【十三】druid 原理解析
druid 原理解析
先前写了一篇博客关于druid集成相关的,这里来分析一下druid原理,结合这两篇文章希望读者能够把druid理解透彻。
一、druid介绍
Druid连接池是阿里巴巴开源的数据库连接池项目。Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
二、druid源码解读
首先从github把源码down下来,导入idea,可以整体代码结构如下:
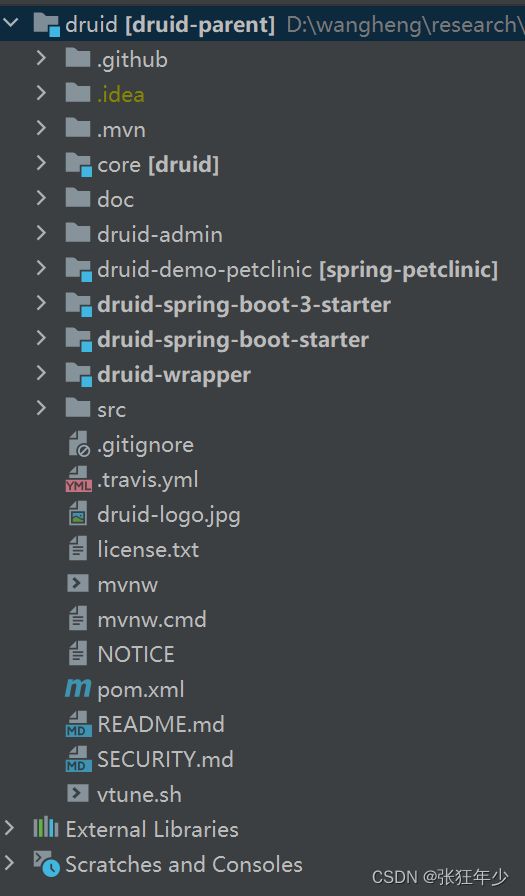
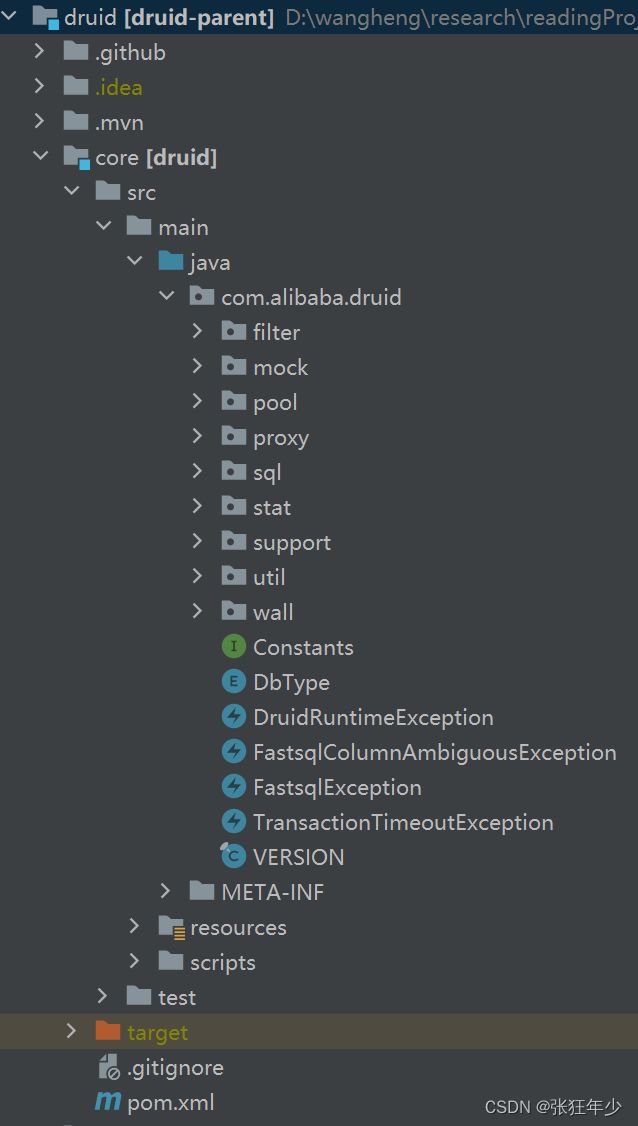
这里主要讲解一下核心包core,在test目录中有很多单元测试类,我们通过DruidTest来讲解Druid主流程。

通过debug,我们看到实例化DruidTest对象的时候,调用了数据库连接池参数初始化方法

继续往下看,我们找到了dataSource参数初始化方法
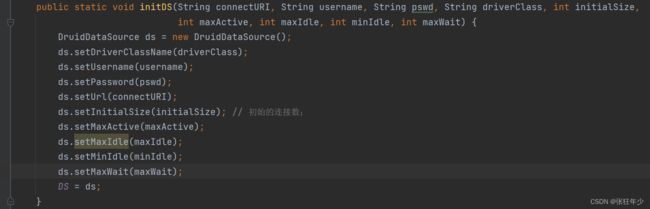
这里只是对数据库连接池对象DruidDataSource参数进行了初始化过程,数据库连接池怎么初始化的,以及怎么从数据库连接池中获取数据库连接,这一步应该是我们最关心的地方,之前使用jdbc的时候,每一次操作的时候都需要去连接数据库,这里我们要关注一下使用druid之后获取连接有什么不一样,池化技术是怎么实现的。

这里我们注意到调用了init()方法,这个方法逻辑比较复杂,这里不展开来讲解了,我们这次只关注主流程的分析,理解清楚了主流程的逻辑之后有兴趣可以去看一下其他代码设计的逻辑。
在init()方法中我们找到了以下这段代码:

这段代码主要是不停的调用createPhysicalConnection()初始线程数。
再往后debug我们看到了创建连接线程的方法 createAndStartCreatorThread();
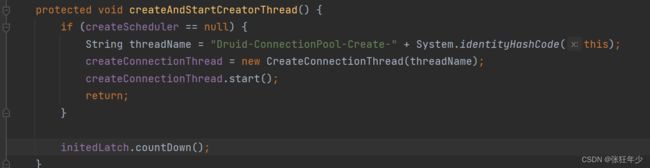
可以看到在方法中开启了一个创建连接的守护线程,线程中处理逻辑也是比较复杂的,我们还是先关注主流程的逻辑,在线程run方法中我们找到了创建连接的方法createPhysicalConnection(),这里有一个注意点run()方法里面是一个死循环
//创建连接
createPhysicalConnection(url, physicalConnectProperties);
//初始化连接,设置自动提交、事务隔离性
initPhysicalConnection(conn, variables, globalVariables);
进入createPhysicalConnection方法我们关注一下如下这段逻辑:
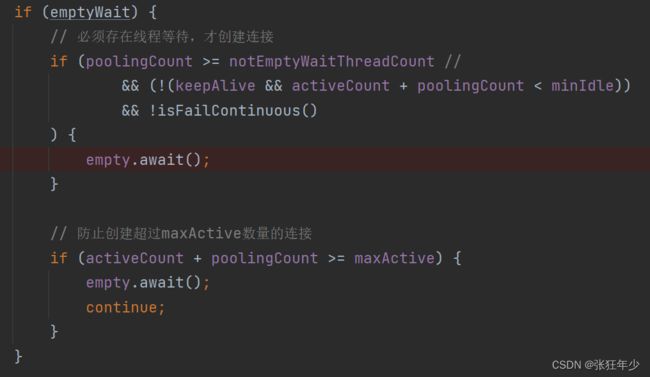
这里设计的比较巧妙,通过判断是否存在线程等待的情况,去执行下面创建新连接的逻辑。
我这边通过创建一个初始化线程数为1的方式来测试了一下这段代码的逻辑:
initDS(connectURI, "root", "123456", "com.mysql.cj.jdbc.Driver", 1, 10, 10, 10, 10);
另外写了一个循环来获取比数据库连接:
因为获取的线程数大于初始化线程数所以会触发创建新连接的逻辑。
总结:本篇文章从druid连接池概括介绍到druid主流程的源码分析,应该是把druid的原理讲解的比较清晰了,后续还会去介绍一下数据库连接的归还和销毁等逻辑,在这里没有过多的展开细节的地方,如果过多的去分析源码的实现细节阅读源码的过程中就很容易陷入其中,这也是我对大家的阅读源码的一个忠告,分析一款开源产品一定是先抓主线,理解透彻之后再去分析细节。最后,感谢大家认真阅读本篇文章,希望大家有所收获!