【博弈论笔记】第四章 重复博弈
文章目录
- 第四章 重复博弈
-
- 4.1 重复博弈引论
-
- 4.1.1 重复博弈定义和意义
- 4.1.2 重复博弈的基本概念
- 4.2 有限次重复博弈
-
- 4.2.1 两人零和博弈的有限次重复博弈
- 4.2.2 唯一纯策略纳什均衡博弈的有限次重复博弈
- 4.2.3 多个纯策略纳什均衡博弈的有限次重复博弈
- 4.2.4 有限次重复博弈的民间定理
- 4.3 无限次重复博弈
-
- 4.3.1 两人零和博弈的无限次重复博弈
- 4.3.2 唯一纯策略纳什均衡博弈的无限次重复博弈
- 4.3.3 无限次重复古诺模型
- 4.3.4 有效工资率博弈
- Summary
此部分博弈论笔记参考自经济博弈论(第四版)/谢识予和老师的PPT,是在平时学习中以及期末备考中整理的,主要注重对本章节知识点的梳理以及重点知识的理解,细节和逻辑部分还不是很完善,可能不太适合初学者阅读(看书应该会理解的更明白O(∩_∩)O哈哈~)。现更新到博客上供大家浏览,希望能够帮助到正在学习博弈论的大家。
第四章 重复博弈
4.1 重复博弈引论
4.1.1 重复博弈定义和意义
定义:给定一个基本博弈G(静态博弈或动态博弈),重复进行T次,每次重复G时博弈方都能观察到以前的博弈结果,这样的博弈过程称为“G的T次重复博弈”,记为G(T)。
分类:
- 有限次重复博弈:预先知道重复次数,有明确结束时间
- 无限次重复博弈:重复博弈在理论上可以无限制重复进行下去,则称为“无限次重复博弈”,记为G(∞)
- 随机结束的重复博弈:重复次数或结束时间不确定的有限次重复博弈,称为“随机结束的重复博弈”。
意义:重复博弈可解释一般静态博弈和动态博弈无法解释的问题,对理解许多问题和现象有重要价值。
- (1)影响博弈结果
- (2)对应长期关系
- (3)体现出信誉和合作的机制
4.1.2 重复博弈的基本概念
-
重复博弈的策略、子博弈和均衡路径
- 重复博弈的策略:重复博弈中, 博弈方在每个阶段针对每种情况如何选择策略的完整计划。
- 重复博弈的子博弈:重复博弈中, 从某个阶段(不包括第一次博弈)开始,包括此后所有阶段的博弈。 子博弈要么仍是重复博弈,要么是原博弈。
- 重复博弈的均衡路径:重复博弈中,各博弈方的均衡策略组合所对应的策略路径。
-
得益
- (1) 重复博弈的总得益:博弈方各阶段的得益总和
- (2)重复博弈的平均得益:总得益除以博弈重复次数
从博弈效率评价的角度,平均得益比总得益更有意义。
-
(3)重复博弈的总得益现值:不同时将获得的同样大小利益的价值有差别,折算为现在值易于比较.
贴现系数 δ \delta δ可根据利率 γ \gamma γ计算: δ = 1 1 + γ \delta = \frac{1}{1+\gamma} δ=1+γ1,则总得益现在值为:
π = π 1 + δ π 2 + δ 2 π 3 + ⋯ + δ T − 1 π T = ∑ t = 1 T δ t − 1 π t , ( T 可为 ∞ ) \pi=\pi_1+\delta\pi_2+\delta^2\pi_3+\cdots+\delta^{T-1}\pi_T=\sum_{t=1}^T\delta^{t-1}\pi_t,(T可为\infty) π=π1+δπ2+δ2π3+⋯+δT−1πT=t=1∑Tδt−1πt,(T可为∞) -
(4)重复博弈的平均得益
如果一常数 π ‾ \overline \pi π作为重复博弈(有限次重复或无限次重复)各个阶段的得益,能产生与得益序列 π 1 , π 2 , π 3 , . . . . . . \boldsymbol{\pi}_{1},\boldsymbol{\pi}_{2},\boldsymbol{\pi}_{3},...... π1,π2,π3,......相同的现值,则称其为此得益序列的平均得益,即:
∑ t = 1 ∞ δ t − 1 π ‾ = π ‾ ( 1 − δ ) = ∑ t = 1 ∞ δ t − 1 π t π ‾ = ( 1 − δ ) ∑ t = 1 ∞ δ t − 1 π t \sum_{t=1}^{\infty}\delta^{t-1}\overline \pi=\frac{\overline{\pi}}{(1-\delta)}=\sum_{t=1}^{\infty}\delta^{t-1}\pi_t\\ \overline{\pi}=(1-\delta)\sum\limits_{t=1}^{\infty}\delta^{t-1}\pi_t t=1∑∞δt−1π=(1−δ)π=t=1∑∞δt−1πtπ=(1−δ)t=1∑∞δt−1πt -
(5)随机结束的重复博弈的得益
假设博弈在每个阶段结束的概率为 p,继续的概率为 1-p
则期望得益的现值为:
π = π 1 + π 2 ( 1 − p ) / ( 1 + γ ) + π i ( 1 − p ) 2 / ( 1 + γ ) 2 + ⋯ = ∑ i = 1 ∞ π i ( 1 − p ) i − 1 ( 1 + γ ) i − 1 = ∑ i = 1 ∞ π i ( 1 − p 1 + γ ) i − 1 = ∑ i = 1 ∞ δ i − 1 π i \begin{aligned}\pi=\pi_1+\pi_2(1-p)/(1+\gamma)+\pi_i(1-p)^2/(1+\gamma)^2+\cdots\\ =\sum\limits_{i=1}^{\infty}\pi_i\frac{(1-p)^{i-1}}{(1+\gamma)^{i-1}}=\sum\limits_{i=1}^{\infty}\pi_i\left(\frac{1-p}{1+\gamma}\right)^{i-1}=\sum\limits_{i=1}^{\infty}\delta^{i-1}\pi_i\end{aligned} π=π1+π2(1−p)/(1+γ)+πi(1−p)2/(1+γ)2+⋯=i=1∑∞πi(1+γ)i−1(1−p)i−1=i=1∑∞πi(1+γ1−p)i−1=i=1∑∞δi−1πi
这里的贴现系数不再是 1 1 + γ \frac{1}{1+\gamma} 1+γ1,而是 1 − p 1 + γ \frac{1-p}{1+\gamma} 1+γ1−p
4.2 有限次重复博弈
4.2.1 两人零和博弈的有限次重复博弈
-
零和博弈没有纯策略纳什均衡,重复博弈并不改变这一点。
-
在所有零和博弈的有限次重复博弈中,博弈方的策略都是重复一次性博弈的混合策略纳什均衡的策略
逆推法证明:
有限次重复博弈的最后一次博弈就是原博弈本身,此时没有后续博弈,博弈方没有合作的必要,所以会采取原策略的混合策略纳什均衡,倒推到第二阶段,博弈方可预见最后一个阶段的结果,相当于倒数第二阶段就是最后阶段,同样没有合作必要,依次类推可得出结论。
4.2.2 唯一纯策略纳什均衡博弈的有限次重复博弈
首先容易理解的是,如果原博弈唯一的纯策略纳什均衡本身是帕累托最优,重复博奔显然不会改变博弃方的行为方式。
值得关心的是原博弈唯一的纳什均衡没有达到帕累托效率,存在通过合作提高效率可能性的囚徒困境式博弈,是否能通过重复博弈实现合作结果。
-
有限次重复的囚徒困境博弈
(1)两次重复博弈
采用逆推归纳:
-
对于第二阶段,不会再有后续,所以选择(坦白,坦白)
-
对于第一阶段,博弈方知道第二阶段结果: (坦白, 坦白),不管第一阶段选择哪个策略组合,双方在两次重复博弈中的总得益都是第一阶段得益加“-5”。 所以还是相当于一次博弈,结果为(坦白,坦白)
(2)有限次重复博弈
依据上述方法,可证明: 3、 4、 ……n次重复博弈的结果都是(坦白,坦白),构成重复博弈唯一的子博弈完美纳什均衡。
-
-
一般结论
定理:设原博弈G有唯一的纯策略纳什均衡,则对有限次重复博弈G(T)( T为任意正整数),博弈方每个阶段都采用G的纳什均衡策略,是G(T)的唯一子博弈完美纳什均衡。
定理的含义:
- 不会出现合作
- 不能实现更高效率的博弈结果
-
有限次重复竞价博弈
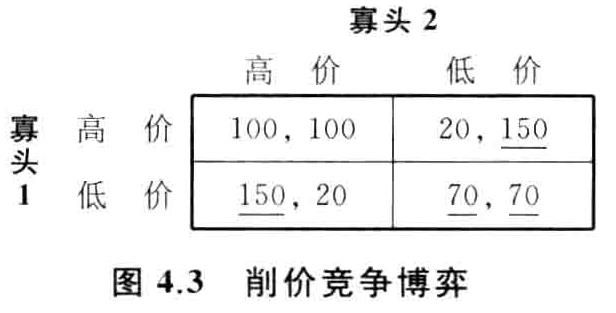
分析过程、结论与囚徒困境完全一样。
4.2.3 多个纯策略纳什均衡博弈的有限次重复博弈
存在多个纯策略纳什均衡时,情况会发生变化吗?能不能得到比一次博弈更好的结果
-
三价博弈的重复博弈

①一次博弈的纯策略纳什均衡 ( M , M ) ; ( L , L ) (M, M); (L, L) (M,M);(L,L)
而 ( H , H ) (H, H) (H,H):总利益最大,个体利益也较好,但非纳什均衡 ,两次重复博弈的结果会改善吗?
②两次重复博弈的纳什均衡
——厂商1的策略(同厂商2):
第一次选H, 第二次据第一次结果选择:
A. 若第一次结果 (H,H),则第二次不会选H,而选M;
B. 若第一次结果为其他,则第二次选L报复。而由逆推归纳法可知 ( H , H ) − ( M , M ) (H, H) -(M, M) (H,H)−(M,M)是子博弈完美纳什均衡,因为虽然第一阶段不是子博弈完美纳什均衡,但若一方偏离的话第二阶段会遭到报复,收益也不好。同时因为两次博弈之间的因果关系,可将两次博弈合并成一次博弈进而计算得益,可发现第一阶段选(H,H)也是帕累托上策均衡。
这也就是触发策略:博弈方双方先试探合作,一旦发觉对方不合作,就选择不合作进行报复,
触发策略作用:
- 重复博弈中实现合作和提高效率的关键机制
- 重复博弈分析的重要“构件”
③多次重复博弈
子博弈完美纳什均衡路径:$(H,H)- (H,H) -…… -(H,H) - (M,M) $
-
触发策略的进一步讨论
①(可信性问题)
根据构成子博弈完美纳什均衡的触发策略,另一方将在第二阶段采用报复性的L策略,这样偏离一方也只能采用 L,双方策略虽然仍然是纳什均衡,但都只能得到较差的得益。因此,触发策略在报复偏离均衡博弈方的同时,报复者自己也会受到损失。
如果未偏离一方不计前嫌,仍然与对方共同采用 M,对他自己也是有利的。这必然引起触发策略是否真正可信的问题。
触发策略不可信 ⟶ \longrightarrow ⟶ 不管第一阶段结果如何 ⟶ \longrightarrow ⟶ 第二阶段都是(M,M) ⟶ \longrightarrow ⟶ 第一阶段所有得益 + (3,3) ⟶ \longrightarrow ⟶ 转为一次博弈 ⟶ \longrightarrow ⟶ 两次重复(M,M)
②报复机制非常可信的两次重复博弈

触发策略:
- 博弈方1: 第一阶段选H;若第一阶段结果是(H,H),第二阶段选M;否则, 选P
- 博弈方2: 第一阶段选H; 若第一阶段结果是(H,H),第二阶段选M;否则, 选Q
这种情况下报复机制是可信的,会让最终的结果朝着预定方向走。
-
两市场博弈的重复博弈
触发策略只是有多个纯策略纳什均衡博弈重复博弈的有效策略之一,而且不是普遍适用的,有些情况下其他策略更有效。下面这个两市场博弈的重复博弈就是这方面的例子。

① 两厂商同时发现A、 B两市场,每个厂商只具有在一个市场发展的能力。
② A市场大,一家厂商难以开发好,两家共同开发更好。
③ B市场小,一家开发较好,两家开发无利可图。单次博弈的分析:
① 纯策略纳什均衡: (A,B), (B,A)
② 混合策略纳什均衡:都以(0.5,0.5)在A、 B间随机选,双方期望得益=0.5× 0.5× (3+4+1+0)=2但是纯策略(A,B), (B,A)不易达成共识,混合策略相对安全,但期望得益不高,而最佳策略组合(A,A)无法实现。
两次重复博弈的分析,有4条子博弈完美纳什均衡路径 :
① 连续两次纯策略: 连续两次(A,B),或连续两次(B,A)——》 双方平均得益(1,4)或(4,1)
② 连续两次混合策略均衡——》 双方平均期望得益2
③ 轮换策略: (A,B)——(B,A),或 (B,A)——(A,B)——》双方平均得益2.5
④ 一次纯策略(A,B)或(B,A),另一次混合策略——》 双方平均得益 (1.5, 3), (3, 1.5)
重复博弈使博弈结果出现更多可能,平均得益和公平性都优于一次性博弈;但都与最佳结果 (A,A)-(3,3)有差距。
三次重复博弈的触发策略:
厂商1:
第一阶段:选A;
第二阶段: 若第一阶段结果(A,A),第二阶段选A报答,(A,B)若第一阶段结果(A,B),第二阶段选B;(B,A)
第三阶段:无条件选B,对方被迫选A厂商2:
第一阶段:选A
第二阶段:无条件选B(第一阶段(A,A),厂商1第2阶段选A)
第三阶段:若第一阶段结果(A,A),第三阶段选A,若第一阶段结果(B,A),第三阶段选B3次重复博弈的均衡路径:(A, A)-(A, B)-(B, A),双方每阶段平均得益: (3+1+4)/3=2.67
厂商1的触发策略在第二阶段;厂商2的触发策略在第三阶段。报复机制对偏离者有惩罚作用,对报复者有利——》有很强可信性。
101次重复博弈:
厂商1的策略
前99次选A;
从第二次开始,一旦发现哪次结果是(A,B),则选B坚持到底;
最后两次重复与3次重复博弈后两次相同的策略,如果99阶段结果(A,A)则选A。若(A,B)选B厂商2策略与厂商1前99次相同,后两次相反
双方每阶段平均得益: (99× 3+1+4)/101=2.9
4.2.4 有限次重复博弈的民间定理
上节讨论的启发
(1)运用触发策略可实现高效均衡
有多个纯策略纳什均衡时,可通过设计触发策略,实现一次性博弈中无法实现的潜在合作利益。
(2)实现高效均衡的关键因素
提高效率和发掘潜在利益的可能性和程度,与原博弈结构和重复博弈次数有关。
4.3 无限次重复博弈
与有限次重复博弈的区别:
- 没有最后一次博弈
- 须考虑得益的贴现问题
4.3.1 两人零和博弈的无限次重复博弈
两人零和博弈的无限次重复,与有限次重复的博弈结果没区别。因为重复次数的无限增加,不能改变利益上的对立关系,也不会创造出潜在的合作利益。
4.3.2 唯一纯策略纳什均衡博弈的无限次重复博弈
囚徒困境式的博弈在有限次重复博弈中仍没有较好的效果,那么在无限次博弈中是否会有不同钠
-
寡头竞价博弈的无限次重复

①两博弈方的相同触发策略:
第一阶段:选H
第t阶段:若前t-1阶段结果都是(H,H),则继续选H;否则选L。
双方都先试图合作,第一次无条件选H,若发现对方也合作,坚持H;一旦发现对方不合作,则永远选L报复。②双方采用触发策略是纳什均衡证明:
若博弈方2第一阶段选L,双方得益(0, 5),引起博弈方1一直选L报复,博弈方2总得益现值为:
π = 5 + 1 ⋅ δ + 1 ⋅ δ 2 + ⋯ = 5 + δ 1 − δ \pi=5+1\cdot\delta+1\cdot\delta^2+\cdots=5+\frac{\delta}{1-\delta} π=5+1⋅δ+1⋅δ2+⋯=5+1−δδ
若博弈方2第一阶段选H, 双方得益(4, 4)下一阶段面临同样选择, 博弈方2总得益现值:
V = 4 + δ V V=4+\delta V V=4+δV这里两个V的意思是,第二阶段进入的循环与第一阶段相同,所以得益也相同
解得: V = 4 1 − δ V=\frac{4}{1-\delta} V=1−δ4
所以博弈方2选择的依据为:
4 / ( 1 − δ ) > 5 + δ / ( 1 − δ ) 即 δ > 1 / 4 4/(1-\delta)>5+\delta/(1-\delta)即\delta>1/4 4/(1−δ)>5+δ/(1−δ)即δ>1/4
当δ >1/4,上述触发策略组合构成寡头竞价的无限次重复博弈的子博弈完美纳什均衡,其均衡路径为两博弈方每阶段都选H。
总结:
在有限次重复博弈中,只有原博弈有多个纯策略纳什均衡时,才可能实现潜在的合作利益。——有限次重复博弈的民间定理
在无限次重复博弈中,原博弈有一个纳什均衡,就可能实现潜在的合作利益。——无限次重复博弈的民间定理
民间定理:

4.3.3 无限次重复古诺模型
前述两寡头削价竞争是各博弈方只有两种可选策略的离散策略博弈,而博弈方的行为选择越多,重复博弈的路径也越多,在无限次重复博弈中,实现较高效率均衡的机会也越多。对此,可以通过产量竞争古诺模型的无限次重复博弈加以说明。
假设:市场价格—— P = P ( Q ) = 8 − Q P=P(Q)=8-Q P=P(Q)=8−Q;市场总产量—— Q = q 1 + q 2 Q=q1+q2 Q=q1+q2;两厂商边际成本=2, 固定成本=0
分析:一次性博弈中有唯一纳什均衡(2,2),此时的得益为(4,4)
如果采取合作垄断市场 : 垄断产量 Q m Q_m Qm=3,两厂商各生产1.5——》 得益(4.5, 4.5),但是在一次性静态博弈和有限次重复博弈中都不能实现。
- 在无限次重复博弈中:
-
触发策略:
① 第一阶段:生产垄断产量的一半1.5;
② 第t阶段:若前t-1阶段的结果都是(1.5, 1.5),则继续生产1.5; 否则,生产古诺产量 2。 -
触发策略的条件:
① 不偏离总得益现值: 4.5 ( 1 + δ + δ 2 + . . . . . ) = 4.5 / ( 1 − δ ) 4.5(1+\delta+\delta^2+.....)=4.5/(1-\delta) 4.5(1+δ+δ2+.....)=4.5/(1−δ)
② 厂商2偏离触发策略的总得益现0值:一次 q 2 = 2.25 q_2=2.25 q2=2.25,利润=5.0625 >4.5
5.0625 + 4 ( δ + δ 2 + ⋯ ) = 5.0625 + 4 δ 1 − δ 5.0625+4(\delta+\delta^2+\cdots)=5.0625+\frac{4\delta}{1-\delta} 5.0625+4(δ+δ2+⋯)=5.0625+1−δ4δ
触发条件: 4.5 1 − δ ⩾ 5.0625 + 4 δ 1 − δ \frac{4.5}{1-\delta}\geqslant5.0625+\frac{4\delta}{1-\delta} 1−δ4.5⩾5.0625+1−δ4δ
-
δ ≥ 9/17 ——》双方都采用触发策略是子博弈完美纳什均衡;
-
δ < 9/17 ——》厂商2偏离
若贴现系数太小——》博弈方只顾眼前利益,不怕对方报复——》 无限次重复博弈不能提高原博弈的效率。
-
-
低水平合作的无限次重复博弈
δ < 9/17——》 偏离——》 不能让两厂商把产量都控制在合作产量(1.5),但有可能控制在高于合作产量,且低于古诺产量的水平 q ∗ ( 1.5 < q ∗ < 2 ) q^*(1.5 < q^* < 2) q∗(1.5<q∗<2) ( q m / 2 < q ∗ < q c ) \left(\boldsymbol{q}_m / \mathbf{2}<\boldsymbol{q}^*<\boldsymbol{q}_c\right) (qm/2<q∗<qc)
当 δ \delta δ越大时,将来利益越重要,就能支持越低的子博弈完美纳什均衡产量 q ∗ q^* q∗。上述分析也揭示了, 为什么通货膨胀严重国家的企业在经济活动中短期行为更为严重的一种理论根源。因为通货膨胀率越高, 末来利益折算成现在值的贴现系数就越低, 企业就越重视当前利益而不重视长期利益, 它们的行为就有更强烈的急功近利特征。这种急功近利的短期行为对经济效率害处很大。因此严重的通货膨胀不仅对宏观经济的稳定运行很大危害, 而且对经济运行的微观基础也有很大危害, 加强对通货膨胀的控制非常重要。
-
加大惩罚力度和提高合作水平
不用古诺产量而是另一个 x ( x > 2 ) x(x>2) x(x>2)来进行惩罚
-
触发策略:
(1) 第 1 阶段:生产合作产量 q m / 2 q_m / 2 qm/2
(2) 第 t 阶段:
若 t − 1 \mathrm{t}-1 t−1 阶段结果 ( q m / 2 , q m / 2 ) \left(q_m / 2, q_m / 2\right) (qm/2,qm/2), 生产 q m / 2 q_m / 2 qm/2 合作
若t-1阶段结果 ( q m / 2 , a ) \left(q_m / 2, a\right) (qm/2,a) 或 ( b , q m / 2 ) \left(b, q_m / 2\right) (b,qm/2), 生产 x > q c x>q_c x>qc 惩罚对方
(3) 第 t + 1 \mathbf{t}+\mathbf{1} t+1 阶段:
若 t \mathrm{t} t 阶段结果 ( x , x ) , t + 1 (x, x), \mathrm{t}+1 (x,x),t+1 阶段生产 q m / 2 q_m / 2 qm/2 重新试图合作 -
判断依据:
第一阶段厂商 2 选择是否偏离的依据, 是偏离得到的好处与第 二阶段受惩罚损失的现在值的大小关系。即
δ ( π m 2 − π x ) = δ ( 4.5 − 6 x + 2 x 2 ) ⩾ π d − π m 2 = 5.0625 − 4.5 = 0.5625 \begin{aligned} \delta\left(\frac{\pi_m}{2}-\pi_x\right) & =\delta\left(4.5-6 x+2 x^2\right) \\ & \geqslant \pi_d-\frac{\pi_m}{2}=5.0625-4.5=0.5625 \end{aligned} δ(2πm−πx)=δ(4.5−6x+2x2)⩾πd−2πm=5.0625−4.5=0.5625
也即 δ ⩾ 0.5625 / ( 4.5 − 6 x + 2 x 2 ) \delta \geqslant 0.5625 /\left(4.5-6 x+2 x^2\right) δ⩾0.5625/(4.5−6x+2x2) 时,厂商 2 不会选择偏离; 反之, 则会偏离。
-
4.3.4 有效工资率博弈
有效工资:既能降低厂商的劳动力成本,也能激励员工努力工作的工资。

-
对于一次博弈来说:
w − e < w ⟶ w-e
-
对于无限次重复博弈:
① 触发策略
A. 厂商的策略
- 第一阶段:厂商给有效工资 w ∗ w^* w∗
- 第 t 阶段:
- 若t-1阶段结果是高产 ( y − w ∗ , ? ) (y-w^*, ?) (y−w∗,?),继续给 w ∗ w^* w∗;
- 若t-1阶段结果是低产,则解雇, w = 0 w=0 w=0
B.工人的策略:
- 第一阶段:若w*>w0,接受
- 第 t 阶段:
- 若以前各期 ( y − w ∗ , w ∗ − e ) (y-w^*, w^*-e) (y−w∗,w∗−e)且当前工资为 w ∗ w^* w∗,努力工作;
- 若w ≠ w ∗ w^* w∗, 但 w > w 0 w>w_0 w>w0,偷懒
②得益情况
工人努力:
V e = ( w ∗ − e ) + δ V e 即 : V e = ( w ∗ − e ) / ( 1 − δ ) V_e=(w^*-e)+\delta V_e\\即:V_e=(w^*-e)/(1-\delta) Ve=(w∗−e)+δVe即:Ve=(w∗−e)/(1−δ)
工人偷懒: V s = w ∗ + δ [ p V s + ( 1 − p ) w 0 1 − δ ] V_s=w^*+\delta\bigg[pV_s+\left(1-p\right)\frac{w_0}{1-\delta}\bigg] Vs=w∗+δ[pVs+(1−p)1−δw0]公式表明,有p的概率会进行到下一个循环,有1-p的概率,工人被开除,然后拿 w 0 w_0 w0
易知,当 V e > V s V_e>V_s Ve>Vs时工人会努力工作,即:
w ∗ ⩾ w 0 + ( 1 − p δ δ ( 1 − p ) ) e = w 0 + ( 1 + 1 − δ δ ( 1 − p ) ) e = w 0 + e + 1 − δ δ ( 1 − p ) e \begin{array}{ll}w^{*}&\geqslant w_{0}+\left(\frac{1-p\delta}{\delta(1-p)}\right)e=w_{0}+\left(1+\frac{1-\delta}{\delta(1-p)}\right)e\\ &=w_{0}+e+\frac{1-\delta}{\delta(1-p)}e\end{array} w∗⩾w0+(δ(1−p)1−pδ)e=w0+(1+δ(1−p)1−δ)e=w0+e+δ(1−p)1−δe
而厂商只要满足 y − w ∗ > 0 y-w^*>0 y−w∗>0就会选择此触发策略,在这两个条件限制下,也就组成了一个子博弈完美纳什均衡。
Summary
此部分用于对所学内容的快速梳理记忆
-
基本概念:有限次重复和无限次重复,折现系数 δ = 1 1 + γ \delta=\frac{1}{1+\gamma} δ=1+γ1
-
有限次重复博弈下,纳什均衡是否会发生变化:
- 零和博弈和唯一纯策略纳什均衡博弈不会变
- 多个纯策略纳什均衡博弈
- 三价博弈,在两次重复博弈时使用触发策略
- 触发策略的讨论:是否具有可信性
- 两市场博弈:存在混合策略,但在触发策略里与混合策略无关,1、2、3、101博弈的逐次分析,触发策略的使用可以越来越接近最大平均利益
- 引出民间定理:重复博弈次数越多利益越大(在有限次重复博弈中,只有原博弈有多个纯策略纳什均衡时,才可能实现潜在的合作利益。)
-
无限次重复博弈中情况怎么样
- 与有限次的区别在于:没有最后一次博弈且需考虑贴现问题
- 零和博弈不会受影响
- 唯一纯策略纳什均衡博弈
- 寡头竞价:需用贴现来证明触发策略是纳什均衡
- 民间定理:在无限次重复博弈中,原博弈有一个纳什均衡,就可能实现潜在的合作利益。
- 无限次重复古诺模型
- 触发策略的设计
- δ \delta δ达不到要求时,低水平合作的出发策略
- 加大惩罚力度和提高合作水平
- 有效工资率博弈 类似
有限次重复博弈中的触发策略较为单纯,无限次的要考虑贴现率
若无纯策略纳什均衡,只有混合策略纳什均衡,那么有限次和无限次重复都只会继续原博弈的混合策略
All in all 有限次单纯考虑触发策略判断子博弈完美纳什均衡,无限次要结合 δ \delta δ证明完美纳什