Kafka系列之:一次性传送和事务消息传递
Kafka系列之:一次性传送和事务消息传递
- 一、目标
- 二、关于事务和流的一些知识
- 三、公共接口
- 四、示例应用程序
- 五、新配置
- 六、计划变更
-
- 1.幂等生产者保证
- 2.事务保证
- 七、关键概念
- 八、数据流
- 九、授权
- 十、RPC 协议总结
-
- 1.获取请求/响应
- 2.生产请求/响应
- 3.ListOffset请求/响应
- 4.FindCoordinator请求/响应
- 5.InitPid请求/响应
- 6.AddPartitionsToTxn请求/响应
- 7.AddOffsetsToTxnRequest
- 8.EndTxn请求/响应
- 9.WriteTxnMarkersRequest/Response
- 10.TxnOffsetCommit请求/响应
- 十一、消息格式
- 十二、消息集字段
- 十三、消息字段
- 十四、控制消息
- 十五、空间比较
- 十六、指标
- 十七、兼容性、弃用和迁移计划
一、目标
- 本文档概述了加强 Kafka 消息传递语义的提案。
- Kafka 目前至少提供一次语义,即。当进行可靠性调整时,可以保证用户每条消息写入都将至少保留一次,而不会丢失数据。由于生产者重试,流中可能会出现重复。例如,代理可能会在提交消息和向生产者发送确认之间崩溃,导致生产者重试,从而导致流中出现重复消息。
- 消息传递系统的用户极大地受益于更严格的幂等生产者语义,即。每条消息写入都将被保留一次,不会重复,也不会丢失数据——即使在客户端重试或代理失败的情况下也是如此。这些更强的语义不仅使编写应用程序变得更容易,而且还扩展了可以使用给定消息传递系统的应用程序的空间。
- 然而,幂等生产者不为跨多个 TopicPartition 的写入提供保证。为此,需要更强的交易保证,即。以原子方式写入多个 TopicPartition 的能力。我们所说的原子性是指将一组消息作为一个单元跨 TopicPartition 提交的能力:要么所有消息都提交,要么都不提交。
- 流处理应用程序是“消费-转换-生产”任务的管道,当流的重复处理不可接受时,绝对需要事务保证。因此,向 Kafka(一个流平台)添加事务保证不仅使其对于流处理而且对于各种其他应用程序都更加有用。
- 在本文档中,我们提出了将事务引入 Kafka 的提案。我们将只关注用户面临的变化:客户端 API 变化、我们将引入的新配置以及保证摘要。我们还概述了基本数据流,其中总结了我们将通过事务引入的所有新 RPC。
二、关于事务和流的一些知识
- 我们提到事务的主要动机是在 Kafka Streams 中实现一次处理。值得进一步深入研究这个用例,因为它激发了我们设计中的许多权衡。
- 回想一下,使用 Kafka Streams 的数据转换通常通过多个流处理器进行,每个流处理器都通过 Kafka 主题连接。这种设置称为流拓扑,基本上是一个 DAG,其中流处理器是节点,连接的 Kafka 主题是顶点。这种模式是所有流式架构的典型模式。
- 因此,Kafka 流的事务本质上包含输入消息、本地状态存储的更新以及输出消息。在事务中包含输入偏移量会促使将“sendOffsets”API 添加到 Producer 接口,如下所述。
- 此外,流拓扑可以变得相当深——10级并不罕见。如果输出消息仅在事务提交时具体化,则 N 级深的拓扑将需要 N x T 来处理其输入,其中 T 是单个事务的平均时间。因此,Kafka Streams 需要推测执行,其中输出消息甚至可以在提交之前被下游处理器读取。否则,事务将不会成为重要的流应用程序的选择。这激发了稍后描述的“未提交读”消费者模式。
- 这是我们选择针对流用例进行优化的两个特定实例。当读者阅读本文档时,我们鼓励她牢记这个用例,因为它激发了提案的大部分内容。
三、公共接口
生产者 API 变更
生产者将获得五个新方法(initTransactions、beginTransaction、sendOffsets、commitTransaction、abortTransaction),并且更新了 send 方法以抛出新的异常。详细说明如下:
KafkaProducer.java
public interface Producer<K,V> extends Closeable {
/**
* Needs to be called before any of the other transaction methods. Assumes that
* the transactional.id is specified in the producer configuration.
*
* This method does the following:
* 1. Ensures any transactions initiated by previous instances of the producer
* are completed. If the previous instance had failed with a transaction in
* progress, it will be aborted. If the last transaction had begun completion,
* but not yet finished, this method awaits its completion.
* 2. Gets the internal producer id and epoch, used in all future transactional
* messages issued by the producer.
*
* @throws IllegalStateException if the TransactionalId for the producer is not set
* in the configuration.
*/
void initTransactions() throws IllegalStateException;
/**
* Should be called before the start of each new transaction.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void beginTransaction() throws ProducerFencedException;
/**
* Sends a list of consumed offsets to the consumer group coordinator, and also marks
* those offsets as part of the current transaction. These offsets will be considered
* consumed only if the transaction is committed successfully.
*
* This method should be used when you need to batch consumed and produced messages
* together, typically in a consume-transform-produce pattern.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException;
/**
* Commits the ongoing transaction.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void commitTransaction() throws ProducerFencedException;
/**
* Aborts the ongoing transaction.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void abortTransaction() throws ProducerFencedException;
/**
* Send the given record asynchronously and return a future which will eventually contain the response information.
*
* @param record The record to send
* @return A future which will eventually contain the response information
*
*/
public Future<RecordMetadata> send(ProducerRecord<K, V> record);
/**
* Send a record and invoke the given callback when the record has been acknowledged by the server
*/
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
}
OutOfOrderSequence 异常
如果代理检测到数据丢失,生产者将引发 OutOfOrderSequenceException。换句话说,如果它收到的序列号大于它预期的序列号。该异常将在将来返回并传递给回调(如果有)。这是一个致命异常,以后调用 Producer 方法(如 send、beginTransaction、commitTransaction 等)将引发 IlegalStateException。
四、示例应用程序
这是一个简单的应用程序,演示了上面介绍的 API 的用法。
KafkaTransactionsExample.java
public class KafkaTransactionsExample {
public static void main(String args[]) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfig);
// Note that the ‘transactional.id’ configuration _must_ be specified in the
// producer config in order to use transactions.
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
// We need to initialize transactions once per producer instance. To use transactions,
// it is assumed that the application id is specified in the config with the key
// transactional.id.
//
// This method will recover or abort transactions initiated by previous instances of a
// producer with the same app id. Any other transactional messages will report an error
// if initialization was not performed.
//
// The response indicates success or failure. Some failures are irrecoverable and will
// require a new producer instance. See the documentation for TransactionMetadata for a
// list of error codes.
producer.initTransactions();
while(true) {
ConsumerRecords<String, String> records = consumer.poll(CONSUMER_POLL_TIMEOUT);
if (!records.isEmpty()) {
// Start a new transaction. This will begin the process of batching the consumed
// records as well
// as an records produced as a result of processing the input records.
//
// We need to check the response to make sure that this producer is able to initiate
// a new transaction.
producer.beginTransaction();
// Process the input records and send them to the output topic(s).
List<ProducerRecord<String, String>> outputRecords = processRecords(records);
for (ProducerRecord<String, String> outputRecord : outputRecords) {
producer.send(outputRecord);
}
// To ensure that the consumed and produced messages are batched, we need to commit
// the offsets through
// the producer and not the consumer.
//
// If this returns an error, we should abort the transaction.
sendOffsetsResult = producer.sendOffsetsToTransaction(getUncommittedOffsets());
// Now that we have consumed, processed, and produced a batch of messages, let's
// commit the results.
// If this does not report success, then the transaction will be rolled back.
producer.commitTransaction();
}
}
}
}
五、新配置
Broker配置
| 参数 | 描述 |
|---|---|
| transactional.id.timeout.ms | 事务协调器在主动使生产者 TransactionalId 过期而不从其接收任何事务状态更新之前等待的最长时间(以毫秒为单位)。默认值为 604800000(7 天)。这允许每周定期的生产者作业维护其 ID。 |
| max.transaction.timeout.ms | 事务允许的最大超时时间。如果客户端请求的交易时间超过此时间,则代理将在 InitPidRequest 中返回 InvalidTransactionTimeout 错误。这可以防止客户端超时过大,从而导致消费者无法读取事务中包含的主题。默认值为 900000(15 分钟)。这是需要发送消息事务的时间段的保守上限。 |
| transaction.state.log.replication.factor | 事务状态主题的副本数。默认值:3 |
| transaction.state.log.num.partitions | 事务状态主题的分区数。默认值:50 |
| transaction.state.log.min.isr | 必须在线考虑事务状态主题的每个分区的最小同步副本数。默认值:2 |
| transaction.state.log.segment.bytes | 事务状态主题的段大小。默认值:104857600 字节。 |
Producer配置
| 参数 | 描述 |
|---|---|
| enable.idempotence | 是否启用幂等性(默认为 false)。如果禁用,生产者将不会在生产请求中设置 PID 字段,并且当前生产者交付语义将生效。请注意,必须启用幂等性才能使用事务。启用幂等性时,我们强制 acks=all、重试次数 > 1 和 max.inflight.requests.per.connection=1。如果没有这些配置的这些值,我们就无法保证幂等性。如果应用程序没有显式覆盖这些设置,则在启用幂等性时,生产者将设置 acks=all、retries=Integer.MAX_VALUE 和 max.inflight.requests.per.connection=1。 |
| transaction.timeout.ms | 事务协调器在主动中止正在进行的事务之前等待来自生产者的事务状态更新的最长时间(以毫秒为单位)。该配置值将与 InitPidRequest 一起发送到事务协调器。如果该值大于代理中的 max.transaction.timeout.ms 设置,则请求将失败并出现“InvalidTransactionTimeout”错误。默认值为 60000。这使得交易不会阻塞下游消费超过一分钟,这在实时应用程序中通常是允许的。 |
| transactional.id | 用于事务交付的 TransactionalId。这使得跨多个生产者会话的可靠性语义成为可能,因为它允许客户端保证使用相同 TransactionalId 的事务在开始任何新事务之前已完成。如果未提供 TransactionalId,则生产者仅限于幂等传递。请注意,如果配置了 TransactionalId,则必须启用enable.idempotence。默认为空,即不能使用交易。 |
消费者配置
| 参数 | 描述 |
|---|---|
| isolation.level | 以下是可能的值(默认值为 read_uncommissed):read_uncommissed:按偏移量顺序消耗已提交和未提交的消息。read_commissed:仅按偏移量顺序消费非事务性消息或已提交的事务性消息。为了维持偏移排序,此设置意味着我们必须在消费者中缓冲消息,直到我们看到给定事务中的所有消息。 |
六、计划变更
1.幂等生产者保证
为了实现幂等生产者语义,我们引入了生产者 ID(以下称为 PID)和 Kafka 消息的序列号的概念。每个新的生产者在初始化期间都会被分配一个唯一的PID。 PID 分配对用户完全透明,并且永远不会被客户端公开。
对于给定的 PID,序列号将从零开始并单调递增,每个主题分区生成一个序列号。生产者将在发送到代理的每条消息上递增序列号。代理在内存中维护从每个 PID 接收到的每个主题分区的序列号。如果生产请求的序列号不正好比该 PID/TopicPartition 对中最后提交的消息大 1,则代理将拒绝生产请求。序列号较低的消息会导致重复错误,生产者可以忽略该错误。编号较高的消息会导致乱序错误,这表明某些消息已丢失,并且是致命的。
这确保了即使生产者必须在失败时重试请求,每条消息也将在日志中保留一次。此外,由于生产者的每个新实例都被分配了一个新的、唯一的 PID,因此我们只能保证单个生产者会话内的幂等生产。
这些幂等生产者语义对于指标跟踪和审计等无状态应用程序可能有用。
2.事务保证
从本质上讲,事务保证使应用程序能够原子地生成多个 TopicPartition,即。对这些 TopicPartition 的所有写入都将作为一个单元成功或失败。
此外,由于消费者进度被记录为对偏移量主题的写入,因此利用上述功能使应用程序能够将消费和生成的消息批量处理到单个原子单元中,即。仅当整个“消费-转换-生产”全部执行时,一组消息才可以被视为已消费。
此外,有状态应用程序还能够确保应用程序多个会话的连续性。换句话说,Kafka可以保证跨应用程序反弹的幂等生产和事务恢复。
为了实现这一点,我们要求应用程序提供一个在应用程序的所有会话中保持稳定的唯一 ID。在本文档的其余部分中,我们将此类 id 称为 TransactionalId。虽然 TransactionalId 和内部 PID 之间可能存在 1-1 映射,但主要区别在于 TransactionalId 是由用户提供的,并且是在下面描述的跨生产者会话之间启用幂等保证的原因。
当提供这样的 TransactionalId 时,Kafka 将保证:
- 具有给定 TransactionalId 的恰好一个活跃生产者。这是通过当具有相同 TransactionalId 的新实例上线时隔离旧代来实现的。
- 跨应用程序会话的事务恢复。如果一个应用程序实例终止,则可以保证下一个实例已完成所有未完成的事务(无论是中止还是提交),从而在恢复工作之前使新实例处于干净状态。
请注意,这里提到的交易保证是从生产者的角度来看的。在消费者方面,保障稍弱一些。特别是,我们不能保证已提交事务的所有消息都会被一起消耗。这是出于以下几个原因:
- 对于压缩主题,事务的某些消息可能会被新版本覆盖。
- 事务可能跨越日志段。因此,当删除旧段时,我们可能会丢失事务第一部分中的一些消息。
- 消费者可能会寻求交易中的任意点,从而错过一些初始消息。
- 消费者可能不会从参与事务的所有分区中进行消费。因此,他们将永远无法读取构成交易的所有消息。
七、关键概念
实现事务,即。确保以原子方式生成和消费一组消息,我们引入了几个新概念:
- 我们引入一个称为事务协调器的新实体。与消费者组协调器类似,每个生产者都分配有一个事务协调器,所有分配PID和管理事务的逻辑都由事务协调器完成。
- 我们引入了一个新的内部 kafka 主题,称为事务日志。与消费者偏移主题类似,事务日志是每个事务的持久且复制的记录。事务日志是事务协调器的状态存储,最新版本日志的快照封装了每个活动事务的当前状态。
- 我们引入控制消息的概念。这些是写入用户主题的特殊消息,由客户端处理,但从未暴露给用户。例如,它们用于让代理向消费者指示先前获取的消息是否已原子提交。控制消息之前已经在这里提出过。
- 我们引入了 TransactionalId 的概念,使用户能够以持久的方式唯一地标识生产者。具有相同 TransactionalId 的生产者的不同实例将能够恢复(或中止)前一个实例实例化的任何事务。
- 我们引入了生产者纪元的概念,这使我们能够确保只有一个具有给定 TransactionalId 的生产者的合法活动实例,从而使我们能够在发生故障时维持事务保证。
除了上述新概念之外,我们还引入了新的请求类型、现有请求的新版本以及核心消息格式的新版本,以支持事务。所有这些细节将推迟到其他文件。
八、数据流

在上图中,锋利的边缘框代表不同的机器。底部的圆形框代表 Kafka TopicPartition,对角圆形框代表在代理内部运行的逻辑实体。
每个箭头代表一个 RPC,或对 Kafka 主题的写入。这些操作按照每个箭头旁边的数字指示的顺序发生。以下部分的编号与上图中的操作相匹配,并描述了相关操作。
-
查找事务协调器——FindCoordinatorRequest
由于事务协调器处于分配 PID 和管理事务的中心,因此生产者要做的第一件事就是向任何代理发出 FindCoordinatorRequest(以前称为 GroupCoordinatorRequest,但为了更通用的用途而重命名)以发现其协调器的位置。 -
获取生产者Id——InitPidRequest
发现协调器的位置后,下一步是检索生产者的 PID。这是通过向事务协调器发出 InitPidRequest 来实现的
2.1 当指定TransactionalId时
如果设置了 transactional.id 配置,则此 TransactionalId 与 InitPidRequest 一起传递,并且到相应 PID 的映射将记录在步骤 2a 中的事务日志中。这使我们能够将 TransactionalId 的相同 PID 返回给生产者的未来实例,从而能够恢复或中止以前不完整的事务。
除了返回 PID 之外,InitPidRequest 还执行以下任务:
- 提高 PID 的纪元,以便生产者的任何先前的僵尸实例都被隔离并且无法继续其事务。
- 恢复(前滚或回滚)生产者的前一个实例留下的任何未完成的事务。
InitPidRequest 的处理是同步的。一旦返回,生产者就可以发送数据并开始新的交易。
2.2 未指定TransactionalId时
如果配置中未指定 TransactionalId,则会分配新的 PID,并且生产者仅在单个会话中享有幂等语义和事务语义。
-
启动事务 – beginTransaction() API
新的 KafkaProducer 将有一个 beginTransaction() 方法,必须调用该方法来发出新事务开始的信号。生产者记录本地状态,表明事务已经开始,但从协调者的角度来看,事务在发送第一个记录之前不会开始。 -
消费-转换-生产循环
在此阶段,生产者开始消费、转换、生产构成交易的消息。这是一个漫长的阶段,可能由多个请求组成。
4.1 添加分区到Txn请求
第一次将新的 TopicPartition 作为事务的一部分写入时,生产者会将此请求发送到事务协调器。协调器在步骤 4.1a 中记录将此 TopicPartition 添加到事务中的情况。我们需要这些信息,以便我们可以将提交或中止标记写入每个 TopicPartition(有关详细信息,请参阅第 5.2 节)。如果这是添加到事务中的第一个分区,协调器还将启动事务计时器。
4.2 生产请求
生产者通过一个或多个 ProduceRequest(从生产者的 send 方法触发)将一堆消息写入用户的 TopicPartition。这些请求包括 PID、纪元和序列号,如 4.2a 中所示。
4.3 添加OffsetCommitsToTxnRequest
生产者有一个新的 KafkaProducer.sendOffsetsToTransaction API 方法,可以批量消费和生产消息。此方法采用 Map
sendOffsetsToTransaction 方法将带有 groupId 的 AddOffsetCommitsToTxnRequests 发送到事务协调器,从中可以推断出内部 __consumer-offsets 主题中该消费者组的 TopicPartition。事务协调器在步骤 4.3a 中将此主题分区的添加记录到事务日志中。
4.4 TxnOffsetCommit请求
同样作为 sendOffsets 的一部分,生产者将向消费者协调器发送 TxnOffsetCommitRequest,以将偏移量保留在 __consumer-offsets 主题中(步骤 4.4a)。消费者协调器通过使用作为此请求的一部分发送的 PID 和生产者纪元来验证生产者是否被允许发出此请求(并且不是僵尸)。
在提交事务之前,消耗的偏移量在外部不可见,我们现在将讨论该过程。
- 提交或中止交易
数据写入后,用户必须调用 KafkaProducer 的新 commitTransaction 或 abortTransaction 方法。这些方法将分别开始提交或中止事务的过程。
5.1 结束Txn请求
当生产者完成事务时,必须调用新引入的 KafkaProducer.commitTransaction 或 KafkaProducer.abortTransaction。前者将4中产生的数据提供给下游消费者。后者有效地从日志中删除生成的数据:用户永远无法访问它,即。下游消费者将读取并丢弃中止的消息。
无论调用哪个生产者方法,生产者都会向事务协调器发出 EndTxnRequest,并附加指示事务是要提交还是中止的数据。收到此请求后,协调员:
- 将 PREPARE_COMMIT 或 PREPARE_ABORT 消息写入事务日志。 (步骤 5.1a)
- 开始通过 WriteTxnMarkerRequest 将称为 COMMIT(或 ABORT)标记的命令消息写入用户日志的过程。 (参见下文第 5.2 节)。
- 最后将 COMMITTED(或 ABORTED)消息写入事务日志。 (见下文 5.3)。
5.2 写入TxnMarkerRequest
该请求由事务协调器向作为事务一部分的每个 TopicPartition 的领导者发出。收到此请求后,每个代理都会将 COMMIT(PID) 或 ABORT(PID) 控制消息写入日志。 (步骤 5.2a)
此消息向消费者指示是否必须将具有给定 PID 的消息传递给用户或丢弃。因此,消费者将缓冲具有 PID 的消息,直到它读取相应的 COMMIT 或 ABORT 消息,此时它将分别传递或删除消息。
请注意,如果 __consumer-offsets 主题是事务中的 TopicPartition 之一,则提交(或中止)标记也会写入日志,并且通知消费者协调器在以下情况下需要具体化这些偏移量:在中止的情况下提交或忽略它们(左侧步骤 5.2a)。
5.3 编写最终的提交或中止消息
当所有提交或中止标记写入数据日志后,事务协调器将最终的 COMMITTED 或 ABORTED 消息写入事务日志,表明事务已完成(图中的步骤 5.3)。此时,事务日志中与该事务相关的大部分消息都可以被删除。
我们只需要保留已完成交易的 PID 和时间戳,因此我们最终可以删除生产者的 TransactionalId->PID 映射。请参阅下面的“PID 过期”部分。
九、授权
最好控制对事务日志的访问,以确保客户端不会有意或无意地干扰彼此的事务。在这项工作中,我们引入了一种新的资源类型来表示与事务生产者相关的 TransactionalId,以及授权失败的关联错误代码。
case object ProducerTransactionalId extends ResourceType {
val name = "ProducerTransactionalId"
val errorCode = Errors.TRANSACTIONAL_ID_AUTHORIZATION_FAILED.code
}
事务协调器处理以下每个请求:InitPid、AddPartitionsToTxn、AddOffsetsToTxn 和 EndTxn。对事务协调器的每个请求都包含生产者的 TransactionalId,可用于授权。每个请求都会改变生产者的事务状态,因此它们都需要对相应的 ProducerTransactionalId 资源进行写入访问。此外,AddPartitionsToTxn API 需要对与所包含分区相对应的主题具有写入权限,而 AddOffsetsToTxn API 需要对请求中包含的组具有读取权限。
我们还需要额外的授权才能生成交易数据。这可以用来最大限度地降低“无休止交易攻击”的风险,在这种攻击中,恶意生产者在没有相应 COMMIT 或 ABORT 标记的情况下写入交易数据,以阻止 LSO 前进和消费者取得进展。我们可以使用上面介绍的 ProducerTransactionalId 资源来确保生产者有权写入事务数据,因为生产者的 TransactionalId 包含在 ProduceRequest 架构中。 WriteTxnMarker API 仅供代理间使用,因此需要集群资源上的 ClusterAction 权限。请注意,不允许通过 Produce API 写入控制消息。
不允许客户端使用 Produce API 直接写入事务日志,尽管出于调试目的让具有读取权限的消费者可以访问事务日志非常有用。
协调员授权限制的讨论
虽然我们可以使用TransactionalId控制对事务日志的访问,但我们无法阻止恶意生产者劫持另一个生产者的PID并将数据写入日志。这将允许攻击者将不良数据插入到活动交易中,或者通过强制纪元碰撞来隔离授权生产者。然而,恶意生产者不可能完成交易,因为代理不允许客户端写入控制消息。另请注意,恶意生产者必须对合法生产者使用的同一组主题拥有写入权限,因此仍然可以结合使用主题 ACL 和 TransactionalId ACL 来保护敏感主题。未来的工作可以探索保护 TransactionalId 和 PID 之间的绑定(例如通过使用消息身份验证代码)。
十、RPC 协议总结
我们在本节中总结了所有新的请求/响应对以及修改后的请求。
1.获取请求/响应
由消费者发送给任何分区领导者以获取消息。我们提高了 API 版本以允许使用者指定所需的隔离级别。我们还修改响应模式以包含已获取消息范围内的已中止事务列表。
FetchRequest
// FetchRequest v4
FetchRequest => ReplicaId MaxWaitTime MinBytes IsolationLevel [TopicName [Partition FetchOffset MaxBytes]]
ReplicaId => int32
MaxWaitTime => int32
MinBytes => int32
IsolationLevel => int8 (READ_COMMITTED | READ_UNCOMMITTED)
TopicName => string
Partition => int32
FetchOffset => int64
MaxBytes => int32
FetchResponse
// FetchResponse v4
FetchResponse => ThrottleTime [TopicName [Partition ErrorCode HighwaterMarkOffset LastStableOffset AbortedTransactions MessageSetSize MessageSet]]
ThrottleTime => int32
TopicName => string
Partition => int32
ErrorCode => int16
HighwaterMarkOffset => int64
LastStableOffset => int64
AbortedTransactions => [PID FirstOffset]
PID => int64
FirstOffset => int64
MessageSetSize => int32
当消费者发送对旧版本的请求时,代理采用 READ_UNCOMMITTED 隔离级别,并在发回响应之前将消息集转换为适当的格式。因此不能使用零拷贝。当启用压缩时,这种转换的成本可能会很高,因此尽快更新客户端非常重要。
我们还将 LSO 添加到获取响应中。在 READ_COMMMITED 中,消费者将使用它来计算延迟而不是高水位线。另请注意添加了中止事务字段。 READ_COMMITTED 模式下的消费者使用它来了解中止的事务从哪里开始。这允许消费者丢弃中止的事务数据而不进行缓冲,直到读取关联的标记为止。
2.生产请求/响应
由生产者发送给任何代理以生成消息。我们修改架构以允许每个分区仅发送一个消息集,而不是允许协议为每个分区发送多个消息集。这允许我们删除消息集大小,因为每个消息集已经包含一个大小字段。更重要的是,由于只有一条消息集要写入日志,因此不再可能出现部分生产失败。完整的消息集要么成功写入日志(并复制),要么未成功写入日志。
我们包含 TransactionalId 是为了确保使用事务性消息的生产者(即在属性中设置了事务位的生产者)有权这样做。如果客户端不使用事务,则该字段应为空。
ProduceRequest
// ProduceRequest v3
ProduceRequest => TransactionalId
RequiredAcks
Timeout
[TopicName [Partition MessageSetSize MessageSet]]
TransactionalId => nullableString
RequiredAcks => int16
Timeout => int32
Partition => int32
MessageSetSize => int32
MessageSet => bytes
ProduceResponse
// ProduceResponse v3
ProduceResponse => [TopicName [Partition ErrorCode Offset Timestamp]]
ThrottleTime
TopicName => string
Partition => int32
ErrorCode => int16
Offset => int64
Timestamp => int64
ThrottleTime => int32
错误代码:
- 重复序列号 [新]
- 无效序列号 [新]
- 无效的ProducerEpoch [新]
- UNSUPPORTED_FOR_MESSAGE_FORMAT
请注意,发送版本 3 的生产请求的客户端必须使用新的消息集格式。写入日志时,代理仍可能将消息向下转换为较旧的格式,具体取决于指定的内部消息格式。
3.ListOffset请求/响应
由客户端发送,用于按时间戳搜索偏移量并查找分区的第一个和最后一个偏移量。在此提案中,我们修改此请求以支持检索最后一个稳定偏移量,这是消费者在 READ_COMMITTED 模式下实现eekToEnd() 所需要的。
ListOffsetRequest
// ListOffsetRequestV2
ListOffsetRequest => ReplicaId [TopicName [Partition Time]]
ReplicaId => int32
TopicName => string
Partition => int32
Time => int64
ListOffsetResponse
ListOffsetResponse => [TopicName [PartitionOffsets]]
PartitionOffsets => Partition ErrorCode Timestamp [Offset]
Partition => int32
ErrorCode => int16
Timestamp => int64
Offset => int64
该架构与版本 1 完全相同,但我们现在支持在请求 (-3) 中使用新的哨兵时间戳来检索 LSO。
4.FindCoordinator请求/响应
由客户端发送给任何经纪人以查找相应的协调员。这与之前用于查找组协调器的 API 相同,但我们更改了名称以反映更一般的用法(没有用于事务性生产者的组)。我们提高了请求的版本,并添加了一个新字段来指示组类型,可以是 Consumer 或 Txn。请求处理详细信息可以在此处找到。
FindCoordinatorRequest
// v2
FindCoordinatorRequest => TransactionalId CoordinatorType
TransactionalId => string
CoordinatorType => byte /* 0: consumer, 1: transaction */
FindCoordinatorResponse
FindCoordinatorResponse => ErrorCode Coordinator
ErrorCode => int16
Coordinator => NodeId Host Port
NodeId => int32
Host => string
Port => int32
错误代码:
- 好的
- 协调员不可用
节点 ID 是代理的标识符。我们使用协调器 ID 来标识与相应代理的连接。
5.InitPid请求/响应
由生产者发送到其事务协调器,以获取分配的 PID、增加其纪元,并隔离任何共享相同 TransactionalId 的先前生产者。请求处理详细信息可以在此处找到。
InitPidRequest
InitPidRequest => TransactionalId TransactionTimeoutMs
TransactionalId => String
TransactionTimeoutMs => int32
InitPidResponse
InitPIDResponse => Error PID Epoch
Error => Int16
PID => Int64
Epoch => Int16
错误代码:
- 好的
- NotCoordinatorForTransactionalId
- 协调员不可用
- 并发交易
- 无效交易超时
6.AddPartitionsToTxn请求/响应
由生产者发送到其事务协调器,以将分区添加到当前正在进行的事务中。请求处理详细信息可以在此处找到。
AddPartitionsToTxnRequest
AddPartitionsToTxnRequest => TransactionalId PID Epoch [Topic [Partition]]
TransactionalId => string
PID => int64
Epoch => int16
Topic => string
Partition => int32
AddPartitionsToTxnResponse
AddPartitionsToTxnResponse => ErrorCode
ErrorCode: int16
错误代码:
- 好的
- 非协调者
- 协调员不可用
- 协调器加载进行中
- 无效的Pid映射
- 无效的Txn状态
- 并发交易
- 群组授权失败
7.AddOffsetsToTxnRequest
由生产者发送到其事务协调器,以指示消费者偏移提交操作被调用作为当前正在进行的事务的一部分。请求处理详细信息可以在此处找到。
AddOffsetsToTxnRequest
AddOffsetsToTxnRequest => TransactionalId PID Epoch ConsumerGroupID
TransactionalId => string
PID => int64
Epoch => int16
ConsumerGroupID => string
AddOffsetsToTxnResponse
AddOffsetsToTxnResponse => ErrorCode
ErrorCode: int16
错误代码:
- 好的
- 无效的ProducerEpoch
- 无效的Pid映射
- NotCoordinatorForTransactionalId
- 协调员不可用
- 并发交易
- 无效的Txn请求
8.EndTxn请求/响应
由生产者发送给其事务协调器以准备提交或中止当前正在进行的事务。请求处理详细信息可以在此处找到。
EndTxnRequest
EndTxnRequest => TransactionalId PID Epoch Command
TransactionalId => string
PID => int64
Epoch => int16
Command => boolean (false(0) means ABORT, true(1) means COMMIT)
EndTxnResponse
EndTxnResponse => ErrorCode
ErrorCode => int16
错误代码:
- 好的
- 无效的ProducerEpoch
- 无效的Pid映射
- 协调员不可用
- 并发交易
- NotCoordinatorForTransactionalId
- 无效的Txn请求
9.WriteTxnMarkersRequest/Response
由事务协调器发送给代理以提交事务。请求处理详细信息可以在此处找到。
WriteTxnMarkersRequest
WriteTxnMarkersRequest => [CoorinadorEpoch PID Epoch Marker [Topic [Partition]]]
CoordinatorEpoch => int32
PID => int64
Epoch => int16
Marker => boolean (false(0) means ABORT, true(1) means COMMIT)
Topic => string
Partition => int32
WriteTxnMarkersResponse
WriteTxnMarkersResponse => [PID [TopicName [Partition ErrorCode]]]
PID => int64
TopicName => string
Partition => int32
ErrorCode => int16
Error code:
- Ok
10.TxnOffsetCommit请求/响应
由事务生产者发送给消费者组协调员以在单个事务中提交偏移量。请求处理详细信息可以在此处找到。
请注意,就像消费者一样,用户不会明确设置保留时间,并且将始终使用默认值(-1),这让代理可以确定其保留时间。
TxnOffsetCommitRequest
TxnOffsetCommitRequest => ConsumerGroupID
PID
Epoch
RetentionTime
OffsetAndMetadata
ConsumerGroupID => string
PID => int64
Epoch => int16
RetentionTime => int64
OffsetAndMetadata => [TopicName [Partition Offset Metadata]]
TopicName => string
Partition => int32
Offset => int64
Metadata => string
TxnOffsetCommitResponse
TxnOffsetCommitResponse => [TopicName [Partition ErrorCode]]]
TopicName => string
Partition => int32
ErrorCode => int16
错误代码:
- 无效的ProducerEpoch
注意:以下内容与 TxnOffsetCommitRequest/Response 无关:当来自使用者的 OffsetCommitRequest 由于可重试错误而失败时,我们将 RetriableOffsetCommitException 返回到应用程序回调。以前,此“RetriableOffsetCommitException”将包含基础异常。随着 KIP-98 中的更改,我们不再将底层异常包含在“RetriableOffsetCommitException”中。
十一、消息格式
为了将 PID 和 epoch 等新字段添加到生成的消息中以进行事务消息传递和重复数据删除,我们需要更改 Kafka 的消息格式并提高其版本(即“魔字节”)。更具体地说,我们需要将以下字段添加到每条消息中:
- PID => int64
- 纪元 => int16
- 序列号 => int32
在消息级格式模式上添加这些字段可能会增加大量开销;另一方面,至少 PID 和纪元在来自给定生产者的一组消息中永远不会改变。因此,我们建议通过为消息集提供与单个消息不同的模式来增强消息集的当前概念。通过这种方式,我们可以仅在消息集级别定位这些字段,这使得额外的开销可以在多批消息之间分摊,而不是单独为每条消息支付成本。
一旦达到 int16_max 和 int32_max,纪元和序列号都会回绕。由于纪元和序列号都有单点分配和验证,因此包装这些值不会破坏幂等或事务语义。
作为参考,当前的消息格式(v1)如下:
MessageSet => [Offset MessageSize Message]
Offset => int64
MessageSize => int32
Message => Crc Magic Attributes Timestamp Key Value
Crc => int32
Magic => int8
Attributes => int8
Timestamp => int64
Key => bytes
Value => bytes
消息集是消息序列。为了支持压缩,我们目前使用这种格式,允许将消息集的压缩输出嵌入到另一个消息(也称为“包装消息”)的值字段中。在此设计中,我们建议将此概念扩展到非压缩消息,并解耦消息包装器(包含压缩消息集)的架构。这使我们能够在消息集级别维护一组单独的字段,并避免一些代价高昂的冗余:
MessageSet =>
FirstOffset => int64
Length => int32
PartitionLeaderEpoch => int32 /* Added for KIP-101 */
Magic => int8 /* bump up to “2” */
CRC => int32 /* CRC32C which covers everything from Attributes on */
Attributes => int16
LastOffsetDelta => int32 {NEW}
FirstTimestamp => int64 {NEW}
MaxTimestamp => int64 {NEW}
PID => int64 {NEW}
ProducerEpoch => int16 {NEW}
FirstSequence => int32 {NEW}
Messages => [Message]
Message => {ALL FIELDS NEW}
Length => varint
Attributes => int8
TimestampDelta => varint
OffsetDelta => varint
KeyLen => varint
Key => data
ValueLen => varint
Value => data
Headers => [Header] /* See KIP-82. Note the array uses a varint for the number of headers. */
Header => HeaderKey HeaderVal
HeaderKeyLen => varint
HeaderKey => string
HeaderValueLen => varint
HeaderValue => data
仅在消息集级别存储某些字段的能力使我们能够在将消息批处理到消息集中时显着节省空间。例如,无需在每个消息中写入 PID,因为每个消息集中的所有消息的 PID 始终相同。此外,通过分离消息级别格式和消息集格式,现在我们还可以对内部(相对)偏移量使用可变长度类型,并在固定的 8 字节字段大小上节省大量空间。
十二、消息集字段
此格式中消息集的前四个字段必须与现有格式相同,因为魔字节之前的任何字段都无法更改,以便提供遵循 KIP-32 中使用的类似方法的升级路径。请求旧版本格式的客户将需要在经纪商上进行转换。
消息集标头中提供的偏移量表示集合中第一条消息的偏移量。同样,我们的序列号字段表示第一条消息的序列号。我们还在消息集级别包含“偏移量增量”,以提供一种简单的方法来计算集合中的最后一个偏移量/序列号:即下一个消息集的起始偏移量应该是“偏移量+偏移量增量”。这也使我们能够搜索与特定偏移量相对应的消息集,而无需扫描各个消息,这些消息可能会或可能不会被压缩。类似地,我们可以使用它来轻松计算下一个期望的序列号。
消息集的偏移量、序列号和偏移量增量值在消息集创建后永远不会改变。日志清理器可以从消息集中删除单个消息,并且一旦删除所有消息,它也可以删除消息集本身,但是我们必须保留消息集中曾经使用过的序列号范围,因为我们依赖于此确定每个 PID 预期的下一个序列号。
消息集属性:消息集属性本质上与现有格式相同,尽管我们添加了一个额外的字节以供将来使用。除了现有的 3 位用于指示压缩编解码器和 1 位用于时间戳类型之外,我们将使用另一位来指示消息集是事务性的(请参阅事务标记部分)。这让 READ_COMMITTED 中的使用者知道给定消息集是否需要事务标记。
控制标志指示消息集中包含的消息不适合应用程序使用(见下文)。

关于最大消息大小的讨论。代理的配置 max.message.size 之前控制单个未压缩消息或一组压缩消息的最大大小。通过这种设计,它现在可以控制最大消息集大小(压缩与否)。实际上,差异很小,因为单个消息可以编写为单例消息集,上面提到的开销增加很小。
十三、消息字段
消息格式的长度字段被编码为有符号的可变长度整数。类似地,偏移量增量和密钥长度字段也被编码为unitVar。然后,消息的偏移量可以计算为消息集的偏移量 + 偏移量增量。
消息属性:在此格式中,我们还为各个消息属性添加了一个字节。只有消息集可以被压缩,因此不需要为压缩类型保留其中一些属性。所有消息级属性都可供将来使用。

十四、控制消息
我们使用控制消息来表示事务标记。具有控制属性集(见上文)的批次中包含的所有消息都被视为控制消息并遵循特定格式。每个控制消息必须有一个非空键,用于指示控制消息类型的类型,架构如下:
ControlMessageKey => Version ControlMessageType
Version => int16
ControlMessageType => int16
在该提案中,控制消息类型为0表示COMMIT标记,控制消息类型为1表示ABORT标记。控制值的模式通常特定于控制消息类型。
关于消息级模式的讨论。关于此模式的一些附加说明:
轻松访问第一条消息的偏移量使我们能够根据需要将消息流式传输给用户。在现有格式中,我们只知道每个消息集中的最后一个偏移量,因此我们必须将消息完全读取到内存中,以便计算要返回给用户的第一条消息的偏移量。
和以前一样,消息集标头具有固定大小。这很重要,因为它允许我们在写入磁盘之前在代理上进行就地偏移/时间戳分配。
我们已删除此格式中的每条消息 CRC。我们最初犹豫是否这样做,因为它在一些审计应用程序中用于端到端验证。问题在于,即使在目前,假设生产者看到的 CRC 与消费者看到的 CRC 相匹配也是不安全的。不保留它的一种情况是当主题配置为使用日志追加时间时。另一种情况是消息在附加到日志之前需要进行上转换。出于这些原因,为了节省空间和节省计算,我们删除了 CRC 并弃用了客户端对这些字段的使用。
消息集CRC包括报头和消息数据。或者,我们可以让它仅覆盖标头,但如果压缩数据损坏,则解压缩可能会失败并出现模糊错误。此外,这需要我们将消息级 CRC 添加回消息中。
CRC32C 多项式用于新格式中的所有 CRC 计算,因为优化的实现速度明显更快(即,如果它们使用 SSE4.2 中引入的 CRC32 指令)。
消息集中的各个消息将其完整大小(包括标头、键和值)作为第一个字段。这样做的目的是为了提高反序列化的效率。正如我们对消息集本身所做的那样,我们可以从输入流中读取大小,相应地分配内存,并执行一次读取直到消息末尾。如果我们正在寻找特定的消息,这也使得跳过消息变得更容易,这可能使我们免于复制键和值。
我们没有在消息模式中包含值大小的字段,因为它可以使用消息大小以及标头和密钥的长度直接计算。
我们使用可变长度整数来表示时间戳。我们的做法是让第一条消息
十五、空间比较
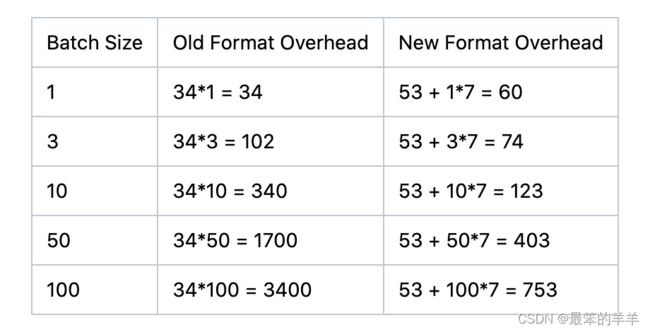
随着批量大小的增加,由于消除了冗余,新格式的开销与旧格式相比变得更小。旧格式中每条消息的开销固定为 34 字节。对于新格式,消息集开销为 53 字节,而每条消息的开销范围为 6 到 25 字节。这使得发送单个消息的成本更高,但即使是适度的批处理也可以快速恢复空间。例如,假设固定消息大小为 1K,具有 100 字节密钥和相当接近的时间戳,则对于每个额外的批处理消息,开销仅增加 7 字节(消息大小 2 字节,属性 1 字节,时间戳增量 2 字节, 1 个字节用于偏移增量,1 个字节用于密钥大小):
十六、指标
作为这项工作的一部分,我们需要公开新的指标以使系统可运行。这些包括:
实时 PID 数量(PID->序列映射大小的代理)
每个分区的当前 LSO(用于检测卡住的消费者和丢失的提交/中止标记)。
活动 transactionalId 的数量(事务协调器消耗的内存的代理)。
十七、兼容性、弃用和迁移计划
我们遵循 KIP-32 中使用的相同方法。要从以前的消息格式版本升级,用户应该:
- 将代理间协议设置为之前部署的版本,升级代理一次。
- 使用更新的代理间协议再次升级代理,但保持消息格式不变。
- 通知客户端他们可以升级,但还不应该开始使用幂等/事务消息 API。
- [当观察到大多数客户端已升级时] 重新启动代理,并将消息格式版本设置为最新。
- 通知升级后的客户端他们现在可以开始使用幂等/事务消息 API。
步骤 3 的原因是为了避免将消息下转换为旧格式的性能成本,这实际上会失去“零复制”优化。理想情况下,所有消费者在生产者开始写入新消息格式之前就已升级。
注意:由于旧的生产者早已被弃用,并且旧的消费者将在 0.11.0 中弃用,因此这些客户端将不支持新格式。为了避免转化率下降,用户必须升级到新客户端。可以有选择地启用已使用新客户端的主题的消息格式。