Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向
文章目录
- 前言
- 1. 万用字符
- 2. 特殊字符
- 3. 数据流重导向
-
- 3.1标准输出
- 3.2 标准输入
- 总结
前言
这篇博客是对之前在查找的时候涉及到的一些通配符(bash里面就是万用字符)的整理。这个为后面管线相关打一个基础。
1. 万用字符
这里整理了一个表格,后面配上相关实例。
| 符号 | 含义 |
|---|---|
| * | 代表“ 0 个到无穷多个”任意字符 |
| ? | 代表“一定有一个”任意字符 |
| [ ] | 同样代表“一定有一个在括号内”的字符(非任意字符)。例如 [abcd] 代表“一定有一个字符, 可能是 a, b, c, d 这四个任何一个” |
| [ - ] | 若有减号在中括号内时,代表“在编码顺序内的所有字符”。例如 [0-9] 代表 0 到 9 之间的所有数字,因为数字的语系编码是连续的! |
| [ ^ ] | 若中括号内的第一个字符为指数符号 (^) ,那表示“反向选择”,例如 [^abc] 代表 一定有一个字符,只要是非 a, b, c 的其他字符就接受的意思。 |
实例:
以/etc目录下为例
在cd进/etc目录之后,通过ls可以看到非常多的文件,部分文件前缀重合,这样方便我们演示。
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第1张图片](http://img.e-com-net.com/image/info8/ea5f0e8129bb4ed894c6cf3042032679.jpg)
上图没有列全,下面还有好多文件。
例1:我们通过ls h*表示以h开头的文件,h后面接0/无穷个字符的文件都行。
这里我们可以看到列出的是h开头的一些文件以及以hp目录下hp开头的文件。它们都满足h开头的文件,只不过ubuntu把它们归了个类,说明了不同文件是当前目录的还是下面子目录的。
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第2张图片](http://img.e-com-net.com/image/info8/dddf22bf6aef4b09b8dcd14f67d5ea22.jpg)
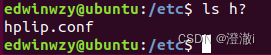
例2:现在要查找以host开头,并且一定是host后面还有一个字符的。
指令:ls host?
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第3张图片](http://img.e-com-net.com/image/info8/32b616a2263147caa51f0f777849ea06.jpg)
![]()
host开头的有很多,但host后面只有一个字符的只有hosts文件,所以通过ls host?查找的结果当然也就只有hosts文件。
例3:现在查找以h开头,并且一定是h后面有一个字符文件。
我们通过ls可以看到/etc目录下有一个hp子目录。
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第4张图片](http://img.e-com-net.com/image/info8/872520e7ee364b1e99ab963f3f220b0f.jpg)
当我们用ls h?的时候,它并不会显示hp目录,而是直接把hp里面的文件显示出来。这个和例2少许不同,值得注意。
例4:列出/etc目录下包含[wzy]三个字符中的任意一个字符为首且后面的字符不限制的文件。
指令:ls [wzy]*
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第5张图片](http://img.e-com-net.com/image/info8/3dee003919da4d5382d69ad797d36f15.jpg)
例5:列出/etc目录下包含x->z字符开头且后面字符不限的文件。
这里如果是目录,则会把对应目录的所有文件全列出来。
指令:ls [x-z]*
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第6张图片](http://img.e-com-net.com/image/info8/27d632b778e84cf6a24da8a815f9a3a5.jpg)
例6:和例5一样的效果,只不过采样反向选择方式。
指令:ls [^a-w]*
这里表示列出除了a->w开头的其他字母开头的文件,这里除了a->w,那就是xyz开头,所以实现的效果和上面例5是一样的。
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第7张图片](http://img.e-com-net.com/image/info8/d723fb1e48df4614abebd71747580c65.jpg)
2. 特殊字符
bash除了上面的万用字符,还有很多特殊字符。
下面列一个表格,方便查阅。
| 符号 | 内容 |
|---|---|
| # | 注解符号:这个最常被使用在 script 当中,视为说明!在后的数据均不执行 |
| \ | 跳脱符号:将“特殊字符或万用字符”还原成一般字符 |
| | | 管线 (pipe):分隔两个管线命令的界定(后两节介绍); |
| ; | 连续指令下达分隔符号:连续性命令的界定 (注意!与管线命令并不相同) |
| ~ | 使用者的主文件夹 |
| $ | 取用变量前置字符:亦即是变量之前需要加的变量取代值 |
| & | 工作控制 (job control):将指令变成背景下工作 |
| ! | 逻辑运算意义上的“非” not 的意思! |
| / | 目录符号:路径分隔的符号 |
| >, >> | 数据流重导向:输出导向,分别是“取代”与“累加” |
| <, << | 数据流重导向:输入导向 (这两个留待下节介绍) |
| ’ ’ | 单引号,不具有变量置换的功能 ($ 变为纯文本) |
| " " | 具有变量置换的功能! ($ 可保留相关功能) |
| `` | 两个 ` 中间为可以先执行的指令,亦可使用 $( ) |
| ( ) | 在中间为子 shell 的起始与结束 |
| { } | 在中间为命令区块的组合! |
3. 数据流重导向
3.1标准输出
这个词听起来挺高大上的,说简单点就是我输出的东西换个地方存。
比如我们之前用ls指令查看当前目录下的所有文件,那么控制台会直接输出到控制台界面。
我们如果想把这个输出的内容导入到我们创建第一个文件中,比如我在/home/edwinwzy/LearnOfLinux目录下创建一个空文件datatre,
我想将/etc目录下用ls指令输出的内容存放到datatre中,我可以这样做:ls >/home/edwinwzy/LearnOfLinux/datatre
这里datatre文件可以不用创建,因为我们使用指令的时候,如果没有这个文件,系统会自动创建并且保存数据到该文件。
下图左边是指令,右边是文件内的数据。
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第8张图片](http://img.e-com-net.com/image/info8/8aec786c44964d23a438d80292c0a5b1.jpg)
上面是数据流重导向的常规运用,下面结合书上的内容对数据流重导向进行详细介绍。
我们执行一个指令的时候,这个指令可能会由文件读入数据,经过处理之后,再将数据输出到屏幕上。 通常数据信息包括标准的输出和错误输出,standard output 与 standard error output 分别代表“标准输出 (STDOUT)”与“标准错误输出 (STDERR)”, 这两个东西默认都是输出到屏幕上面来的。标准输出指的是“指令执行所回传的正确的讯息”,而标准错误输出可理解为“ 指令执行失败后,所回传的错误讯息”。
比如我们用ls查看habcd开头的文件,但其实我们/etc目录下没有,这时会就会提示没有这个文件,那么这就是标准错误输出。反之,如果有符号我们指令条件的文件,那就会显示该文件,这个文件的显示就是标准输出。
标准输入 (stdin) :代码为 0 ,使用 < 或 << ;
标准输出 (stdout):代码为 1 ,使用 > 或 >> ;
标准错误输出(stderr):代码为 2 ,使用 2> 或 2>> ;
这个小节一开始以及演示过用法,但是>与>>有什么不同,怎么用,下面给出解释。
>默认标准输出,而非标准错误输出。
1> :以覆盖的方法将“正确的数据”输出到指定的文件或设备上;
1>>:以累加的方法将“正确的数据”输出到指定的文件或设备上;
2> :以覆盖的方法将“错误的数据”输出到指定的文件或设备上;
2>>:以累加的方法将“错误的数据”输出到指定的文件或设备上;
如果我们想多个指令的输出放到同一个文件上,就会涉及到累加和覆盖情况,上面则列出了用法,用法比较简单,这里不演示了。
下面还有几个用法:
如果我知道错误讯息会发生,所以要将错误讯息忽略掉而不显示或储存呢? 这个时候黑洞设备 /dev/null 就很重要了!这个 /dev/null 可以吃掉任何导向这个设备的信息。
1.将错误的数据丢弃,屏幕上显示正确的数据
find /home -name .bashrc 2> /dev/null
2.无论正确是还是错误的数据统一都保存到一个文件中
find /home -name .bashrc > list 2> list -------错误写法
find /home -name .bashrc > list 2>&1 -----正确写法
错误写法为什么错?虽然它确实可以把正确和错误的数据统一的保存,但由于两股数据同时写入一个文件,又没有使用特殊的语法, 此时两股数据可能会交叉写入该文件内,造成次序的错乱。所以虽然最终 list 文件还是会产生,但是里面的数据排列就会怪怪的,而不是原本屏幕上的输出排序。
3.2 标准输入
上面写的都是通过指令输出数据,再把数据存放到一个文件中去。
那标准输入就是相反的过程,即本来由控制台输入的数据变成了从文件中读取数据。
举个例子应该就很好懂了。
我在当前目录下使用cat >data,如果没有data文件则会自动创建,接着输入123456,按ctrl+c。
此时一个含有123456文本名为data的文件创建了。

现在我要创建一个DATA文件,里面的数据内容是data的数据。
![]()
![Linux学习[17]bash学习深入3---万用字符&特殊符号---数据流重导向_第9张图片](http://img.e-com-net.com/image/info8/a8638a8ab6454b36abe21cffa540da77.jpg)
上面这个例子只是一个演示,实际运用还需要后面实践。
总结
这篇博客整理了万用字符和特殊符号,并对前者的用法进行了举例,同时详细阐述了数据流重导向,为后面的管线等学习打了个基础。