TextRank算法的基本原理及textrank4zh使用实例
原地址:https://blog.csdn.net/wotui1842/article/details/80351386
TextRank算法是一种文本排序算法,由谷歌的网页重要性排序算法PageRank算法改进而来,它能够从一个给定的文本中提取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法提取出该文本的关键句。其提出论文是: Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004. 论文的百度学术下载地址为:点击打开链接。本文将首先介绍TextRank算法的基本原理,然后给出Python中TextRank算法的中文文本实现模块textrank4zh的使用实例。
1 TextRank算法的基本原理
TextRank算法是由网页重要性排序算法PageRank算法迁移而来:PageRank算法根据万维网上页面之间的链接关系计算每个页面的重要性;TextRank算法将词视为“万维网上的节点”,根据词之间的共现关系计算每个词的重要性,并将PageRank中的有向边变为无向边。所以,在介绍TextRank算法之前,先介绍一下PageRank算法。
1.1 PageRank算法的基本概念和原理
PageRank算法的起源要从搜索引擎的发展讲起。早期的搜索引擎普遍采用分类目录方法,即通过人工对网页进行分类,整理出高质量的网站。随着网页的增多,人工分类的方法变得不现实,人们开始尝试使用文本检索的方法,即通过计算用户查询的关键词与网页内容的相关程度来返回搜索结果。这种方法突破了网页数量的限制,但是这种方法的效果并不总是很好,因为某些网站会刻意“操作”某些关键词从而使自己的搜索排名靠前。这一问题在1998年4月的第七届国际万维网大会上得以解决——Larry Page和Sergey Brin提出了PageRank算法。该算法通过计算网页链接的数量和质量来粗略估计网页的重要性,算法创立之初即应用在谷歌的搜索引擎中,对网页进行排名。
PageRank算法的核心思想如下:
- 如果一个网页被很多其他网页链接到,说明这个网页比较重要,即该网页的PR值(PageRank值)会相对较高;
- 如果一个PR值很高的网页链接到一个其他网页,那么被链接到的网页的PR值会相应地因此而提高。
以投票机制的观点来看,一个网页的得票数由所有链向它的网页的得票数经过递归算法来得到,有到一个网页的超链接相当于对该网页投了一票。
为了便于理解,考虑以下情境:
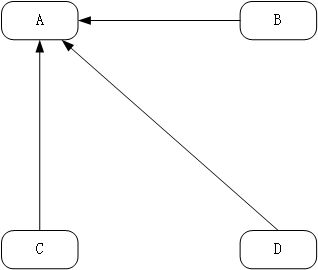
1)如上左图,假设一个只由4个网页组成的集合:A、B、C和D,如果网页B、C、D都链向网页A,且网页B、C、D均没有链出,那么网页A的PR值将是网页B、C、D的PR值之和:

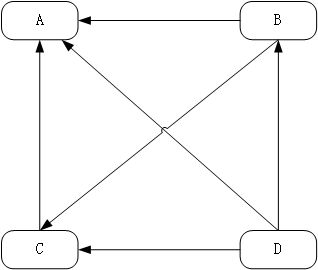
2)如上右图,继续假设在上述情境下,网页B有链接链向网页C,网页D有链接链向网页A、B、C,一个网页不能多次投票,所以网页B投给它链向的网页1/2票,网页D投给它链向的网页1/3票,计算此情境下网页A的PR值为:
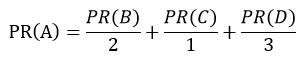
即,在一个网页为其他网页投票时,根据链出总数平分该网页的PR值,将其作为该网页为其链向网页所投票数,即:

3)再抽象一下,建立一个简化模型,对于任意的网页i,它的PR值可以表示如下:

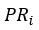 :网页i的PR值
:网页i的PR值
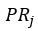 :网页j的PR值
:网页j的PR值
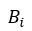 :所有链接到网页i的网页集合
:所有链接到网页i的网页集合
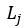 :网页j的对外链出数
:网页j的对外链出数
以上讲的是PageRank算法的简单模型,但是简单模型并不适用于只链出自己的网页或几个网页的链出形成一个循环的情况,所以考虑更具普遍性的PageRank算法模型——随机浏览模型。
随机浏览模型的假设是这样的:假定一个网页浏览者从一个随机页面开始浏览,浏览者不断点击当前网页的链接开始下一次浏览。但是,浏览者会逐渐厌倦并开始随机浏览网页。随机浏览的方式更符合用户的真实浏览行为,避免了上述情况的发生,由此产生了随机浏览模型,随机浏览模型中每个网页的PR值通过以下公式计算:
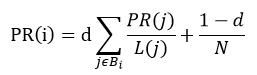
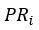 :网页i的PR值
:网页i的PR值
 :网页j的PR值
:网页j的PR值
 :网页j的对外链出数
:网页j的对外链出数
 :所有链接到网页i的网页集合
:所有链接到网页i的网页集合
 :网络中网页的总数
:网络中网页的总数
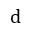 :阻尼系数,即按照超链接进行浏览的概率,一般取经验值为0.85
:阻尼系数,即按照超链接进行浏览的概率,一般取经验值为0.85
 :浏览者随机跳转到一个新网页的概率
:浏览者随机跳转到一个新网页的概率
一个网页的PR值是由其他网页的PR值计算得到的。由于PR=A*PR(A为概率转移矩阵)满足马尔科夫链的性质,那么通过迭代可以得到所有网页的PR值。经过重复计算,这些网页的PR值会趋于正常和稳定。
随着研究的深入,目前PageRank算法被广泛应用于众多方面,例如学术论文的重要性排名、学术论文作者的重要性排序、网络爬虫、关键词与关键句的抽取等。
1.2 从PageRank算法到TextRank算法
TextRank算法是由PageRank算法改进而来的,二者的思想有相同之处,区别在于:PageRank算法根据网页之间的链接关系构造网络,而TextRank算法根据词之间的共现关系构造网络;PageRank算法构造的网络中的边是有向无权边,而TextRank算法构造的网络中的边是无向有权边。TextRank算法的核心公式如下,其中 用于表示两个节点之间的边连接具有不同的重要程度:
用于表示两个节点之间的边连接具有不同的重要程度:

为了便于理解,给出使用TextRank算法提取关键词和关键词组的具体步骤如下:
1)将给定的文本按照整句进行分割,即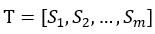 ;
;
2)对于每个句子 ,对其进行分词和词性标注,然后剔除停用词,只保留指定词性的词,如名词、动词、形容词等,即
,对其进行分词和词性标注,然后剔除停用词,只保留指定词性的词,如名词、动词、形容词等,即 ,其中
,其中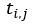 为句子i中保留下的词;
为句子i中保留下的词;
3)构建词图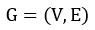 ,其中V为节点集合,由以上步骤生成的词组成,然后采用共现关系构造任意两个节点之间的边:两个节点之间存在边仅当它们对应的词在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词,一般K取2;
,其中V为节点集合,由以上步骤生成的词组成,然后采用共现关系构造任意两个节点之间的边:两个节点之间存在边仅当它们对应的词在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词,一般K取2;
4)根据上面的公式,迭代计算各节点的权重,直至收敛;
5)对节点的权重进行倒序排序,从中得到最重要的t个单词,作为top-t关键词;
6)对于得到的top-t关键词,在原始文本中进行标记,若它们之间形成了相邻词组,则作为关键词组提取出来。
从给定文本中提取关键句时,将文本中的每个句子分别看作一个节点,如果两个句子有相似性,则认为这两个句子对应的节点之间存在一条无向有权边,衡量句子之间相似性的公式如下:

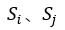 :两个句子
:两个句子
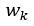 :句子中的词
:句子中的词
分子部分的意思是同时出现在两个句子中的同一个词的数量,分母是对句子中词的个数求对数后求和,这样设计可以遏制较长的句子在相似度计算上的优势。
根据以上相似度计算公式循环计算任意两个节点之间的相似度,设置阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后迭代计算每个节点的TextRank值,排序后选出TextRank值最高的几个节点对应的句子作为关键句。
1.3 textrank4zh模块源码解读
textrank4zh模块是针对中文文本的TextRank算法的python算法实现,该模块的下载地址为:点击打开链接
对其源码解读如下:
util.py:textrank4zh模块的工具包,TextRank算法的核心思想在该文件中实现。
# -*- encoding:utf-8 -*-
"""
@author: letian
@homepage: http://www.letiantian.me
@github: https://github.com/someus/
"""
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import os
import math
import networkx as nx
import numpy as np
import sys
try:
reload(sys)
sys.setdefaultencoding('utf-8')
except:
pass
sentence_delimiters = ['?', '!', ';', '?', '!', '。', ';', '……', '…', '\n']
allow_speech_tags = ['an', 'i', 'j', 'l', 'n', 'nr', 'nrfg', 'ns', 'nt', 'nz', 't', 'v', 'vd', 'vn', 'eng']
PY2 = sys.version_info[0] == 2
if not PY2:
# Python 3.x and up
text_type = str
string_types = (str,)
xrange = range
def as_text(v): ## 生成unicode字符串
if v is None:
return None
elif isinstance(v, bytes):
return v.decode('utf-8', errors='ignore')
elif isinstance(v, str):
return v
else:
raise ValueError('Unknown type %r' % type(v))
def is_text(v):
return isinstance(v, text_type)
else:
# Python 2.x
text_type = unicode
string_types = (str, unicode)
xrange = xrange
def as_text(v):
if v is None:
return None
elif isinstance(v, unicode):
return v
elif isinstance(v, str):
return v.decode('utf-8', errors='ignore')
else:
raise ValueError('Invalid type %r' % type(v))
def is_text(v):
return isinstance(v, text_type)
__DEBUG = None
def debug(*args):
global __DEBUG
if __DEBUG is None:
try:
if os.environ['DEBUG'] == '1':
__DEBUG = True
else:
__DEBUG = False
except:
__DEBUG = False
if __DEBUG:
print(' '.join([str(arg) for arg in args]))
class AttrDict(dict):
"""Dict that can get attribute by dot"""
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
def combine(word_list, window=2):
"""构造在window下的单词组合,用来构造单词之间的边。
Keyword arguments:
word_list -- list of str, 由单词组成的列表。
windows -- int, 窗口大小。
"""
if window < 2: window = 2
for x in xrange(1, window):
if x >= len(word_list):
break
word_list2 = word_list[x:]
res = zip(word_list, word_list2)
for r in res:
yield r
def get_similarity(word_list1, word_list2):
"""默认的用于计算两个句子相似度的函数。
Keyword arguments:
word_list1, word_list2 -- 分别代表两个句子,都是由单词组成的列表
"""
words = list(set(word_list1 + word_list2))
vector1 = [float(word_list1.count(word)) for word in words]
vector2 = [float(word_list2.count(word)) for word in words]
vector3 = [vector1[x] * vector2[x] for x in xrange(len(vector1))]
vector4 = [1 for num in vector3 if num > 0.]
co_occur_num = sum(vector4)
if abs(co_occur_num) <= 1e-12:
return 0.
denominator = math.log(float(len(word_list1))) + math.log(float(len(word_list2))) # 分母
if abs(denominator) < 1e-12:
return 0.
return co_occur_num / denominator
def sort_words(vertex_source, edge_source, window=2, pagerank_config={'alpha': 0.85, }):
"""将单词按关键程度从大到小排序
Keyword arguments:
vertex_source -- 二维列表,子列表代表句子,子列表的元素是单词,这些单词用来构造pagerank中的节点
edge_source -- 二维列表,子列表代表句子,子列表的元素是单词,根据单词位置关系构造pagerank中的边
window -- 一个句子中相邻的window个单词,两两之间认为有边
pagerank_config -- pagerank的设置
"""
sorted_words = []
word_index = {}
index_word = {}
_vertex_source = vertex_source
_edge_source = edge_source
words_number = 0
for word_list in _vertex_source:
for word in word_list:
if not word in word_index:
word_index[word] = words_number
index_word[words_number] = word
words_number += 1
graph = np.zeros((words_number, words_number))
for word_list in _edge_source:
for w1, w2 in combine(word_list, window):
if w1 in word_index and w2 in word_index:
index1 = word_index[w1]
index2 = word_index[w2]
graph[index1][index2] = 1.0
graph[index2][index1] = 1.0
debug('graph:\n', graph)
nx_graph = nx.from_numpy_matrix(graph)
scores = nx.pagerank(nx_graph, **pagerank_config) # this is a dict
sorted_scores = sorted(scores.items(), key=lambda item: item[1], reverse=True)
for index, score in sorted_scores:
item = AttrDict(word=index_word[index], weight=score)
sorted_words.append(item)
return sorted_words
def sort_sentences(sentences, words, sim_func=get_similarity, pagerank_config={'alpha': 0.85, }):
"""将句子按照关键程度从大到小排序
Keyword arguments:
sentences -- 列表,元素是句子
words -- 二维列表,子列表和sentences中的句子对应,子列表由单词组成
sim_func -- 计算两个句子的相似性,参数是两个由单词组成的列表
pagerank_config -- pagerank的设置
"""
sorted_sentences = []
_source = words
sentences_num = len(_source)
graph = np.zeros((sentences_num, sentences_num))
for x in xrange(sentences_num):
for y in xrange(x, sentences_num):
similarity = sim_func(_source[x], _source[y])
graph[x, y] = similarity
graph[y, x] = similarity
nx_graph = nx.from_numpy_matrix(graph)
scores = nx.pagerank(nx_graph, **pagerank_config) # this is a dict
sorted_scores = sorted(scores.items(), key=lambda item: item[1], reverse=True)
for index, score in sorted_scores:
item = AttrDict(index=index, sentence=sentences[index], weight=score)
sorted_sentences.append(item)
return sorted_sentences
if __name__ == '__main__':
pass
Segmentation.py:包含用于分词和分句的类。
# -*- encoding:utf-8 -*-
"""
@author: letian
@homepage: http://www.letiantian.me
@github: https://github.com/someus/
"""
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import os
import math
import networkx as nx
import numpy as np
import sys
try:
reload(sys)
sys.setdefaultencoding('utf-8')
except:
pass
sentence_delimiters = ['?', '!', ';', '?', '!', '。', ';', '……', '…', '\n']
allow_speech_tags = ['an', 'i', 'j', 'l', 'n', 'nr', 'nrfg', 'ns', 'nt', 'nz', 't', 'v', 'vd', 'vn', 'eng']
PY2 = sys.version_info[0] == 2
if not PY2:
# Python 3.x and up
text_type = str
string_types = (str,)
xrange = range
def as_text(v): ## 生成unicode字符串
if v is None:
return None
elif isinstance(v, bytes):
return v.decode('utf-8', errors='ignore')
elif isinstance(v, str):
return v
else:
raise ValueError('Unknown type %r' % type(v))
def is_text(v):
return isinstance(v, text_type)
else:
# Python 2.x
text_type = unicode
string_types = (str, unicode)
xrange = xrange
def as_text(v):
if v is None:
return None
elif isinstance(v, unicode):
return v
elif isinstance(v, str):
return v.decode('utf-8', errors='ignore')
else:
raise ValueError('Invalid type %r' % type(v))
def is_text(v):
return isinstance(v, text_type)
__DEBUG = None
def debug(*args):
global __DEBUG
if __DEBUG is None:
try:
if os.environ['DEBUG'] == '1':
__DEBUG = True
else:
__DEBUG = False
except:
__DEBUG = False
if __DEBUG:
print(' '.join([str(arg) for arg in args]))
class AttrDict(dict):
"""Dict that can get attribute by dot"""
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
def combine(word_list, window=2):
"""构造在window下的单词组合,用来构造单词之间的边。
Keyword arguments:
word_list -- list of str, 由单词组成的列表。
windows -- int, 窗口大小。
"""
if window < 2: window = 2
for x in xrange(1, window):
if x >= len(word_list):
break
word_list2 = word_list[x:]
res = zip(word_list, word_list2)
for r in res:
yield r
def get_similarity(word_list1, word_list2):
"""默认的用于计算两个句子相似度的函数。
Keyword arguments:
word_list1, word_list2 -- 分别代表两个句子,都是由单词组成的列表
"""
words = list(set(word_list1 + word_list2))
vector1 = [float(word_list1.count(word)) for word in words]
vector2 = [float(word_list2.count(word)) for word in words]
vector3 = [vector1[x] * vector2[x] for x in xrange(len(vector1))]
vector4 = [1 for num in vector3 if num > 0.]
co_occur_num = sum(vector4)
if abs(co_occur_num) <= 1e-12:
return 0.
denominator = math.log(float(len(word_list1))) + math.log(float(len(word_list2))) # 分母
if abs(denominator) < 1e-12:
return 0.
return co_occur_num / denominator
def sort_words(vertex_source, edge_source, window=2, pagerank_config={'alpha': 0.85, }):
"""将单词按关键程度从大到小排序
Keyword arguments:
vertex_source -- 二维列表,子列表代表句子,子列表的元素是单词,这些单词用来构造pagerank中的节点
edge_source -- 二维列表,子列表代表句子,子列表的元素是单词,根据单词位置关系构造pagerank中的边
window -- 一个句子中相邻的window个单词,两两之间认为有边
pagerank_config -- pagerank的设置
"""
sorted_words = []
word_index = {}
index_word = {}
_vertex_source = vertex_source
_edge_source = edge_source
words_number = 0
for word_list in _vertex_source:
for word in word_list:
if not word in word_index:
word_index[word] = words_number
index_word[words_number] = word
words_number += 1
graph = np.zeros((words_number, words_number))
for word_list in _edge_source:
for w1, w2 in combine(word_list, window):
if w1 in word_index and w2 in word_index:
index1 = word_index[w1]
index2 = word_index[w2]
graph[index1][index2] = 1.0
graph[index2][index1] = 1.0
debug('graph:\n', graph)
nx_graph = nx.from_numpy_matrix(graph)
scores = nx.pagerank(nx_graph, **pagerank_config) # this is a dict
sorted_scores = sorted(scores.items(), key=lambda item: item[1], reverse=True)
for index, score in sorted_scores:
item = AttrDict(word=index_word[index], weight=score)
sorted_words.append(item)
return sorted_words
def sort_sentences(sentences, words, sim_func=get_similarity, pagerank_config={'alpha': 0.85, }):
"""将句子按照关键程度从大到小排序
Keyword arguments:
sentences -- 列表,元素是句子
words -- 二维列表,子列表和sentences中的句子对应,子列表由单词组成
sim_func -- 计算两个句子的相似性,参数是两个由单词组成的列表
pagerank_config -- pagerank的设置
"""
sorted_sentences = []
_source = words
sentences_num = len(_source)
graph = np.zeros((sentences_num, sentences_num))
for x in xrange(sentences_num):
for y in xrange(x, sentences_num):
similarity = sim_func(_source[x], _source[y])
graph[x, y] = similarity
graph[y, x] = similarity
nx_graph = nx.from_numpy_matrix(graph)
scores = nx.pagerank(nx_graph, **pagerank_config) # this is a dict
sorted_scores = sorted(scores.items(), key=lambda item: item[1], reverse=True)
for index, score in sorted_scores:
item = AttrDict(index=index, sentence=sentences[index], weight=score)
sorted_sentences.append(item)
return sorted_sentences
if __name__ == '__main__':
pass
TextRank4Sentence.py:包含用于提取关键句的类。
# -*- encoding:utf-8 -*-
"""
@author: letian
@homepage: http://www.letiantian.me
@github: https://github.com/someus/
"""
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import networkx as nx
import numpy as np
from . import util
from .Segmentation import Segmentation
class TextRank4Sentence(object):
def __init__(self, stop_words_file=None,
allow_speech_tags=util.allow_speech_tags,
delimiters=util.sentence_delimiters):
"""
Keyword arguments:
stop_words_file -- str,停止词文件路径,若不是str则是使用默认停止词文件
delimiters -- 默认值是`?!;?!。;…\n`,用来将文本拆分为句子。
Object Var:
self.sentences -- 由句子组成的列表。
self.words_no_filter -- 对sentences中每个句子分词而得到的两级列表。
self.words_no_stop_words -- 去掉words_no_filter中的停止词而得到的两级列表。
self.words_all_filters -- 保留words_no_stop_words中指定词性的单词而得到的两级列表。
"""
self.seg = Segmentation(stop_words_file=stop_words_file,
allow_speech_tags=allow_speech_tags,
delimiters=delimiters)
self.sentences = None
self.words_no_filter = None # 2维列表
self.words_no_stop_words = None
self.words_all_filters = None
self.key_sentences = None
def analyze(self, text, lower=False,
source='no_stop_words',
sim_func=util.get_similarity,
pagerank_config={'alpha': 0.85, }):
"""
Keyword arguments:
text -- 文本内容,字符串。
lower -- 是否将文本转换为小写。默认为False。
source -- 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来生成句子之间的相似度。
默认值为`'all_filters'`,可选值为`'no_filter', 'no_stop_words', 'all_filters'`。
sim_func -- 指定计算句子相似度的函数。
"""
self.key_sentences = []
result = self.seg.segment(text=text, lower=lower)
self.sentences = result.sentences
self.words_no_filter = result.words_no_filter
self.words_no_stop_words = result.words_no_stop_words
self.words_all_filters = result.words_all_filters
options = ['no_filter', 'no_stop_words', 'all_filters']
if source in options:
_source = result['words_' + source]
else:
_source = result['words_no_stop_words']
self.key_sentences = util.sort_sentences(sentences=self.sentences,
words=_source,
sim_func=sim_func,
pagerank_config=pagerank_config)
def get_key_sentences(self, num=6, sentence_min_len=6):
"""获取最重要的num个长度大于等于sentence_min_len的句子用来生成摘要。
Return:
多个句子组成的列表。
"""
result = []
count = 0
for item in self.key_sentences:
if count >= num:
break
if len(item['sentence']) >= sentence_min_len:
result.append(item)
count += 1
return result
if __name__ == '__main__':
pass
2 textrank4zh模块的使用
2.1 textrank4zh模块的安装
这里介绍几种安装Python模块的方法,仅供参考。
1)python setup.py install --user
2)sudo python setup.py install
3)pip install textrank4zh --user
4)sudo pip install textrank4zh
textrank4zh模块在python2或python3中均可使用,它所依赖的其他模块要求满足:
jieba >= 0.35; numpy >= 1.7.1;networkx >= 1.9.1
2.2 textrank4zh的使用实例
因为操作比较简单,所有直接以代码的形式展示例子,代码在python3环境下亲测可用。
1)提取关键词、关键短语和关键句
#-*-coding:utf-8-*-
"""
@author:taoshouzheng
@time:2018/5/18 8:20
@email:[email protected]
"""
# 导入系统模块
import sys
# imp模块提供了一个可以实现import语句的接口
from imp import reload
# 异常处理
try:
# reload方法用于对已经加载的模块进行重新加载,一般用于原模块有变化的情况
reload(sys)
# 设置系统的默认编码方式,仅本次有效,因为setdefaultencoding函数在被系统调用后即被删除
sys.setdefaultencoding('utf-8')
except:
pass
"""
展示textrank4zh模块的主要功能:
提取关键词
提取关键短语(关键词组)
提取摘要(关键句)
"""
# 导入编码转换模块
import codecs
# 从textrank4zh模块中导入提取关键词和生成摘要的类
from textrank4zh import TextRank4Keyword, TextRank4Sentence
# 待读取的文本文件,一则新闻
file = r'C:\Users\Tao Shouzheng\Desktop\01.txt'
# 打开并读取文本文件
text = codecs.open(file, 'r', 'utf-8').read()
# 创建分词类的实例
tr4w = TextRank4Keyword()
# 对文本进行分析,设定窗口大小为2,并将英文单词小写
tr4w.analyze(text=text, lower=True, window=2)
"""输出"""
print('关键词为:')
# 从关键词列表中获取前20个关键词
for item in tr4w.get_keywords(num=20, word_min_len=1):
# 打印每个关键词的内容及关键词的权重
print(item.word, item.weight)
print('\n')
print('关键短语为:')
# 从关键短语列表中获取关键短语
for phrase in tr4w.get_keyphrases(keywords_num=20, min_occur_num=2):
print(phrase)
print('\n')
# 创建分句类的实例
tr4s = TextRank4Sentence()
# 英文单词小写,进行词性过滤并剔除停用词
tr4s.analyze(text=text, lower=True, source='all_filters')
print('摘要为:')
# 抽取3条句子作为摘要
for item in tr4s.get_key_sentences(num=3):
# 打印句子的索引、权重和内容
print(item.index, item.weight, item.sentence)结果如下:
关键词为:
媒体 0.02155864734852778
高圆圆 0.020220281898126486
微 0.01671909730824073
宾客 0.014328439104001788
赵又廷 0.014035488254875914
答谢 0.013759845912857732
谢娜 0.013361244496632448
现身 0.012724133346018603
记者 0.01227742092899235
新人 0.01183128428494362
北京 0.011686712993089671
博 0.011447168887452668
展示 0.010889176260920504
捧场 0.010507502237123278
礼物 0.010447275379792245
张杰 0.009558332870902892
当晚 0.009137982757893915
戴 0.008915271161035208
酒店 0.00883521621207796
外套 0.008822082954131174
关键短语为:
微博
摘要为:
0 0.07097195571711616 中新网北京12月1日电(记者 张曦) 30日晚,高圆圆和赵又廷在京举行答谢宴,诸多明星现身捧场,其中包括张杰(微博)、谢娜(微博)夫妇、何炅(微博)、蔡康永(微博)、徐克、张凯丽、黄轩(微博)等
6 0.05410372364148859 高圆圆身穿粉色外套,看到大批记者在场露出娇羞神色,赵又廷则戴着鸭舌帽,十分淡定,两人快步走进电梯,未接受媒体采访
27 0.04904283129838876 记者了解到,出席高圆圆、赵又廷答谢宴的宾客近百人,其中不少都是女方的高中同学
2)展示textrank4zh模块的三种分词模式的效果
三种分词模式分别为:
words_no_filter模式:简单分词,不剔除停用词,不进行词性过滤
words_no_stop_words模式:剔除停用词
words_all_filters模式(默认):即剔除停用词,又进行词性过滤
#-*-coding:utf-8-*-
"""
@author:taoshouzheng
@time:2018/5/18 14:52
@email:[email protected]
"""
import codecs
from imp import reload
from textrank4zh import TextRank4Keyword, TextRank4Sentence
import sys
try:
reload(sys)
sys.setdefaultencoding('utf-8')
except:
pass
"""测试3类分词的效果"""
text = '这间酒店位于北京东三环,里面摆放很多雕塑,文艺气息十足。答谢宴于晚上8点开始。'
tr4w = TextRank4Keyword()
tr4w.analyze(text=text, lower=True, window=2)
# 将文本划分为句子列表
print('sentences:')
for s in tr4w.sentences:
print(s)
print('\n')
# 对句子列表中的句子进行分词,不进行词性过滤
print('words_no_filter:')
# words为词列表,tr4w.words_no_filter为由词列表组成的列表
for words in tr4w.words_no_filter:
print('/'.join(words))
print('\n')
# 打印去掉停用词的词列表
print('words_no_stop_words:')
for words in tr4w.words_no_stop_words:
print('/'.join(words))
print('\n')
# 打印去掉停用词并进行词性过滤之后的词列表
print('words_all_filters:')
for words in tr4w.words_all_filters:
print('/'.join(words))
结果如下:
sentences:
这间酒店位于北京东三环,里面摆放很多雕塑,文艺气息十足
答谢宴于晚上8点开始
words_no_filter:
这/间/酒店/位于/北京/东三环/里面/摆放/很多/雕塑/文艺/气息/十足
答谢/宴于/晚上/8/点/开始
words_no_stop_words:
间/酒店/位于/北京/东三环/里面/摆放/很多/雕塑/文艺/气息/十足
答谢/宴于/晚上/8/点
words_all_filters:
酒店/位于/北京/东三环/摆放/雕塑/文艺/气息
答谢/宴于/晚上
在本文的写作过程中,参考了一些文章或帖子,附上链接如下:
1)python中jieba分词快速入门:点击打开链接
2)jieba(结巴)分词种词性简介:点击打开链接
3)TextRank算法:点击打开链接
4)PageRank算法 到 textRank:点击打开链接
5)PageRank排序算法详细介绍:点击打开链接
6)PageRank:点击打开链接
7)PageRank算法--从原理到实现:点击打开链接
8)Textrank算法介绍:点击打开链接
9)关键词提取算法-TextRank:点击打开链接
10)最全中文停用词表整理(1893个):点击打开链接
11)中文文本提取关键词、关键词组、关键句(textrank4zh使用)--python学习:点击打开链接
12)谷歌背后的数学:点击打开链接