分布式系统的一致性和一致性模型详解
分布式系统的一致性和一致性模型详解
- 一、分布式系统
- 二、一致性
-
- 描述一致性的角度
- 一致性的观测方式
- 三、一致性模型
-
- happen before关系
- 单调读(Monotonic Reads)
- 单调写(Monotonic Writes)
- 写后读 / 读你所写(Read Your Writes)
- PRAM(Pipeline Random Access Memory) / FIFO
- 读后写(Writes Follow Reads)
- 因果一致性(Causal Consistency)
- 顺序一致性(Sequential Consistency)
- 线性一致性(Linearizability)
- 最终一致性(Eventual Consistency)
- 四、总结
一、分布式系统
在介绍一致性之前,我们首先回顾一下分布式系统。
分布式系统是由相互独立的逻辑单元组成的系统,逻辑单元间并发地依托特定的消息传递方式相互交流。往小了说,分布式系统可以是多核下的内存读写模型,不同的cpu通过内存进行相互交流,保证用户程序在多进程的场景下正确执行;往大了说,分布式系统也可以是对现实世界的高度抽象,每个人通过感官行为进行信息交流。通常,我们说的分布式系统是建立在网络上的服务器集群,服务器间通过网络进行交流,结合多服务器的计算和存储资源以解决单点系统的性能瓶颈和容灾能力差等问题。
分布式系统的最终目标是能够表现地像单点系统一样,但在现实情况下我们需要考虑的问题很多从而导致该目标难以实现:
- 如果分布式系统中的一个节点故障,系统是否还能正常提供服务?如果故障了两个、三个呢?
- 网络环境是不可靠的,可能会出现延迟、丢包、乱序,不同节点上的数据是否能保持一致?能达到什么程度的一致?
- 网络可能出现分区,此时系统是否还能正常提供服务?
- …
CAP理论根据上述现实可能出现的情况给出了一个衡量分布式系统的标准,指的是在一个分布式系统中,CAP三个条件不能同时被满足,只能任选其二。其中:
- C:一致性(Consistency),指在同一时刻客户端对分布式系统中任意节点的读取结果应该是一致的;
- A:可用性(Availability),指分布式系统提供的服务应一直处于可用状态;
- P:分区容错性(Partiton Tolerance),指分布式系统在网络出现分区(节点间不能正常通信)的情况下仍能正常提供服务。
我们考虑某一时刻分布式系统中出现了网络分区,系统被隔离成为两个孤岛,为了保持服务的正常运行必须选择P,此时需要在C和A中做出权衡,如果让两个孤岛都能提供可用的服务,即选择了A,那么两个孤岛处理不同的请求会导致它们存储的数据出现偏离,会导致孤岛间数据的不一致(放弃了C);为了保持两个孤岛间数据的一致性,即选择了C,那么两个孤岛必须停止提供服务(至少停止提供写服务),此时便放弃了可用性(放弃了A);如果既想保证一致性,也想保持可用性,那么每个节点的数据需要通过网络进行数据同步,只有在没出现网络分区的情况下才行,因此放弃了P。
因为在分布式系统中网络分区是不可避免的,因此P通常是必选项,需要在C和A之中做出取舍
分区容错性中提到的网络分区实际上是一个很宽泛的概念,在分布式系统中没有可靠的故障检测机制,如果在一定时间内没有收到某节点的消息(向该节点发送消息后在一定时间内没有收到响应;或在一定时间内没有收到该节点的心跳),就认为该节点故障。但我们没法确定故障节点是因为网络分区、网络延迟还是服务器宕机导致没有消息传出。这里我们认为分区容错性提到的网络分区等价为上述的节点故障,举个例子,在100个节点的分布式系统中忽然有一个节点失联(无法确定是真的网络分区或是网络延时、节点宕机),我们就认为出现了网络分区,在C和A之间的权衡其实就是决定剩下99个节点是否继续提供可用的服务,若提供,那么失联的那个节点一定会与另外99个节点产生数据的不一致
可以看出,CAP理论比较极端,但世界不是非黑即白的,我们是否可以在容忍一定数量节点故障的前提下支持一定程度的一致性,是否可以保证不同节点的数据在有限时间内最终能达到一致的前提下支持一定程度的可用性?显然是可以的,相比起主从同步复制与主从异步复制,我们可以选择使用主从半同步复制、读写仲裁及共识算法等方式来对分布式系统一致性和可用性进行折衷,使其更加灵活。
通过共识算法等方式,分布式系统可以在异步的网络环境下,同时满足一定程度的可用性以及一定程度的一致性。此时,我们需要一定的标准来界定一定程度的范围。
通常我们可以通过以下指标来表示分布式系统可用性的强弱:
- 系统在保证服务正常运行的前提下能接受多少节点的故障(1/5、1/4、1/2);
- 系统在保证服务正常运行的前提下能接受节点什么类型的故障(拜占庭、非拜占庭);
- 系统在客户端低负载的情况下是否能保证低时延,在客户端高负载的情况下是否能保证高吞吐量,其指标能达到多少;
- …
同时,我们可以通过分级来对用户提供不同强度的一致性保证:
- 线性一致性;
- 顺序一致性;
- 因果一致性;
- 最终一致性;
- …
而本文后面要讲的一致性模型就是对不同的一致性强度建模使分布式系统的行为对用户来说是可预测的。
二、一致性
描述一致性的角度
在介绍一致性模型前,需要对分布式系统的一致性做一些补充。
通常,我们会通过两个角度来描述分布式系统的一致性,服务端角度以及客户端角度。
从服务端角度描述一致性是指分布式系统内部节点间数据的一致性。举个例子,在主从同步复制的场景下,只有当主从节点数据都落库后才响应客户端,此时主库和从库的数据一定是一致的;而在主从异步复制的场景下,主库数据落库后异步通知从库数据落库,无需等待从库应答便可响应客户端,因此某一时刻主库和从库的数据可能是不一致的。
从客户端角度描述一致性则是着眼于客户端观测到的分布式系统的行为。举个例子,在主从异步复制的场景下,我们只允许主库处理客户端的读写请求,那么在某一时刻,即使主库和从库的数据在服务端角度看来不一致,但在客户端角度看来是一致的(不同客户端的请求都由主库处理,读的都是主库的数据),只是损失了数据的可靠性。
一般来说,在不考虑一致性强度的情况下,我们可以简单的认为若一个系统在服务端角度满足一致性,那么在客户端角度也一定能满足一致性;但在客户端角度满足一致性不意味着在服务端角度也一定能满足一致性。分布式系统是面向客户(端)的,客户(端)并不关心分布式系统中每个节点的数据是否达成一致(在客户看来系统是黑盒),只关心分布式系统能否提供客户看来的一致性。也就是说不论分布式系统内的所有节点的数据是否一致,只要整个系统能使客户端看到其所需的一致即可。
实际上,依托经典的共识算法Paxos,我们可以轻松实现线性一致性(读操作也走Paxos流程),但Paxos能保证的也仅仅是在异步的网络环境中,在容忍一定节点故障的前提下,必定使整个系统对某一顺序的操作序列达成共识,尽可能使每个副本都维护该顺序的操作序列。虽然每个节点的数据不一定一致,但可以使系统对外表现一致。
在对一致性模型的理解中基于哪个角度并不关键,因为一致性模型定义的是分布式系统的表现/表象,而不是实现(或行为)/本质。客户端角度也可以转化为服务端角度,只要认为每个客户端在分布式系统内都有一个对应的代表(节点)即可。
一致性的观测方式
一致性在体现分布式系统数据一致的同时,也体现了事件顺序的一致。若任意时刻客户端看到的分布式系统的数据都是一致的,那么它们看到的分布式系统数据的展现顺序也一定是一致的。而客户端对分布式系统事件的观测顺序以及观测时延(客户端收到某一操作的成功响应到客户端观测到该操作造成的影响之间的时间差)是体现一致性强度的关键。
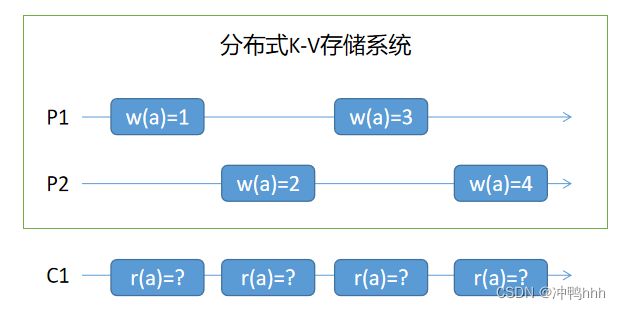
如上图,P1与P2两个节点(进程)组成了一个分布式K-V存储系统,并按图中顺序依次对变量a进行写操作。客户端C1在很短的时间间隔频繁读取变量a的值,那么C1看到的变量a的值的变化顺序可能是什么呢?
在不对系统做任何约束的情况下,C1有4!种读取结果的可能,为{r(a)=1, r(a)=2, r(a)=3, r(a)=4}的全排列,因为分布式系统存在时钟和网络不可靠的问题,我们不能确定P1和P2操作实际执行的顺序。此时该系统具有最弱的一致性,或者可以理解为不具有一致性。
若该系统实现了FIFO一致性,C1有7种读取结果的可能,因为在C1读取的结果中,r(a)=1一定在r(a)=3之前,r(a)=2一定在r(a)=4之前。此时系统的一致性强度有所提升。
若该系统实现了线性一致性,C1只有可能有一种读取结果,为r(a)=1 -> r(a)=2 -> r(a)=3 -> r(a)=4。此时系统拥有最强的一致性。
反过来想,如果C1读到的结果为r(a)=1 -> r(a)=2 -> r(a)=3 -> r(a)=4,那么其满足上述的三种一致性;如果读到的结果为r(a)=1 -> r(a)=3 -> r(a)=2 -> r(a)=4,那么其满足FIFO一致性而不满足线性一致性。
换个角度,如果系统能保证C1读到的结果只能是r(a)=1 -> r(a)=2 -> r(a)=3 -> r(a)=4,这就代表系统提供了线性一致性,我们就可以依据此预测分布式系统的行为,从而针对性地实现业务;如果系统能保证C1读到的结果为FIFO对应的7种结果中的一种,那么系统就提供了FIFO一致性,我们可以针对这可能的7种结果对应用层进行编程。
这就是一致性模型的基础。
三、一致性模型
一致性模型由事件序列的集合组成,保证客户端观测到的事件序列一定属于该集合,这就使得我们能够确定系统可能出现的所有情况,并进行针对性的处理。
换言之,一致性是分布式系统对自己做出的约束,一致性模型是分布式系统对用户做出的保证,使分布式系统的行为对用户来说是可预测的。如果一个系统满足线性一致性,根据其一致性模型我们可以确定系统事件发生的顺序,从而选择满足需求的业务场景(如OLTP数据库)。
在了解一致性模型的定义后,接下来对不同强度一致性模型进行详解。在讲解前推荐一个博客,该博客对一致性模型进行了很好的总结,本文下面的模型强弱关系也是参考了此博客。
JEPSEN一致性模型博客
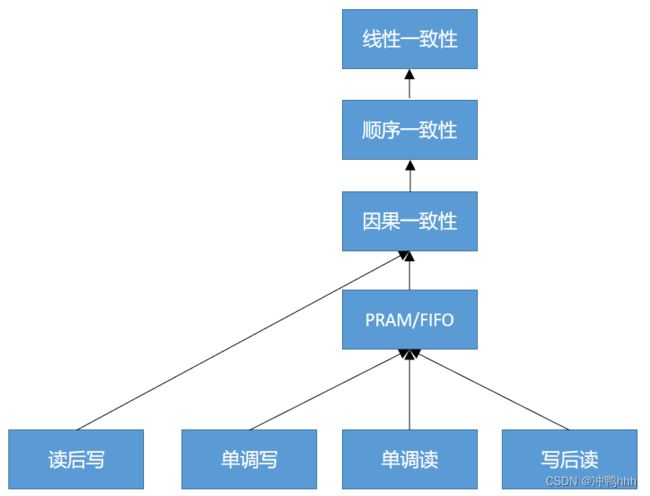
一致性模型的总体关系图如下,从下往上一致性逐渐增强。
happen before关系
首先,我们需要理解happen before关系(也可以称为因果关系)。happen before是Lamport在其分布式领域经典论文《Time, Clocks, and the Ordering of Events in a Distributed System》中提出的概念,用于衡量分布式系统中事件发生的先后顺序。

happen before关系满足:
- 同一进程中若事件a先于b发生,则
a happen before b,即a -> b;(体现在上图中的p1 -> p2) - 若进程P1的事件b观测到了进程P2的事件a造成的影响,则
a happen before b,即a -> b;(体现在上图中的p1 -> q2)
原文中第二点是通过消息的收发表示的,但我们可以认为原文中第二点是上述第二点的子集
同时,happen before关系满足传递律,若存在a -> b和b -> c,则有a -> c。
后续会通过happen before关系来表示一致性模型中事件的顺序。
单调读(Monotonic Reads)
一个节点先后成功执行读操作r1以及r2,r2不能读到比r1读到的数据所属的状态更早的状态对应的数据,也就是说r2一定会读到比r1更新的数据。
在不同节点上(real-time)先后发起的r1以及r2则不用满足r2读到的数据比r1更新的约束。
实现单调读的最简单的方式便是在分布式系统中由一个固定副本来处理读请求,在这种情况下,分布式系统的读行为与单点系统的读行为表现一致,显然可以实现单调读。
单调写(Monotonic Writes)
一个进程先后执行写操作w1以及w2,这两个操作若被其它进程感知,那么一定会感知到w1 -> w2,也就是说,其它副本若能观测到w1以及w2,那么其观测到的顺序一定先是w1再是w2。
在不同进程上(real-time)先后发起的w1以及w2则不需要所有副本都观测到先w1后w2的顺序。
写后读 / 读你所写(Read Your Writes)
一个进程先后执行操作w1以及r2,那么r2一定能读到w1对数据的更改,即w1 -> r2。
进程A先执行操作w1,然后进程B执行操作r2,那么进程B的操作r2不一定能读到w1对数据的更改。
PRAM(Pipeline Random Access Memory) / FIFO
实际上单独讨论单调读、单调写、写后读意义不大,需结合来看。
PRAM一致性为单调读、单调写、写后读的结合。该一致性模型完善了单进程上的因果关系,也就是说一个进程上的操作序列若被其它进程感知,那么它们感知到的序列顺序一定是一致的,但不同进程上的操作序列在不违背单进程序列顺序的情况下可能出现任意穿插的情况。
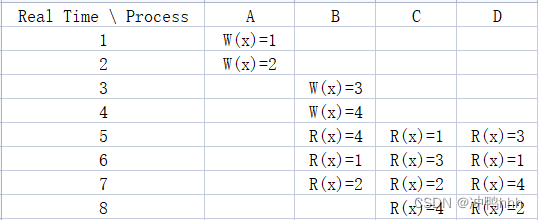
上图则为PRAM的例子,我们可以发现其满足了单调读、单调写、读你所写三种一致性的约束。
单调读体现在进程B在5、6、7的读操作上,进程B在4读到x=4后的读操作并没有读到旧的数据(虽然A在1、2的写操作在real time上早于B的读操作,但由于不存在因果关系,所以B并不知道A的写操作发生地更早)。
单调写体现在:由A可知写操作的顺序为W(x)=1 -> W(x)=2(W(x)=1 happen before W(x)=2),由B可知写操作的顺序为W(x)=3 -> W(x)=4(W(x)=3 happen before W(x)=4)。C和D观测到了这些写操作,虽然它们读取到x值的顺序不同,但都满足W(x)=1 happen before W(x)=2以及W(x)=3 happen before W(x)=4。
读你所写体现在进程B在4、5的操作上。5上的读操作读到了最新的写操作(W(x)=4 -> R(x)=4)。
实际上该一致性为单点结构上的线性一致性,只约束了单进程上的因果关系,并未考虑不同进程间的因果关系。
读后写(Writes Follow Reads)
如果一个进程A执行了写操作w1,然后进程B执行读操作r2,且r2读到了w1,那么进程B之后执行的写操作w3一定在w1后被观测到,即w1 -> r2 -> w3。
也就是说,通过Writes Follow Reads,实现了跨进程的因果联系(不同进程的操作间的因果联系)。当B的r2读到A的w1,就说明w1 happen before r2,而在B上容易得知r2 happen before w3,所以可以建立w1 -> w3的因果,其它进程观测到的顺序也应该是这样的。
因果一致性(Causal Consistency)
因果一致性为PRAM与Writes Follow Reads的结合。
Writes Follow Reads为不同进程间的操作传递了因果(通过读操作观测其它进程的写操作),因此因果一致性的每个进程都有自己的因果视角(就像人通过五感建立事件间的因果关系)。

如上图,进程A建立了W(x)=1 -> W(x)=2的因果,进程B在3时观测到了A的写操作,因此建立了W(x)=1 -> W(x)=2 -> R(x)=2 -> W(x)=3的因果(通过观测传递因果,B通过R(x)=2获取了A建立的W(x)=1 -> W(x)=2因果),进程C在5时观测到了B的W(x)=3操作,因此C建立了W(x)=1 -> W(x)=2 -> R(x)=2 -> W(x)=3 -> R(x)=3的视图,之后C在6时读到了x=1,此时违反了因果一致性,但并不违反PRAM,这是因为因果一致性要求因果可以在进程间传递(通过Writes Follow Reads)。
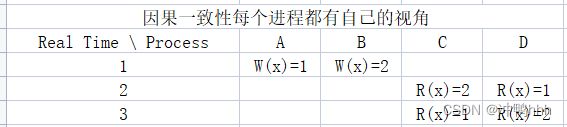
但若两个写操作之间没有因果,则不同的进程可能会存在不同的视图,如上图。C和D产生了不同的视图,会造成一定的麻烦。
因此还存在收敛因果一致性,指系统最终会收敛。即使现在C读到的x是1,D读到的x是2,最终C和D一定会读到相同的值。
顺序一致性(Sequential Consistency)
顺序一致性首次被提出是在1979年Lamport的论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》,要求:
- 执行结果与这些处理器以某一串行顺序执行的结果相同;
- 每个处理器内部操作的执行看起来又与程序描述的顺序一致。
这里我们需要关注的主要是第一点,分布式系统的执行结果与分布在不同进程上的事件以某一串行顺序执行结果相同。
本文在一致性的观测方式章节中通过客户端读取分布式K-V存储系统展现事件的顺序。因为客户端在很小的时间间隔频繁读数据,才可以读取到变量a的四次变化,也才产生了一个全局视野。但实际上,客户端并不一定能读取得足够频繁从而感知到事件的全局变化。
假设客户端C1读取到的顺序是r(a)=1 -> r(a)=2,C2读取到的是r(a)=2 -> r(a)=4,那么我们可以根据happen before原则的传递律,结合所有客户端的视角尽可能合成一个全局视野,为r(a)=1 -> r(a)=2 -> r(a)=4,此时认为该执行结果可以与w(a)=1 -> r(a)=1 -> w(a)=2 -> r(a)=2 -> w(a)=3 -> w(a)=4 -> r(a)=4这一事件序列串行顺序执行结果相同。

但对于因果一致性,如上图,可以获取四个进程的视角,A为W(x)=1,B为W(x)=2,C为R(x)=2 -> R(x)=1,D为R(x)=1 -> R(x)=2。但依托这四个进程的视角,我们不能将其合成一个串行的事件序列,因为C和D的视角冲突,我们没法构建R(x)=1和R(x)=2在全局视角下的因果关系,因此没有满足顺序一致性。这也体现了因果一致性的约束强度比顺序一致性低。
因果一致性只要求事件的发生顺序满足happen before原则,顺序一致性在此基础上还要求每个进程观测到的事件序列一定都是某一串行事件序列的子序列。
但是顺序一致性没有实时性要求。在某一时刻进程A对x的读操作的结果为R(x)=3,然后该进程执行了写操作w(x)=4并收到了成功,建立了w(x)=3 -> w(x)=4的全局序列,那么此时某进程B可以读到R(x)=3,只要保证w(x)=4在w(x)=3之后可见即可,只要事件的可见性严格遵循全局序列,就可以满足顺序一致性。
线性一致性(Linearizability)
线性一致性在顺序一致性的基础上强调实时性,当一个进程的某个写操作w1结束(可以看作客户端收到了响应,并提示成功)后,后续w1对于任意进程的任意操作都应该是立即可见的,如下图。
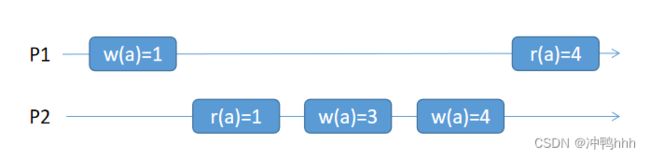
然而,这种实时性的实现通常会造成系统性能的降低(额外的通讯开销或更长的时延)。
最终一致性(Eventual Consistency)
通常,我们所说的强一致性就是线性一致性,CAP理论中的一致性指的就是线性一致性。而弱一致性指的是最终一致性,BASE原理中的E指的就是最终一致性。
最终一致性要求客户端在某一时刻可能在分布式系统中读取到不一致甚至旧的数据,但最终系统会收敛并保持一致。
实际上最终一致性相比起保证系统的一致性,更像是保证系统的活性(liveness)。比如因果一致性不一定能保证系统的收敛,也就是说一个系统能满足因果一致性,但却不一定满足最终一致性。
四、总结
能否正确理解一致性是能否更好理解分布式系统的基础。本文描述了我对分布式系统中一致性和一致性模型的理解,或许稍有偏颇,但应该可以为心中对一致性怀有困惑的同学稍解疑难。