污点分析技术
目录
污点分析技术
基本原理
识别污点源和汇聚点
污点传播分析
污点传播分析的关键技术
污点分析方法实现
污点分析在实际应用中的关键技术
总结
参考文献
污点分析技术
基本原理
污点分析定义
污点分析可以抽象成一个三元组source 即污点源,代表直接引入不受信任的数据或者机密数据到系统中;sink 即污点汇聚点,代表直接产生安全敏感操作(违反数据完整性)或者泄露隐私数据到外界(违反数据保密性);sanitizer 即无害处理,代表通过数据加密或者移除危害操作等手段使数据传播不再对软件系统的信息安全产生危害。
污点分析就是分析程序中由污点源引入的数据是否能够不经无害处理,而直接传播到污点汇聚点。如果不能,说明系统是信息流安全的;否则,说明系统产生了隐私数据泄露或危险数据操作等安全问题。
在漏洞分析中,使用污点分析技术将所感兴趣的数据(通常来自程序的外部输入,假定所有输入都是危险的)标记为污点数据,然后通过跟踪和污点数据相关的信息的流向,可以知道它们是否会影响某些关键的程序操作,进而挖掘程序漏洞。即将程序是否存在某种漏洞的问题转化为污点信息是否会被 Sink 点上的操作所使用的问题。
污点分析常常包括以下几个部分(如图 2 所示):
-
识别污点信息在程序中的产生点(Source点)并对污点信息进行标记(根据所分析的系统的不同使用定制的识别策略)
-
污点传播分析(利用特定的规则跟踪分析污点信息在程序中的传播过程)
-
漏洞检测、无害处理(在一些关键的程序点(Sink点)检测关键的操作是否会受到污点信息的影响)
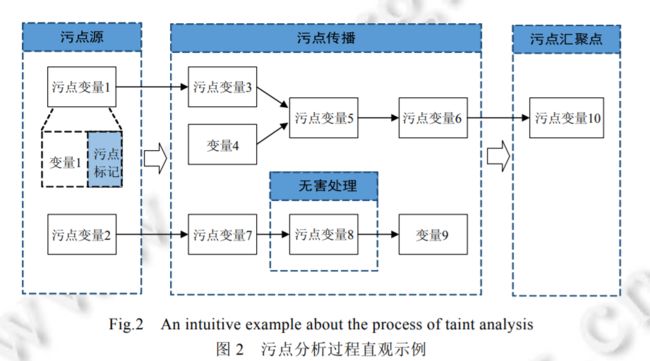
识别污点源和汇聚点
识别污点源和污点汇聚点是污点分析的前提。目前,在不同的应用程序中识别污点源和汇聚点的方法各不相同。缺乏通用方法的原因一方面来自系统模型、编程语言之间的差异。另一方面,污点分析关注的安全漏洞类型不同,也会导致对污点源和污点汇聚点的收集方法迥异。表 1 所示为在 Web 应用程序漏洞检测中的污点源示例1,它们是 Web 框架中关键对象的属性。

现有的识别污点源和汇聚点的方法可以大致分成 3 类:
-
使用启发式的策略进行标记,例如把来自程序外部输入的数据统称为“污点”数据,保守地认为这些数据有可能包含恶意的攻击数据(如 PHP Aspis);
-
根据具体应用程序调用的 API 或者重要的数据类型,手工标记源和汇聚点(如 DroidSafe2);
-
使用统计或机器学习技术自动地识别和标记污点源及汇聚点3。
污点传播分析
污点传播分析就是分析污点标记数据在程序中的传播途径.按照分析过程中关注的程序依赖关系的不同, 可以将污点传播分析分为显式流分析和隐式流分析。
显示流分析
污点传播分析中的显式流分析就是分析污点标记如何随程序中变量之间的数据依赖关系传播

以图 3 所 示的程序为例,变量 a 和 b 被预定义的污点源函数 source 标记为污点源.假设 a 和 b 被赋予的污点标记分别为taint_a 和 taint_b.由于第 5 行的变量 x 直接数据依赖于变量 a,第 6 行的变量 y 直接数据依赖于变量 b,显式流分析会分别将污点标记 taint_a 和 taint_b 传播给第 5 行的变量 x 和第 6 行的变量 y.又由于 x 和 y 分别可以到达第 7 行和第 8 行的污点汇聚点(用预定义的污点汇聚点函数 sink 标识),图 3 所示的代码存在信息泄漏的问题.我们将在后面具体介绍目前污点传播分析中显式流分析面临的主要挑战和解决方法。
隐式流分析
污点传播分析中的隐式流分析是分析污点标记如何随程序中变量之间的控制依赖关系传播,也就是分析污点标记如何从条件指令传播到其所控制的语句。

在图 4 所示的程序中,变量 X 是被污点标记的字符串类型变量,变量 Y 和变量 X 之间并没有直接或间接的数据依赖关系(显式流关系),但 X 上的污点标记可以经过控制依赖隐式地传播到 Y。
具体来说,由第 4 行的循环条件控制的外层循环顺序地取出 X 中的每一个字符,转化成整型后赋给变量 x,再由第 7 行的循环条件控制的内层循环以累加的方式将 x 的值赋给 y,最后由外层循环将 y 逐一传给 Y.最终,第 12 行的 Y 值和 X 值相同,程序存在信息泄漏问题.但是,如果不进行隐式流污点传播分析,第 12 行 的变量 Y 将不会被赋予污点标记,程序的信息泄漏问题被掩盖.
隐式流污点传播一直以来都是一个重要的问题,和显式流一样,如果不被正确处理,会使污点分析的结果不精确.由于对隐式流污点传播处理不当导致本应被标记的变量没有被标记的问题称为欠污染(under-taint)问题.相反地,由于污点标记的数量过多而导致污点变量大量扩散的问题称为过污染(over-taint)问题.目前,针对隐式流问题的研究重点是尽量减少欠污染和过污染的情况.我们将在后面具体介绍现有技术是如何解决上述问题的。
无害处理
污点数据在传播的过程中可能会经过无害处理模块,无害处理模块是指污点数据经过该模块的处理后,数据本身不再携带敏感信息或者针对该数据的操作不会再对系统产生危害.换言之,带污点标记的数据在经过无害处理模块后,污点标记可以被移除.正确地使用无害处理可以降低系统中污点标记的数量,提高污点分析的效率,并且避免由于污点扩散导致的分析结果不精确的问题
在应用过程中,为了防止敏感数据被泄露(保护保密性),通常会对敏感数据进行加密处理.此时,加密库函数应该被识别成无害处理模块.这一方面是由于库函数中使用了大量的加密算法,导致攻击者很难有效地计算出密码的可能范围;另一方面是加密后的数据不再具有威胁性,继续传播污点标记没有意义。
此外,为了防止外界数据因为携带危险操作而对系统关键区域产生危害(保护完整性),通常会对输入的数据进行验证。
综上,目前对污点源、污点汇聚点以及无害处理模块的识别通常根据系统或漏洞类型使用定制的方法.由于这些方法都比较直接,本文将不再进行更深入的探讨.下一节将重点介绍污点传播中的关键技术。
总结,使用污点分析检测程序漏洞的工作原理如下图所示:

-
基于数据流的污点分析。在不考虑隐式信息流的情况下,可以将污点分析看做针对污点数据的数据流分析。根据污点传播规则跟踪污点信息或者标记路径上的变量污染情况,进而检查污点信息是否影响敏感操作。
-
基于依赖关系的污点分析。考虑隐式信息流,在分析过程中,根据程序中的语句或者指令之间的依赖关系,检查 Sink 点处敏感操作是否依赖于 Source 点处接收污点信息的操作。
污点传播分析的关键技术
污点传播分析是当前污点分析领域的研究重点.与程序分析技术相结合,可以获得更加高效、精确的污点分析结果.根据分析过程中是否需要运行程序,可以将污点传播分析分为静态污点分析和动态污点分析.本节主要介绍如何使用动/静态程序分析技术来解决污点传播中的显式流分析和隐式流分析问题
显式流分析和隐式流分析是从两种不同的角度(数据流和控制流)来观察污点传播
污点传播中的显式流分析
静态分析技术
静态污点传播分析(简称静态污点分析)是指在不运行且不修改代码的前提下,通过分析程序变量间的数据依赖关系来检测数据能否从污点源传播到污点汇聚点.
静态污点分析的对象一般是程序的源码或中间表示.可以将对污点传播中显式流的静态分析问题转化为对程序中静态数据依赖的分析:
-
首先,根据程序中的函数调用关系构建调用图(call graph,简称CG);
-
然后,在函数内或者函数间根据不同的程序特性进行具体的数据流传播分析.常见的显式流污点传播方式包括直接赋值传播、通过函数(过程)调用传播以及通过别名(指针)传播
以图 5 所示的 Java 程序为例:

第 3 行的变量 b 为初始的污点标记变量,程序第 4 行将一个包含变量 b 的算术表达式的计算结果直接赋给变量 c.由于变量 c 和变量 b 之间具有直接的赋值关系,污点标记可直接从赋值语句右部的变量传播到左部,也就是上述 3种显式流污点传播方式中的直接赋值传播
接下来,变量 c 被作为实参传递给程序第 5 行的函数 foo,c 上的污点标记也通过函数调用传播到 foo 的形参 z,z 的污点标记又通过直接赋值传播到程序第 8 行的 x.f.由于 foo 的另外两个参数对象 x 和 y 都是对对象 a 的引用,二者之间存在别名,因此,x.f的污点标记可以通过别名传播到第 9 行的污点汇聚点,程序存在泄漏问题.
目前,利用数据流分析解决显式污点传播分析中的直接赋值传播和函数调用传播已经相当成熟,研究的重点是如何为别名传播的分析提供更精确、高效的解决方案.由于精确度越高(上下文敏感、流敏感、域敏感、对象敏感等)的程序静态分析技术往往伴随着越大的时空开销,追求全敏感且高效的别名分析难度较大.又由于静态污点传播分析关注的是从污点源到污点汇聚点之间的数据流关系,分析对象并非完整的程序,而是确定的入口和出口之间的程序片段.这就意味着可以尝试采用按需(on-demand)定制的别名分析方法来解决显式流态污点分析中的别名传播问题
动态分析技术
动态污点传播分析(简称动态污点分析)是指在程序运行过程中,通过实时监控程序的污点数据在系统程序中的传播来检测数据能否从污点源传播到污点汇聚点.动态污点传播分析首先需要为污点数据扩展一个污点标记(tainted tag)的标签并将其存储在存储单元(内存、寄存器、缓存等)中,然后根据指令类型和指令操作数设计相应的传播逻辑传播污点标记
动态污点传播分析按照实现层次被分为基于硬件、基于软件以及混合型的污点传播分析这3类
1.硬件
基于硬件的污点传播分析需要定制的硬件支持,一般需要在原有体系结构上为寄存器或者内存扩展一个标记位,用来存储污点标记
2.基于软件
基于软件的污点传播分析通过修改程序的二进制代码来进行污点标记位的存储与传播
基于软件的污点传播的优点在于不必更改处理器等底层的硬件,并且可以支持更高的语义逻辑的安全策略(利用其更贴近源程序层次的特点),但缺点是使用插桩(instrumentation 在保证被测程序原有逻辑完整性的基础上在程序中插入一些探针)或代码重写(code rewriting)修改程序往往会给分析系统带来巨大的开销.相反地,基于硬件的污点传播分析虽然可以利用定制硬件降低开销,但通常不能支持更高的语义逻辑的安全策略,并且需要对处理器结构进行重新设计
3.混合型
混合型的污点分析是对上述两类方法的折中,即,通过尽可能少的硬件结构改动以保证更高的语义逻辑的安全策略
目前,针对动态污点传播分析的研究工作关注的首要问题是如何设计有效的污点传播逻辑,以确保精确的污点传播分析
污点传播中的隐式流分析
污点传播分析中的隐式流分析就是分析污点数据如何通过控制依赖进行传播,如果忽略了对隐式流污点传播的分析,则会导致欠污染的情况;如果对隐式流分析不当,那么除了欠污染之外,还可能出现过污染的情况.与显式流分析类似,隐式流分析技术同样也可以分为静态分析和动态分析两类
静态分析技术
静态隐式流分析面临的核心问题是精度与效率不可兼得的问题.精确的隐式流污点传播分析需要分析每一个分支控制条件是否需要传播污点标记.路径敏感的数据流分析往往会产生路径爆炸问题,导致开销难以接受.为了降低开销,一种简单的静态传播(标记)分支语句的污点标记方法是将控制依赖于它的语句全部进行污点标记,但该方法会导致一些并不携带隐私数据的变量被标记,导致过污染情况的发生.过污染会引起污点的大量扩散,最终导致用户得到的报告中信息过多,难以使用
动态分析技术
动态隐式流分析关注的首要问题是如何确定污点控制条件下需要标记的语句的范围.由于动态执行轨迹并不能反映出被执行的指令之间的控制依赖关系,目前的研究多采用离线的静态分析辅助判断动态污点传播中的隐式流标记范围.Clause等人提出,利用离线静态分析得到的控制流图节点间的后支配(post-dominate)关系来解决动态污点传播中的隐式流标记问题
例如,如图 6(a)所示,程序第 3 行的分支语句被标记为污点源,当document.cookie 的值为 abc 时,会发生污点数据泄露.根据基于后支配关系的标记算法,会对该示例第 4 行语句的指令目的地,即 x 的值进行污点标记.(ps:因为根据该分支控制下的语句的执行结果可以判定污染源document.cookie的值,造成污点数据泄露)

动态分析面临的第 2 个问题是由于部分泄漏(partially leaked)导致的漏报.部分泄漏是指污点信息通过动态未执行部分进行传播并泄漏.Vogt等人发现,只动态地标记分支条件下的语句会发生这种情况
仍以图 6(a)中的程序为例:当第 3 行的控制条件被执行时,对应的 x 会被标记.此时,x 的值为 true,而 y 值没有变化,仍然为 false.在后续执行过程中,由于第 9行的污点汇聚点不可达,而第 12 行的汇聚点可达,动态分析没有检测到污点数据泄漏.但攻击者由第 11 行 y 等于 false 的条件能够反推出程序执行了第 3 行的分支条件,程序实际上存在信息泄漏的问题.这个信息泄露是由第 6 行未被执行到的 y 的赋值语句所触发的.因此,y 应该被动态污点传播分析所标记.为了解决部分泄漏问题,Vogt等人在传统的动态污点分析基础上增加了离线的静态分析,以跟踪动态执行过程中的控制依赖关系,对污点分支控制范围内的所有赋值语句中的变量都进行标记.具体到图 6(a)所示的例子,就是第 4 行和第 6 行中的变量均会被污点标记.但是,Vogt 等人的方法仍然会产生过污染的情况.
动态分析需要解决的第 3 个问题是如何选择合适的污点标记分支进行污点传播.鉴于单纯地将所有包含污点标记的分支进行传播会导致过污染的情况,可以根据信息泄漏范围的不同,定量地设计污点标记分支的选择策略.
以图 6(b)所示的程序为例,第 2 行的变量 a 为初始的污点标记变量.第 5 行、第 7 行、第 9 行均为以 a作为源操作数的污点标记的分支.如果传播策略为只要分支指令中包含污点标记就对其进行传播,那么第 5 行、第 7 行、第 9 行将分别被传播给第 6 行、第 8 行、第 10 行,并最终传播到第 12 行的污点汇聚点.如果对这段程序进行深入分析会发现,3个分支条件所提供的信息值(所能泄露的信息范围)并不相同,分别是 a 等于 10、a大于 10 且小于或等于 13(将 w 值代入计算)以及 a 小于 10.对于 a 等于 10 的情况,攻击者可以根据第 12 行泄漏的 x 的值直接还原出污点源处 a 的值(这类分支也被称为能够保存完整信息的分支);对于 a 大于 10 且小于或等于 13 的情况,攻击者也只需要尝试 3 次就可以还原信息;而对于 a 小于 10 的情况,攻击者所获得的不确定性较大,成功还原信息的几率显著低于前两种,对该分支进行污点传播的实际意义不大.
Bao等人只将严格控制依赖(strict control dependence)识别成需要污点传播的分支,其中,严格控制依赖即分支条件表达式的两端具有常数差异的分支.但是,Bao 的方法只适用于能够在编译阶段计算出常数差异的分支.
污点分析方法实现
静态污点分析技术
静态污点分析系统首先对程序代码进行解析,获得程序代码的中间表示,然后在中间表示的基础上对程序代码进行控制流分析等辅助分析,以获得需要的控制流图、调用图等。在辅助分析的过程中,系统可以利用污点分析规则在中间表示上识别程序中的 Source 点和 Sink 点。最后检测系统根据污点分析规则,利用静态污点分析检查程序是否存在污点类型的漏洞。
基于数据流的污点分析
在基于数据流的污点分析中,常常需要一些辅助分析技术,例如别名分析、取值分析等,来提高分析精度。辅助分析和污点分析交替进行,通常沿着程序路径的方向分析污点信息的流向,检查 Source 点处程序接收的污点信息是否会影响到 Sink 点处的敏感操作。
过程内的分析中,按照一定的顺序分析过程内的每一条语句或者指令,进而分析污点信息的流向。
-
记录污点信息。在静态分析层面,程序变量的污染情况为主要关注对象。为记录污染信息,通常为变量添加一个污染标签。最简单的就是一个布尔型变量,表示变量是否被污染。更复杂的标签还可以记录变量的污染信息来自哪些 Source 点,甚至精确到 Source 点接收数据的哪一部分。当然也可以不使用污染标签,这时我们通过对变量进行跟踪的方式达到分析污点信息流向的目的。例如使用栈或者队列来记录被污染的变量。
-
程序语句的分析。在确定如何记录污染信息后,将对程序语句进行静态分析。通常我们主要关注赋值语句、控制转移语句以及过程调用语句三类。
-
赋值语句。
-
对于简单的赋值语句,形如
a = b这样的,记录语句左端的变量和右端的变量具有相同的污染状态。程序中的常量通常认为是未污染的,如果一个变量被赋值为常量,在不考虑隐式信息流的情况下,认为变量的状态在赋值后是未污染的。 -
对于形如
a = b + c这样带有二元操作的赋值语句,通常规定如果右端的操作数只要有一个是被污染的,则左端的变量是污染的(除非右端计算结果为常量)。 -
对于和数组元素相关的赋值,如果可以通过静态分析确定数组下标的取值或者取值范围,那么就可以精确地判断数组中哪个或哪些元素是污染的。但通常静态分析不能确定一个变量是污染的,那么就简单地认为整个数组都是污染的。
-
对于包含字段或者包含指针操作的赋值语句,常常需要用到指向分析的分析结果。
-
-
控制转移语句。
-
在分析条件控制转移语句时,首先考虑语句中的路径条件可能是包含对污点数据的限制,在实际分析中常常需要识别这种限制污点数据的条件,以判断这些限制条件是否足够包含程序不会受到攻击。如果得出路径条件的限制是足够的,那么可以将相应的变量标记为未污染的。
-
对于循环语句,通常规定循环变量的取值范围不能受到输入的影响。例如在语句
for (i = 1; i < k; i++){}中,可以规定循环的上界 k 不能是污染的。
-
-
过程调用语句。
-
可以使用过程间的分析或者直接应用过程摘要进行分析。污点分析所使用的过程摘要主要描述怎样改变与该过程相关的变量的污染状态,以及对哪些变量的污染状态进行检测。这些变量可以是过程使用的参数、参数的字段或者过程的返回值等。例如在语句
flag = obj。method(str);中,str 是污染的,那么通过过程间的分析,将变量 obj 的字段 str 标记为污染的,而记录方法的返回值的变量 flag 标记为未污染的。 -
在实际的过程间分析中,可以对已经分析过的过程构建过程摘要。例如前面的语句,其过程摘要描述为:方法 method 的参数污染状态决定其接收对象的实例域 str 的污染状态,并且它的返回值是未受污染的。那么下一次分析需要时,就可以直接应用摘要进行分析。
-
-
-
代码的遍历。一般情况下,常常使用流敏感的方式或者路径敏感的方式进行遍历,并分析过程中的代码。如果使用流敏感的方式,可以通过对不同路径上的分析结果进行汇集,以发现程序中的数据净化规则。如果使用路径敏感的分析方式,则需要关注路径条件,如果路径条件中涉及对污染变量取值的限制,可认为路径条件对污染数据进行了净化,还可以将分析路径条件对污染数据的限制进行记录,如果在一条程序路径上,这些限制足够保证数据不会被攻击者利用,就可以将相应的变量标记为未污染的。
过程间的分析与数据流过程间分析类似,使用自底向上的分析方法,分析调用图中的每一个过程,进而对程序进行整体的分析。
基于依赖关系的污点分析
在基于依赖关系的污点分析中,首先利用程序的中间表示、控制流图和过程调用图构造程序完整的或者局部的程序的依赖关系。在分析程序依赖关系后,根据污点分析规则,检测 Sink 点处敏感操作是否依赖于 Source 点。
分析程序依赖关系的过程可以看做是构建程序依赖图的过程。程序依赖图是一个有向图。它的节点是程序语句,它的有向边表示程序语句之间的依赖关系。程序依赖图的有向边常常包括数据依赖边和控制依赖边。在构建有一定规模的程序的依赖图时,需要按需地构建程序依赖关系,并且优先考虑和污点信息相关的程序代码。
静态污点分析实例分析
在使用污点分析方法检测程序漏洞时,污点数据相关的程序漏洞是主要关注对象,如 SQL 注入漏洞、命令注入漏洞和跨站脚本漏洞等。
下面是一个存在 SQL 注入漏洞 ASP 程序的例子:
<%
Set pwd = "bar"
Set sql1 = "SELECT companyname FROM " & Request。Cookies("hello")
Set sql2 = Request。QueryString("foo")
MySqlStuff pwd, sql1, sql2
Sub MySqlStuff(password, cmd1, cmd2)
Set conn = Server。CreateObject("ADODB。Connection")
conn。Provider = "Microsoft。Jet。OLEDB。4。0"
conn。Open "c:/webdata/foo。mdb", "foo", password
Set rs = conn。Execute(cmd2)
Set rs = Server。CreateObject("ADODB。recordset")
rs。Open cmd1, conn
End Sub
%>首先对这段代码表示为一种三地址码的形式,例如第 3 行可以表示为:
a = "SELECT companyname FROM "
b = "hello"
param0 Request
param1 b
callCookies
return c
sql1 = a & c解析完毕后,需要对程序代码进行控制流分析,这里只包含了一个调用关系(第 5 行)。
接下来,需要识别程序中的 Source 点和 Sink 点以及初始的被污染的数据。
具体的分析过程如下:
-
调用 Request。Cookies("hello") 的返回结果是污染的,所以变量 sql1 也是污染的。
-
调用 Request。QueryString("foo") 的返回结果 sql2 是污染的。
-
函数 MySqlStuff 被调用,它的参数 sql1,sql2 都是污染的。分了分析函数的处理过程,根据第 6 行函数的声明,标记其参数 cmd1,cmd2 是污染的。
-
第 10 行是程序的 Sink 点,函数 conn。Execute 执行 SQL 操作,其参数 cmd2 是污染的,进而发现污染数据从 Source 点传播到 Sink 点。因此,认为程序存在 SQL 注入漏洞
动态污点分析技术
动态污点分析是在程序运行的基础上,对数据流或控制流进行监控,从而实现对数据在内存中的显式传播、数据误用等进行跟踪和检测。动态污点分析与静态污点分析的唯一区别在于静态污点分析技术在检测时并不真正运行程序,而是通过模拟程序的执行过程来传播污点标记,而动态污点分析技术需要运行程序,同时实时传播并检测污点标记。
动态污点分析技术可分为三个部分:
-
污点数据标记:程序攻击面是程序接受输入数据的接口集,一般由程序入口点和外部函数调用组成。在污点分析中,来自外部的输入数据会被标记为污点数据。根据输入数据来源的不同,可分为三类:网络输入、文件输入和输入设备输入。
-
污点动态跟踪:在污点数据标记的基础上,对进程进行指令粒度的动态跟踪分析,分析每一条指令的效果,直至覆盖整个程序的运行过程,跟踪数据流的传播。
-
动态污点跟踪通常基于以下三种机制
-
动态代码插桩:可以跟踪单个进程的污点数据流动,通过在被分析程序中插入分析代码,跟踪污点信息流在进程中的流动方向。
-
全系统模拟:利用全系统模拟技术,分析模拟系统中每条指令的污点信息扩散路径,可以跟踪污点数据在操作系统内的流动。
-
虚拟机监视器:通过在虚拟机监视器中增加分析污点信息流的功能,跟踪污点数据在整个客户机中各个虚拟机之间的流动。
-
-
污点动态跟踪通常需要影子内存(shadow memory)来映射实际内存的污染情况,从而记录内存区域和寄存器是否是被污染的。对每条语句进行分析的过程中,污点跟踪攻击根据影子内存判断是否存在污点信息的传播,从而对污点信息进行传播并将传播结果保存于影子内存中,进而追踪污点数据的流向。
-
一般情况下,数据移动类和算数类指令都将造成显示的信息流传播。为了跟踪污点数据的显示传播,需要在每个数据移动指令和算数指令执行前做监控,当指令的结果被其中一个操作数污染后,把结果数据对应的影子内存设置为一个指针,指向源污染点操作数指向的数据结构。
-
-
污点误用检查:在正确标记污点数据并对污点数据的传播进行实时跟踪后,就需要对攻击做出正确的检测即检测污点数据是否有非法使用的情况。
动态污点分析的优缺点:
-
优点:误报率较低,检测结果的可信度较高。
-
缺点:
-
漏报率较高:由于程序动态运行时的代码覆盖率决定的。
-
平台相关性较高:特定的动态污点分析工具只能够解决在特定平台上运行的程序。
-
资源消耗大:包括空间上和时间上。
-
动态污点分析的方法实现
1.污点数据标记
污点数据通常主要是指软件系统所接受的外部输入数据,在计算机中,这些数据可能以内存临时数据的形式存储,也可能以文件的形式存储。当程序需要使用这些数据时,一般通过函数或系统调用来进行数据访问和处理,因此只需要对这些关键函数进行监控,即可得到程序读取或输出了什么污点信息。另外对于网络输入,也需要对网络操作函数进行监控。
识别出污点数据后,需要对污点进行标记。污点生命周期是指在该生命周期的时间范围内,污点被定义为有效。污点生命周期开始于污点创建时刻,生成污点标记,结束于污点删除时刻,清除污点标记。
-
污点创建
-
将来自于非可靠来源的数据分配给某寄存器或内存操作数时
-
将已经标记为污点的数据通过运算分配给某寄存器或内存操作数时
-
-
污点删除
-
将非污点数据指派给存放污点的寄存器或内存操作数时
-
将污点数据指派给存放污点的寄存器或内存地址时,此时会删除原污点,并创建新污点
-
一些会清除污点痕迹的算数运算或逻辑运算操作时
-
2.污点动态跟踪
当污点数据从一个位置传递到另一个位置时,则认为产生了污点传播。污点传播规则:
| 指令类型 | 传播规则 | 举例说明 |
|---|---|---|
| 拷贝或移动指令 | T(a)<-T(b) | mov a, b |
| 算数运算指令 | T(a)<-T(b) | add a, b |
| 堆栈操作指令 | T(esp)<-T(a) | push a |
| 拷贝或移动类函数调用指令 | T(dst)<-T(src) | call memcpy |
| 清零指令 | T(a)<-false | xor a, a |
注:T(x) 的取值分为 true 和 false 两种,取值为 true 时表示 x 为污点,否则 x 不是污点。
对于污点信息流,通过污点跟踪和函数监控,已经能够进行污点信息流流动方向的分析。但由于缺少对象级的信息,仅靠指令级的信息流动并不能完全给出要分析的软件的确切行为。因此,需要在函数监控的基础上进行视图重建,如获取文件对象和套接字对象的详细信息,以方便进一步的分析工作。
根据漏洞分析的实际需求,污点分析应包括两方面的信息:
-
污点的传播关系,对于任一污点能够获知其传播情况。
-
对污点数据进行处理的所有指令信息,包括指令地址、操作码、操作数以及在污点处理过程中这些指令执行的先后顺序等。
污点动态跟踪的实现通常使用:
-
影子内存:真实内存中污点数据的镜像,用于存放程序执行的当前时刻所有的有效污点。
-
污点传播树:用于表示污点的传播关系。
-
污点处理指令链:用于按时间顺序存储与污点数据处理相关的所有指令。
当遇到会引起污点传播的指令时,首先对指令中的每个操作数都通过污点快速映射查找影子内存中是否存在与之对应的影子污点从而确定其是否为污点数据,然后根据污点传播规则得到该指令引起的污点传播结果,并将传播产生的新污点添加到影子内存和污点传播树中,同时将失效污点对应的影子污点删除。同时由于一条指令是否涉及污点数据的处理,需要在污点分析过程中动态确定,因此需要在污点处理指令链中记录污点数据的指令信息。
3.污点误用检查
污点敏感点,即 Sink 点,是污点数据有可能被误用的指令或系统调用点,主要分为:
-
跳转地址:检查污点数据是否用于跳转对象,如返回地址、函数指针、函数指针偏移等。具体操作是在每个跳转类指令(如call、ret、jmp等)执行前进行监控分析,保证跳转对象不是污点数据所在的内存地址。
-
格式化字符串:检查污点数据是否用作printf系列函数的格式化字符串参数。
-
系统调用参数:检查特殊系统调用的特殊参数是否为污点数据。
-
标志位:跟踪标志位是否被感染,及被感染的标志位是否用于改变程序控制流。
-
地址:检查数据移动类指令的地址是否被感染。
在进行污点误用检查时,通常需要根据一些漏洞模式来进行检查,首先需要明确常见漏洞在二进制代码上的表现形式,然后将其提炼成漏洞模式,以更有效地指导自动化的安全分析。
动态污点分析的实例分析
下面我们来看一个使用动态污点分析的方法检测缓冲区溢出漏洞的例子。
void fun(char *str)
{
char temp[15];
printf("in strncpy, source: %s\n", str);
strncpy(temp, str, strlen(str)); // Sink 点
}
int main(int argc, char *argv[])
{
char source[30];
gets(source); // Source 点
if (strlen(source) < 30)
fun(source);
else
printf("too long string, %s\n", source);
return 0;
}漏洞很明显, 调用 strncpy 函数存在缓冲区溢出。
程序接受外部输入字符串的二进制代码如下:
0x08048609 <+51>: lea eax,[ebp-0x2a]
0x0804860c <+54>: push eax
0x0804860d <+55>: call 0x8048400
...
0x0804862c <+86>: lea eax,[ebp-0x2a]
0x0804862f <+89>: push eax
0x08048630 <+90>: call 0x8048566 程序调用 strncpy 函数的二进制代码如下:
0x080485a1 <+59>: push DWORD PTR [ebp-0x2c]
0x080485a4 <+62>: call 0x8048420
0x080485a9 <+67>: add esp,0x10
0x080485ac <+70>: sub esp,0x4
0x080485af <+73>: push eax
0x080485b0 <+74>: push DWORD PTR [ebp-0x2c]
0x080485b3 <+77>: lea eax,[ebp-0x1b]
0x080485b6 <+80>: push eax
0x080485b7 <+81>: call 0x8048440 首先,在扫描该程序的二进制代码时,能够扫描到 call ,该函数会读入外部输入,即程序的攻击面。确定了攻击面后,我们将分析污染源数据并进行标记,即将 [ebp-0x2a] 数组(即源程序中的source)标记为污点数据。程序继续执行,该污染标记会随着该值的传播而一直传递。在进入 fun() 函数时,该污染标记通过形参实参的映射传递到参数 str 上。然后运行到 Sink 点函数 strncpy()。该函数的第二个参数即 str 和 第三个参数 strlen(str) 都是污点数据。最后在执行 strncpy() 函数时,若设定了相应的漏洞规则(目标数组小于源数组),则漏洞规则将被触发,检测出缓冲区溢出漏洞。
污点分析在实际应用中的关键技术
污点分析被广泛地应用在系统隐私数据泄露、安全漏洞等问题的检测中.在实际应用过程中,由于系统框架、语言特性等方面的差异,通用的污点分析技术往往难以适用.比如:系统框架的高度模块化以及各模块之间复杂的调用关系导致污点源到汇聚点的传播路径变得复杂、庞大,采用通用的污点分析技术可能面临开销难以接受的问题;通用的污点分析技术对新的语言特性支持有限等.为此,需要针对不同的应用场景,对通用的污点分析技术进行扩展或定制
本节以两个代表性的应用场景——智能手机的隐私泄漏检测和Web应用安全漏洞检测为切入点,总结近10年来污点分析技术在上述领域的应用实践过程中所面临的问题和关键解决技术
检测智能手机隐私泄露
针对Android的污点传播分析也围绕组件展开,按照传播可能通过的模块的不同,分为组件内污点传播、组件间污点传播、组件与库函数之间的污点传播这3类(如图7所示).接下来将分别介绍针对这3类传播问题的静态和动态污点传播分析技术

静态污点分析
1.组件内污点传播分析
组件内部污点分析面临的主要问题是如何构建完整的分析模型.不同于传统的C/C++程序(有唯一的Main函数入口),Android应用程序存在有多个入口函数的情况.这个情况源于Android应用程序复杂的运行生命周期(例如onCreate,onStart,onResume,onPause等)以及程序中大量存在的回调函数和异步函数调用.由于任何的程序入口都有可能是隐私数据的来源,在静态的污点分析开始之前必须构建完整的应用程序模型,以确保程序中每一种可能的执行路径都会被静态污点传播分析覆盖到
LeakMiner4和CHEX5尝试使用增量的方法构建系统调用图.
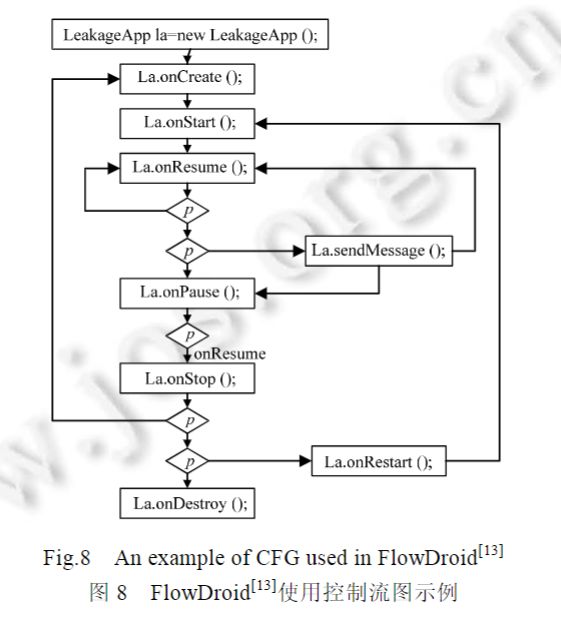
Arzt等人设计的FlowDroid6提出了一种更系统的构建Android程序完整分析模型的方法:首先,通过XML配置文件提取与Android生命周期相关的入口函数,将这些方法作为节点,并根据Android生命周期构建调用图(如图8所示);其次,对于生命周期内的回调函数,在该调用图的基础上增加不透明谓词节点(即图8中菱形的P节点);然后,增量式地将回调函数加入这个函数调用图;最后,将调用图上所有的执行入口连接到一个虚假的Main函数上.FlowDroid中的一次合法的执行,就是对调用图进行的一次遍历
Gordon等人7提出的DroidSafe使用Android设备实现(Android device implementation)来构建Android的完整分析模型.Android设备实现是对Android运行环境的一个简单模拟,它使用Java语言,结合Android Open Source Porject(AOSP),实现了与原Android接口语义等价的模型,并使用精确分析存根(accurate analysis stub)将AOSP代码之外的函数加入到模型中
2.组件间污点传播分析
即使正确分析了组件内的数据流关系,污点数据仍然可能通过组件间的数据流来传递,从而造成信息泄露.如上图7左侧所示,即使保证了对组件A内部污点传播的精确分析,组件A仍然可能通过调用方法startActivityforResult()将信息传递给组件B,再通过组件B产生泄露.因此,针对Android应用的污点分析还需要分析出组件间所有可能的数据流信息.组件间通信是通过组件发送Intent消息对象完成的.Intent按照参数字段是否包含目标组件名称分为显式Intent和隐式Intent.如图9所示:显式Intent对象使用一个包含目标组件名称的参数显式地指定通信的下一个组件;隐式Intent使用action,category等域隐式地让Android系统通过Intent Filter自动选择一个组件调用.目前,解决该问题的主要思想是利用Intent参数信息分析组件间的数据流

解决组件间数据流的前提是解析Intent的目的地,解析Intent目的地包括解析显式Intent的目的地和隐式Intent的目的地.由于显式Intent的目的地可以直接通过初始化Intent的地址字符串参数获得,目前,解析显式Intent目的地的常用方法是使用字符串分析工具提取Intent中字符串参数的信息.
解析隐式Intent目的地的主要方法是分析配置文件信息与Intent Filter注册器之间的映射关系,建立发送Intent组件和接受Intent组件之间的配对关系.在解析出Intent目的地之后,问题的重点转移到如何提高组件间数据流分析的精度上.
Klieber等人尝试在已经建立好的组件内污点分析的基础上,结合推导规则来分析组件间数据流.在分析之前,需要收集组件内部的污点源和汇聚点以及组件内Intent的发送目的地标签等信息.表4和表5给出了推导规则的前提定义和具体的推导规则,其中,一次完整的分析是指根据已知组件内部的信息src→sinksrc→sin**k以及推导规则识别所有src′→sink′src′→sin**k′的流集合
Octeau等人尝试使用现有的程序分析方法提高组件间数据流分析的精度,他们将组件间数据流分析问题转化成IDE(interprocedural distributive environment)问题[58]进行求解.DroidSafe设计了一种对象敏感的别名分析技术,在此基础上提供的精度优化方法包括:提取Intent的目的地的字符串参数、将Intent目的地的初始化函数嵌入到目的组件当中以提高别名分析的精度,同时,增加处理Android Service的支持


组件与库函数之间的污点传播分析
组件与库函数之间的污点传播分析面临的主要问题包括对Android库函数自身庞大的代码量的分析以及组件和某些库函数使用的实现语言不同(Android组件通常用Java实现,而本地库则采用C/C++代码编写)这两方面
动态污点分析
Android系统中的动态污点同样需要分析组件内污点传播、组件间污点传播以及组件代码与本地库之间的污点传播.动态污点分析面临的主要挑战是系统信息除了在系统内部通过DEX指令传播以外,还会经过其他的通道,如本地库、网络、文件等.
1.组件内的污点传播
2.组件间的污点传播
3.组件与本地库函数间的污点传播
包括污点数据通过本地库代码或文件进行传播.TaintDroid通过设计后置条件对本地代码的函数进行污点传播.后置条件为:
(a) 所有本地代码访问的外部变量都会被标记上污点标签;
(b) 根据预定义规则将被赋值的函数返回值也标记上污点标签
总结
污点分析作为信息流分析的一种实践技术,被广泛应用于互联网及移动终端平台上应用程序的信息安全保障中.本文介绍了污点分析的基本原理和通用技术,并针对近年来污点分析在解决实际应用程序安全问题时遇到的问题和关键解决技术进行了分析综述.不同于基于安全类型系统的信息流分析技术,污点分析可以不改变程序现有的编程模型或语言特性,并提供精确信息流传播跟踪.在实际应用过程中,污点分析还需要借助传统的程序分析技术的支持,例如静态分析中的数据流分析、动态分析中的代码重写等技术.另外,结合测试用例生成技术、符号执行技术以及虚拟机技术,也会给污点分析带来更多行之有效的解决方案
参考文献
[1] Vogt P, Nentwich F, Jovanovic N, Kirda E, Kruegel C, Vigna G. Cross site scripting prevention with dynamic data tainting and static analysis. In: Proc. of the NDSS 2007. 2007. 12. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.72.4505
[2] Gordon MI, Kim D, Perkins JH, Gilham L, Nguyen N, Rinard MC. Information flow analysis of Android applications in DroidSafe. In: Proc. of the NDSS 2015. 2015. [doi: 10.14722/ndss.2015.23089]
[3] Rasthofer S, Arzt S, Bodden E. A machine-learning approach for classifying and categorizing android sources and sinks. In: Proc. of the Network and Distributed System Security Symp. (NDSS). 2014. [doi: 10.14722/ndss.2014.23039]
[4] Yang Z, Yang M. Leakminer: Detect information leakage on Android with static taint analysis. In: Proc. of the Software Engineering. IEEE, 2012. 101−104. [doi: 10.1109/WCSE.2012.26]
[5] Lu L, Li Z, Wu Z, Lee W, Jiang G. Chex: Statically vetting Android apps for component hijacking vulnerabilities. In: Proc. of the 2012 ACM Conf. on Computer and Communications Security. ACM Press, 2012. 229−240. [doi: 10.1145/2382196.2382223]
[6] Arzt S, Rasthofer S, Fritz C, Bodden E, Bartel A, Klein J, Le Traon Y, Octeau D, McDaniel P. Flowdroid: Precise context, flow, field, object-sensitive and lifecycle-aware taint analysis for Android apps. ACM SIGPLAN Notices, 2014,49(6):259−269. [doi: 10.1145/2594291.2594299]
[7] Gordon MI, Kim D, Perkins JH, Gilham L, Nguyen N, Rinard MC. Information flow analysis of Android applications in DroidSafe. In: Proc. of the NDSS 2015. 2015. [doi: 10.14722/ndss.2015.23089]
原文链接