【数据结构】建堆的方式、堆排序以及TopK问题
建堆的方式、堆排序以及TopK问题
- 1、建堆的两种方式
-
- 1.1 向上调整建堆
- 1.2 向下调整建堆
- 2、堆排序
- 3、TopK问题
- 4、建堆、堆排序、TopK问题全部代码
1、建堆的两种方式
我们知道,堆是二叉树的一种,二叉树的建立是借助结构体与数组完成的(通过在结构体中创建动态开辟的数组变量储存堆中的元素)。
除了借助结构体外,有没有其他方式,直接建堆。
1.1 向上调整建堆
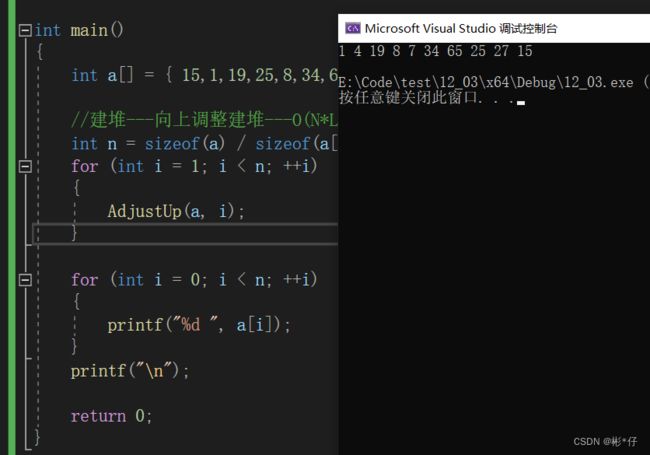
//交换函数 void Swap(HPDataType* p1, HPDataType* p2) { HPDataType tmp = *p1; *p1 = *p2; *p2 = tmp; } //向上调整函数 typedef int HPDataType; void AdjustUp(HPDataType* a, int child) { int parent = (child - 1) / 2; //找到堆最后一个数的父亲的下标 while (child > 0) //孩子的下标等于0时,说明堆从最后一个数一路向上比较,已经到达堆顶了 { //小根堆,任意孩子的值要大于父节点的值,不是的话则要向上调整 if (a[child] < a[parent]) //改为>,这个堆结构就成为大堆了 { Swap(&a[child], &a[parent]); //修正父亲与孩子的下标,通过循环不断比较,直到成为堆的形状 child = parent; parent = (child - 1) / 2; } else { break; } } } int main() { int a[] = { 15,1,19,25,8,34,65,4,27,7 }; //建堆---向上调整建堆---O(N*LogN) int n = sizeof(a) / sizeof(a[0]); for (int i = 1; i < n; ++i) { AdjustUp(a, i); } for (int i = 0; i < n; ++i) { printf("%d ", a[i]); } printf("\n"); return 0; }打印结果
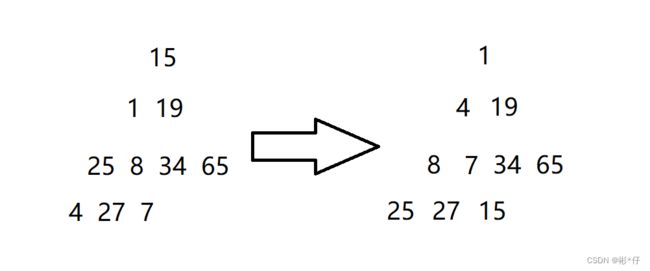
1.打印结果将一串无序的数组建立成为小堆。只要将向上调整中的if语句中的小于符号改成大于符号,建成的就是大堆。
2.向上调整建堆从第二个节点开始向上调整(即数组下标为1的节点),因为第一个节点是根节点,根节点没有父节点,再往上就没有节点了。第二个节点向上调整完毕,接着第三个节点,然后第四个节点、第五个节点,直到最后一个节点向上调整完毕。
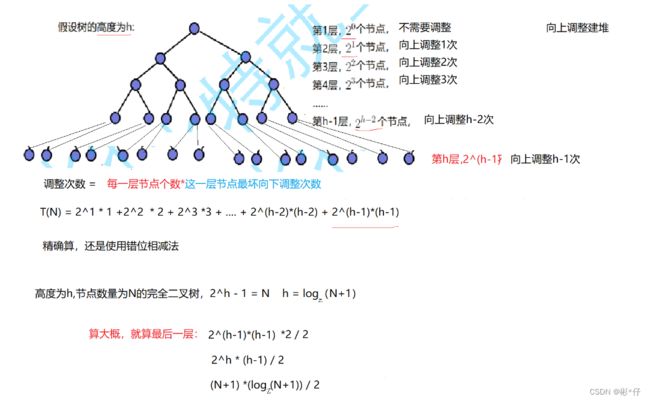
3.向上调整建堆的时间复杂度
可以看到,在一棵树中,越往下的节点,向上调整的次数越多,并且越往下的层级包含的节点数越多,所以越往下的层级每个节点向上调整的次数加起来是越大的。由上述式子计算,最后一层所有节点总共需要向上调整的次数最大为(N+1) * ((log(N+1)-1)/2),即最后一层需要向上调整的时间复杂度为O(N * log(N))。因为最后一层的时间复杂度已经是最大的,前面所有层级加起来的时间复杂度也不会超过,所以向上调整总的时间复杂度为O(N * log(N))。
1.2 向下调整建堆
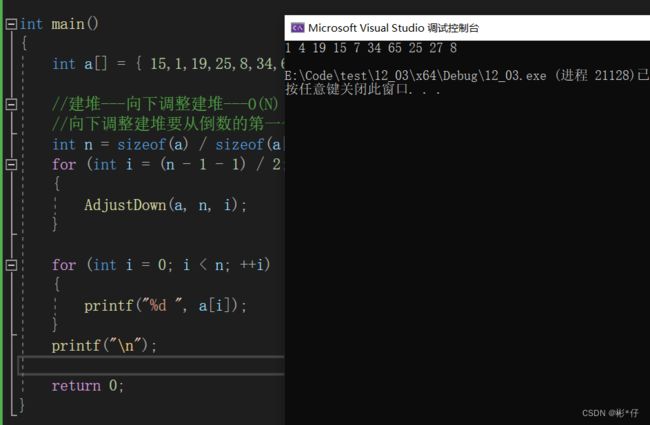
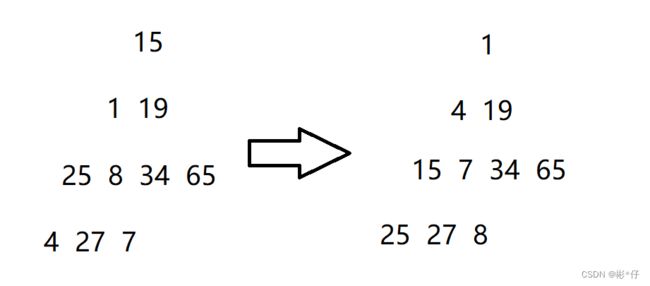
//交换函数 void Swap(HPDataType* p1, HPDataType* p2) { HPDataType tmp = *p1; *p1 = *p2; *p2 = tmp; } //向下调整函数 typedef int HPDataType; void AdjustDown(HPDataType* a, int n, int parent) { int minChild = parent * 2 + 1; //先默认左边的孩子是整个小根堆中次小的孩子 while (minChild < n) { //与右孩子比较一下,找出小的那个孩子的下标 if (minChild + 1 < n && a[minChild + 1] < a[minChild]) { minChild++; } //找到次小的孩子后将其与父节点比较 if (a[minChild] < a[parent]) { Swap(&a[minChild], &a[parent]); //修正父亲与孩子的下标,通过循环不断比较,直到成为堆的形状 parent = minChild; minChild = parent * 2 + 1; } else { break; } } } int main() { int a[] = { 15,1,19,25,8,34,65,4,27,7 }; //建堆---向下调整建堆---O(N) //向下调整建堆要从倒数的第一个非叶子节点开始向下调整,一直调整到根节点位置 int n = sizeof(a) / sizeof(a[0]); for (int i = (n - 1 - 1) / 2; i >= 0; --i) { AdjustDown(a, n, i); } for (int i = 0; i < n; ++i) { printf("%d ", a[i]); } printf("\n"); return 0; }打印结果
1.打印结果将一串无序的数组建立成为小堆。只要将向下调整中的两个if语句中的小于符号改成大于符号,建成的就是大堆。
2.向下调整建堆从倒数的第一个非叶子节点开始向下调整,因为叶子节点往下没有子节点了,不用在往下调整了。倒数第一个非叶子节点调整完毕,接着倒数第二个非叶子节点向下调整,然后倒数第三个非叶子节点向下调整,一直到根节点位置向下调整。(n-1-1)/2 是在找倒数第一个非叶子节点。
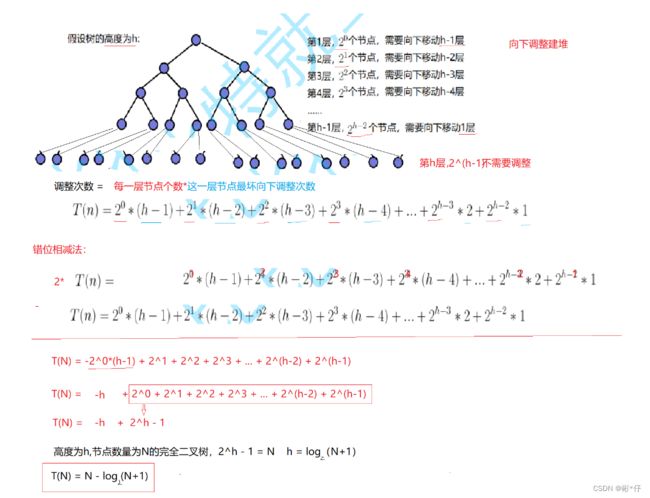
3.向下调整时间复杂度
由上述式子算出,向下调整建堆最坏需要向下调整N-log(N+1)次,因此向下调整建堆的时间复杂度为O(N)。
总结: 经由上述可知,向下调整建堆的时间复杂度与向上调整建堆的时间复杂度相比,向下调整建堆所需时间更少,因此在没有结构体构造堆的情况下,选择向下调整直接建堆。
2、堆排序
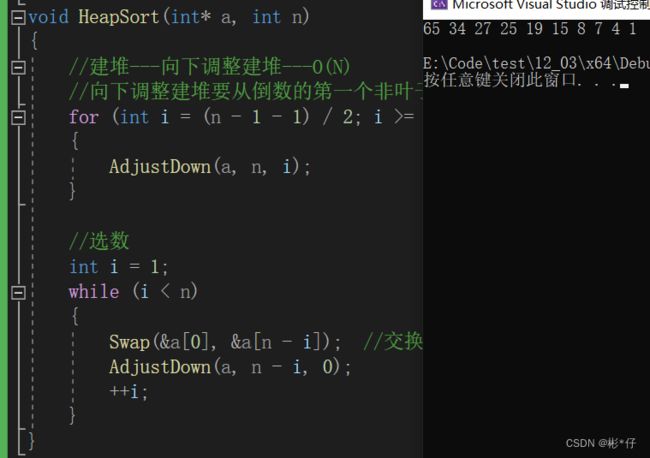
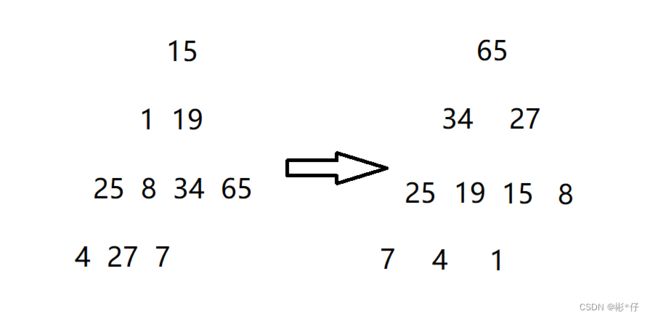
void Swap(HPDataType* p1, HPDataType* p2) { HPDataType tmp = *p1; *p1 = *p2; *p2 = tmp; } //向下调整函数 typedef int HPDataType; void AdjustDown(HPDataType* a, int n, int parent) { int minChild = parent * 2 + 1; //先默认左边的孩子是整个小根堆中次小的孩子 while (minChild < n) { //与右孩子比较一下,找出小的那个孩子的下标 if (minChild + 1 < n && a[minChild + 1] < a[minChild]) { minChild++; } //找到次小的孩子后将其与父节点比较 if (a[minChild] < a[parent]) { Swap(&a[minChild], &a[parent]); //修正父亲与孩子的下标,通过循环不断比较,直到成为堆的形状 parent = minChild; minChild = parent * 2 + 1; } else { break; } } } //堆排序函数 //大思路:选择排序,依次选数,从后往前排 //升序---先建大堆,建堆完毕后,此时最大的数在第一位,把第一个和最后一个的位置进行交换, // 交换完毕后,把最后一个不看做堆里面的,进行向下调整,选出次大的。后续依次类似处理。 //降序---先建小堆,建堆完毕后,此时最小的数在第一位,把第一个和最后一个的位置进行交换, //交换完毕后,把最后一个不看做堆里面的,进行向下调整,选出次小的。后续依次类似处理。 void HeapSort(int* a, int n) { //建堆---向下调整建堆---O(N) //向下调整建堆要从倒数的第一个非叶子节点开始向下调整,一直调整到根节点位置 for (int i = (n - 1 - 1) / 2; i >= 0; --i) { AdjustDown(a, n, i); } //选数 int i = 1; while (i < n) { Swap(&a[0], &a[n - i]); //交换第一个数跟最后一个数 AdjustDown(a, n - i, 0); ++i; } } int main() { int a[] = { 15,1,19,25,8,34,65,4,27,7 }; HeapSort(a, sizeof(a) / sizeof(int)); for (size_t i = 0; i < sizeof(a) / sizeof(int); ++i) { printf("%d ", a[i]); } printf("\n"); return 0; }打印结果
1.打印结果将一串无序的数组建立成为降序的小堆。
2.堆排序的思路:
大思路:选择排序,依次选数,从后往前排2.1升序—先建大堆,建堆完毕后,此时最大的数在第一位,把第一个和最后一个的位置进行交换,
交换完毕后,把最后一个不看做堆里面的,进行向下调整,选出次大的。后续依次类似处理。
2.2降序—先建小堆,建堆完毕后,此时最小的数在第一位,把第一个和最后一个的位置进行交换,
交换完毕后,把最后一个不看做堆里面的,进行向下调整,选出次小的。后续依次类似处理。
3、TopK问题
TopK问题就是在N个数中选出最大的前K个数或者最小的前K个数来。
这个问题有两种思路,例如选出最大的前K个数,
思路1,建大堆(用向下调整建堆的方式),将根节点与尾节点进行交换(此时根节点上的数为最大的数),交换后不将尾节点算入堆中,剩余的N-1个数重新建堆,重复K次,这样最大的前K个数就被筛选出来了。
时间复杂度为O(N+(logN)* K)。
思路2,建小堆(用向下调整建堆的方式),用N个数中的前K个数建一个K个数的小堆,剩余的N-K个数一一与堆顶比较,只要比堆顶大就入队,入堆后再重新向下调整建成小堆。当比较完毕后,小堆中的K个数就是在N个数中选出的最大前K个数。时间复杂度为K+(log(k)) *(N-K)。
分析思路1与思路2的优劣: 当N很大,K很小的时候,选第二种方式,例如当N=100亿,K=100,100亿个整数有400亿个字节(Byte),一个G有1024 *1024 *1024(Byte)=1073741824个字节(Byte)≈1000000000=10亿字节(Byte),所以当N=100亿时,要占用的空间为400÷10=40个G,所占内存过大,所以一般选用思路2的方式,即:
在N个数中选出最大的前K个数-----建小堆
在N个数中选出最小的前K个数-----建大堆
在文件中先写入10个数,选取这十个数中最大的前3个数,代码如下:
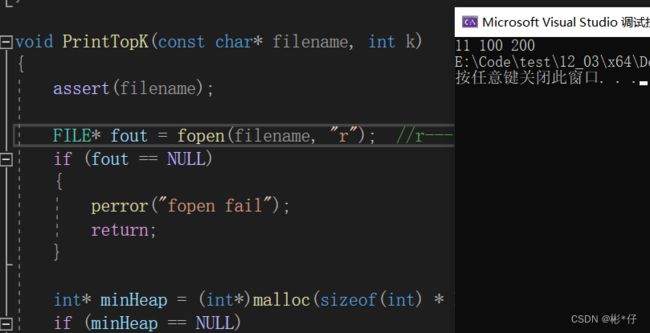
void PrintTopK(const char* filename, int k) { assert(filename); FILE* fout = fopen(filename, "r"); //r--->在Test,c这个源文件路径下打开一个本身已经存在的叫Data.txt的文件,将这个文件的地址赋值给文件指针 if (fout == NULL) { perror("fopen fail"); return; } int* minHeap = (int*)malloc(sizeof(int) * k); if (minHeap == NULL) { perror("malloc fail"); return; } //如何读取前k个数 for (int i = 0; i < k; ++i) { fscanf(fout, "%d", &minHeap[i]); } //建堆,将读取的前k个数建成小堆,向下调整建堆 for (int j = (k - 1 - 1) / 2; j >= 0; --j) { AdjustDown(minHeap, k, j); } //继续读取N-k个数 int val = 0; while (fscanf(fout, "%d", &val) != EOF) { if (val > minHeap[0]) { minHeap[0] = val; AdjustDown(minHeap, k, 0); } } for (int i = 0; i < k; ++i) { printf("%d ", minHeap[i]); } free(minHeap); fclose(fout); } //top k问题 N个数,找出这N个数中最大的前k个数 int main() { const char* filename = "Data.txt"; int k = 3; PrintTopK(filename, k); return 0; }1.Fopen:打开文件,Fclose:关闭文件,fscanf:从文件中读取数据(即从文件中输入数据到屏幕上,sanf是从键盘上输入数据到屏幕上)
2.fscanf(fout, “%d”, &val);从fout中以 %d的类型读取数据到变量val中。
3.已经存在的data.txt文件中10个数为 0 3 11 2 4 1 100 2 200 5。文件放在与Tsetc同一级的目录下。
4.打印结果为
前3个最大的数被选出来了,被选出来的数并不是有序的,这里有序只不过是巧合而已。
5. 向下调整函数的实现被写在了Heap.c中,在第一节中,向下调整的实现已经写过了,这里就不搬上来了。
在文件中随机生成10000个数(1~10000中的任意数,包含了重复的数),选出其中最大的前10个数来,如何实现?
这个只要多写一个在文件中随机生成数的函数就行,代码如下。
//在文件中随机数的生成 void CreateDataFile(const char* filename, int k) { assert(filename); FILE* fin = fopen(filename, "w"); //w--->在test.c这个源文件路径下创建一个test.txt的文件,如果这个文件已经存在,则将 //这个文件里的内容全部销毁,相当于重新创建了这个文件。 if (fin == NULL) { perror("fin fail"); return; } srand(time(0)); for (int i = 0; i < k; ++i) { fprintf(fin, "%d\n", rand()%10000); } fclose(fin); } void PrintTopK(const char* filename, int k) { assert(filename); FILE* fout = fopen(filename, "r"); //r--->在Test,c这个源文件路径下打开一个本身已经存在的叫Data.txt的文件,将这个文件的地址赋值给文件指针 if (fout == NULL) { perror("fopen fail"); return; } int* minHeap = (int*)malloc(sizeof(int) * k); if (minHeap == NULL) { perror("malloc fail"); return; } //如何读取前k个数 for (int i = 0; i < k; ++i) { fscanf(fout, "%d", &minHeap[i]); } //建堆,将读取的前k个数建成小堆 for (int j = (k - 1 - 1) / 2; j >= 0; --j) { AdjustDown(minHeap, k, j); } //继续读取N-k个数 int val = 0; while (fscanf(fout, "%d", &val) != EOF) { if (val > minHeap[0]) { minHeap[0] = val; AdjustDown(minHeap, k, 0); } } for (int i = 0; i < k; ++i) { printf("%d ", minHeap[i]); } free(minHeap); fclose(fout); } int main() { const char* filename = "Data.txt"; int N = 10000; int k = 10; CreateDataFile(filename, N); PrintTopK(filename, k); return 0; }1.void CreateDataFile(const char* filename, int k);---->在文件中生成随机数
2.如何生成随机数?
rand()函数能够生成不同的伪随机数,如果要生成0到10000之间的伪随机数,则rand()%10000,这样生成的伪随机数就是0~9999。不过如果直接使用rand(),每次生成的伪随机数都是一样的,比如第一次生成的是1 4 99 3……,下一次运行程序生成的还是1 4 99 3……,因此每次使用rand()前都要先使用srand()初始化一遍,如果srand()中的参数是固定的话,每次初始化的值也是一样的,即每次调用rand()生成的伪随机数还是一样的,因此需要srand()中的参数不是固定的,这样每次调用rand()时,生成的伪随机数才能不是一样的。刚好,电脑上流动的时间是在变化的,运用时间戳函数time(),能够将每时每刻的时间转换为time_t类型的值,不同时间调用time(),生成的值都不同,因此这个值作为srand()的参数,随着srand()中的参数变化,每次初始化的值也不一样了,rand()生成的伪随机数也不一样了。
time()的头文件是time.h
3.fprintf(fin, “%d\n”, rand()%10000);—>将参数3以%d的类型写进文件指针fin指向的文件。
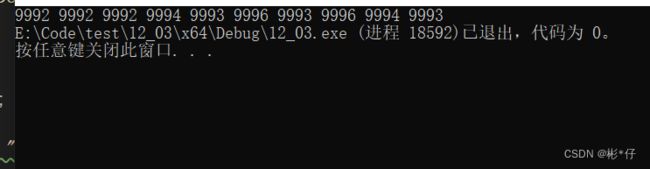
打印结果
上述文本文件是在文件中随机生成的1000个数中截取的一部份,运行结果是这一万个数种最大的前十个数。因为随机生成的数有重复的,因此最大的前十个数也有重复的。
4.如何验证这个程序的正确性?
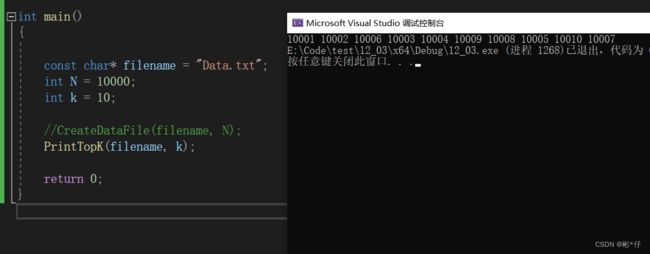
答:首相将随机生成数函数屏蔽,然后在之前已经生成的随机数种中手动加入十个比这一万个数都大的数,如果程序运行后,能把这手动添加的数全部选出来,说明程序无误。现在加入 10001 10002 10003……10010。
int main() { const char* filename = "Data.txt"; int N = 10000; int k = 10; //CreateDataFile(filename, N); PrintTopK(filename, k); return 0; }打印结果
手动加入的十个最大的数全部被挑选出来,说明程序无误。


4、建堆、堆排序、TopK问题全部代码
Heap.h部分:写函数的声明,函数的头文件。
#pragma once
#include Heap.c部分:各自定义函数的实现
#define _CRT_SECURE_NO_WARNINGS 1
#include "Heap.h"
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//向上调整函数
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2; //找到堆最后一个数的父亲的下标
while (child > 0) //孩子的下标等于0时,说明堆从最后一个数一路向上比较,已经到达堆顶了
{
//小根堆,任意孩子的值要大于父节点的值,不是的话则要向上调整
if (a[child] < a[parent]) //改为>,这个堆结构就成为大堆了
{
Swap(&a[child], &a[parent]);
//修正父亲与孩子的下标,通过循环不断比较,直到成为堆的形状
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//向下调整函数
void AdjustDown(HPDataType* a, int n, int parent)
{
int minChild = parent * 2 + 1; //先默认左边的孩子是整个小根堆中次小的孩子
while (minChild < n)
{
//与右孩子比较一下,找出小的那个孩子的下标
if (minChild + 1 < n && a[minChild + 1] < a[minChild])
{
minChild++;
}
//找到次小的孩子后将其与父节点比较
if (a[minChild] < a[parent])
{
Swap(&a[minChild], &a[parent]);
//修正父亲与孩子的下标,通过循环不断比较,直到成为堆的形状
parent = minChild;
minChild = parent * 2 + 1;
}
else
{
break;
}
}
}
//在文件中随机数的生成
void CreateDataFile(const char* filename, int k)
{
assert(filename);
FILE* fin = fopen(filename, "w"); //w--->在test.c这个源文件路径下创建一个test.txt的文件,如果这个文件已经存在,则将
//这个文件里的内容全部销毁,相当于重新创建了这个文件。
if (fin == NULL)
{
perror("fin fail");
return;
}
srand(time(0));
for (int i = 0; i < k; ++i)
{
fprintf(fin, "%d\n", rand() % 10000);
}
fclose(fin);
}
//TopK函数
void PrintTopK(const char* filename, int k)
{
assert(filename);
FILE* fout = fopen(filename, "r"); //r--->在Test,c这个源文件路径下打开一个本身已经存在的叫Data.txt的文件,将这个文件的地址赋值给文件指针
if (fout == NULL)
{
perror("fopen fail");
return;
}
int* minHeap = (int*)malloc(sizeof(int) * k);
if (minHeap == NULL)
{
perror("malloc fail");
return;
}
//如何读取前k个数
for (int i = 0; i < k; ++i)
{
fscanf(fout, "%d", &minHeap[i]);
}
//建堆,将读取的前k个数建成小堆
for (int j = (k - 1 - 1) / 2; j >= 0; --j)
{
AdjustDown(minHeap, k, j);
}
//继续读取N-k个数
int val = 0;
while (fscanf(fout, "%d", &val) != EOF)
{
if (val > minHeap[0])
{
minHeap[0] = val;
AdjustDown(minHeap, k, 0);
}
}
for (int i = 0; i < k; ++i)
{
printf("%d ", minHeap[i]);
}
free(minHeap);
fclose(fout);
}
Test.c部分:主函数放在这,在主函数中调用各自定义函数。在实现各函数时,可以用来测试各函数的功能。
#define _CRT_SECURE_NO_WARNINGS 1
#include "Heap.h"
//向上调整建堆
int main()
{
int a[] = { 15,1,19,25,8,34,65,4,27,7 };
//建堆---向上调整建堆---O(N*LogN)
int n = sizeof(a) / sizeof(a[0]);
for (int i = 1; i < n; ++i)
{
AdjustUp(a, i);
}
for (int i = 0; i < n; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
//向下调整建堆
int main()
{
int a[] = { 15,1,19,25,8,34,65,4,27,7 };
//建堆---向下调整建堆---O(N)
//向下调整建堆要从倒数的第一个非叶子节点开始向下调整,一直调整到根节点位置
int n = sizeof(a) / sizeof(a[0]);
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
for (int i = 0; i < n; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
//堆排序函数
//大思路:选择排序,依次选数,从后往前排
//升序---先建大堆,建堆完毕后,此时最大的数在第一位,把第一个和最后一个的位置进行交换,
// 交换完毕后,把最后一个不看做堆里面的,进行向下调整,选出次大的。后续依次类似处理。
//降序---先建小堆,建堆完毕后,此时最小的数在第一位,把第一个和最后一个的位置进行交换,
//交换完毕后,把最后一个不看做堆里面的,进行向下调整,选出次小的。后续依次类似处理。
void HeapSort(int* a, int n)
{
//建堆---向下调整建堆---O(N)
//向下调整建堆要从倒数的第一个非叶子节点开始向下调整,一直调整到根节点位置
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
//选数
int i = 1;
while (i < n)
{
Swap(&a[0], &a[n - i]); //交换第一个数跟最后一个数
AdjustDown(a, n - i, 0);
++i;
}
}
int main()
{
int a[] = { 15,1,19,25,8,34,65,4,27,7 };
HeapSort(a, sizeof(a) / sizeof(int));
for (size_t i = 0; i < sizeof(a) / sizeof(int); ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
//top k问题 N个数,找出这N个数中最大的前k个数
int main()
{
const char* filename = "Data.txt";
int k = 3;
PrintTopK(filename, k);
return 0;
}
//在文件中随机生成10000个数,然后找出其中前十个最大数。
int main()
{
const char* filename = "Data.txt";
int N = 10000;
int k = 10;
CreateDataFile(filename, N);
PrintTopK(filename, k);
return 0;
}