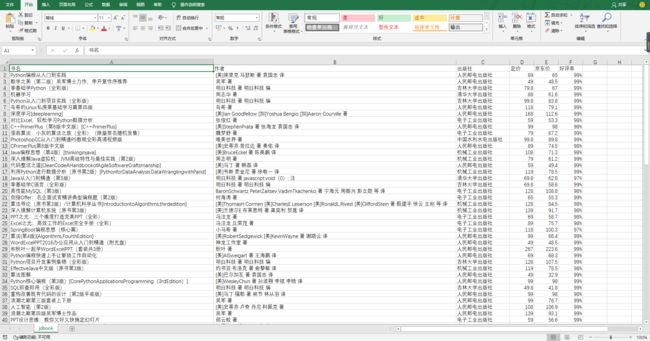
Python爬取京东图书销量榜
Python小作业
题目:
从京东爬取2019年 “计算与互联网”的图书销量榜,包括图书的"书名", “作者”, “出版社”, “定价”, “京东价”, “好评率”,存入csv文件中。
爬取结果:
链接:https://pan.baidu.com/s/19PcHiFzIk0efVBXTgNoupw
提取码:vmua
注:网页结构及数据接口地址有可能发生变化,因此不能保证其时效性。
分析
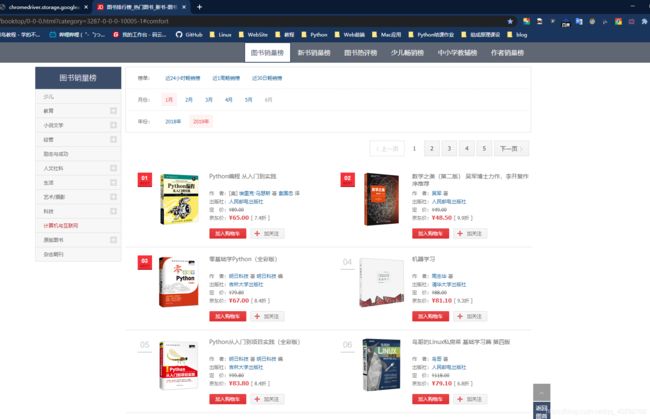
爬取网页https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-5-1
需要安装的库:
import requests
from bs4 import BeautifulSoup
import random
import re
import json
from selenium import webdriver
import time
import csv
运行selenium还需下载相应浏览器的驱动,并且拷贝到python的安装目录。
首先分析url中最后以为数字代表页数,由此可以通过拼接url的方式得到2019年的共5页的url。
url = "https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10005-"
count = 0
for i in range(1, 6):
r = requests.get(url + str(i), headers=headers)
r.encoding = "GBK"
soup = BeautifulSoup(r.text, "html.parser")
li = soup.find('ul', class_="clearfix").find_all('li')
使用bs4库对返回的页面进行解析,获取“作者”和“出版社”并保存在变量中。
for e in li:
count += 1
detail = e.find('div', class_="p-detail")
href = "https:" + detail.find('a')['href'] # 二级链接
dl = detail.find_all('dl')
author = dl[0].find('dd').text.replace(' ', '').replace("\n", ' ').replace("著", "著 ") # 作者
press = dl[1].find('a').string # 出版社
因书名在当前页面显示不完整,所以在商品详情页面获取。
new_soup = BeautifulSoup(requests.get(href, headers=headers).text, "html.parser")
name = new_soup.select_one('.sku-name').text.replace("\n", '').replace(" ", '') # 书名
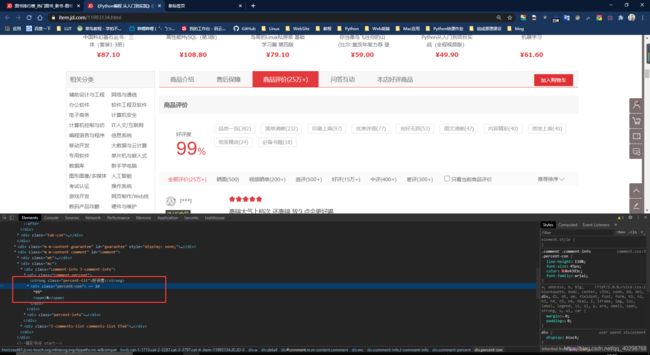
商品价格通过Beautiful解析不到,由此分析可能是通过ajax异步请求来获取数据。分析网页请求,得到JD商品价格的api接口地址https://p.3.cn/prices/mgets?skuIds=J_skuId,首先获取商品的sjuId,再将其替换就可获取商品的价格信息。

接口返回的数据为json格式(下图是chrome安装了json插件的效果)。

ajax_url = "https://p.3.cn/prices/mgets?skuIds=J_" # 京东商品价格api
skuId = re.search(r'\d+', href).group() # 正则表达式获取商品的skuId
json_p = requests.get(ajax_url + skuId).text # 获取接口内容
data = json.loads(json_p.replace('[', '').replace(']', '')) # 转为json格式
price = data['m'] # 定价
jd_price = data['op'] # 京东价
商品的好评度需要将滑到底部才会加载出来,因此可以使用selenium模拟浏览器行为。
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # 无窗口运行
driver = webdriver.Chrome(options=chrome_options)
driver.get(href)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 模拟浏览器滑到最下面
time.sleep(1) # 短暂延时
html = BeautifulSoup(driver.page_source, "html.parser")
percent = html.find('div', class_="percent-con").text # 好评率
driver.quit() # 使用完关闭浏览器
将所有结果保存,由于爬取时间稍长,所以爬取时打印进度。
result.append([name, author, press, price, jd_price, percent])
print("{0:.2%}".format(count / 100))
最后将所有结果存进csv文件中。
if __name__ == '__main__':
table_head = ["书名", "作者", "出版社", "定价", "京东价", "好评率"]
writer = csv.writer(open("jdbook.csv", 'w')) # 创建文件
writer.writerow(table_head) # 写入表头
writer.writerows(result) # 写入数据
源代码及运行结果:
import requests
from bs4 import BeautifulSoup
import random
import re
import json
from selenium import webdriver
import time
import csv
result = [] # 保存最终结果
my_headers = [
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
]
headers = {'User-Agent': random.choice(my_headers)}
url = "https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10005-"
count = 0
for i in range(1, 6):
r = requests.get(url + str(i), headers=headers)
r.encoding = "GBK"
soup = BeautifulSoup(r.text, "html.parser")
li = soup.find('ul', class_="clearfix").find_all('li')
for e in li:
count += 1
detail = e.find('div', class_="p-detail")
href = "https:" + detail.find('a')['href'] # 二级链接
dl = detail.find_all('dl')
author = dl[0].find('dd').text.replace(' ', '').replace("\n", ' ').replace("著", "著 ") # 作者
press = dl[1].find('a').string # 出版社
new_soup = BeautifulSoup(requests.get(href, headers=headers).text, "html.parser")
name = new_soup.select_one('.sku-name').text.replace("\n", '').replace(" ", '') # 书名
ajax_url = "https://p.3.cn/prices/mgets?skuIds=J_" # 京东商品价格api
skuId = re.search(r'\d+', href).group() # 正则表达式获取商品的skuId
json_p = requests.get(ajax_url + skuId).text # 获取接口内容
data = json.loads(json_p.replace('[', '').replace(']', '')) # 转为json格式
price = data['m'] # 定价
jd_price = data['op'] # 京东价
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # 无窗口运行
driver = webdriver.Chrome(options=chrome_options)
driver.get(href)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 模拟浏览器滑到最下面
time.sleep(1) # 短暂延时
html = BeautifulSoup(driver.page_source, "html.parser")
percent = html.find('div', class_="percent-con").text # 好评率
driver.quit() # 使用完关闭浏览器
result.append([name, author, press, price, jd_price, percent])
print("{0:.2%}".format(count / 100))
if __name__ == '__main__':
table_head = ["书名", "作者", "出版社", "定价", "京东价", "好评率"]
writer = csv.writer(open("jdbook.csv", 'w', newline='')) # 创建文件
writer.writerow(table_head) # 写入表头
writer.writerows(result) # 写入数据
csv文件: