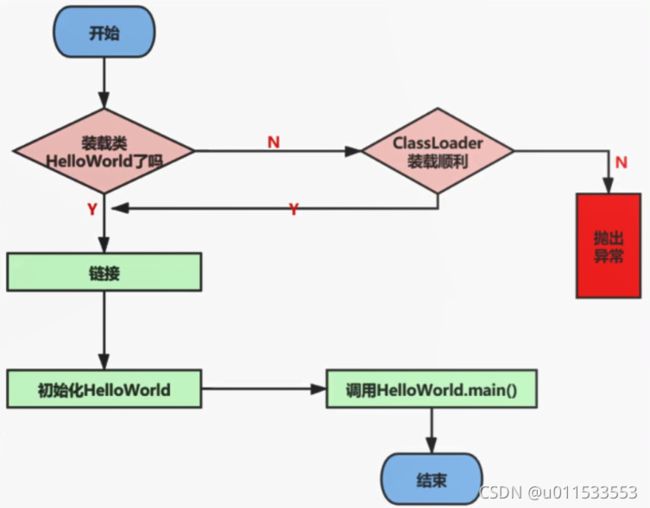
3.1.1、大厂面试题

3.2、过程一:Loading(加载)阶段
3.2.1、加载完成的操作
3.2.2、二进制流的获取方式
3.2.3、类模型与Class实例的位置
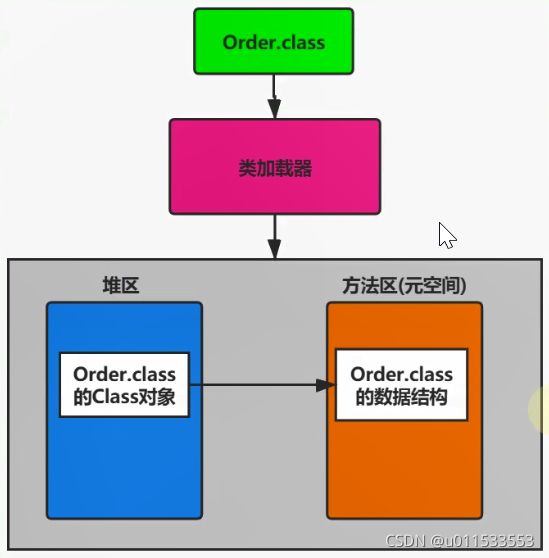
3.2.4、数组类的加载
3.3、过程二:Linking(链接)阶段
3.3.1、环节1:链接阶段之Verification(验证)

3.3.2、环节2:链接阶段之Preparation(准备)
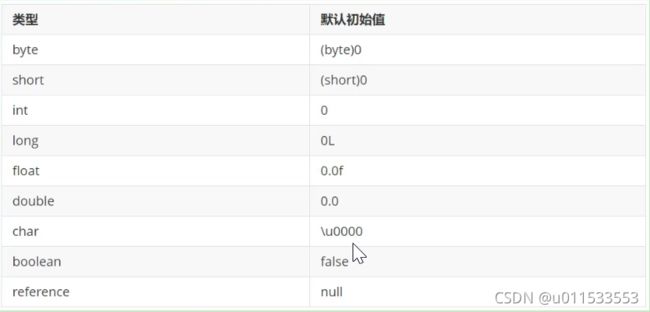
/*
对于基本数据类型:
非 final 修饰的变量,在准备环节进行默认初始化赋值;final修饰以后,在准备环节直接进行显式赋值
拓展:如果使用字面量的方式定义一个字符串的常量的话,也是在准备环节直接进行显式赋值
*/
public class LinkingTest{
private static long id;
private static final int num = 1;
public static final String constStr = "CONST";
}
3.3.3、环节3:链接阶段之Resolution(解析)
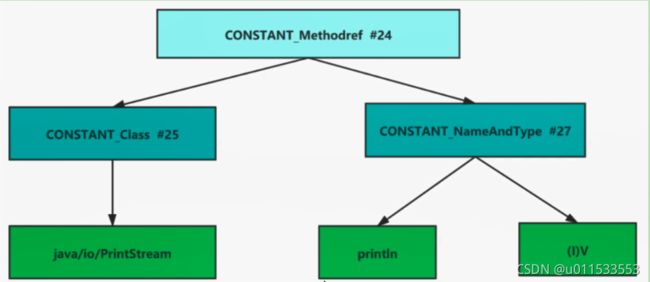
3.4、过程三:Initialization(初始化)阶段
3.4.1、static与final的搭配问题
package com.pengtxyl.two.chapter03;
import java.util.Random;
/*
* 说明:使用 static final 修饰的字段的显式赋值的操作,到底是在哪个阶段进行的赋值?
* 情况1:在链接阶段的准备环节赋值
* 情况2:在初始化阶段3.4.2、()的线程安全性
3.4.3、类的初始化情况:主动使用vs被动使用
3.5、过程四:类的Using(使用)
3.6、过程五:类的Unloading(卸载)
4、再谈类的加载器
4.1、概述
4.1.1、大厂面试题
4.1.2、类加载的分类
4.1.3、类加载的必要性
4.1.4、命名空间
4.1.5、类加载机制的基本特征
4.2、复习:类的加载器分类
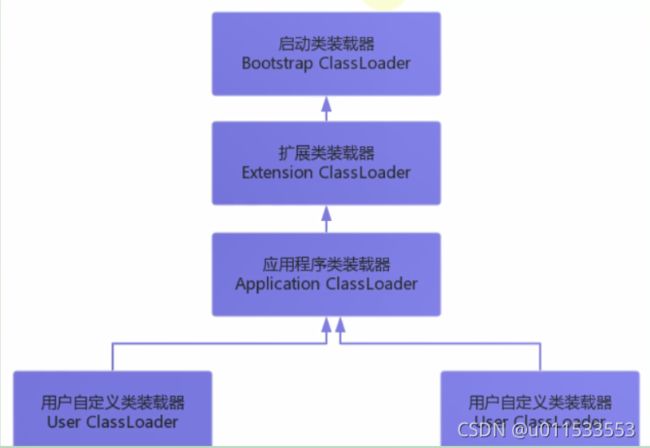
public ParentClassLoader {}
public ChildClassLoader {
ParentClassLoader parent; //父类加载器
public ChildClassLoader(ClassLoader parent) { //parent = new ParentClassLoader();
this.parent = parent;
}
}
4.2.1、引导类加载器

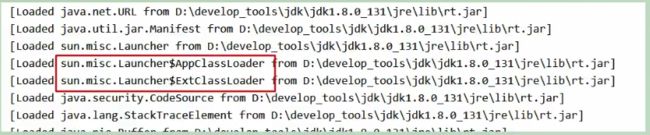
4.2.2、扩展类加载器

4.2.3、系统类加载器
4.2.4、用户自定义类加载器
4.3、测试不同的类加载器
获取ClassLoader的途径
获得当前类的 Classloader:clazz. getClassLoader()
获得当前线程上下文的Classloade:Thread. currentThread. getContextClassLoader(),上下文的 ClassLoader 就是系统类加载器
获得系统的Classloader:ClassLoader. getSystemClassLoader()
4.4、ClassLoader源码解析
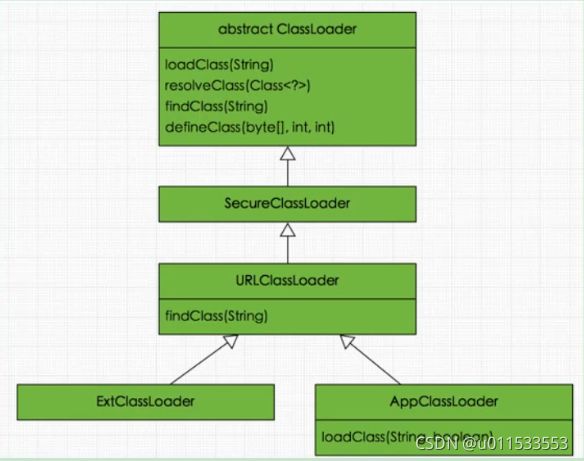
4.4.1、ClassLoader的主要方法
//测试代码:
ClassLoader.getSystemClassLoader().loadClass("com.atguigu.java.User");
//涉及到对如下方法的调用
protected Class<?> loadClass(String name, boolean resolve) //resolve: true表示加载class的同时进行解析操作
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) { //同步操作,保证只能加载一次
// 首先,在缓存中判断是否已经加载同名的类
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) { //获取当前类加载器的父类加载器
//如果存在父类加载器,则调用父类加载器进行类的加载
c = parent.loadClass(name, false);
} else { //parent为null:父类加载器是引导类加载器
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) { //当前类加载器的父类加载器未加载此类或者当前类加载器未加载此类
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
//调用当前ClassLoader的findClass方法
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
在JDK1.2之前,在自定义类加载时,总会去继承Classloader类并重写loadClass方法,从而实现自定义的类加载类。但是在JDK1.2之后已不再建议用户去覆盖loadClass()方法,而是建议把自定义的类加载逻辑写在findClass()方法中,从前面的分析可知, findClass()方法是在loadClass()方法中被调用的,loadclass()方法中父加载器加载失败后,则会调用自己的 findClass()方法来完成类加载,这样就可以保证自定义的类加载器也符合双亲委托模式
需要注意的是 Classloader类中并没有实现 findClass()方法的具体代码逻辑,取而代之的是抛出ClassNotFoundException异常,同时应该知道的是 findClass方法通常是和 defineClass方法起使用的。一般情况下,在自定义类加载器时,会直接覆盖 Classloader的 findClass()方法并编写加载规则,取得要加载类的字节码后转换成流,然后调用 defineClass()方法生成类的Class对象
defineclass()方法是用来将byte字节流解析成JVM能够识别的Class对象( Classloader中已实现该方法逻辑),通过这个方法不仅能够通过class文件实例化class对象,也可以通过其他方式实例化class对象,如通过网络接收类的字节码,然后转换为byte字节流创建对应的class对象
defineClass()方法通常与 findClass()方法一起使用,一般情况下,在自定义类加载器时,会直接覆盖Classloader的 findClass()方法并编写加载规则,取得要加载类的字节码后转换成流,然后调用 defineClass()方去生成类的class对象
protected Class<?> findClass(String name) throws ClassNotFoundException {
//获取类的字节数组
byte[] classData = getClassData(name);
if(classData == null) {
throw new ClassNotFoundException();
} else {
//使用defineClass生成class对象
return defineClass(name, classData, 0, classData.length);
}
}
4.4.2、SecureClassLoader与URLClassLoader
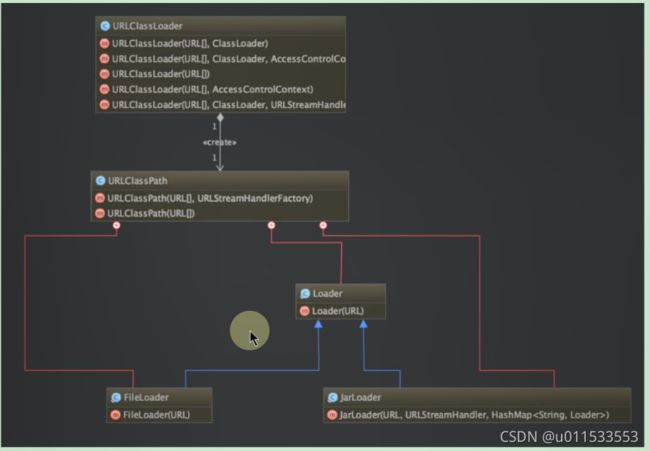
4.4.3、ExtClassLoader与AppClassLoader

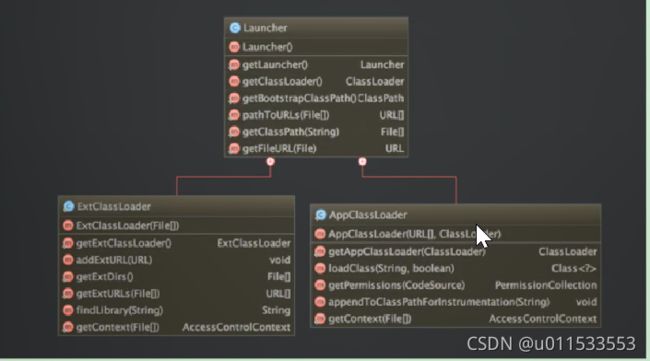
4.4.4、Class.forName()与ClassLoader.loadClass()
4.5、双亲委派模型
4.5.1、定义与本质
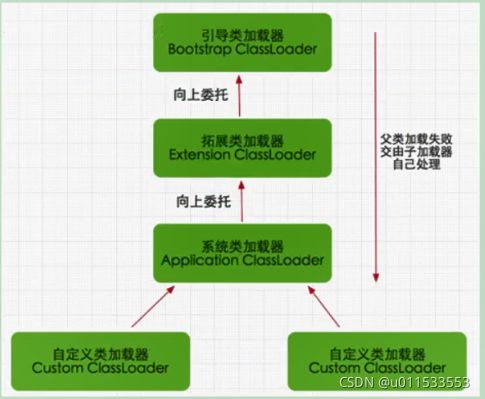
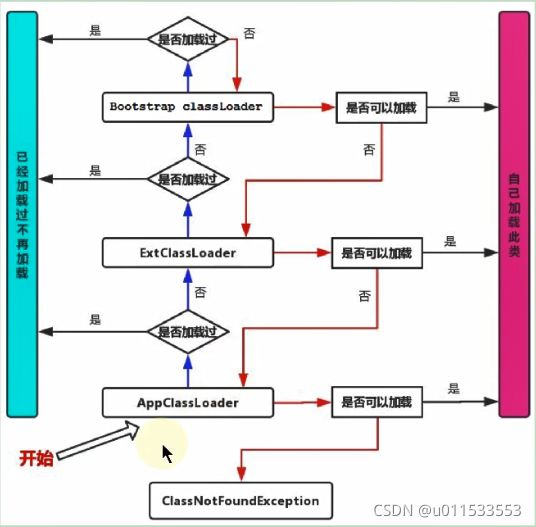
4.5.2、优势与劣势
4.5.3、破坏双亲委派机制
①、破坏双亲委派机制1
②、破坏双亲委派机制2

③、破坏双亲委派机制3
4.5.4、热替换的实现

4.6、沙箱安全机制
4.6.1、JDK1.0时期
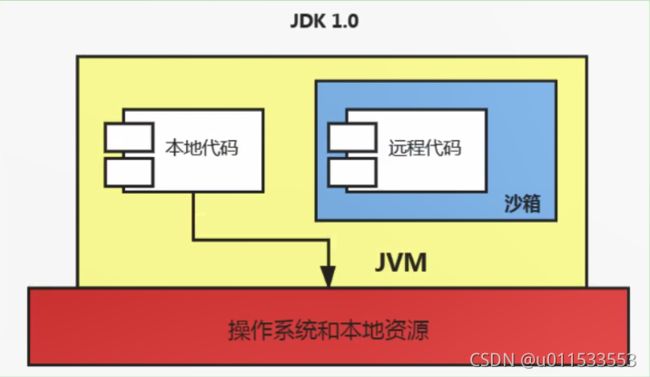
4.6.2、JDK1.1时期
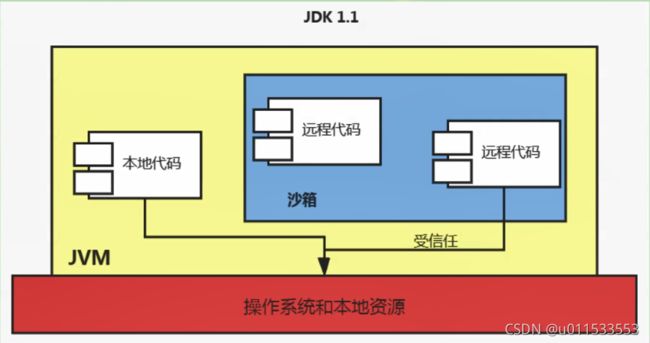
4.6.3、JDK1.2时期

4.6.4、JDK1.6时期
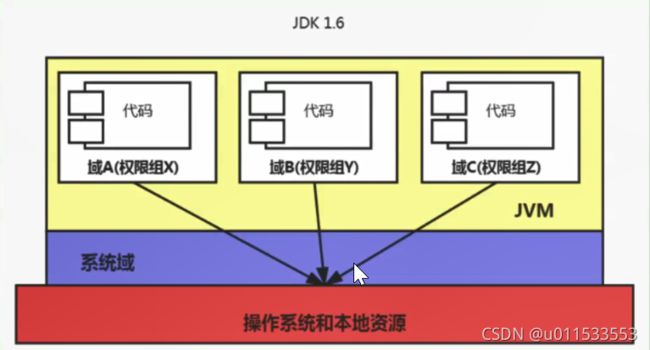
4.7、自定义类的加载器
4.7.1、实现方式
package com.pengtxyl.two.chapter04;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.IOException;
public class MyClassLoader extends ClassLoader {
private String byteCodePath;
public MyClassLoader(String byteCodePath) {
this.byteCodePath = byteCodePath;
}
public MyClassLoader(ClassLoader parent, String byteCodePath) {
super(parent);
this.byteCodePath = byteCodePath;
}
@Override
protected Class<?> findClass(String className) throws ClassNotFoundException {
BufferedInputStream bis = null;
ByteArrayOutputStream baos = null;
try {
String fileName = byteCodePath + className + ".class";
bis = new BufferedInputStream(new FileInputStream(fileName));
baos = new ByteArrayOutputStream();
int len;
byte[] data = new byte[1024];
while ((len = bis.read(data)) != -1) {
baos.write(data, 0, len);
}
byte[] byteCodes = baos.toByteArray();
Class clazz = defineClass(null, byteCodes, 0, byteCodes.length);
return clazz;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(baos != null) {
baos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if(bis != null) {
bis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
package com.pengtxyl.two.chapter04;
public class MyClassLoaderTest {
public static void main(String[] args) {
MyClassLoader loader = new MyClassLoader("d:/");
try {
Class clazz = loader.loadClass("User");
System.out.println("加载此类的类的加载器为: " + clazz.getClassLoader().getClass().getName());
System.out.println("加载当前User类的类的加载器的父类加载器为: " + clazz.getClassLoader().getParent().getClass().getName());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
三、性能监控与调优篇
1、概述篇
1.1、大厂面试题

1.2、背景说明
1.2.1、生产环境中的问题
1.2.2、为什么要调优
1.2.3、不同阶段的考虑
1.3、调优概述
1.3.1、监控的依据
1.3.2、调优的大方向
1.4、性能优化的步骤
1.4.1、(发现问题):性能监控
1.4.2、(排查问题):性能分析
1.4.3、(解决问题):性能调优
1.5、性能评价/测试指标
1.5.1、停顿时间(或响应时间)
1.5.2、吐吞量
1.5.3、并发数
1.5.4、内存占用
1.5.5、相互间的关系
2、JVM监控及诊断工具-命令行篇
2.1、概述
2.2、jps:查看正在运行的Java进程
2.2.1、基本情况
2.2.2、测试
2.2.3、基本语法
2.3、jstat:查看JVM统计信息
2.3.1、基本情况
2.3.2、基本语法
jstat -<option> [-t] [-h<lines>] <vmid> [<interval>] [<count>]

新生代相关:
S0C是第一个幸存者区的大小(字节)
S1C是第二个幸存者区的大小(字节)
S0U是第一个幸存者区已使用的大小(字节)
S1U是第二个幸存者区已使用的大小(字节)
EC是Eden空间的大小(字节)
EU是Eden已使用的大小(字节)
老年代相关:
OC是老年代的大小(字节)
OU是老年代已使用的大小(字节)
方法区(元空间)相关:
MC是方法区的大小
MU是方法区已使用的大小
CCSC是压缩类空间的大小
CCSU是压缩类空间已使用的大小
其他:
YGC是指从应用程序启动到采样时young gc次数
YGCT是指从应用程序启动到采样时young gc消耗的时间(秒)
FGC是指从应用程序启动到采样时full gc次数
FGCT是指从应用程序启动到采样时full gc消耗的时间(秒)
GCT是指从应用程序启动到采样时gc的总时间






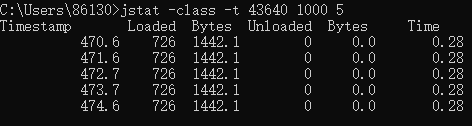
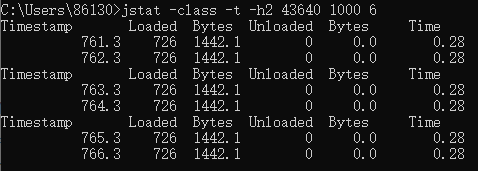
2.3.3、补充
2.4、jinfo:实时查看和修改JVM配置参数
2.4.1、基本情况
2.4.2、基本语法
选项
选项说明
no option
输出全部的参数和系统属性
-flag name
输出对应名称的参数
-flag [±]name
开启或者关闭对应名称的参数,只有被标记为 manageable 参数才可以被动态修改
-flag name=value
设定对应名称的参数
-flags
输出全部的参数
-sysprops
输出系统属性





2.4.3、拓展


2.5、jmap:导出内存映像文件&内存使用情况
2.5.1、基本情况
2.5.2、基本语法
选项
作用
-dump
生成 dump 文件
-finalizerinfo
以 ClassLoader 为统计口径输出永久代的内存状态信息
-heap
输出整个堆空间的详细信息,包括 GC 的使用、堆配置信息,以及内存的使用信息等
-histo
输出堆空间中对象的统计信息,包括类、实例数量和合计容量
-permstat
以 ClassLoader 为统计口径输出永久代的内存状态信息
-F
当虚拟机进程对 -dump 选项没有任何响应时,强制执行生成 dump 文件
2.5.3、使用1:导出内存映像文件
①、手动的方式

②、自动的方式
2.5.4、使用2:显示堆内存相关信息
①、jmap -heap pid

②、-jmap -histo pid

2.5.5、使用3:其他作用
①、jmap -permstat pid
②、jmap -finalizerinfo
2.5.6、小结
2.6、jhat:JDK自带堆分析工具
2.6.1、基本情况
2.6.2、基本语法
2.7、jstack:打印JVM中线程快照
2.7.1、基本情况
2.7.1、基本语法

2.8、jcmd:多功能命令行
2.8.1、基本情况
2.8.2、基本语法


2.9、jstatd:远程主机信息收集

3、JVM监控及诊断工具-GUI篇
3.1、工具概述
3.2、jConsole
3.2.1、基本概述
3.2.2、启动
3.2.3、三种连接方式
3.3、Visual VM
3.3.1、基本概述
3.3.2、插件的安装
3.3.3、连接方式
3.3.4、主要功能
3.4、eclipse MAT
3.4.1、基本概述
3.4.2、获取堆dump文件
3.4.3、分析堆dump文件


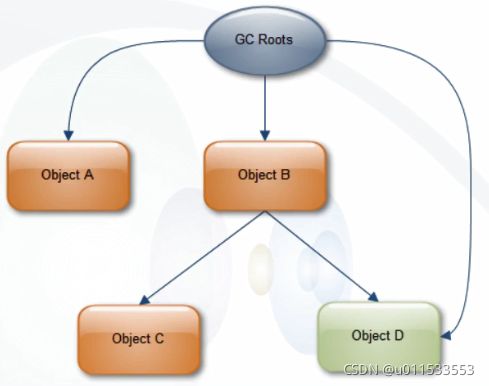
package com.pengtxyl.three.chapter03.mat;
import java.util.ArrayList;
import java.util.List;
/**
* 有一个学生浏览网页的记录程序,它将记录每个学生访问过的网站地址
* 它由三个部分组成:Student、WebPage和StudentTrance 三个类
*
* -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=d:\student.hprof
*/
public class StudentTrance {
static List<WebPage> webPages = new ArrayList<>();
public static void crteateWebPages() {
for (int i = 0; i < 100; i++) {
WebPage wp = new WebPage();
wp.setUrl("http://www." + Integer.toString(i) + ".com");
wp.setContent(Integer.toString(i));
webPages.add(wp);
}
}
public static void main(String[] args) {
crteateWebPages();
Student st3 = new Student(3, "Tom");
Student st5 = new Student(5, "Jerry");
Student st7 = new Student(7, "Lily");
for (int i = 0; i < webPages.size(); i++) {
if(i % st3.getId() == 0) {
st3.visit(webPages.get(i));
}
if(i % st5.getId() == 0) {
st5.visit(webPages.get(i));
}
if(i % st7.getId() == 0) {
st7.visit(webPages.get(i));
}
}
webPages.clear();
System.gc();
}
}
class Student {
private int id;
private String name;
private List<WebPage> history = new ArrayList<>();
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<WebPage> getHistory() {
return history;
}
public void setHistory(List<WebPage> history) {
this.history = history;
}
public void visit(WebPage wp) {
if(wp != null) {
history.add(wp);
}
}
}
class WebPage {
private String url;
private String content;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}




3.4.4、案例:Tomcat堆溢出分析


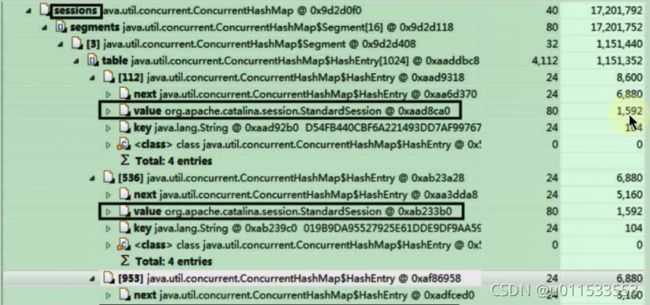
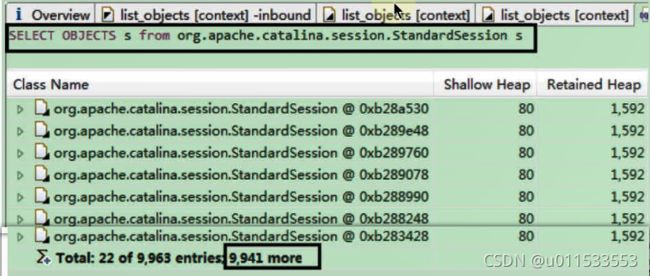
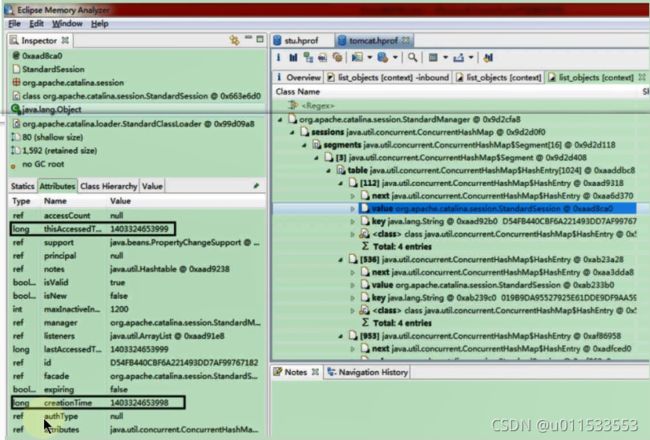

补充1:再谈内存泄漏
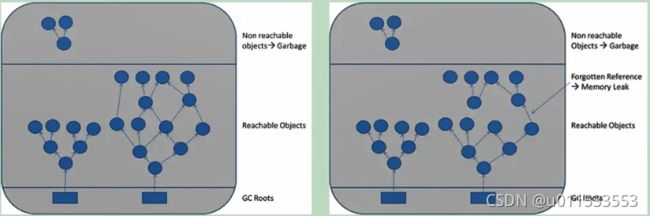
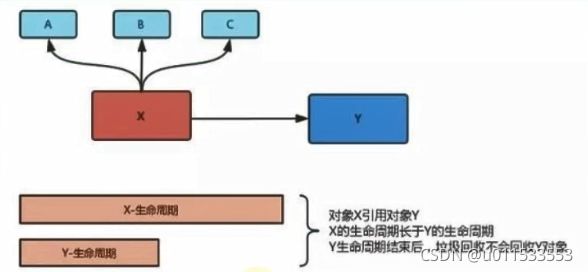
public class MemoryLeak {
static List list = new ArrayList();
public void oomTests() {
Object obj = new Object(); //局部变量
list.add(obj);
}
}
public static void main(String[] args) {
try {
Connection conn = null;
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("url", "", "");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("...");
} catch (Exception e) { //异常日志
} finally {
//1. 关闭结果集 Statement
//2. 关闭声明的对象 ResultSet
//3. 关闭连接 Connection
}
}
public class UsingRandom{
private String msg;
public void receiveMsg() {
readFromNet(); //从网络中接收数据保存到 msg 中
saveDB(); //把 msg 保存到数据库中
}
}
package com.pengtxyl.three.chapter03.memoryleak;
import java.util.HashSet;
import java.util.Objects;
public class ChangeHashCode1 {
public static void main(String[] args) {
HashSet<Point> hs = new HashSet<>();
Point cc = new Point();
cc.setX(10); //hashCode = 41
hs.add(cc);
cc.setX(20); //hashCode = 51,此行为导致了内存泄漏
System.out.println("hs.remove = " + hs.remove(cc)); //false
hs.add(cc);
System.out.println("hs.size = " + hs.size()); //2
}
}
class Point {
int x;
public int getX() {
return x;
}
public void setX() {
this.x = x;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null) return false;
if(getClass() != obj.getClass()) return false;
Point other = (Point) obj;
if (x != other.x) return false;
return true;
}
}
package com.pengtxyl.three.chapter03.memoryleak;
import java.util.HashSet;
import java.util.Objects;
public class ChangeHashCode {
public static void main(String[] args) {
HashSet set = new HashSet();
Person p1 = new Person(1001, "AA");
Person p2 = new Person(1002, "BB");
set.add(p1);
set.add(p2);
p1.name = "CC"; //导致了内存的泄漏
set.remove(p1); //删除失败
System.out.println(set);
// set.add(new Person(1001, "CC"));
// System.out.println(set);
// set.add(new Person(1001, "AA"));
// System.out.println(set);
}
}
class Person {
int id;
String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
if(id != person.id) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (name != null ? name.hashCode() : 0);
return result;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
package com.pengtxyl.three.chapter03.memoryleak;
import java.util.HashMap;
import java.util.Map;
import java.util.WeakHashMap;
import java.util.concurrent.TimeUnit;
public class MapTest {
static Map wMap = new WeakHashMap();
static Map map = new HashMap();
public static void main(String[] args) {
init();
testWeakHashMap();
testHashMap();
}
public static void init() {
String ref1 = new String("object1");
String ref2 = new String("object2");
String ref3 = new String("object3");
String ref4 = new String("object4");
wMap.put(ref1, "cacheObject1");
wMap.put(ref2, "cacheObject2");
map.put(ref3, "cacheObject3");
map.put(ref4, "cacheObject4");
System.out.println("String引用ref1, ref2, ref3, ref4消失");
}
public static void testWeakHashMap() {
System.out.println("WeakHashMap GC 之前");
for (Object o : wMap.entrySet()) {
System.out.println(o);
}
try {
System.gc();
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("WeakHashMap GC 之后");
for (Object o : wMap.entrySet()) {
System.out.println(o);
}
}
public static void testHashMap() {
System.out.println("HashMap GC 之前");
for (Object o : map.entrySet()) {
System.out.println(o);
}
try {
System.gc();
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("HashMap GC 之后");
for (Object o : map.entrySet()) {
System.out.println(o);
}
}
}
package com.pengtxyl.three.chapter03.memoryleak;
import java.util.Arrays;
import java.util.EmptyStackException;
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object e) { //入栈
ensureCapacity();
elements[size++] = e;
}
public Object pop() { //出栈
if (size == 0) {
throw new EmptyStackException();
}
return elements[--size];
}
/*public Object pop() {
if(size == 0) {
throw new EmptyStackException();
}
Object result = elements[--size];
elements[size] = null;
return result;
}*/
private void ensureCapacity() {
if (elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
}

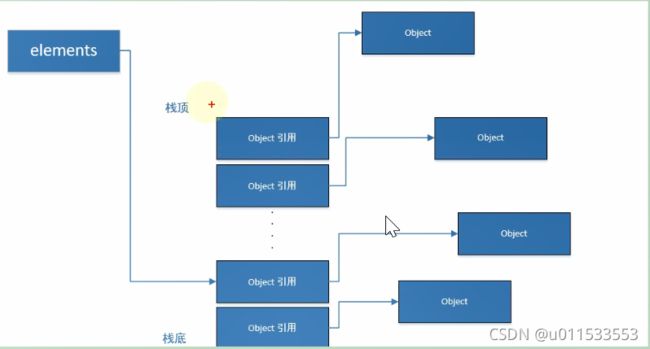
public Object pop() {
if(size == 0) {
throw new EmptyStackException();
}
Object result = elements[--size];
elements[size] = null;
return result;
}
package com.pengtxyl.three.chapter03.memoryleak;
public class TestActivity extends Activity {
private static final Object key = new Object();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new Thread() { //匿名线程
public void run() {
synchronized(key) {
try {
key.wait();
} catch (InterruptedException e) {
e.printStackTrance();
}
}
}
}.start();
}
}

补充2、支持使用OQL语言查询对象信息
SELECT * FROM "com\.atguigu\..*"
SELECT * FROM java.lang.String s WHERE toString(s) LIKE ".*java.*"
[ <alias>. ] <field> . <field> . <field>
3.5、JProfiler
3.5.1、基本概述

3.5.2、安装与配置
3.5.3、具体使用


3.5.4、案例分析
package com.pengtxyl.three.chapter03.jprofiler;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
public class JProfilerTest {
public static void main(String[] args) {
while(true) {
ArrayList list = new ArrayList();
for(int i = 0 ; i < 500 ; i++) {
Data data = new Data();
list.add(data);
}
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Data{
private int size = 10;
private byte[] buffer = new byte[1024 * 1024];
private String info = "hello,atguigu";
}
package com.pengtxyl.three.chapter03.jprofiler;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
public class MemoryLeak {
public static void main(String[] args) {
while(true) {
ArrayList beanList = new ArrayList();
for(int i = 0 ; i < 500 ; i++) {
Bean data = new Bean();
data.list.add(new byte[1024 * 10]);
beanList.add(data);
}
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Bean{
int size = 10;
String info = "hello,atguigu";
static ArrayList list = new ArrayList();
}
3.6、Arthas
3.6.1、基本概述
3.6.2、安装与使用
arthas-agent: 基于 JavaAgent 技术的代理
bin: 一些启动脚本
arthas-boot: Java 版本的一键安装启动脚本
arthas-client: telnet client 代码
arthas-common: 一些共用的工具类和枚举类
arthas-core: 核心库,各种 arthas 命令的交互和实现
arthas-demo: 实例代码
arthas-memorycompiler: 内存编译器代码,Fork from
https://github.com/skalogs/SkaETL/tree/master/compiler
arthas-packaging: maven打包相关的
arthas-site: arthas站点
arthas-spy: 编织到目标类中的各个切面
static: 静态资源
arthas-testcase: 测试
[4] : 21032 org.jetbrains.idea.maven.server.RemoteMavenServerjps -l 或者 ps -ef | grep java
3.6.3、相关诊断指令
help--查看命令帮助信息
cat--打印文件内容,和linux里的cat命令类似
echo--打印参数,和linux里的echo命令类似
grep-匹配查找,和linux里的grep命令类似
tee--复制标准输入到标准输出和指定的文件,和linux里的tee命令类似
pwd--返回当前的工作目录,和linux命令类似
cls--清空当前屏幕区域
session--查看当前会话的信息
reset--重置增强类,将被Arthas增强过的类全部还原,Arthas服务端关闭时会重置所有增强过的类
version--输出当前目标Java进程所加载的Arthas版本号
history--打印命令历史
quit--退出当前Arthas客户端,其他Arthas客户端不受影响
stop--关闭Arthas服务端,所有Arthas客户端全部退出
keymap--Arthas快捷键列表及自定义快捷键
dashboard--当前系统的实时数据面板
thread--查看当前JVM的线程堆栈信息
jvm--查看当前JVM的信息
sysprop--查看和修改JVM的系统属性
sysenv--查看JVM的环境变量
vmoption--查看和修改JVM里诊断相关的option
perfcounter--查看当前JVM的Perf Counter信息
logger--查看和修改logger
getstatic--查看类的静态属性
ognl--执行ognl表达式
mbean--查看Mbean的信息
heapdump--dump java heap,类似jmap命令的heap dump功能
sc--查看JVM已加载的类信息
sm--查看已加载类的方法信息
jad--反编译指定已加载类的源码
mc--内存编译器,内存编译 .java文件为 .class文件
retransform--加载外部的.class文件,retransform到JVM里
redefine--加载外部的.class文件,redefine到JVM里
dump--dump已加载类的bytecode到特定目录
classloader--查看classloader的继承树,urls,类加载信息,使用classloader去getResource
monitor--方法执行监控
watch--方法执行数据观测
trace--方法内部调用路径,并输出方法路径上的每个节点上耗时
stack--输出当前方法被调用的调用路径
tt--方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
使用 > 将结果重写到日志文件,使用&指令命令是后台运行, session断开不影响任务执行(生命周期默认为1天)
jobs: 列出所有job
kill: 强制终止任务
fg: 将暂停的任务拉到前台执行
bg: 将暂停的任务放到后台执行
grep: 搜索满足条件的结果
plaintext: 将命令的结果去除ANSI颜色
wc: 按行统计输出结果
options: 查看或设置 Arthas全局开关
rofile: 使用 async-profiler对应用采样,生成火焰图
3.7、Java Mission Control
3.7.1、历史
3.7.2、启动
3.7.3、概述
3.7.4、功能:实时监控 JVM 运行时的状态
3.7.5、Java Flight Recorder



3.8、其他工具
3.8.1、Flame Graphs(火焰图)

3.8.2、Tprofiler
3.8.3、Btrace
3.8.4、YourKit
3.8.5、JProbe
3.8.6、Spring Insight
4、JVM运行时参数
4.1、JVM参数选项类型
4.1.1、类型一:标准参数选项
4.1.2、类型二:-X参数选项
4.1.3、类型三:-XX参数选项
4.2、添加JVM参数选项
4.2.1、Eclipse
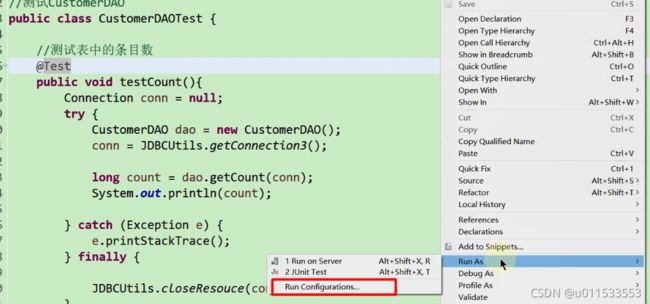
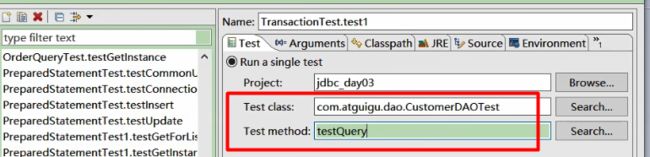

4.2.2、IDEA

4.2.3、运行 jar 包
java -Xms50m -Xmx50m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -jar demo.jar
4.2.4、通过 Tomcat 运行 war 包
4.2.5、程序运行过程中
4.3、常用的JVM参数选项
4.3.1、打印设置的 XX 选项及值
4.3.2、堆、栈、方法区等内存大小设置
4.3.3、OutofMemory相关的选项
#!/bin/bash
pid=$(ps -ef|grep Server.jar|awk '{if($8=="java"){print $2}}')
kill -9 $pid
cd /opt/Server/
sh run.sh
echo off
wmic process where Name='java.exe' delete
cd D:\Server
start run.bat
4.3.4、垃圾收集器相关选项
4.3.5、GC日志相关选项
4.3.6、其他参数
4.4、通过Java代码获取JVM参数
package com.pengtxyl.three.chapter03.jvm;
import java.lang.management.ManagementFactory;
import java.lang.management.MemoryMXBean;
import java.lang.management.MemoryUsage;
public class MemoryMonitor {
public static void main(String[] args) {
MemoryMXBean memoryMXBean = ManagementFactory.getMemoryMXBean();
MemoryUsage usage = memoryMXBean.getHeapMemoryUsage();
System.out.println("INIT HEAP: " + usage.getInit() / 1024 / 1024 + "m");
System.out.println("MAX HEAP: " + usage.getMax() / 1024 / 1024 + "m");
System.out.println("USE HEAP: " + usage.getUsed() / 1024 / 1024 + "m");
System.out.println("\nFull Information: ");
System.out.println("Heap Memory Usage: " + memoryMXBean.getHeapMemoryUsage());
System.out.println("Non-Heap Memory Usage: " + memoryMXBean.getNonHeapMemoryUsage());
System.out.println("=====通过 java 来获取相关系统状态=====");
System.out.println("当前堆内存大小 totalMemory: " + (int) Runtime.getRuntime().totalMemory() / 1024 / 1024 + "m");
System.out.println("空闲堆内存大小 freeMemory: " + (int)Runtime.getRuntime().freeMemory() / 1024 / 1024 + "m");
System.out.println("最大可用总堆内存 maxMemory: " + Runtime.getRuntime().maxMemory() / 1024 / 1024 + "m");
}
}
输出结果:
INIT HEAP: 126m
MAX HEAP: 1772m
USE HEAP: 3m
Full Information:
Heap Memory Usage: init = 132120576(129024K) used = 3361168(3282K) committed = 126877696(123904K) max = 1858600960(1815040K)
Non-Heap Memory Usage: init = 2555904(2496K) used = 5193192(5071K) committed = 8060928(7872K) max = -1(-1K)
=====通过 java 来获取相关系统状态=====
当前堆内存大小 totalMemory: 121m
空闲堆内存大小 freeMemory: 117m
最大可用总堆内存 maxMemory: 1772m
Process finished with exit code 0
5、分析 GC 日志
5.1、GC日志参数
5.2、GC日志格式
5.2.1、复习:GC分类
5.2.2、GC日志分类
[GC (Allocation Failure) [PSYoungGen: 31744K->2192K(36863K)]
31744K->2200K(121856K),0.0139308 secs] [Times: user=0.05 sys=0.01,
real=0.01 secs]

[Full GC (Metadata GC Threshold) [PSYoungGen: 5104K->0K(132096K)]
[ParOldGen: 416K->5453K(50176K)] 5520K->5453K(182272K), [Metaspace:
20637K->20637K(1067008K)], 0.0245883 secs] [Times: user=0.06 sys=0.00,
real=0.02 secs]

5.2.3、GC日志结构剖析
5.2.4、Minor GC日志解析
2021-11-20T17:19:43.265-0800: 0.822: [GC (ALLOCATION FAILURE) [PSYOUNGGEN:
76800K->8433K(89600K)] 76800K->8449K(294400K), 0.0088371 SECS] [TIMES:
USER=0.02 SYS=0.01, REAL=0.01 SECS]
5.2.5、Full GC日志剖析
2020-11-20T17:19:43.794-0800: 1.351: [FULL GC (METADATA GC THRESHOLD)
[PSYOUNGGEN: 10082K->0K(89600K)] [PAROLDGEN: 32K->9638K(204800K)]
10114K->9638K(29440K),
[METASPACE: 20158K->20156K(1067008K)], 0.0285388 SECS] [TIMES: USER=0.11,
SYS=0.00, REAL=0.03 SEC]
5.3、GC日志分析工具
5.3.1、GCeasy
5.3.2、GCViewer
5.3.3、其他工具