全球新闻数据可视化(1)--数据下载与处理
一、GDELT介绍
GDELT ( www.gdeltproject.org ) 每时每刻监控着每个国家的几乎每个角落的 100 多种语言的新闻媒体 -- 印刷的、广播的和web 形式的,识别人员、位置、组织、数量、主题、数据源、情绪、报价、图片和每秒都在推动全球社会的事件,GDELT 为全球提供了一个自由开放的计算平台。
GDELT 主要包含两大数据集: Event Database (事件数据库) 、 Global Knowledge Graph (GKG, 全球知识图谱),记录了从1969 年至今的新闻,并于每十五分钟更新一次数据。
二、研究内容
本次研究数据来自 gdelt 数据库,爬取 2022.01.01-2022.07.20 所有 export 和 mentions 表,从中提取俄乌 冲突相关数据,由此进行分析。主要分析内容如下:
- 基于BERT实现GDELT新闻事件数据中事件正文文本的情感分析
- 基于MySQL的本地数据库导入、查询和存储
- 基于JavaScript和echarts的数据可视化图表库对新闻事件数据进行多方面可视化
- 将可视化界面部署到服务器上以供其他用户通过网址查看
- 其他算法进行情感分析
三、项目实施方法设计
1、使用语言
前段静态页面: html 、 css 、 JavaScript 、 echarts
连接数据库页面:增加 php 连接 MySQL
数据处理: Pycharm+Python , Jupyter+Python
2、项目流程
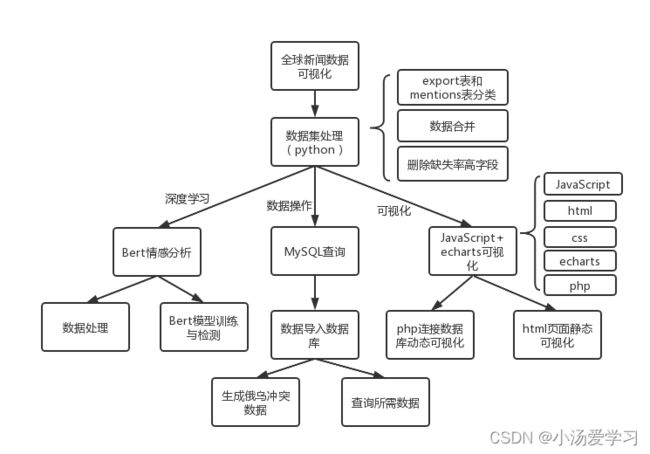
四、具体实现与测试
1、数据集下载
def get_data(url):# 获取url
file_name = url.split("gdeltv2/")[1].split(".zip")[0]
r = requests.get(url)
temp_file=open("./temp.zip", "wb")
temp_file.write(r.content)
temp_file.close()
try:
my_zip=zipfile.ZipFile('./temp.zip','r')
my_zip.extract(file_name,path="./data")
my_zip.close()
except Exception:
print("%s not exist" % file_name)
return None
def get_data_df(): #日期读取
f=open("date.txt")
date=[]
time=[]
for i in f.readlines():
date.append(i.strip("\n"))
f.close()
f=open("time.txt")
for i in f.readlines():
time.append(i.strip("\n"))
f.close()
#地址整合
url1 = "http://data.gdeltproject.org/gdeltv2/%s.export.CSV.zip"
url2 = "http://data.gdeltproject.org/gdeltv2/%s.mentions.CSV.zip"
for i in date:
for j in time:
str_real_time=i+j
get_data(url1%str_real_time)
get_data(url2%str_real_time)
print("%s-complete"%i) 下载 2022.01.01-2022.07.20 的数据, 数据量大约 20GB ,下载完成后, export 表和 mentions 表混合放置,因此需要将表按月分类放置,代码如下:
import os
import shutil
for i in range(1,8):
src_folder="./totaldata/20220"+str(i)
tar_folder="./totaldata/20220"+str(i)
files=os.listdir(src_folder)
for file in files:
src_path=src_folder+'/'+file
for file in files:
# 将每个文件的完整路径拼接出来
src_path = src_folder + '/' + file
if os.path.isfile(src_path):
tar_path = tar_folder + '/' + file.split('.')[-2]
print(tar_path)
# 如果文件夹不存在则创建
if not os.path.exists(tar_path):
os.mkdir(tar_path)
# 移动文件
shutil.move(src_path, tar_path) 为了更方便处理,我们将 export 表的数据合并, mentions 表的数据合并,代码如下:
os.chdir(Folder_Path)
file_list=os.listdir()
for i in range(1,len(file_list)):
df=pd.read_csv(file_list[i],sep='\t')
df.to_csv(SaveFile_Path+"/"+SaveFile_Name,encoding="utf_8_sig",
index=False,header=None,mode='a+')
sys.stdout.write("\r已合并:%.2f%%"%float((i/len(file_list))*100))
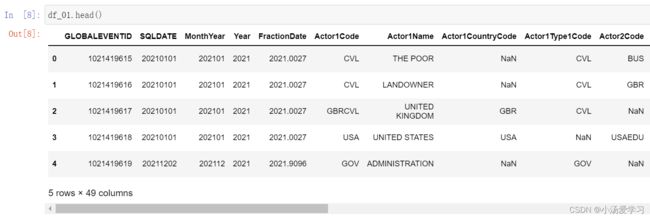
sys.stdout.flush()2、数据集处理
(1)查看空字段数量并排序
is_null=df_01.isnull().sum().sort_values(ascending=False)
is_null[is_null>row*0.85]#筛选出空值数量大于85%的数据(2)删除缺失率大于85%字段
drop_columns=['Actor2Type3Code','Actor1Type3Code','Actor2Religion2Code',
'Actor1Religion2Code','Actor2EthnicCode','Actor1EthnicCode',
'Actor2Religion1Code','Actor2KnownGroupCode','Actor1Religion1Code',
'Actor1KnownGroupCode','Actor2Type2Code','Actor1Type2Code']
df_01.drop(drop_columns,axis=1,inplace=True)得到结果如下:
3、数据导入MySQL与分析
(1)创建数据库
这里值得注意的是,很多字段在后续分析中没有用到,但还是导入进去了,为了和元数据保持一致性。
CREATE TABLE `export` (
`GLOBALEVENTID` int NOT NULL,
`SQLDATE` bigint,
`MonthYear` bigint,
`Year` bigint,
`FractionDate` bigint,
`Actor1Code` varchar(255),
`Actor1Name` varchar(255),
`Actor1CountryCode` varchar(255),
`Actor1Type1Code` varchar(255),
`Actor2Code` varchar(255),
`Actor2Name` varchar(255),
`Actor2CountryCode` varchar(255),
`Actor2Type1Code` varchar(255),
`IsRootEvent` varchar(255),
`EventCode` varchar(255),
`EventBaseCode` varchar(255),
`EventRootCode` varchar(255),
`QuadClass` int,
`GoldsteinScale` double,
`NumMentions` int,
`NumSources` int,
`NumArticles` int,
`AvgTone` double,
`Actor1Geo_Type` varchar(255),
`Actor1Geo_FullName` varchar(255),
`Actor1Geo_CountryCode` varchar(255),
`Actor1Geo_ADM1Code` varchar(255),
`Actor1Geo_ADM2Code` varchar(255),
`Actor1Geo_Lat` double,
`Actor1Geo_Long` double,
`Actor1Geo_FeatureID` varchar(255),
`Actor2Geo_Type` varchar(255),
`Actor2Geo_FullName` varchar(255),
`Actor2Geo_CountryCode` varchar(255),
`Actor2Geo_ADM1Code` varchar(255),
`Actor2Geo_ADM2Code` varchar(255),
`Actor2Geo_Lat` double,
`Actor2Geo_Long` double,
`Actor2Geo_FeatureID` varchar(255),
`ActionGeo_Type` varchar(255),
`ActionGeo_FullName` varchar(255),
`ActionGeo_CountryCode` varchar(255),
`ActionGeo_ADM1Code` varchar(255),
`ActionGeo_ADM2Code` varchar(255),
`ActionGeo_Lat` double,
`ActionGeo_Long` double,
`ActionGeo_FeatureID` varchar(255),
`DATEADDED` bigint,
`SOURCEURL` text,
PRIMARY KEY (`GLOBALEVENTID`)
);(2)导入数据
LOAD DATA INFILE 'E:/term/code/mergedata/export/export_202201.csv' INTO TABLE
`export`
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\r\n'
IGNORE 1 ROWS;(3)年份处理和简单查询
DELETE
FROM rus_and_ukr
WHERE `MonthYear`<202201
SELECT COUNT(GLOBALEVENTID) FROM export -- 21504131接下来将针对俄乌冲突进行筛选查询和可视化~