【PWN】Pwndbg
参考文章:Linux下GDB简明教程(包括GUI模式)_whahu1989的专栏-CSDN博客
目录
一、gdb与pwndbg
二、调试
1.编译某一程序:gcc
2.gdb test
3.反汇编:disass main
4.常用的调试命令
1.b xx
2.r
3.c
4.n
5.s
6.info xx
7.p xx
8.set xx
9.x
10.bt
11.q
12. 删除断点
13.finish
14.(gdb) jump 5
15.(gdb) return
一、gdb与pwndbg
GDB——The GNU Project Debugger.是Linux下面的一款强大的基于命令行的软件调试器。
GDB的所有操作都基于命令行进行,有别于windows上的各种调试器。
GDB的调试目标主要是带源代码的软件,即进行开发调试。若想要进行逆向工程调试,则需要GDB插件来提供额外的功能。pwndbg专门针对pwn题调试添加了额外的功能。
二、调试
1.编译某一程序:gcc
gcc -m32 -o test test.c
或gcc test.c -o test
或gcc -Wall -g -o test test.c
-Wall 代表编译器在编译过程中会输出警告信息(Warning),比如有些变量你并没有使用,指针指向的类型有误,main 函数没有返回整数值等。
-g 代表编译器会收集调试(debug)信息,这样如果你的程序运行出错,就可以通过 gdb 或者 lldb 等工具进行逐行调试,方便找出错误原因。
-o 代表编译器会将编译完成后的可执行文件以你指定的名称输出到你指定的文件夹下。-o 的空格后的名称就是输出的文件的名称。如果不加这个参数,每次编译后生成的可执行文件都会放在根目录下,名字叫做 a.out。每次编译成功后都会把上一次的 a.out 文件覆盖。
-m32:编译32位程序
2.gdb test
3.反汇编:disass main
4.常用的调试命令
1.b xx
设置断点(b是breakpoint的缩写)
b 函数名 //在指定函数的起始处设置断点
b 行号 //在指定代码行设置断点
b 文件名:函数名
b 文件名:行号
b +偏移量
b -偏移量
b *地址 //不建议使用
2.r
运行的意思(r是run的缩写),一般用来代码开始运行,或者重新运行(如果调试到一半又想从头开始运行)
n(不会进入函数内部)
s(会执行到函数内部)
c
start(无断点时)
3.c
继续执行(c是continue的缩写),当执行r运行到某个断点后,后面想继续执行到下一个断点或者把剩下代码执行完毕,就可以使用c
4.n
next的意思,执行当前行代码
5.s
step的意思,当一行代码里有函数调用,那么执行s会跳入函数里执行,如果没有函数调用,那么效果和n相同
6.info xx
查看一些信息,如断点或者局部变量,分别是info b和info locals
i r,查看寄存器
查看断点信息:info br,简写:i b
info register $ebp 查看寄存器ebp中的内容 (简写为 i r ebp)
i r eflags 查看状态寄存器
i r ss 查看段寄存器
i functions 查看所有的函数
disas addr 查看addr处前后的反汇编代码
stack 20 查看栈内20个值
show args 查看参数
vmmap 查看映射状况 peda带有
readelf 查看elf文件中各个段的起始地址 peda带有
parseheap 显示堆状况 peda带有
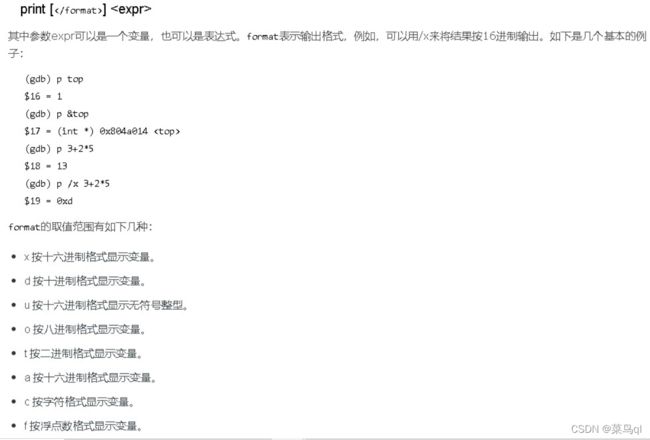
7.p xx
p是print的缩写,打印某个变量的值。
p system/main 显示某个函数地址
p $esp 显示寄存器
p/x p/a p/b p/s。。。
p 0xff - 0xea 计算器
print &VarName 查看变量地址
p * 0xffffebac 查看某个地址处的值
8.set xx
设置某个变量的值
9.x
指定大小 起始内存地址,即查看起始内存地址上指定大小的内存里的值。如x /3b 0x11223344,就是查看以0x11223344开始的3个字节的值,也可以是x /3w 0x11223344,就是查看以0x11223344开始的3个word的值
命令格式:x/
n是一个正整数,表示需要显示的内存单元的个数
f 表示显示的格式(可取如下值: x 按十六进制格式显示变量。d 按十进制格式显示变量。u 按十进制格式显示无符号整型。o 按八进制格式显示变量。t 按二进制格式显示变量。a 按十六进制格式显示变量。i 指令地址格式c 按字符格式显示变量。f 按浮点数格式显示变量。)
u 表示从当前地址往后请求的字节数 默认4byte,u参数可以用下面的字符来代替,b表示单字节,h表示双字节,w表示四字节,g表示八字节
x/xw addr 显示某个地址处开始的16进制内容,如果有符号表会加载符号表
x/x $esp 查看esp寄存器中的值
如x $ebp-0x2c
x/s addr 查看addr处的字符串
x/b addr 查看addr处的字符
x/i addr 查看addr处的反汇编结果

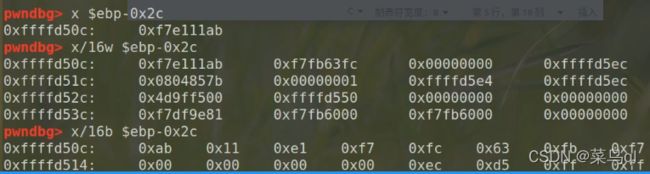
共16组,分别以四字节/单字节显示
10.bt
backtrace的缩写,回溯,当使用s进入某个函数后,输入bt可以打印该函数的栈帧
list,在命令行下显示源码,可以是list或者list 行号,后者是以指定行号为基准,显示该行号前后的代码
11.q
quit的意思,即退出gdb调试
12. 删除断点
delete <断点id>:删除指定断点 //也可简写delete为d
delete:删除所有断点
clear 函数名
clear 行号
clear 文件名:行号
clear 文件名:函数名
13.finish
执行完当前函数返回到调用它的函数。运行程序,直到当前函数运行完毕返回再停止。例如进入的单步执行如果已经进入了某函数,而想退出该函数返回到它的调用函数中,可使用命令finish.
14.(gdb) jump 5
跳转执行程序到第5行:这里,可以简写为"j 5"需要注意的是,跳转到第5行执行完毕之后,如果后面没有断点则继续执行,而并不是停在那里了。另外,跳转不会改变当前的堆栈内容,所以跳到别的函数中就会有奇怪的现象,因此最好跳转在一个函数内部进行。跳转的参数也可以是程序代码行的地址,函数名等等。
15.(gdb) return
强制返回当前函数: 这样,将会忽略当前函数还没有执行完毕的语句,强制返回。return后面可以接一个表达式,表达式的返回值就是函数的返回值。
函数的逆向存储:
如函数add(int a,int b){xxx
}
在调用add()前,a,b两个参数先入栈
例:
最简单的内存破坏就是数组溢出。因为数组内存是连续的,数组溢出之后,数据会覆盖数据后面的内存。
#include
#include
#include
int main(void){
char name[10];
int flag = 0;
puts("What's you name?");
fgets(name,50,stdin);
if(flag){
puts("You are here!");
}
return 0;
}
由于Linux下的gcc编译器不支持gets函数,程序编译过后会出现一个警告,即:“warning: the `gets' function is dangerous and should not be used.”
此时,可以用fgets函数代替,函数在头文件stdio.h中,函数原型:char *fgets(char *buf, int bufsize, FILE *stream),即从文件结构体指针stream(键盘输入stdin)中读取数据,每次读一行,读取的数据保存在buf指向的字符数组中,每次最多读bufsize-1个字符(第bufsize个字符赋'\0').
ps:fgets函数会读取'\n'(gets不会),因此有时要将最后的回车符换成\0,否则会有差错。
在以上这一段代码中,
if(flag){
puts("You are here!");
}
这一段代码似乎是永远不可能运行的,称为死代码。但我们可以利用fgets函数的漏洞,实现这一代码的执行;
下面以如上代码为例,介绍一下常用操作命令:
gcc -g test.cpp
对程序进行编译,并开启-g选项生成调试信息,这样gdb才可以调试程序
gdb ./a.out
编译成功后生成a.out。我们开始调试
打印如下
 此时处于命令模式,我们可以输入相关命令来进行调试。
此时处于命令模式,我们可以输入相关命令来进行调试。
起始
输入b main并回车,意思是在main函数起始处打断点,然后输入r并回车,开始执行程序,程序会在main开始处停下来,因为这边设置了断点。
这套操作是调试的基础,因为程序运行都从main函数开始执行,所以我们都会从main开始调试。
执行代码
此时输入n并回车,程序就会执行一行代码。每输入一个n并回车,都会执行一行代码。如果这一行代码有函数调用,那么再输入s就会进入函数体内并执行函数的第一行代码,如果输入n则直接把被调函数执行完。

查看变量
代码里有个结构体变量flag,我们来查看下它的信息,输入p flag
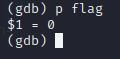
查看结构体里的成员则是p xxx.xxx
查看地址:p &xxx
p &xxx.xxx
![]()
当然,也可以用x查看

用&取地址也行得通
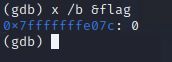
修改变量
修改obj里成员变量的值,使用set flag=1
这个命令就是直接修改内存里的值,这样如果后续代码没有对这个变量重新赋值,那么后面这个变量的值就是我们手动设置的值了。
ps
查看栈:stack 0xxxx