爬虫练习题
1.安装requests库,并爬取百度首页
import requests
url='https://www.baidu.com/'
r=requests.get(url)
r.status_code
r.ending='utf-8'
r.text2.使用BeautifulSoup库爬取计科院网站首页
#爬取计科院网站首页
import requests
from bs4 import BeautifulSoup
url='https://www.swpu.edu.cn/scs/'
res=requests.get(url)
print(res.status_code)
res.encoding='tf-8'
html=res.text
soup=BeautifulSoup(html,'html.parser')
items=soup.find('ul',class_='dynamic_list dynamic_listh').find_all('li')
for item in items:
print(item.find('a').text)
3.从下厨房网站爬取热门菜谱清单
#从下厨房网站爬取热门菜谱清单
import requests
from bs4 import BeautifulSoup
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.42"}
url='https://www.xiachufang.com/explore/'
res=requests.get(url)
#print(res.status_code)
res.coding='utf-8'
html=res.text
soup=BeautifulSoup(html,'html.parser')
items=soup.find_all('div',class_='info pure-u')
ls=[]
for i in items:
tag_a=i.find('a')
name=tag_a.text.strip(" ")
path=url+tag_a['href']
tag_p=i.find('p',class_='ing ellipsis')
shicai=tag_p.text.strip()
ls.append([name,path,shicai])
print(name,path,shicai)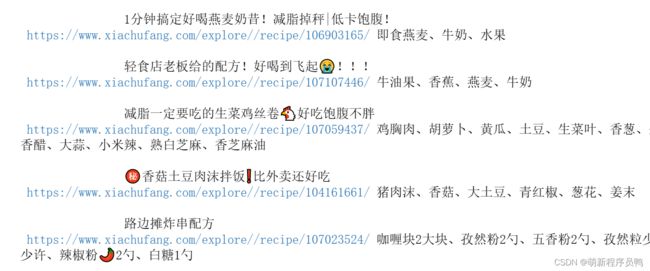
4.爬取豆瓣网top250电影的信息
#爬取豆瓣top250电影的信息
import requests # 引用requests库
from bs4 import BeautifulSoup # 引用BeautifulSoup库
url = 'https://movie.douban.com/top250?start=0&filter='
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
res =requests.get(url,headers = headers) #反爬机制
res.status_code
res.encodeing='utf-8'
text=res.text
soup=BeautifulSoup(text,'html.parser') # 使用BeautifulSoup来解析
items=soup.find_all('div',class_='item') # 查找最小父级标签
for i in items:
print('序号:'+i.find('em').text)
print('片名:'+i.find('span',class_='title').text)
print('评分:'+i.find('span',class_='rating_num').text)
print('宣传语:'+i.find('span',class_='inq').text)
print('链接:'+i.find('a').get('href'))
print('\t')
 5.从国家统计局网站爬取数据
5.从国家统计局网站爬取数据
#从国家统计局网站爬取信息
import requests
from bs4 import BeautifulSoup
import xlwt
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
# 发送请求并获取页面内容
url = 'http://www.stats.gov.cn/xxgk/sjfb/zxfb2020/202303/t20230316_1937306.html'
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 获取表格
tables = soup.find_all('table', class_='MsoNormalTable')
# 创建Excel文件并写入表格数据
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
num = 1
for table in tables:
sheet = book.add_sheet(f'Sheet{num}', cell_overwrite_ok=True)
num = num + 1
row = 0
for tr in table.select('tr'):
col = 0
for td in tr.select('td'):
sheet.write(row, col, td.text.strip())
col += 1
row += 1
book.save('商品住宅销售价格3.xls')
print('数据已成功爬取并保存为Excel文件!')
6.爬取网易云音乐评论
import requests
from Crypto.Cipher import AES;
from base64 import b64encode
import json
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52"
}
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
# 第一个参数
data = {
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_2037904519",
"threadId":"R_SO_4_2037904519"
}
# 第二个参数
e = '010001'
# 第三个参数
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
# 第四个参数
g = '0CoJUm6Qyw8W8jud'
#随机值
i = "R93tStvY71dWCson"
def get_ensSecKey():
return "dd0470d9b4253b249254d3c8e5a08b021ec86e0a2b4d763cb44b0effa4a01676d42634ccf6b85e1476a0ce4c13cc26e9de842093fc49fe2f68fe2cb4b5b70ff6f7f615c02f77b605f6390c8a62871447aa1f90cb4d11f305d95d47bcb9fd112cf5b069f2b87957282c7f9542cd3b35349335e66afb3a52eb63b03b1e051bfe71"
#AES两次加密
def get_params(data):
first = enc_params(data, g);
secend = enc_params(first, i);
return secend;
def to_16(data):
pad = 16 - len(data) % 16;
data += chr(pad) * pad
return data
#加密params
def enc_params(data, key):
aes = AES.new(key=key.encode('utf-8'), IV="0102030405060708".encode('utf-8'), mode=AES.MODE_CBC)
data = to_16(data)
bs = aes.encrypt(data.encode('utf-8')) # 加密的内容长度必须是16的倍数
return str(b64encode(bs), "utf-8")
#url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
resp = requests.post(url, data={
"params": get_params(json.dumps(data)),
"encSecKey": get_ensSecKey()
})
resp.encoding = 'utf-8'
dic = resp.json();
comments = dic['data']['hotComments']
for comment in comments:
userId = comment['user']['userId']
print('评论者ID:'+str(userId))
nickname = comment['user']['nickname']
print('昵称:'+nickname)
time = comment['timeStr']
print('评论时间:'+str(time))
content = comment['content']
print('评论:'+content)
print("---------------------------------------") 
7.参照教材59页:使用requests抓取黑马程序员论坛的数据
import requests
def load_page(url):
headers = {"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/111.0"}
response = requests.get(url, headers=headers)
return response.text
def save_file(html,filename):
print("正在保存" + filename)
with open(filename, 'w', encoding='utf-8') as file:
file.write(html)
def heima_forum(begin_page, end_page):
for page in range(begin_page, end_page + 1):
url = f'http://bbs.itheima.com/forum-425-{page}.html'
file_name = "第" + str(page) + "页.html"
html = load_page(url)
save_file(html, file_name)
if __name__ == "__main__":
begin_page = int(input("请输入起始页码:"))
end_page = int(input("请输入结束页码:"))
heima_forum(begin_page, end_page)
8.参照教材59页:使用request、正则表达式和文件操作爬取并保存”百度贴吧“某帖子全部内容
import re
import requests
def load_page(url):
url: url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
result = response.text
# 正则表达式提取汉字
result = re.findall(r'[\u4e00-\u9fa5]', result)
return result
def save_file(html, filename):
print("正在保存" + filename)
with open(filename, 'w', encoding='utf-8') as file:
file.write(' '.join(html))
def heima_forum(begin_page, end_page):
for page in range(begin_page, end_page + 1):
url = f'https://tieba.baidu.com/p/2124919966#!/l/p1'
filename = '第' + str(page) + '条评论'
html = load_page(url)
save_file(html, filename)
if __name__ == '__main__':
begin_page = int(input("请输入起始条数:"))
end_page = int(input("请输入结束条数:"))
heima_forum(begin_page, end_page)

9.参照教材88页采集黑马程序员论坛的帖子
import json
from lxml import etree
import requests
# 爬取网址
# http://bbs.itheima.com/forum-425-1.html
def load_page(url):
'''
作用:根据url发送请求,获取服务器响应文件
url:需要爬取的url地址
'''
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident / 5.0;"}
request = requests.get(url, headers=headers)
return request.text
def parse_html(html):
text = etree.HTML(html)
node_list = text.xpath('//th[contains(@class,"new") and contains(@class,"forumtit")]')
items = [] # 定义空列表,以保存元素的信息
num = 0 # 定义计数器,用于判断某天前条数
for node in node_list:
try:
# 文章标题
title = node.xpath('./a[1]/text()')[0]
# 文章链接
url = node.xpath('./a[1]/@href')[0]
# 文章作者
author = node.xpath(
'./div[@class="foruminfo"]//a/span/text()')[0]
# 发布时间(具体日期)
release_time = node.xpath('./div[2]/i/span[1]/text()'
)[0].strip().replace('@', '')
# 发布时间(某天前)
one_page = node.xpath('//div[2]/i/span[1]/span/@title')
if one_page:
if num < len(one_page):
release_time = node.xpath(
'//div[2]/i/span[1]/span/@title')[num]
# 构建JSON格式的字符串
item = {
"文章标题": title,
"文章链接": url,
"文章作者": author,
'发布时间': release_time,
}
items.append(item)
num += 1
except Exception as e:
pass
return items
def save_file(items):
try:
with open('heima.json', mode='w+', encoding='utf-8') as f:
f.write(json.dumps(items, ensure_ascii=False, indent=2))
except Exception as e:
print(e)
def heima_forum(begin_page, end_page):
li_data = []
for page in range(begin_page, end_page + 1):
url = f'http://bbs.itheima.com/forum-424-{page}.html'
file_name = "正在请求第" + str(page) + "页"
print(file_name)
html = load_page(url)
data = parse_html(html)
li_data += data
save_file(li_data)
if __name__ == "__main__":
begin_page = int(input("请输入起始页码:"))
end_page = int(input("请输入结束页码:"))
heima_forum(begin_page, end_page)

目录
1.安装requests库,并爬取百度首页
2.使用BeautifulSoup库爬取计科院网站首页
3.从下厨房网站爬取热门菜谱清单
4.爬取豆瓣网top250电影的信息
5.从国家统计局网站爬取数据
6.爬取网易云音乐评论
7.参照教材59页:使用requests抓取黑马程序员论坛的数据
8.参照教材59页:使用request、正则表达式和文件操作爬取并保存”百度贴吧“某帖子全部内容
9.参照教材88页采集黑马程序员论坛的帖子