Spark大数据处理讲课笔记4.8 Spark SQL典型案例
目录
零、本讲学习目标
一、使用Spark SQL实现词频统计
(一)提出任务
(二)实现任务
1、准备数据文件
2、创建Maven项目
3、修改源程序目录
4、添加依赖和设置源程序目录
5、创建日志属性文件
6、创建HDFS配置文件
7、创建词频统计单例对象
8、启动程序,查看结果
9、词频统计数据转化流程图
二、使用Spark SQL计算总分与平均分
(一)提出任务
(二)完成任务
1、准备数据文件
2、新建Maven项目
3、修改源程序目录
4、添加相关依赖和设置源程序目录
5、创建日志属性文件
6、创建HDFS配置文件
7、创建计算总分平均分单例对象
8、运行程序,查看结果
三、使用Spark SQL实现分组排行榜
(一)提出任务
(二)涉及知识点
1、数据集与数据帧
2、开窗函数
(三)完成任务
1、准备数据文件
2、新建Maven项目
3、修改源程序目录
4、添加相关依赖和设置源程序目录
5、创建日志属性文件
6、创建HDFS配置文件
7、创建分组排行榜单例对象
8、运行程序,查看结果
四、使用SparkSQL统计每日新增用户
(一)提出任务
(二)实现思路
(三)完成任务
1、准备数据文件
2、新建Maven项目
4、添加相关依赖和设置源程序目录
5、创建日志属性文件
6、创建HDFS配置文件
7、创建统计新增用户单例对象
8、运行程序,查看结果
9、在Spark Shell里运行代码
零、本讲学习目标
- 使用Spark SQL实现词频统计
- 使用Spark SQL计算总分与平均分
- 使用Spark SQL实现分组排行榜
- 使用Spark SQL统计每日新增用户
一、使用Spark SQL实现词频统计
(一)提出任务
- 词频统计是学习分布式计算的入门程序,有很多种实现方式,例如MapReduce;使用Spark提供的RDD算子可以更加轻松地实现词频统计。本次任务,要求利用SparkSQL来实现词频统计。
- 单词文件
hello scala world
hello spark world
scala is very concise
spark is very powerful
let us learn scala and spark
we can learn them well
- 词频统计结果
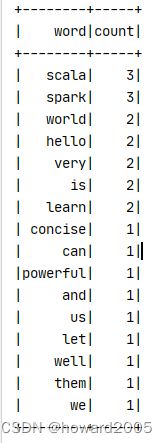
(二)实现任务
1、准备数据文件
- 在
/home目录创建words.txt
- 上传单词文件到HDFS指定目录

2、创建Maven项目
- 创建Maven项目 - SparkSQLWordCount

- 单击【Finish】按钮

3、修改源程序目录
- 将
java目录改成scala目录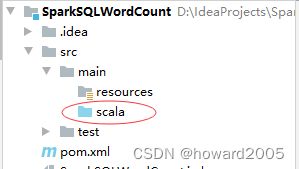
4、添加依赖和设置源程序目录
- 在
pom.xml文件里添加依赖和设置源程序目录
4.0.0
net.huawei.sql
SparkSQLWordCount
1.0-SNAPSHOT
org.scala-lang
scala-library
2.12.15
org.apache.spark
spark-core_2.12
3.1.3
org.apache.spark
spark-sql_2.12
3.1.3
src/main/scala
5、创建日志属性文件
- 在
resources目录里创建log4j.properties文件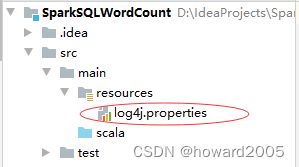
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6、创建HDFS配置文件
- 在
resources目录里创建hdfs-site.xml文件
only config in clients
dfs.client.use.datanode.hostname
true
7、创建词频统计单例对象
- 创建
net.huawei.sql包,在包里创建WordCount单例对象
package net.huawei.sql
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* 功能:利用Spark SQL实现词频统计
* 作者:华卫
* 日期:2023年05月25日
*/
object WordCount {
def main(args: Array[String]): Unit = {
// 创建或得到SparkSession
val spark = SparkSession.builder()
.appName("SparkSQLWordCount")
.master("local[*]")
.getOrCreate()
// 读取HDFS上的单词文件
val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/wordcount/input/words.txt")
// 显示数据集lines内容
lines.show()
// 导入Spark会话对象的隐式转换
import spark.implicits._
// 将数据集中的数据按空格切分并合并
val words: Dataset[String] = lines.flatMap(_.split(" "))
// 显示数据集words内容
words.show()
// 将数据集默认列名由value改为word,并转换成数据帧
val df = words.withColumnRenamed("value", "word").toDF()
// 显示数据帧内容
df.show()
// 基于数据帧创建临时视图
df.createTempView("v_words")
// 执行SQL分组查询,实现词频统计
val wc = spark.sql(
"""
| select word, count(*) as count
| from v_words group by word
| order by count desc
|""".stripMargin)
// 显示词频统计结果
wc.show()
// 关闭会话
spark.close()
}
}
8、启动程序,查看结果
- 运行
WordCount单例对象
9、词频统计数据转化流程图
- 文本文件,转化成数据集,再转化成数据帧,最后基于表查询得到结果数据帧

二、使用Spark SQL计算总分与平均分
(一)提出任务
-
有多科成绩表,比如python.txt、spark.txt、django.txt,计算每个学生三科总分与平均分
-
Python成绩表 -
python.txt
1 张三丰 89
2 李孟达 95
3 唐雨涵 92
4 王晓云 93
5 张晓琳 88
6 佟湘玉 88
7 杨文达 66
8 陈燕文 98
- Spark成绩表 -
spark.txt
1 张三丰 67
2 李孟达 78
3 唐雨涵 89
4 王晓云 75
5 张晓琳 93
6 佟湘玉 70
7 杨文达 87
8 陈燕文 90
- Django成绩表 -
django.txt
1 张三丰 88
2 李孟达 93
3 唐雨涵 97
4 王晓云 87
5 张晓琳 79
6 佟湘玉 89
7 杨文达 93
8 陈燕文 95
- 期望输出结果
1 张三丰 244 81.33
2 李孟达 266 88.67
3 唐雨涵 278 92.67
4 王晓云 255 85.00
5 张晓琳 260 86.67
6 佟湘玉 247 82.33
7 杨文达 246 82.00
8 陈燕文 283 94.33
(二)完成任务
1、准备数据文件
- 在
master虚拟机上创建三个成绩文件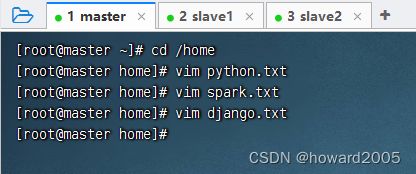
- 查看三个成绩文件内容
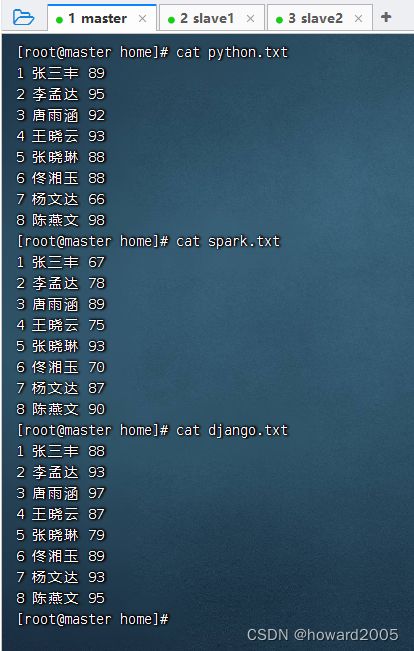
- 将三个成绩文件上传到HDFS的
/calsumavg/input目录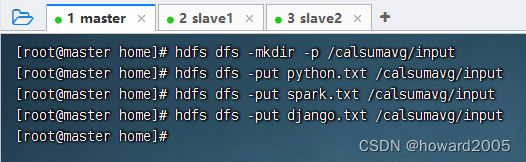
2、新建Maven项目
-
设置项目信息(项目名、保存位置、组编号、项目编号)
-
单击【Finish】按钮

3、修改源程序目录
- 将
java目录改成scala目录
4、添加相关依赖和设置源程序目录
- 在
pom.xml文件里添加依赖和设置源程序目录
4.0.0
net.huawei.sql
CalculateSumAvg
1.0-SNAPSHOT
org.scala-lang
scala-library
2.12.15
org.apache.spark
spark-core_2.12
3.1.3
org.apache.spark
spark-sql_2.12
3.1.3
src/main/scala
5、创建日志属性文件
- 在
resources里创建日志属性文件 -log4j.properties
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6、创建HDFS配置文件
- 在
resources目录里创建hdfs-site.xml文件
only config in clients
dfs.client.use.datanode.hostname
true
7、创建计算总分平均分单例对象
- 在
net.huawei.sql包里创建CalculateSumAverage单例对象
package net.huawei.sql
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* 功能:利用Spark SQL计算总分与平均分
* 作者:华卫
* 日期:2023年05月25日
*/
object CalculateSumAverage {
def main(args: Array[String]): Unit = {
// 创建或得到Spark会话对象
val spark = SparkSession.builder()
.appName("CalculateSumAverage")
.master("local[*]")
.getOrCreate()
// 读取HDFS上的成绩文件
val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/calsumavg/input")
// 导入隐式转换
import spark.implicits._
// 创建成绩数据集
val gradeDS: Dataset[Grade] = lines.map(
line => {
val fields = line.split(" ")
val id = fields(0).toInt
val name = fields(1)
val score = fields(2).toInt
Grade(id, name, score)
})
// 将数据集转换成数据帧
val df = gradeDS.toDF();
// 基于数据帧创建临时表
df.createOrReplaceTempView("t_grade")
// 查询临时表,计算总分与平均分
val result = spark.sql(
"""
|select first(id) as id, name, sum(score) as sum,
| cast(avg(score) as decimal(5, 2)) as average
| from t_grade
| group by name
| order by id
|""".stripMargin
)
// 按照指定格式输出总分与平均分
result.collect.foreach(row => println(row(0) + " " + row(1) + " " + row (2) + " " + row(3)))
// 关闭Spark会话
spark.close()
}
// 定义成绩样例类
case class Grade(id: Int, name: String, score: Int)
}
8、运行程序,查看结果
- 运行
CalculateSumAvg单例对象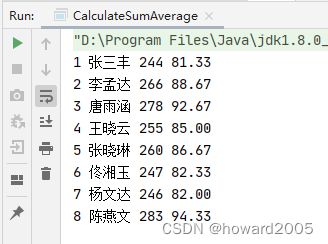
三、使用Spark SQL实现分组排行榜
(一)提出任务
- 分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
- 有一组学生成绩数据
张三丰 90
李孟达 85
张三丰 87
王晓云 93
李孟达 65
张三丰 76
王晓云 78
李孟达 60
张三丰 94
王晓云 97
李孟达 88
张三丰 80
王晓云 88
李孟达 82
王晓云 98
- 同一个学生有多门成绩,现需要计算每个学生分数最高的前3个成绩,期望输出结果
张三丰:94
张三丰:90
张三丰:87
李孟达:88
李孟达:85
李孟达:82
王晓云:98
王晓云:97
王晓云:93
- 数据表
t_grade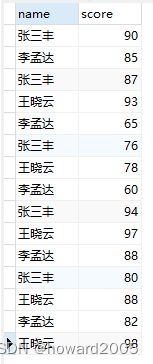
- 执行查询
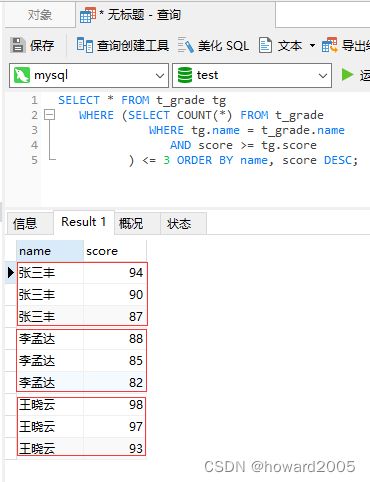
SELECT * FROM t_grade tg
WHERE (SELECT COUNT(*) FROM t_grade
WHERE tg.name = t_grade.name
AND score >= tg.score
) <= 3 ORDER BY name, score DESC;
(二)涉及知识点
1、数据集与数据帧
- 参看本博《Spark大数据处理讲课笔记4.1 Spark SQL概述、数据帧与数据集》
2、开窗函数
(1)开窗函数概述
Spark 1.5.x版本以后,在Spark SQL和DataFrame中引入了开窗函数,其中比较常用的开窗函数就是row_number(),该函数的作用是根据表中字段进行分组,然后根据表中的字段排序;其实就是根据其排序顺序,给组中的每条记录添加一个序号,且每组序号都是从1开始,可利用它这个特性进行分组取topN。
(2)开窗函数格式
ROW_NUMBER()OVER (PARTITION BYfield1ORDER BYfield2DESC) rank- 分组求top3的SQL语句

(三)完成任务
1、准备数据文件
- 在
/home目录里创建成绩文件grades.txt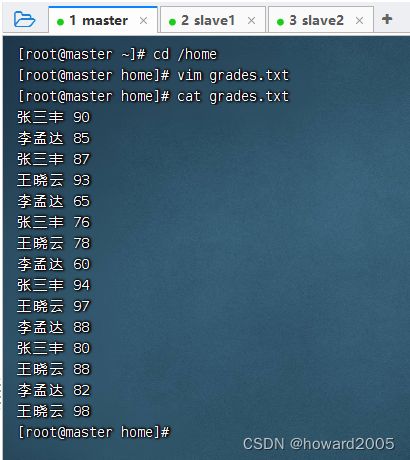
- 将
grades.txt上传到HDFS的/topn/input目录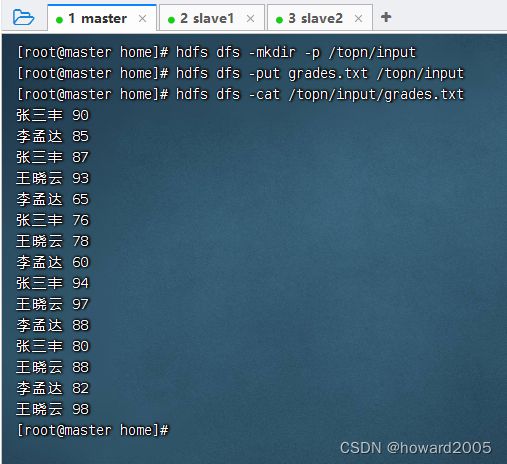
2、新建Maven项目
-
设置项目信息(项目名、保存位置、组编号、项目编号)

-
单击【Finish】按钮

3、修改源程序目录
- 将
java目录改成scala目录
4、添加相关依赖和设置源程序目录
- 在
pom.xml文件里添加依赖和设置源程序目录
4.0.0
net.huawei.sql
SparkSQLGradeTopN
1.0-SNAPSHOT
org.scala-lang
scala-library
2.12.15
org.apache.spark
spark-core_2.12
3.1.3
org.apache.spark
spark-sql_2.12
3.1.3
src/main/scala
5、创建日志属性文件
- 在
resources目录里创建log4j.properties文件
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6、创建HDFS配置文件
- 在
resources目录里创建hdfs-site.xml文件
only config in clients
dfs.client.use.datanode.hostname
true
7、创建分组排行榜单例对象
- 在
net.huawei.sql包里创建GradeTopN单例对象
package net.huawei.sql
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* 功能:利用Spark SQL实现分组排行榜
* 作者:华卫
* 日期:2022年06月15日
*/
object GradeTopNBySQL {
def main(args: Array[String]): Unit = {
// 创建或得到Spark会话对象
val spark = SparkSession.builder()
.appName("GradeTopNBySQL")
.master("local[*]")
.getOrCreate()
// 读取HDFS上的成绩文件
val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/input/grades.txt")
// 导入隐式转换
import spark.implicits._
// 创建成绩数据集
val gradeDS: Dataset[Grade] = lines.map(
line => { val fields = line.split(" ")
val name = fields(0)
val score = fields(1).toInt
Grade(name, score)
})
// 将数据集转换成数据帧
val df = gradeDS.toDF()
// 基于数据帧创建临时表
df.createOrReplaceTempView("t_grade")
// 查询临时表,实现分组排行榜
val top3 = spark.sql(
"""
|SELECT name, score FROM
| (SELECT name, score, row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""".stripMargin
)
// 按指定格式输出分组排行榜
top3.foreach(row => println(row(0) + ": " + row(1)))
// 关闭Spark会话
spark.close()
}
// 定义成绩样例类
case class Grade(name: String, score: Int)
}
8、运行程序,查看结果
- 运行
GradeTopN单例对象
四、使用SparkSQL统计每日新增用户
(一)提出任务
- 已知有以下用户访问历史数据,第一列为用户访问网站的日期,第二列为用户名。
2023-05-01,mike
2023-05-01,alice
2023-05-01,brown
2023-05-02,mike
2023-05-02,alice
2023-05-02,green
2023-05-03,alice
2023-05-03,smith
2023-05-03,brian
| 2023-05-01 | mike | alice | brown |
| 2023-05-02 | mike | alice | green |
| 2023-05-03 | alice | smith | brian |
- 现需要根据上述数据统计每日新增的用户数量,期望统计结果。
2023-05-01新增用户数:3
2023-05-02新增用户数:1
2023-05-03新增用户数:2
- 1
- 2
- 3
- 即2023-05-01新增了3个用户(分别为mike、alice、brown),2023-05-02新增了1个用户(green),2023-05-03新增了两个用户(分别为smith、brian)。
(二)实现思路
- 使用倒排索引法,若将用户名看作关键词,访问日期看作文档ID,则用户名与访问日期的映射关系如下图所示。
| 2023-05-01 | 2023-05-02 | 2023-05-3 | |
|---|---|---|---|
| mike | √ | √ | |
| alice | √ | √ | √ |
| brown | √ | ||
| green | √ | ||
| smith | √ | ||
| brian | √ |
- 若同一个用户对应多个访问日期,则最小的日期为该用户的注册日期,即新增日期,其他日期为重复访问日期,不应统计在内。因此每个用户应该只计算用户访问的最小日期即可。如下图所示,将每个用户访问的最小日期都移到第一列,第一列为有效数据,只统计第一列中每个日期的出现次数,即为对应日期的新增用户数。
| 列一 | 列二 | 列三 | |
|---|---|---|---|
| mike | 2023-05-01 | 2023-05-02 | |
| alice | 2023-05-01 | 2022-01-02 | 2022-01-03 |
| brown | 2023-05-01 | ||
| green | 2023-05-02 | ||
| smith | 2023-05-03 | ||
| brian | 2023-05-03 |
(三)完成任务
1、准备数据文件
- 在
/home目录里创建users.txt文件
- 先创建
/newusers/input目录,再将用户文件上传到该目录
2、新建Maven项目
- 设置项目信息(项目名、保存位置、组编号、项目编号)
- 单击【Finish】按钮

- 将
java目录改成scala目录
4、添加相关依赖和设置源程序目录
- 在
pom.xml文件里添加依赖和设置源程序目录
4.0.0
net.huawei.sql
SparkSQLCountNewUsers
1.0-SNAPSHOT
org.scala-lang
scala-library
2.12.15
org.apache.spark
spark-core_2.12
3.1.3
org.apache.spark
spark-sql_2.12
3.1.3
src/main/scala
5、创建日志属性文件
- 在
resources目录里创建log4j.properties文件
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6、创建HDFS配置文件
- 在
resources目录里创建hdfs-site.xml文件
only config in clients
dfs.client.use.datanode.hostname
true
7、创建统计新增用户单例对象
- 创建
net.huawei.sql包,在包里创建CountNewUsers单例对象
package net.huawei.sql
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* 功能:使用SparkSQL统计新增用户
* 作者:华卫
* 日期:2023年05月25日
*/
object CountNewUsers {
def main(args: Array[String]): Unit = {
def main(args: Array[String]): Unit = {
// 创建或得到Spark会话对象
val spark = SparkSession.builder()
.appName("CountNewUsers")
.master("local[*]")
.getOrCreate()
// 读取HDFS上的用户文件
val ds: Dataset[String] = spark.read.textFile("hdfs://master:9000/newusers/input/users.txt")
// 导入隐式转换
import spark.implicits._
// 创建用户数据集
val userDS: Dataset[User] = ds.map(
line => {
val fields = line.split(",")
val date = fields(0)
val name = fields(1)
User(date, name)
}
)
//将数据转换成数据帧
val df = userDS.toDF()
// 创建临时表
df.createOrReplaceTempView("t_user")
// 统计每日新增用户
val result = spark.sql(
"""
|select date, count(name) as count from
| (select min(date) as date, name from t_user group by name)
|group by date
|""".stripMargin
)
// 输出统计结果
result.foreach(row => println(row(0) + "新增用户数:" + row(1)))
// 关闭Spark会话
spark.close()
}
}
//编写User样例类
case class User(date: String, name: String)
}
8、运行程序,查看结果
- 运行
CountNewUsers单例对象
- 很奇怪,没有显示统计结果
9、在Spark Shell里运行代码
- 执行如下代码,查看结果