fp-growth算法详解与实现
fp-growth算法详解与实现
- 一、摘要
- 二、绪论
- 三、算法介绍
- 四、算法实现
- 五、为什么要迭代建树寻找频繁项集
- 六、总结
一、摘要
本文讲解fp-growth算法的原理,梳理了fp-growth算法的实现流程,并使用Java实现fp-growth算法,通过面向对象的思想使算法更加结构化,并使其更加通俗易懂。
二、绪论
在之前的博客中我们详细介绍了Apriori算法的实现(要是不知道,可以自行百度或看我之前的博客),但大家应该可以发现,Apriori算法在求得频繁项集的时候会对数据集进行多次扫描,很大程度上降低算法执行的效率。实际上Apriori算法只是一类关联算法的试探,其效率较低,很难使用在实际环境中。于是韩家炜教授等人提了出FP-growth(Frequent Pattern growth)算法,该算法是频繁模式(Frequent Pattern, FP)挖掘领域的经典算法,它实现频繁项集的收集只需要扫描两遍数据集,降低了IO次数,大大提高了算法的效率,同时,该算法是可以在实际生产环境中使用的。
三、算法介绍
FP-growth算法性能强大是因为它将数据集化为了FPTree这一数据结构,寻找频繁项集的过程便是对这颗数进行操作的过程。
由于这个算法的数据结构比较多,概念也不好用生涩的语言来描述,这里我们不再列举FP-growth算法的各个数据结构概念,而是在实际操作中进行讲解。
首先我们先将算法的整个流程进行描述:
(1)第一次扫描数据集统计每个项目出现的次数,并在头指针表中进行计数,然后删除不满足支持度要求的表项;
(2)第二次扫描数据集删除每条记录中不满足支持度的项目,然后对每条记录中的项目按照其出现次数进行降序排序;
(3)第三次扫描数据集建立FPTree并完善头指针表;
(4)迭代(1)至(3)收集频繁项集;
在这里我将两次扫描数据集给拆分成了三次,是因为这样代码的结构比较清晰,实际上可以将(2)和(3)合为一次扫描。而步骤(4)会在后面进行详细介绍。
下面我们详细讲解算法过程。对于数据集:

在第一遍扫描数据集的时候,创建头指针表,利用头指针表记录每个项目出现的次数,然后删掉支持度没达到要求的项目对应的头指针表项。
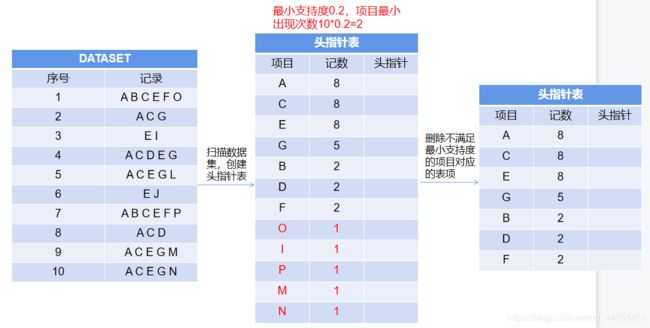
第二次扫描数据集通过头指针表(判断项目对应的表项是否为空)删除每条记录中不满足支持度的项目,然后对每条记录中的项目按照其出现次数进行降序排序。
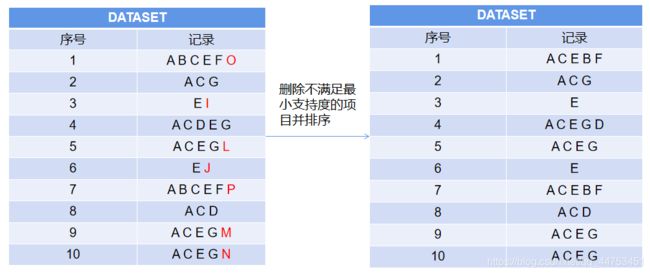
排序的时候需要注意一点,当两个项目的支持度一样时,需要对其按照一个新的规则再进行排序(如项目的ascii码),保证相同支持度的项目也是有序排列的,不然在构建FPTree的时候会出现误差。(后面举例说明)
然后在第三次扫描的时候创建FPTree并完善头指针表。树中的每一条路径对应着一种相互关联项目组合(如购物篮分析中小票中的商品组合),每一个结点不光保存项目名称,还保存其出现的次数。
开始时FPTree只有一个空的根节点,建立FPTree时我们遍历读取数据集中的每一条记录按排好序的顺序插入FP树,如果有对应结点则计数+1;没有的话创建新结点。直到所有的数据都插入到FP树后,FP树的建立完成。在建树过程中,还要利用头指针表连接相同的项目结点(头指针连接第一次出现的项目结点)。这样形容难以理解,下面直接给出例子。
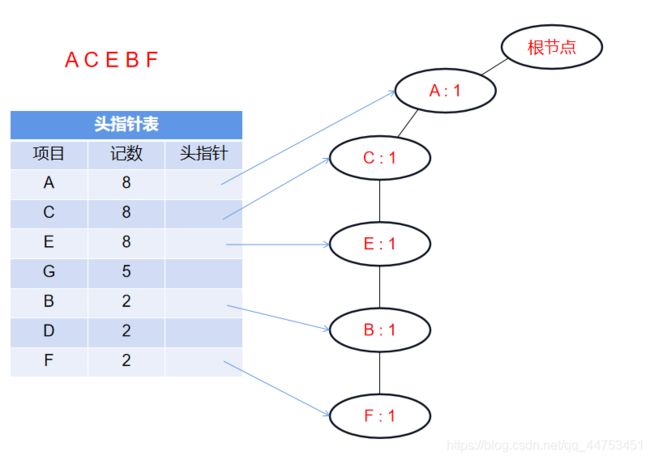
图中黑实线是树结点之间的连接;蓝色箭头是从头指针表发出的同项目结点链表。
插入第一条记录 {A C E B F}:
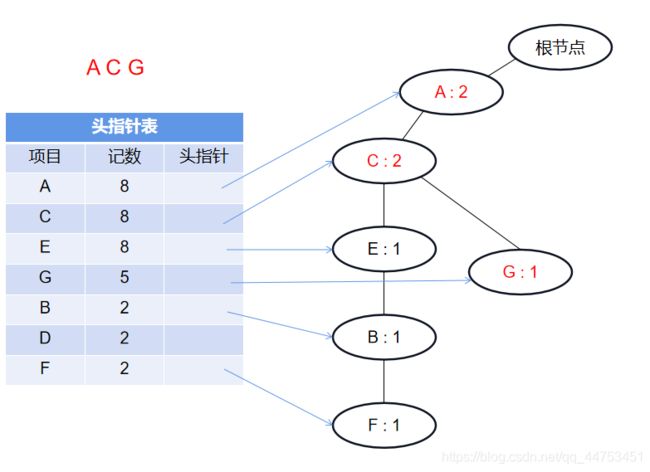
插入第二条记录 {A C G}:
插入第三条记录 {E}:
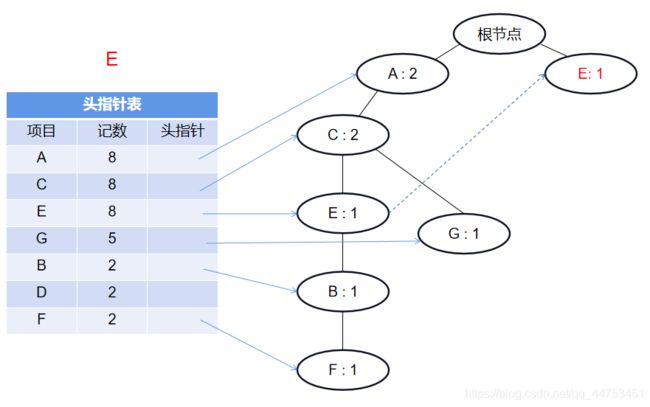
这里就不继续展示插入记录的图了,直接给出最终的FPTree: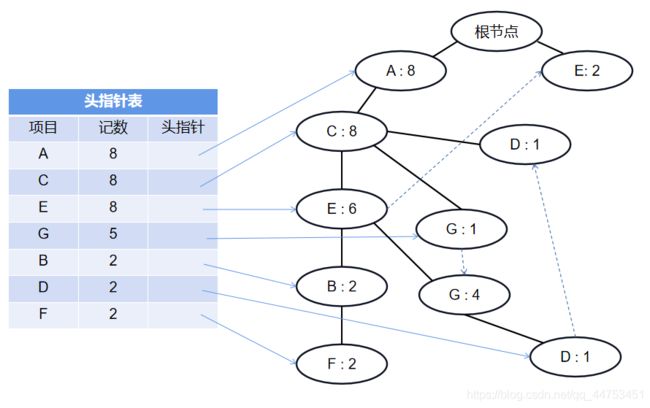
至此我们就得到了一颗完整的FPTree。之后我们便可以迭代建树收集频繁项集了。
首先我们定义每一轮迭代为epoch,每一次的迭代我们都需要经历创建条件FPTree的过程,创建条件FPTree的步骤和创建FPTree是一样的,只不过我们的数据集是某一项目所有条件模式基的集合。
在FPTree中,每一个项目都对应着一个或数个(取决于该项目对应的结点个数)条件模式基。条件模式基是该项目的一个结点到根节点的路径,而该条件模式基对应的记数为该节点的记数,而条件模式基的集合便是该项目所有结点对应的条件模式基的集合。
比如项目F的条件模式基集合只有一个条件模式基,因为该FPTree中只有一个F结点(最左下角的)。
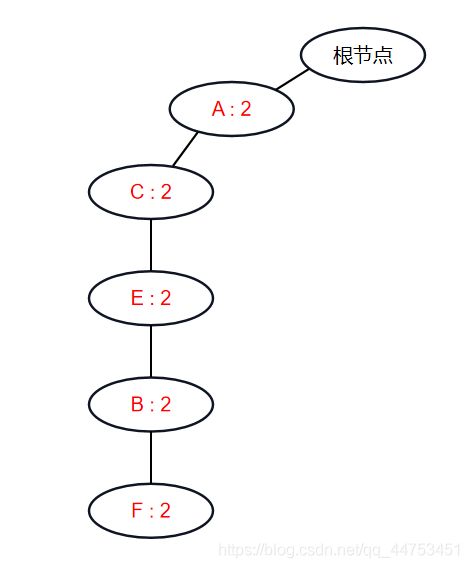
该条件模式基(不包含F结点)为{A C E B, 2}。同理我们可以得到所有项目的条件模式基。不过我们一般获取条件模式基的集合的步骤是:
先对头指针表的所有表项根据项目出现的次数(即头指针表中的记数)进行降序排序(也需要保证相同记数的表项也是有序排序(如记数相同时按项目名称的ascii码再排一次)),然后从记数最少的表项对应的头指针指向的结点开始,根据蓝色箭头连成的链表依次寻找条件模式基,直到所有该项目对应的结点的条件模式基都被找到。便找到了一个项目对应的所有条件模式基。
找到一个项目对应的所有条件模式基之后,我们便可以利用条件模式基的集合创建条件FPTree迭代收集频繁项集。在迭代收集频繁k项集的epoch,我们需要上一次迭代的频繁k-1项集。(注意第一次创建的FPTree对应的头指针表的每个表项对应的项目便是一项集,因为它们都满足最小支持度)
这里用语言难以理解,我们这里直接给出迭代收集频繁项集的代码(但在段落五中讲解了迭代建树寻找频繁项集的原因,希望仔细了解):
/**
* 递归收集频繁项集
*
* @param headPointerTable 头指针表
* @param preFrequentItemSet 递归前的频繁项集
*/
private static void collectFrequentItemSet(Map<String, HeadPointer> headPointerTable, List<String> preFrequentItemSet) {
// 把 Map 转为 List
List<Map.Entry<String, HeadPointer>> headPointerList = new ArrayList<>(headPointerTable.entrySet());
headPointerList.sort((i1, i2) -> {
if (i2.getValue().getCount() > i1.getValue().getCount()) {
return -1;
} else if (i2.getValue().getCount() < i1.getValue().getCount()) {
return 1;
} else {
// 当两个项目出现次数一样时,需要再按ascii码排一次,保证相同支持度的项目也是有序排列的
return i2.getKey().compareTo(i1.getKey());
}
});
// 从头指针表尾开始
for (Map.Entry<String, HeadPointer> entry : headPointerList) {
// 添加频繁项集(需要深复制一个新的List)
List<String> newFrequentItemSet = new ArrayList<>(preFrequentItemSet);
newFrequentItemSet.add(entry.getKey());
addFrequentItemSet(newFrequentItemSet);
// 获取条件模式基
List<ConditionalPatternBase> conditionalPatternBases = getConditionalPatternBases(entry.getValue());
// 创建fp树(将条件模式基集合作为新的数据集)
Map<String, HeadPointer> nextHeadPointerTable = new HashMap<>();
TreeNode root = new TreeNode();
epoch(conditionalPatternBases, nextHeadPointerTable, root);
// 递归获取频繁项集
collectFrequentItemSet(nextHeadPointerTable, newFrequentItemSet);
}
}
其中,倒数第二行的epoch()方法便是创建一颗FPTree的全部过程(三次扫描);方法collectFrequentItemSet()的参数preFrequentItemSet是频繁k-1项集。
当所有的迭代完成之后,频繁项集也便都收集完了。
之前我说过,需要保证相同支持度的项目也要是有序排序,这里给出一个例子。
假设项目支持度A > B = C > D,且这些项目都满足最小支持度,我们删除不满足最小支持度的项目后,数据集有三条记录{C B A}、{D B C A}、{B C A},假设我们使用的是稳定的排序算法进行降序排序,则排序完的新记录为{A C B}、{A B C D}、{A B C},虽然看起来没有什么问题,我们画一下FPTree。
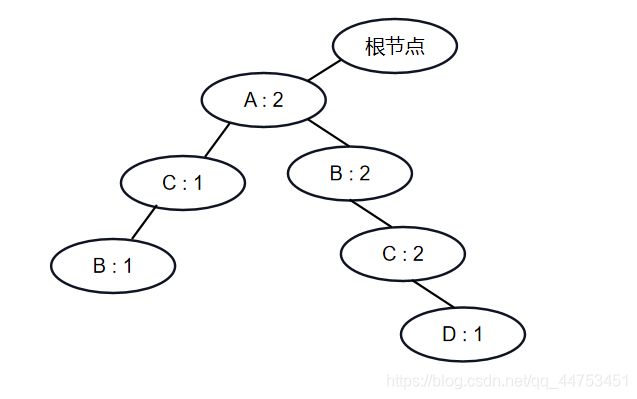
我们都知道,使用fp-growth算法获取频繁项集是为了求出满足置信度的关联规则来探求不同项目之间的关联,也就是同时出现的可能性,很明显,探求小票中不同商品间的关联关系跟商品在小票上出现的次序是没有关系的,也就是说记录是没有顺序的。虽然上面的三条记录ABC都同时出现了,但我们采用稳定的排序算法来排序,会导致即使ABC同时出现,但却被分到了不同的路径,也就是暗中给记录中的项目赋予了顺序这一属性,会导致最后的结果有误差。为了解决这个问题我们需要对相同支持度的项目也设置一个排序规则,如ascii码,这样我们排序后的记录会是这样的{A B C}、{A B C D}、{A B C},得到的FPTree是:
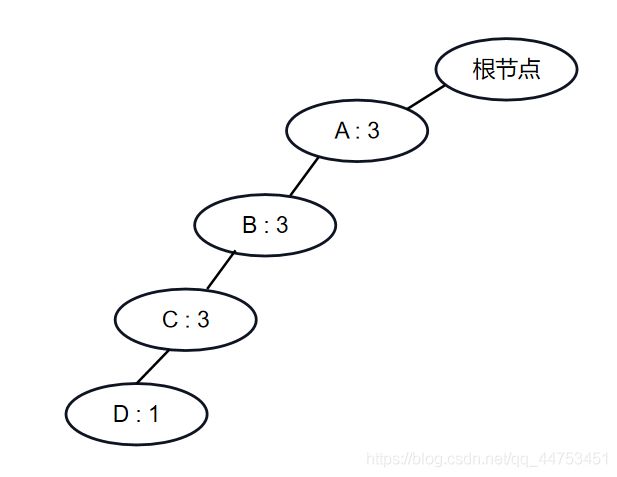
这才是我们想要的FPTree。
至此,算法讲解部分就结束了。
四、算法实现
这里我们使用Java实现。
(1)条件模式基类:
public class ConditionalPatternBase {
// 数据库项目集
private List<String> record;
// 出现次数
private int count;
public ConditionalPatternBase() {
this.count = 1;
}
public ConditionalPatternBase(int count) {
this.count = count;
}
public List<String> getRecord() {
return record;
}
public void setRecord(List<String> record) {
this.record = record;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
(2)头指针表项类:
public class HeadPointer {
// 项目出现次数
private int count;
// 头指针
private TreeNode head;
// 尾指针
private TreeNode tail;
public HeadPointer() {
this.count = 1;
}
public HeadPointer(int count) {
this.count = count;
}
/**
* 计数增加
*/
public void increase(int num) {
count = count + num;
}
/**
* 连接链表
* @param node
*/
public void connect(TreeNode node) {
if (head == null) {
head = node;
tail = head;
} else {
tail.setNextSameItemNode(node);
tail = node;
}
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public TreeNode getHead() {
return head;
}
public void setHead(TreeNode head) {
this.head = head;
}
public TreeNode getTail() {
return tail;
}
public void setTail(TreeNode tail) {
this.tail = tail;
}
}
(3)FPTree结点类:
public class TreeNode {
// 项目名
private String item;
// 路径经过次数
private int count;
// 父节点
private TreeNode parent;
// 子节点
private Map<String, TreeNode> children;
// 链表下一节点(头指针表)
private TreeNode nextSameItemNode;
public TreeNode() {
this.count = 0;
this.children = new HashMap<>();
}
/**
* 计数增加
*/
public void increase(int num){
count = count + num;
}
public String getItem() {
return item;
}
public void setItem(String item) {
this.item = item;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public TreeNode getParent() {
return parent;
}
public void setParent(TreeNode parent) {
this.parent = parent;
}
public Map<String, TreeNode> getChildren() {
return children;
}
public void setChildren(Map<String, TreeNode> children) {
this.children = children;
}
public TreeNode getNextSameItemNode() {
return nextSameItemNode;
}
public void setNextSameItemNode(TreeNode nextSameItemNode) {
this.nextSameItemNode = nextSameItemNode;
}
}
(4)算法实体:
public class FPGrowth {
// 最小支持度
private static double MIN_SUPPORT = 0.05;
// 最小出现次数
private static Integer MIN_APPEAR;
// 频繁项集
private static Map<Integer, Set<List<String>>> FREQUENT_ITEM_SET_TABLE;
public static void main(String[] args) {
// 加载数据集
List<ConditionalPatternBase> dataset = loadData("E:\\data_mining_lab\\src\\data\\OnlineRetailZZ.txt");
// 计算最小出现次数
//MIN_APPEAR = (int) (MIN_SUPPORT * dataset.size());
MIN_APPEAR = 1500;
// 创建fp树
Map<String, HeadPointer> headPointerTable = new HashMap<>();
TreeNode root = new TreeNode();
epoch(dataset, headPointerTable, root);
// 获取频繁项集
FREQUENT_ITEM_SET_TABLE = new HashMap<>();
List<String> preFrequentItemSet = new ArrayList<>();
collectFrequentItemSet(headPointerTable, preFrequentItemSet);
System.out.println();
}
/**
* 递归收集频繁项集
*
* @param headPointerTable 头指针表
* @param preFrequentItemSet 递归前的频繁项集
*/
private static void collectFrequentItemSet(Map<String, HeadPointer> headPointerTable, List<String> preFrequentItemSet) {
// 把 Map 转为 List
List<Map.Entry<String, HeadPointer>> headPointerList = new ArrayList<>(headPointerTable.entrySet());
headPointerList.sort((i1, i2) -> {
if (i2.getValue().getCount() > i1.getValue().getCount()) {
return -1;
} else if (i2.getValue().getCount() < i1.getValue().getCount()) {
return 1;
} else {
// 当两个项目出现次数一样时,需要再按ascii码排一次,保证相同支持度的项目也是有序排列的
return i2.getKey().compareTo(i1.getKey());
}
});
// 从头指针表尾开始
for (Map.Entry<String, HeadPointer> entry : headPointerList) {
// 添加频繁项集(需要深复制一个新的List)
List<String> newFrequentItemSet = new ArrayList<>(preFrequentItemSet);
newFrequentItemSet.add(entry.getKey());
addFrequentItemSet(newFrequentItemSet);
// 获取条件模式基
List<ConditionalPatternBase> conditionalPatternBases = getConditionalPatternBases(entry.getValue());
// 创建fp树(将条件模式基集合作为新的数据集)
Map<String, HeadPointer> nextHeadPointerTable = new HashMap<>();
TreeNode root = new TreeNode();
epoch(conditionalPatternBases, nextHeadPointerTable, root);
// 递归获取频繁项集
collectFrequentItemSet(nextHeadPointerTable, newFrequentItemSet);
}
}
/**
* 获取条件模式基集合
*
* @param ptr 头指针
* @return 条件模式基集合
*/
private static List<ConditionalPatternBase> getConditionalPatternBases(HeadPointer ptr) {
List<ConditionalPatternBase> conditionalPatternBases = new ArrayList<>();
// 遍历同项目链表
TreeNode currentNode = ptr.getHead();
while (currentNode != null) {
// 获取从根节点到该节点的路径
List<String> record = new ArrayList<>();
TreeNode leafNode = currentNode;
// 创建条件模式基
ConditionalPatternBase cpb = new ConditionalPatternBase(leafNode.getCount());
// 条件模式基不包括该节点
leafNode = leafNode.getParent();
while (leafNode.getItem() != null) {
record.add(leafNode.getItem());
leafNode = leafNode.getParent();
}
currentNode = currentNode.getNextSameItemNode();
// 添加路径记录
cpb.setRecord(record);
conditionalPatternBases.add(cpb);
}
return conditionalPatternBases;
}
/**
* 添加频繁项集
*
* @param frequentItemSet 频繁项集
*/
private static void addFrequentItemSet(List<String> frequentItemSet) {
// 要是频繁 k 项集没有实例化Set,实例化Set
Set<List<String>> set = FREQUENT_ITEM_SET_TABLE.computeIfAbsent(frequentItemSet.size(), k -> new HashSet<>());
set.add(frequentItemSet);
}
/**
* 修剪数据集、创建头指针表以及创建fp树
*
* @param dataset 数据集
* @param headPointerTable 头指针表
* @param root fp树根节点
*/
private static void epoch(List<ConditionalPatternBase> dataset, Map<String, HeadPointer> headPointerTable, TreeNode root) {
// 创建头指针表
createHeadPointerTable(dataset, headPointerTable);
// 对数据集进行枝剪和排序
pruningAndSort(dataset, headPointerTable);
// 创建fp树
crateFPTree(dataset, headPointerTable, root);
}
/**
* 加载数据
*
* @param filePath 文件路径
*/
private static List<ConditionalPatternBase> loadData(String filePath) {
Scanner scanner;
List<ConditionalPatternBase> dataset = new ArrayList<>();
try {
scanner = new Scanner(new File(filePath));
while (scanner.hasNext()) {
ConditionalPatternBase record = new ConditionalPatternBase();
record.setRecord(new ArrayList<>(Arrays.asList(scanner.nextLine().split(" "))));
dataset.add(record);
}
scanner.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return dataset;
}
/**
* 创建头指针表
*
* @param dataset 数据集
* @param headPointerMap 头指针表
*/
private static void createHeadPointerTable(List<ConditionalPatternBase> dataset, Map<String, HeadPointer> headPointerMap) {
// 遍历数据集,记录1项集出现的次数
for (ConditionalPatternBase record : dataset) {
for (String item : record.getRecord()) {
if (headPointerMap.containsKey(item)) {
// 增加计数
headPointerMap.get(item).increase(record.getCount());
} else {
// 添加一项集表头
headPointerMap.put(item, new HeadPointer(record.getCount()));
}
}
}
// 枝剪表头中小于最小出现次数的一项集
headPointerMap.values().removeIf(value -> value.getCount() < MIN_APPEAR);
}
/**
* 删除数据集中不满足要求的项目并且对每条记录进行降序排序
*
* @param dataset 数据集
* @param headPointerMap 头指针表
*/
private static void pruningAndSort(List<ConditionalPatternBase> dataset, Map<String, HeadPointer> headPointerMap) {
for (ConditionalPatternBase record : dataset) {
// 删除小于最小出现次数的项目
record.getRecord().removeIf(item -> headPointerMap.get(item) == null);
// 每条记录中的项目按出现次数降序排序
//record.sort((i1, i2) -> Integer.compare(HEAD_POINTER_TABLE.get(i2).getCount(), HEAD_POINTER_TABLE.get(i1).getCount()));
record.getRecord().sort((i1, i2) -> {
if (headPointerMap.get(i2).getCount() < headPointerMap.get(i1).getCount()) {
return -1;
} else if (headPointerMap.get(i2).getCount() > headPointerMap.get(i1).getCount()) {
return 1;
} else {
// 当两个项目出现次数一样时,需要再按ascii码排一次,保证相同支持度的项目也是有序排列的
return i1.compareTo(i2);
}
});
}
}
/**
* 创建 FP 树,完善头指针表
*
* @param dataset 数据集
* @param headPointerMap 头指针表
* @param root fp数根节点
*/
private static void crateFPTree(List<ConditionalPatternBase> dataset, Map<String, HeadPointer> headPointerMap, TreeNode root) {
for (ConditionalPatternBase record : dataset) {
// 从根节点开始
TreeNode currentNode = root;
for (String item : record.getRecord()) {
TreeNode child = currentNode.getChildren().get(item);
// 如果该路径节点不存在,新建一个
if (child == null) {
child = new TreeNode();
child.setItem(item);
child.setParent(currentNode);
// 添加节点
currentNode.getChildren().put(item, child);
// 连接头指针链表
headPointerMap.get(item).connect(child);
}
// 增加出现次数
child.increase(record.getCount());
currentNode = child;
}
}
}
}
五、为什么要迭代建树寻找频繁项集
为什么要以这样的方式迭代收集频繁项集,在网上实际上没有一个比较清晰的说法,这里我说一下我的理解。按照频繁项集的概念-“频繁项集的子集一定是频繁项集”,我们可以知道,频繁k项集一定是由频繁一项集中的项目组成的,这是前提。
我们以小票和商品作比喻来对这个过程进行解释。频繁项集说白了就是一些商品总是一起出现在小票上,所以我们认为这些商品有明显的或者隐含的关系。对于上面的例子,我们将每个项目理解为一种商品。首先在第一次扫描数据集后会把头指针表中不满足最小支持度的项目对应的表项删除,这就意味着此时头指针表中剩下的项目都是频繁一项集(满足最小支持度),也就是说这些单品卖的最火,由“频繁项集的子集一定是频繁项集”我们可以得知,卖的最火的商品组合一定是由卖的最火的这些单品组成的(比如肯德基的套餐的食品组合可能就是通过这类算法得到的),那我们获取频繁k项集为什么不从这些最火的单品(频繁一项集)开始呢?反正最火的商品组合(频繁k项集)一定包含这些最火的单品。
为了分析卖的最火的单品之一F与什么商品最容易一起出现,我们只需要从和单品F一起出现过的商品中筛选即可,而大家仔细品品,单品F的条件模式基不就是和单品F一起出现过的小票记录吗?对于F的条件模式基{A C E B, 2},我们也就很容易理解为什么F的条件模式基的记数为F节点的记数了,因为虽然单品A在所有小票中出现了8次,但与单品F一起出现了2次,所以该条件模式基的含义就是A、C、E、B与F同时出现了2次,而我们寻找与单品F有关的最火商品组合(包含F的频繁k项集),就要在A、C、E、B中找(在F的条件模式基中找)。
虽然F的条件模式基只有一个,但仍然可以推广到多个条件模式基,因为要是F有好几个节点,就代表着包含F的小票分布在FP树中的不同路径中罢了。
综上我们把F的条件模式基作为数据集重新筛选并建成FP树的过程,其实就是找与F同时出现次数更多的单品的过程。不同的是,树中的所有项目是在F出现的情况下出现的,可以理解为条件概率,这也是为什么以条件模式基建起的数被称为条件FP树。我们建立起以F的条件模式基为基础的条件FP树。
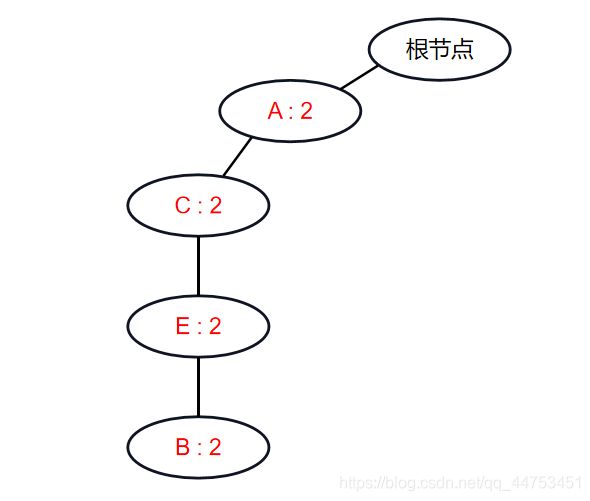
建树之后,我们还是找条件模式基,然后继续建树,直到无法建树为止。按照代码,我们在找B的条件模式基的同时,会将{F B}作为频繁2项集进行保存,实际上,B满足最小支持度,就意味着单品B即使在与单品F一起出现的情况下仍然是火爆的,所以{F B}显然也是包含单品F的情况下最火爆的商品组合之一,依次类推,我们再次创建在这棵条件FP树中以B的条件模式基为基础的条件FP树。

按照代码,我们在找E的条件模式基的同时,会将{F B E}作为频繁3项集进行保存。E满足最小支持度,就意味着单品E即使在与商品组合{F B}一起出现的情况下仍然是火爆的,所以{F B E}显然也是包含商品组合{F B}的情况下最火爆的商品组合之一。
这样,大家就能理解收集频繁项集的实际意义了吧。所以在第一次创建FP树后,对项目N(在迭代过程中可能就是项目集了)的条件模式基进行迭代建树过程,实际上就是寻找包含项目N的频繁项集的过程。
六、总结
抽空总结了一下fp-growth算法,如果发现了什么问题,可以评论区回复或者私信我,以及我还是比较建议大家着重看看第五段的,因为网上没几乎没有材料说明白这个问题,虽然第五段的内容只是我自己的理解,但应该还是有一定可信度的,如果大家发现了问题,也可以和我说。
算法演示数据集参考推荐系统实践(二)FPGrowth感谢博主的辛勤付出!