Redis的数据类型及对应的数据结构(一)
Redis的数据类型和数据结构的对应关系 左边是 Redis 3.0版本的,也就是《Redis 设计与实现》这本书讲解的版本,右边是7.0,注意区别很大
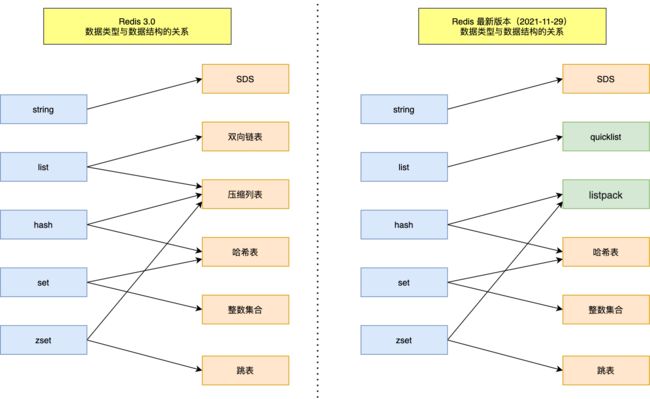
数据类型包括:String、List、Hash、Set、ZSet
对应的底层数据结构入上图
String的应用场景
缓存对象
使用 String 来缓存对象有两种方式:
- 直接缓存整个对象的 JSON,命令例子:
SET user:1 '{"name":"xiaolin", "age":18}'。 - 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子:
MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20。
常规计数
因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。
比如计算文章的阅读量:
# 初始化文章的阅读量
> SET aritcle:readcount:1001 0
OK
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 1
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 2
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 3
# 获取对应文章的阅读量
> GET aritcle:readcount:1001
"3"
#分布式锁
SET 命令有个 NX 参数可以实现「key不存在才插入」,可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
一般而言,还会对分布式锁加上过期时间,分布式锁的命令如下:
SET lock_key unique_value NX PX 10000
- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除,但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
共享 Session 信息
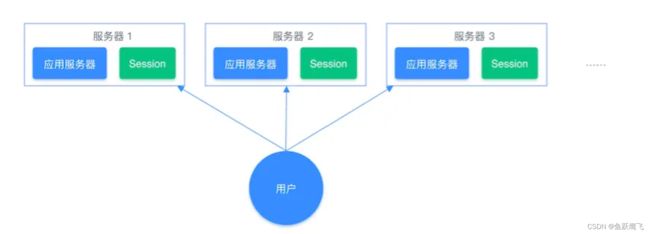
通常我们在开发后台管理系统时,会使用 Session 来保存用户的会话(登录)状态,这些 Session 信息会被保存在服务器端,但这只适用于单系统应用,如果是分布式系统此模式将不再适用。
例如用户一的 Session 信息被存储在服务器一,但第二次访问时用户一被分配到服务器二,这个时候服务器并没有用户一的 Session 信息,就会出现需要重复登录的问题,问题在于分布式系统每次会把请求随机分配到不同的服务器。
分布式系统单独存储 Session 流程图:
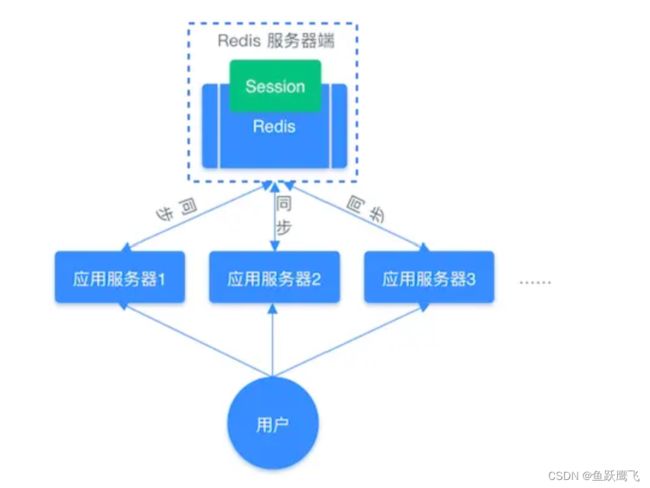
因此,我们需要借助 Redis 对这些 Session 信息进行统一的存储和管理,这样无论请求发送到那台服务器,服务器都会去同一个 Redis 获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。
分布式系统使用同一个 Redis 存储 Session 流程图:
List的应用场景
消息队列
消息队列在存取消息时,必须要满足三个需求,分别是消息保序、处理重复的消息和保证消息可靠性。
Redis 的 List 和 Stream 两种数据类型,就可以满足消息队列的这三个需求。我们先来了解下基于 List 的消息队列实现方法,后面在介绍 Stream 数据类型时候,在详细说说 Stream。
1、如何满足消息保序需求?
List 本身就是按先进先出的顺序对数据进行存取的,所以,如果使用 List 作为消息队列保存消息的话,就已经能满足消息保序的需求了。
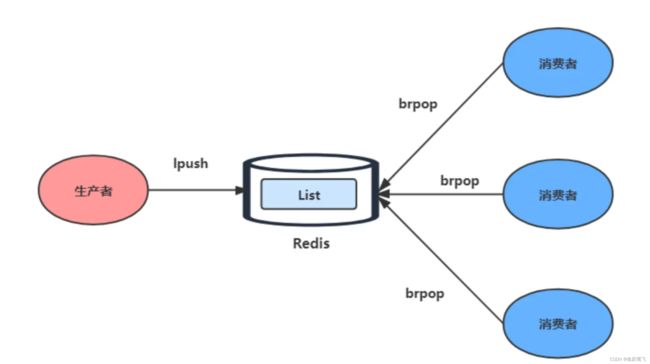
List 可以使用 LPUSH + RPOP (或者反过来,RPUSH+LPOP)命令实现消息队列。

-
生产者使用
LPUSH key value[value...]将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。 -
消费者使用
RPOP key依次读取队列的消息,先进先出。
不过,在消费者读取数据时,有一个潜在的性能风险点。
在生产者往 List 中写入数据时,List 并不会主动地通知消费者有新消息写入,如果消费者想要及时处理消息,就需要在程序中不停地调用 RPOP 命令(比如使用一个while(1)循环)。如果有新消息写入,RPOP命令就会返回结果,否则,RPOP命令返回空值,再继续循环。
所以,即使没有新消息写入List,消费者也要不停地调用 RPOP 命令,这就会导致消费者程序的 CPU 一直消耗在执行 RPOP 命令上,带来不必要的性能损失。
为了解决这个问题,Redis提供了 BRPOP 命令。BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。和消费者程序自己不停地调用RPOP命令相比,这种方式能节省CPU开销。
2、如何处理重复的消息?
消费者要实现重复消息的判断,需要 2 个方面的要求:
- 每个消息都有一个全局的 ID。
- 消费者要记录已经处理过的消息的 ID。当收到一条消息后,消费者程序就可以对比收到的消息 ID 和记录的已处理过的消息 ID,来判断当前收到的消息有没有经过处理。如果已经处理过,那么,消费者程序就不再进行处理了。
但是 List 并不会为每个消息生成 ID 号,所以我们需要自行为每个消息生成一个全局唯一ID,生成之后,我们在用 LPUSH 命令把消息插入 List 时,需要在消息中包含这个全局唯一 ID。
例如,我们执行以下命令,就把一条全局 ID 为 111000102、库存量为 99 的消息插入了消息队列:
> LPUSH mq "111000102:stock:99"
(integer) 1
3、如何保证消息可靠性?
当消费者程序从 List 中读取一条消息后,List 就不会再留存这条消息了。所以,如果消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。
为了留存消息,List 类型提供了 BRPOPLPUSH 命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存。
这样一来,如果消费者程序读了消息但没能正常处理,等它重启后,就可以从备份 List 中重新读取消息并进行处理了。
好了,到这里可以知道基于 List 类型的消息队列,满足消息队列的三大需求(消息保序、处理重复的消息和保证消息可靠性)。
- 消息保序:使用 LPUSH + RPOP;
- 阻塞读取:使用 BRPOP;
- 重复消息处理:生产者自行实现全局唯一 ID;
- 消息的可靠性:使用 BRPOPLPUSH
List 作为消息队列有什么缺陷?
List 不支持多个消费者消费同一条消息,因为一旦消费者拉取一条消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费。
要实现一条消息可以被多个消费者消费,那么就要将多个消费者组成一个消费组,使得多个消费者可以消费同一条消息,但是 List 类型并不支持消费组的实现。
这就要说起 Redis 从 5.0 版本开始提供的 Stream 数据类型了,Stream 同样能够满足消息队列的三大需求,而且它还支持「消费组」形式的消息读取。
Hash应用场景
缓存对象
Hash 类型的 (key,field, value) 的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
我们以用户信息为例,它在关系型数据库中的结构是这样的:

我们可以使用如下命令,将用户对象的信息存储到 Hash 类型:
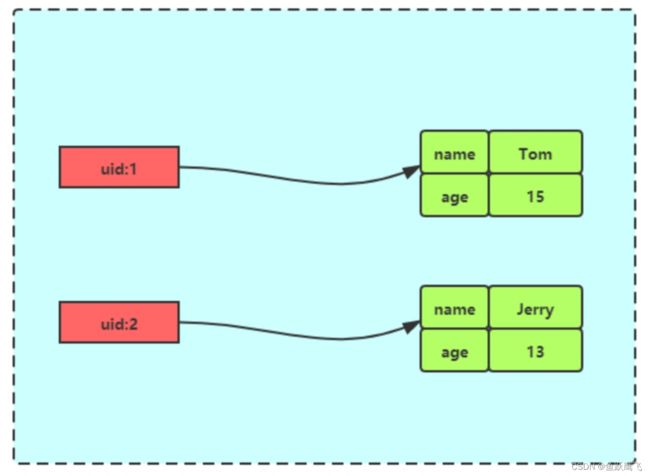
# 存储一个哈希表uid:1的键值
> HMSET uid:1 name Tom age 15
2
# 存储一个哈希表uid:2的键值
> HMSET uid:2 name Jerry age 13
2
# 获取哈希表用户id为1中所有的键值
> HGETALL uid:1
1) "name"
2) "Tom"
3) "age"
4) "15"
Redis Hash 存储其结构如下图:
在介绍 String 类型的应用场景时有所介绍,String + Json也是存储对象的一种方式,那么存储对象时,到底用 String + json 还是用 Hash 呢?
一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。
购物车
以用户 id 为 key,商品 id 为 field,商品数量为 value,恰好构成了购物车的3个要素,如下图所示。
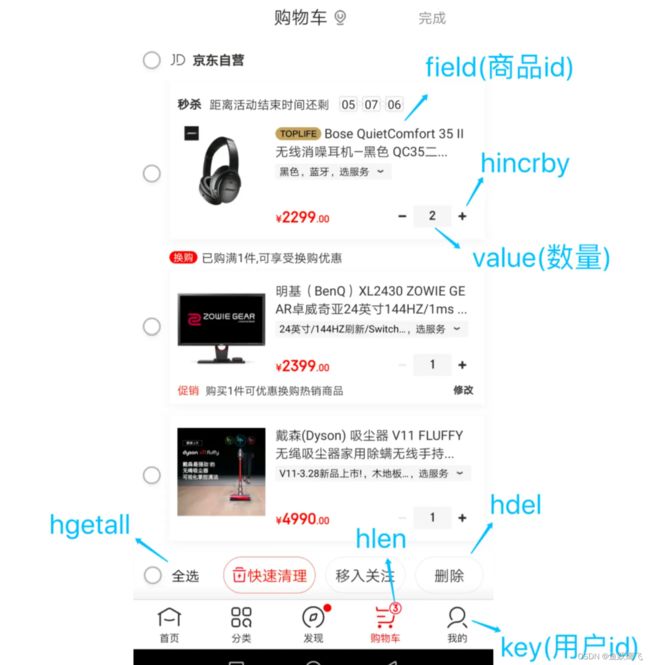
涉及的命令如下:
- 添加商品:
HSET cart:{用户id} {商品id} 1 - 添加数量:
HINCRBY cart:{用户id} {商品id} 1 - 商品总数:
HLEN cart:{用户id} - 删除商品:
HDEL cart:{用户id} {商品id} - 获取购物车所有商品:
HGETALL cart:{用户id}
当前仅仅是将商品ID存储到了Redis 中,在回显商品具体信息的时候,还需要拿着商品 id 查询一次数据库,获取完整的商品的信息。
这样实现购物车具备一定的合理性,但是京东不是这样使用Redis操作购物车的,想了解更深内幕的可以找我私聊。