掌握ASP.NET之路:自定义实体类简介
摘要:有些情况下,非类型化的 DataSet 可能并非数据操作的最佳解决方案。本指南的目的就是探讨 DataSet 的一种替代解决方案,即:自定义实体与集合。(本文包含一些指向英文站点的链接。)
引言
ADODB.RecordSet 和常常被遗忘的 MoveNext 的时代已经过去,取而代之的是 Microsoft ADO.NET 强大而又灵活的功能。我们的新武器就是 System.Data 名称空间,它的特点是具有速度极快的 DataReader 和功能丰富的 DataSet,而且打包在一个面向对象的强大模型中。能够使用这样的工具一点都不奇怪。任何 3 层体系结构都依靠可靠的数据访问层 (DAL) 将数据层与业务层完美地连接起来。高质量的 DAL 有助于改善代码的重新使用,它是获得高性能的关键,而且是完全透明的。
随着工具的改进,我们的开发模式也发生了变化。告别 MoveNext 并不只是让我们摆脱了繁琐的语法,它还让我们认识了断开连接的数据,这种数据对我们开发应用程序的方式产生了深刻的影响。
因为我们已经熟悉了 DataReader(其行为与 RecordSet 非常类似),所以没花多长时间就进一步开发出 DataAdapter、DataSet、DataTable 和 DataView。正是在开发这些新对象的过程中不断得到磨炼的技能改变了我们的开发方式。断开连接的数据使我们可以利用新的缓存技术,从而大大提高了应用程序的性能。这些类的功能使我们能够编写出更智能、更强大的函数,同时还能减少(有时候甚至是大大减少)常见活动所需的代码数量。
有些情况下非常适合使用 DataSet,例如在设计原型、开发小型系统和支持实用程序时。但是,在企业系统中使用 DataSet 可能并不是最佳的解决方案,因为对企业系统来说,易于维护要比投入市场的时间更重要。本指南的目的就是探讨一种适合处理此类工作的 DataSet 的替代解决方案,即:自定义实体与集合。尽管还存在其他替代解决方案,但它们都无法提供相同的功能或无法获得更多的支持。我们的首要任务是了解 DataSet 的缺点,以便理解我们要解决的问题。
记住,每种解决方案都有优缺点,所以 DataSet 的缺点可能比自定义实体的缺点(我们也将进行讨论)更容易让您接受。您和您的团队必须自己决定哪个解决方案更适合您的项目。记住要考虑解决方案的总成本,包括要求改变的实质所在以及生产后所需的时间比实际开发代码的时间更长的可能性。最后请注意,我所说的 DataSet 并不是类型化的 DataSet,但它确实可以弥补非类型化的 DataSet 的一些缺点。
DataSet 存在的问题
缺少抽象
寻找替代解决方案的第一个也是最明显的原因就是 DataSet 无法从数据库结构中提取代码。DataAdapter 可以很好地使您的代码独立于基础数据库供应商(Microsoft、Oracle、IBM 等),但不能抽象出数据库的核心组件:表、列和关系。这些核心数据库组件也是 DataSet 的核心组件。DataSet 和数据库不仅共享通用组件,不幸的是,它们还共享架构。假定有下面这样一个 Select 语句:
SELECT UserId, FirstName, LastName FROM Users
我们知道这些值可以从 DataSet 中的 UserId、FirstName 和 LastName 这些 DataColumn 中获得。
为什么会这么复杂?让我们看一个基本的日常示例。首先我们有一个简单的 DAL 函数:
//C#
public DataSet GetAllUsers() {
SqlConnection connection = new SqlConnection(CONNECTION_STRING);
SqlCommand command = new SqlCommand("GetUsers", connection);
command.CommandType = CommandType.StoredProcedure;
SqlDataAdapter da = new SqlDataAdapter(command);
try {
DataSet ds = new DataSet();
da.Fill(ds);
return ds;
}finally {
connection.Dispose();
command.Dispose();
da.Dispose();
}
}
然后我们有一个页面,它使用重复器显示所有用户:
<HTML> <body> <form id="Form1" method="post" runat="server"> <asp:Repeater ID="users" Runat="server"> <ItemTemplate> <%# DataBinder.Eval(Container.DataItem, "FirstName") %> <br /> </ItemTemplate> </asp:Repeater> </form> </body> </HTML> <script runat="server"> public sub page_load users.DataSource = GetAllUsers() users.DataBind() end sub </script>
正如我们所看到的那样,我们的 ASPX 页面利用 DAL 函数 GetAllUsers 作为重复器的 DataSource。如果由于某种原因(为了性能而降级、为清楚起见而进行了标准化、要求发生了变化)导致数据库架构发生变化,变化就会一直影响 ASPX,即影响使用“FirstName”列名的 Databinder.Eval 行。这将立刻在您脑海中产生一个危险信号:数据库架构的变化会一直影响到 ASPX 代码吗?听起来不太像 N 层,对吗?
如果我们所要做的只是对列进行简单的重命名,那么更改本例中的代码并不复杂。但是,如果在许多地方都使用了 GetAllUsers,更糟糕的是,如果将其作为为无数用户提供服务的 Web 服务,那又会怎么样呢?怎样才能轻松或安全地传播更改?对于这个基本示例而言,存储过程本身作为抽象层可能已经足够;但是依赖存储过程获得除最基本的保护以外的功能则可能会在以后造成更大的问题。可以将此视为一种硬编码;实质上,使用 DataSet 时,您可能需要在数据库架构(不管使用列名称还是序号位置)和应用层/业务层之间建立一个严格的连接。但愿以前的经验(或逻辑)已经让您了解到硬编码对维护工作以及将来的开发产生的影响。
DataSet 无法提供适当抽象的另一个原因是它要求开发人员必须了解基础架构。我们所说的不是基础知识,而是关于列名称、类型和关系的所有知识。去掉这个要求不仅使您的代码不像我们看到的那样容易中断,还使代码更易于编写和维护。简单地说:
Convert.ToInt32(ds.Tables[0].Rows[i]["userId"]);
不仅难于阅读,而且需要非常熟悉列名称及其类型。理想情况下,您的业务层不需要知道有关基础数据库、数据库架构或 SQL 的任何内容。如果您像上述代码字符串中那样使用 DataSet(使用 CodeBehind 并不会有任何改善),您的业务层可能会很薄。
弱类型
DataSet 属于弱类型,因此容易出错,还可能会影响您的开发工作。这意味着无论何时从 DataSet 中检索值,值都以 System.Object 的形式返回,您需要对这种值进行转换。您面临转换可能会失败的风险。不幸的是,失败不是在编译时发生,而是在运行时发生。另外,在处理弱类型的对象时,Microsoft Visual Studio.NET (VS.NET) 等工具对您的开发人员并没有太大的帮助。前面我们说过需要深入了解构架的知识,就是指这个意思。我们再来看一个非常常见的示例:
'Visual Basic.NET
Dim userId As Integer =
? Convert.ToInt32(ds.Tables(0).Rows(0)("UserId"))
Dim userId As Integer = CInt(ds.Tables(0).Rows(0)("UserId"))
Dim userId As Integer = CInt(ds.Tables(0).Rows(0)(0))
//C#
int userId = Convert.ToInt32(ds.Tables[0].Rows[0]("UserId"));
这段代码显示了从 DataSet 中检索值的可能方法——可能您的代码中到处都需要检索值(如果不进行转换,而您使用的又是 Visual Basic .NET,您可能会使用 Option Strict Off 这样的代码,而这会给您带来更大的麻烦。)
不幸的是,这些代码中的每一行都可能会产生大量的运行时错误:
| 1. |
转换可能由于以下原因而失败:
|
||||||
| 2. |
ds.Tables(0) 可能返回一个空引用(如果 DAL 方法或存储过程中有任何部分失败)。 |
||||||
| 3. |
“UserId”可能由于以下原因而是一个无效的列名称:
|
我们可以修改代码并以更安全的方式编写,即为 null/nothing 添加检查,为转换添加 try/catch,但这些对开发人员都没有帮助。
更糟糕的是,正如我们前面所说,这不是抽象的。这意味着,每次要从 DataSet 中检索 userId 时,您都将面临上面提到的风险,或者需要对相同的保护性步骤进行重新编程(当然,实用程序功能可能会有助于降低风险)。弱类型对象将错误从设计时或编译时(这时总能够自动检测并轻松修复错误)转移到运行时(这时的错误可能会出现在生产过程中,而且更难查明)。
非面向对象
您不能仅仅因为 DataSet 是对象,而 C# 和 Visual Basic .NET 是面向对象 (OO) 的语言就能以面向对象的方式使用 DataSet。OO 编程的“hello world”是一个典型的 Person 类,该类又是 Employee 的子类。但 DataSet 并没有使此类继承或其他大多数 OO 技术成为可能(或者至少使它们变得自然/直观)。Scott Hanselman 是类实体的坚决支持者,他做出了最好的解释:
“DataSet 是一个对象,对吗?但它并不是域对象,它不是一个‘苹果’或‘桔子’,而是一个‘DataSet’类型的对象。DataSet 是一只碗(它知道支持数据存储)。DataSet 是一个知道如何保存行和列的对象,它非常了解数据库。但是,我不希望返回碗,我希望返回域对象,例如‘苹果’。”1
DataSet 使数据之间保持一种关系,使它们更强大并且能够在关系数据库中方便地使用。不幸的是,这意味着您将失去 OO 的所有优点。
因为 DataSet 不能作为域对象,所以无法向它们添加功能。通常情况下,对象具有字段、属性和方法,它们的行为针对的是类的实例。例如,您可能会将 Promote 或 CalcuateOvertimePay 函数与 User 对象相关联,该对象可以通过 someUser.Promote() 或 someUser.CalculateOverTimePay() 安全地调用。因为无法向 DataSet 添加方法,所以您需要使用实用程序功能来处理弱类型对象,并且在整个代码中包含硬编码值的更多实例。您一般会以过程代码结束,在过程代码中,您要么不断地从 DataSet 中获取数据,要么以繁琐的方式将它们存储在本地变量中并向其他位置传递。两种方法都有缺点,而且都没有任何优点。
与 DataSet 相反的情况
如果您认为数据访问层应返回 DataSet,您可能会漏掉一些重要的优点。其中一个原因是您可能正在使用一个较薄或不存在的业务层,除了其他问题外,它还限制了您进行抽象的能力。另外,因为您使用的是一般的预编译解决方案,所以很难利用 OO 技术。最后,Visual Studio.NET 等工具使开发人员无法轻松地利用弱类型对象(例如 DataSet),因此降低了效率并且增加了出错的可能性。
所有这些因素都以不同的方式对代码的可维护性产生了直接的影响。缺乏抽象使功能改善和错误修复变得更复杂、更危险。您无法充分利用 OO 提供的代码重新使用或可读性方面的改进。当然还有一点,无论您的开发人员处理的是业务逻辑还是表示逻辑,他们都必须非常了解您的基础数据结构。
自定义实体类
与 DataSet 有关的大多数问题都可以利用 OO 编程的丰富功能在定义明确的业务层中解决。实际上,我们希望获得按照关系组织的数据(数据库),并将数据作为对象(代码)使用。这个概念就是,不是获得保存汽车信息的 DataTable,而是获得汽车对象(称为自定义实体或域对象)。
在了解自定义实体之前,让我们首先看一看我们将要面临的挑战。最明显的挑战就是所需代码的数量。我们不是简单地获取数据并自动填充 DataSet,而是获取数据并手动将数据映射到自定义实体(必须先创建好)。由于这是一项重复性的任务,我们可以使用代码生成工具或 O/R 映射器(后文有详细的介绍)来减轻工作量。更大的问题是将数据从关系世界映射到对象世界的具体过程。对于简单的系统,映射通常是直接的,但是随着复杂性的增加,这两个世界之间的差异就会产生问题。例如,继承在对象世界中是获得代码重新使用以及可维护性的重要技术。不幸的是,继承对关系数据库来说却是一个陌生的概念。另外一个例子就是处理关系的方式不同:对象世界依靠维护单个对象的引用,而关系世界则是利用外键。
因为代码的数量以及关系数据和对象之间的差异不断增加,看起来这个方法并不太适合更复杂的系统,但事实正好相反。通过将各种问题隔离到一个层中,即映射过程(同样可以自动化),复杂的系统也可以从此方法获益。另外,此方法已经很常用,这意味着可以通过几种已有的设计模式彻底解决增加的复杂性。前面讨论的 DataSet 的缺点在复杂系统中将成倍扩大,最后您会得出这样一个系统,它欠缺灵活应变能力的缺点恰好超出其构建的难度。
什么是自定义实体?
自定义实体是代表业务域的对象,因此,它们是业务层的基础。如果您有一个用户身份验证组件(本指南通篇都使用该示例进行讲解),您就可能具有 User 和 Role 对象。电子商务系统可能具有 Supplier 和 Merchandise 对象,而房地产公司则可能具有 House、Room 和 Address 对象。在您的代码中,自定义实体只是一些类(实体和“类”之间具有非常密切的关系,就像在 OO 编程中使用的那样)。一个典型的 User 类可能如下所示:
//C#
public class User {
#region "Fields and Properties"
private int userId;
private string userName;
private string password;
public int UserId {
get { return userId; }
set { userId = value; }
}
public string UserName {
get { return userName; }
set { userName = value; }
}
public string Password {
get { return password; }
set { password = value; }
}
#endregion
#region "Constructors"
public User() {}
public User(int id, string name, string password) {
this.UserId = id;
this.UserName = name;
this.Password = password;
}
#endregion
}
为什么能够从它们获益?
使用自定义实体获得的主要好处来自这样一个简单的事实,即它们是完全受您控制的对象。具体而言,它们允许您:
| • | 利用继承和封装等 OO 技术。 |
| • | 添加自定义行为。 |
例如,我们的 User 类可以通过为其添加 UpdatePassword 函数而受益(我们可能会使用外部/实用程序函数对数据集执行此类操作,但会影响可读性/维护性)。另外,它们属于强类型,这表示我们可以获得 IntelliSense 支持:
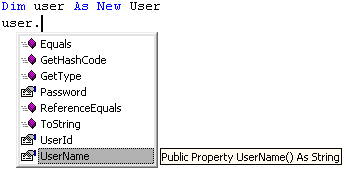
图 1:User 类的 IntelliSense
最后,因为自定义实体为强类型,所以不太需要进行容易出错的强制转换:
Dim userId As Integer = user.UserId
'与
Dim userId As Integer =
? Convert.ToInt32(ds.Tables("users").Rows(0)("UserId"))
对象关系映射
正如前文所讨论的那样,此方法的主要挑战之一就是处理关系数据和对象之间的差异。因为我们的数据始终存储在关系数据库中,所以我们只能在这两个世界之间架起一座桥梁。对于上文的 User 示例,我们可能希望在数据库中建立一个如下所示的用户表:

图 2:User 的数据视图
从这个关系架构映射到自定义实体是一个非常简单的事情:
//C#
public User GetUser(int userId) {
SqlConnection connection = new SqlConnection(CONNECTION_STRING);
SqlCommand command = new SqlCommand("GetUserById", connection);
command.Parameters.Add("@UserId", SqlDbType.Int).Value = userId;
SqlDataReader dr = null;
try{
connection.Open();
dr = command.ExecuteReader(CommandBehavior.SingleRow);
if (dr.Read()){
User user = new User();
user.UserId = Convert.ToInt32(dr["UserId"]);
user.UserName = Convert.ToString(dr["UserName"]);
user.Password = Convert.ToString(dr["Password"]);
return user;
}
return null;
}finally{
if (dr != null && !dr.IsClosed){
dr.Close();
}
connection.Dispose();
command.Dispose();
}
}
我们仍然按照通常的方式设置连接和命令对象,但接着创建了 User 类的一个新实例并从 DataReader 中填充该实例。您仍然可以在此函数中使用 DataSet 并将其映射到您的自定义实体,但 DataSet 相对于 DataReader 的主要好处是前者提供了数据的断开连接的视图。在本例中,User 实例提供了断开连接的视图,使我们可以利用 DataReader 的速度。
等一下!您并没有解决任何问题!
细心的读者可能注意到我前面提到 DataSet 的问题之一是它们并非强类型,这导致效率降低并增加了出现运行时错误的可能性。它们还需要开发人员深入了解基础数据结构。看一看上文的代码,您可能会注意到这些问题依然存在。但请注意,我们已经将这些问题封装到一个非常孤立的代码区域内;这表示您的类实体的使用者(Web 界面、Web 服务使用者、Windows 表单)仍然完全没有意识到这些问题。相反,使用 DataSet 可以将这些问题分散到整个代码中。
改进
上文的代码对显示映射的基本概念很有用,但可以在两个关键的方面进行改进。首先,我们需要提取并将代码填充到其自己的函数中,因为代码有可能会被重新使用:
//C#
public User PopulateUser(IDataRecord dr) {
User user = new User();
user.UserId = Convert.ToInt32(dr["UserId"]);
//检查 NULL 的示例
if (dr["UserName"] != DBNull.Value){
user.UserName = Convert.ToString(dr["UserName"]);
}
user.Password = Convert.ToString(dr["Password"]);
return user;
}
第二个需要注意的事项是,我们不对映射函数使用 SqlDataReader,而是使用 IDataRecord。这是所有 DataReader 实现的接口。使用 IDataRecord 使我们的映射过程独立于供应商。也就是说,我们可以使用上一个函数从 Access 数据库中映射 User,即使它使用 OleDbDataReader 也可以。如果您将这个特定的方法与 Provider Model Design Pattern(链接 1、链接 2)结合使用,您的代码就可以轻松地用于不同的数据库提供程序。
最后,以上代码说明了封装的强大功能。处理 DataSet 中的 NULL 并非最简单的事,因为每次提取值时都需要检查它是否为 NULL。使用上述填充方法,我们在一个地方就轻松地解决了此问题,使我们的客户无需处理它。
映射到何处?
关于此类数据访问和映射函数的归属问题存在一些争论,即究竟是作为独立类的一部分,还是作为适当自定义实体的一部分。将所有用户相关的任务(获取数据、更新和映射)都作为 User 自定义实体的一部分当然很不错。这在数据库架构与自定义实体很相似时会很有用(比如在本例中)。随着系统复杂性的增加,这两个世界的差异开始显现出来,将数据层和业务层明确分离对简化维护有很大的帮助(我喜欢将其称为数据访问层)。将访问和映射代码放在其自己的层 (DAL) 上有一个副作用,即它为确保数据层与业务层的明确分离提供了一个严格的原则:
“永远不要从 System.Data 返回类或从 DAL 返回子命名空间”
自定义集合
到目前为止,我们只了解了如何处理单个实体,但您经常需要处理多个对象。一个简单的解决方案是将多个值存储在一个一般的集合(例如 Arraylist)中。这并非最理想的解决方案,因为它又产生了与 DataSet 有关的一些问题,即:
| • | 它们不是强类型,并且 |
| • | 无法添加自定义行为。 |
最能满足我们需求的解决方案是创建我们自己的自定义集合。幸亏 Microsoft .NET Framework 提供了一个专门为了此目的而继承的类:CollectionBase。CollectionBase 的工作原理是,将所有类型的对象都存储在专有 Arraylist 中,但是通过只接受特定类型(例如 User 对象)的方法来提供对这些专有集合的访问。也就是说,将弱类型代码封装在强类型的 API 中。
虽然自定义集合可能看起来有很多代码,但大多数都可以由代码生成功能或通过剪切和粘贴方便地完成,并且通常只需要一次搜索和替换即可。让我们看一看构成 User 类的自定义集合的不同部分:
//C#
public class UserCollection :CollectionBase {
public User this[int index] {
get {return (User)List[index];}
set {List[index] = value;}
}
public int Add(User value) {
return (List.Add(value));
}
public int IndexOf(User value) {
return (List.IndexOf(value));
}
public void Insert(int index, User value) {
List.Insert(index, value);
}
public void Remove(User value) {
List.Remove(value);
}
public bool Contains(User value) {
return (List.Contains(value));
}
}
通过实现 CollectionBase 可以完成更多任务,但上面的代码代表了自定义集合所需的核心功能。观察一下 Add 函数,可以看出我们只是简单地将对 List.Add(它是一个 Arraylist)的调用封装到仅允许 User 对象的函数中。
映射自定义集合
将我们的关系数据映射到自定义集合的过程与我们对自定义实体执行的过程非常相似。我们不再创建一个实体并将其返回,而是将该实体添加到集合中并循环到下一个:
//C#
public UserCollection GetAllUsers() {
SqlConnection connection = new SqlConnection(CONNECTION_STRING);
SqlCommand command =new SqlCommand("GetAllUsers", connection);
SqlDataReader dr = null;
try{
connection.Open();
dr = command.ExecuteReader(CommandBehavior.SingleResult);
UserCollection users = new UserCollection();
while (dr.Read()){
users.Add(PopulateUser(dr));
}
return users;
}finally{
if (dr != null && !dr.IsClosed){
dr.Close();
}
connection.Dispose();
command.Dispose();
}
}
我们从数据库中获得数据、创建自定义集合,然后通过在结果中循环来创建每个 User 对象并将其添加到集合中。同样要注意 PopulateUser 映射函数是如何重新使用的。
添加自定义行为
在讨论自定义实体时,我们只是泛泛地提到可以将自定义行为添加到类中。您向实体中添加的功能类型很大程度上取决于您要实现的业务逻辑的类型,但您可能希望在自定义集合中实现某些常见的功能。一个示例就是返回一个基于某个键的实体,例如基于 userId 的用户:
//C#
public User FindUserById(int userId) {
foreach (User user in List) {
if (user.UserId == userId){
return user;
}
}
return null;
}
另一个示例可能是返回基于特定标准(例如部分用户名)的用户子集:
//C#
public UserCollection FindMatchingUsers(string search) {
if (search == null){
throw new ArgumentNullException("search cannot be null");
}
UserCollection matchingUsers = new UserCollection();
foreach (User user in List) {
string userName = user.UserName;
if (userName != null && userName.StartsWith(search)){
matchingUsers.Add(user);
}
}
return matchingUsers;
}
可以通过 DataTable.Select 以相同的方式使用 DataSets。需要说明的重要一点是,尽管创建自己的功能使您可以完全控制您的代码,但 Select 方法为完成同样的操作提供了一个非常方便且不需要编写代码的方法。但另一方面,Select 需要开发人员了解基础数据库,而且它不是强类型。
绑定自定义集合
我们看到的第一个示例是将 DataSet 绑定到 ASP.NET 控件。考虑到它很普通,您会高兴地发现自定义集合绑定同样很简单(这是因为 CollectionBase 实现了用于绑定的 Ilist)。自定义集合可以作为任何控件的 DataSource,而 DataBinder.Eval 只能像您使用 DataSet 那样使用:
//C# UserCollection users = DAL.GetAllUsers(); repeater.DataSource = users; repeater.DataBind(); <!-- HTML --> <asp:Repeater onItemDataBound="r_IDB" ID="repeater" Runat="server"> <ItemTemplate> <asp:Label ID="userName" Runat="server"> <%# DataBinder.Eval(Container.DataItem, "UserName") %><br /> </asp:Label> </ItemTemplate> </asp:Repeater>
您可以不使用列名称作为 DataBinder.Eval 的第二个参数,而指定您希望显示的属性名称,在本例中为 UserName。
对于在许多数据绑定控件提供的 OnItemDataBound 或 OnItemCreated 中执行处理的人来说,您可能会将 e.Item.DataItem 强制转换成 DataRowView。当绑定到自定义集合时,e.Item.DataItem 则被强制转换成自定义实体,在我们的示例中为 User 类:
//C#
protected void r_ItemDataBound(object sender, RepeaterItemEventArgs e) {
ListItemType type = e.Item.ItemType;
if (type == ListItemType.AlternatingItem ||
? type == ListItemType.Item){
Label ul = (Label)e.Item.FindControl("userName");
User currentUser = (User)e.Item.DataItem;
if (!PasswordUtility.PasswordIsSecure(currentUser.Password)){
ul.ForeColor = Color.Red;
}
}
}
管理关系
即使在最简单的系统中,实体之间也存在关系。对于关系数据库,可以通过外键维护关系;而使用对象时,关系只是对另一个对象的引用。例如,根据我们前面的示例,User 对象完全可以具有一个 Role:
//C#
public class User {
private Role role;
public Role Role {
get {return role;}
set {role = value;}
}
}
或者一个 Role 集合:
//C#
public class User {
private RoleCollection roles;
public RoleCollection Roles {
get {
if (roles == null){
roles = new RoleCollection();
}
return roles;
}
}
}
在这两个示例中,我们有一个虚构的 Role 类或 RoleCollection 类,它们就是类似于 User 和 UserCollection 类的其他自定义实体或集合类。
映射关系
真正的问题在于如何映射关系。让我们看一个简单的示例,我们希望根据 userId 及其角色来检索一个用户。首先,我们看一看关系模型:
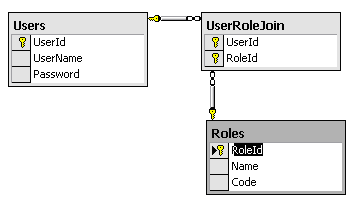
图 3:User 与 Role 之间的关系
这里,我们看到了一个 User 表和一个 Role 表,我们可以将这两个表都以直观的方式映射到自定义实体。我们还有一个 UserRoleJoin 表,它代表了 User 与 Role 之间的多对多关系。
然后,我们使用存储过程来获取两个单独的结果:第一个代表 User,第二个代表该用户的 Role:
CREATE PROCEDURE GetUserById( @UserId INT )AS SELECT UserId, UserName, [Password] FROM Users WHERE UserId = @UserID SELECT R.RoleId, R.[Name], R.Code FROM Roles R INNER JOIN UserRoleJoin URJ ON R.RoleId = URJ.RoleId WHERE URJ.UserId = @UserId
最后,我们从关系模型映射到对象模型:
//C#
public User GetUserById(int userId) {
SqlConnection connection = new SqlConnection(CONNECTION_STRING);
SqlCommand command = new SqlCommand("GetUserById", connection);
command.Parameters.Add("@UserId", SqlDbType.Int).Value = userId;
SqlDataReader dr = null;
try{
connection.Open();
dr = command.ExecuteReader();
User user = null;
if (dr.Read()){
user = PopulateUser(dr);
dr.NextResult();
while(dr.Read()){
user.Roles.Add(PopulateRole(dr));
}
}
return user;
}finally{
if (dr != null && !dr.IsClosed){
dr.Close();
}
connection.Dispose();
command.Dispose();
}
}
User 实例即被创建和填充;我们转移到下一个结果/选择并进行循环,填充 Role 并将它们添加到 User 类的 RolesCollection 属性中。
高级内容
本指南的目的是介绍自定义实体与集合的概念及使用。使用自定义实体是业界广泛采用的做法,因此,也就产生了同样多的模式以处理各种情况。设计模式具有优势的原因有很多。首先,在处理具体的情况时,您可能不是第一次碰到某个给定的问题。设计模式使您可以重新使用给定问题的已经过尝试和测试的解决方案(虽然设计模式并不意味着全盘照抄,但它们几乎总是能够为解决方案提供一个可靠的基础)。相应地,这使您对系统随着复杂性增加而进行缩放的能力充满了信心,不仅因为它是一个广泛使用的方法,还因为它具有详尽的记录。设计模式还为您提供了一个通用的词汇表,使知识的传播和传授更容易实现。
不能说设计模式只适用于自定义实体,实际上许多设计模式都并非如此。但是,如果您找机会试一下,您可能会惊喜地发现许多记载详尽的模式确实适用于自定义实体和映射过程。
最后这一部分专门介绍大型或较复杂的系统可能会碰到的一些高级情况。因为大多数主题都可能值得您单独学习,所以我会尽量为您提供一些入门资料。
Martin Fowler 的 Patterns of Enterprise Application Architecture 就是一个很好的入门材料,它不仅可以作为常见设计模式的优秀参考(具有详细的解释和大量的示例代码),而且它的前 100 页确实可以让您透彻地了解整个概念。另外,Fowler 还提供了一个联机模式目录,它对于已经熟悉概念但需要一个便利参考的人士很有用。
并发
前面的示例介绍的都是从数据库中提取数据并根据这些数据创建对象。总体而言,更新、删除和插入数据等操作是很直观的。我们的业务层负责创建对象、将对象传递给数据访问层,然后让数据访问层处理对象世界与关系世界之间的映射。例如:
//C#
public void UpdateUser(User user) {
SqlConnection connection = new SqlConnection(CONNECTION_STRING);
SqlCommand command = new SqlCommand("UpdateUser", connection);
// 可以借助可重新使用的函数对此进行反向映射
command.Parameters.Add("@UserId", SqlDbType.Int);
command.Parameters[0].Value = user.UserId;
command.Parameters.Add("@Password", SqlDbType.VarChar, 64);
command.Parameters[1].Value = user.Password;
command.Parameters.Add("@UserName", SqlDbType.VarChar, 128);
command.Parameters[2].Value = user.UserName;
try{
connection.Open();
command.ExecuteNonQuery();
}finally{
connection.Dispose();
command.Dispose();
}
}
但在处理并发时就不那么直观了,也就是说,当两个用户试图同时更新相同的数据时会出现什么情况呢?默认的行为(如果您没有执行任何操作)是最后提交数据的人将覆盖以前所有的工作。这可能不是理想的情况,因为一个用户的工作将在未获得任何提示的情况下被覆盖。要完全避免所有冲突,一种方法就是使用消极的并发技术;但此方法需要具有某种锁定机制,这可能很难通过可缩放的方式实现。替代方法就是使用积极的并发技术。让第一个提交的用户控制并通知后面的用户是通常采取的更温和、更用户友好的方法。这可以通过某种行版本控制(例如时间戳)来实现。
参考资料:
| • | |
| • | |
| • | |
| • | |
| • |
性能
与合理的灵活性和功能问题相对的是,我们经常担心细小的性能差异。尽管性能的确很重要,但提供适用于一切情况而不是最简单情况的通用原则通常很难。例如,将自定义集合与 DataSet 相比,哪个更快?使用自定义集合,您可以大量使用 DataReader,这是从数据库中提取数据的较快方式。但答案实际上取决于您使用它们的方式以及处理的数据类型,所以一般性的说明没有任何用。更重要的一点是要认识到,不管您能节省多少处理时间,与维护性方面的差异相比都可能微不足道。
当然,并不是说您不可能找到一个既具有高性能又可维护的解决方案。虽然我强调说答案实际上取决于您的使用方式,但的确有一些模式可以帮助您最大程度地提高性能。但是,首先要知道的是自定义实体与集合缓存以及 DataSet,并且能够利用相同的机制(类似于 HttpCache)。DataSet 的优势之一是它能够编写 Select 语句,以便只获取所需的信息。使用自定义实体时,您常常感到不得不填充整个实体以及子实体。例如,如果要通过 DataSet 显示一个 Organization 列表,您可以只提取 OganizationId、Name 和 Address 并将其绑定到重复器。使用自定义实体时,我总觉得还需要获取所有其他的 Organization 信息,如果该组织通过了 ISO 认证,则可能是一个位标记,即所有员工、其他联系信息等的集合。可能其他人没有碰到这个大难题,但幸运的是,如果我们愿意,我们可以对自定义实体进行很好的控制。最常用的方法是使用一种延迟加载模式,它只在首次需要时获取信息(可以很好地封装在属性中)。这种对各个属性的控制提供了通过其他方式无法轻易获得的巨大灵活性(请想象一下在 DataColumn 级别执行类似操作的情况)。
参考资料:
| • | Lazy Load 设计模式 |
| • |
排序与筛选
虽然 DataView 对排序和筛选的内置支持需要您了解有关 SQL 和基础数据结构的知识,但它提供的方便确实是自定义集合所不具备的。我们仍然可以排序和筛选,但首先需要编写功能。因为技术不一定是最先进的,所以代码的完整描述不属于本节要讨论的范围。大多数技术都很相似,例如使用筛选器类筛选集合以及使用比较器类进行排序,我认为不存在固定的模式。但是,的确存在一些参考资料:
| • | |
| • |
代码生成
解决概念上的障碍后,自定义实体与集合的主要缺点就是灵活性、抽象和维护性差所导致的代码数量的增加。实际上,您可能会认为我所说的维护成本和错误的降低这一切都抵不上代码的增加。虽然这一观点是成立的(同样,因为任何解决方案都不是完美无缺的),但可以通过设计模式和框架(例如 CSLA.NET)大大缓解此问题。代码生成工具与模式和框架完全不同,这些工具可以大大降低您实际需要编写的代码数量。本指南最初打算专门辟出一节详细介绍代码生成工具,特别是流行的免费 CodeSmith;但现有的许多参考资料都可能超出了我自己对该产品的认识。
在继续之前,我认识到代码生成听起来像天方夜谭一样。但经过正确的使用和理解后,它的确是您工具包中不可缺少的一个强大的武器,即使您没有处理自定义实体也是如此。虽然代码生成的确不仅仅适用于自定义实体,但很多都是专为自定义实体而设计的。原因很简单:自定义实体需要大量重复代码。
简言之,代码生成是如何工作的?构想听起来好像遥不可及甚至反而会降低效率,但您基本上通过编写代码(模板)来生成代码。例如,CodeSmith 附带了许多强大的类,使您可以连接到数据库并获取所有属性:表、列(类型、大小等)和关系。获得这些信息后,我们前面讨论的大部分工作都可以自动完成。例如,开发人员可以选择一个表,然后使用正确的模板自动创建自定义实体(带有正确的字段、属性和构造函数),并获得映射函数、自定义集合以及基本的选择、插入、更新和删除功能。甚至还可以更进一步,实现排序、筛选以及我们提到的其他高级功能。
CodeSmith 还附带了许多现成的模板,可以作为很好的学习资料。最后,CodeSmith 还为实现 CSLA.NET 框架提供了许多模板。我最初只花了几个小时来学习基本概念、熟悉 CodeSmith 的功能,但它为我节省的时间已经多得无法计算了。另外,如果所有的开发人员都使用相同的模板,代码的高度一致性将使您能够轻松地继续其他人的工作。
参考资料:
| • | |
| • |
O/R 映射器
即使因为对 O/R 映射器知之甚少使我不敢随便对它们发表议论,但它们自身的潜在价值使其不容忽视。代码生成器生成基于模板的代码,供您复制并粘贴到您自己的源代码中,而 O/R 映射器则在运行时通过某种配置机制动态生成代码。例如,在 XML 文件中,您可以指定某个表的列 X 映射到某个实体的属性 Y。您仍然需要创建自定义实体,但是集合、映射和其他数据访问函数(包括存储过程)都是动态创建的。从理论上讲,O/R 映射器几乎可以完全解决自定义实体存在的问题。随着关系世界和对象世界的差异越来越明显以及映射过程越来越复杂,O/R 映射器的价值就变得越发不可限量了。O/R 映射器的两个缺点据说就是不够安全和性能较差(至少在 .NET 环境中是这样)。根据我所阅读的资料,我确信它们并不是不够安全,虽然在有些情况下性能较差,但在另外一些情况下却表现突出。O/R 映射器并不适合所有情况,但如果您要处理复杂的系统,则应尝试一下它们的功能。
参考资料:
| • | Mapper 设计模式 |
| • | Data Mapper 设计模式 |
| • | |
| • | |
| • | |
| • |
.NET Framework 2.0 的功能
即将面世的 .NET Framework 2.0 版将改变我们在本指南中讨论的一些实施细节。这些改变将减少支持自定义实体所需的代码数量,并有助于处理映射问题。
泛型
议论颇多的泛型之所以存在,主要原因之一就是为了向开发人员提供现成的强类型的集合。我们避开 Arraylist 等现有集合是因为它们属于弱类型。泛型提供了与当前集合同样的方便性,而且它们属于强类型。这是通过在声明时指定类型来实现的。例如,我们可以替换 UserCollection 而不需要增加代码,然后只需创建一个 List<T> 泛型的新实例并指定我们的 User 类即可:
'Visual Basic .NET Dim users as new IList(of User) //C# IList<User> users = new IList<user>();
声明后,我们的 user 集合就只能处理 User 类型的对象了,这为我们提供了编译时检查和优化的所有优点。
参考资料:
| • | |
| • |
可以为空的类型
可以为空的类型实际上就是由于其他原因而非上述原因而使用的泛型。处理数据库时面临的挑战之一就是正确一致地处理支持 NULL 的列。在处理字符串和其他类(称为引用类型)时,您只需为代码中的某个变量指定 nothing/null:
'Visual Basic .NET
if dr("UserName") Is DBNull.Value Then
user.UserName = nothing
End If
//C#
if (dr["UserName"] == DBNull.Value){
user.UserName = null;
}
也可以什么都不做(默认情况下,引用类型为 nothing/null)。这对值类型(例如整数、布尔值、小数等)并不完全一样。您当然也可以为这些值指定 nothing/null,但这样将会指定一个默认值。如果您只声明整数,或者为其指定 nothing/null,变量的值实际上将为 0。这使其很难映射回数据库:值究竟为 0 还是 null?可以为空的类型允许值类型具有具体的值或者为空,从而解决了这个问题。例如,如果我们要在 userId 列中支持 null 值(并不是很符合实际情况),我们会首先将 userId 字段和对应的属性声明为可以为空的类型:
//C#
private Nullable<int> userId;
public Nullable<int> UserId {
get { return userId; }
set { userId = value; }
}
然后利用 HasValue 属性判断是否指定了 nothing/null:
//C#
if (UserId.HasValue) {
return UserId.Value;
} else {
return DBNull.Value;
}
参考资料:
| • | |
| • |
迭代程序
我们前面讨论的 UserCollection 示例只展示了自定义集合中可能需要的基本功能。有一个操作无法通过所提供的实现来完成,即通过一个 foreach 循环在集合中循环。要完成此操作,您的自定义集合必须具有实现 IEnumerable 接口的枚举数支持类。这是一个非常直观且重复性较强的过程,但却引入了更多的代码。C# 2.0 引入了新的 yield 关键字来为您处理此接口的实现细节。Visual Basic .NET 中当前没有与新的 yield 关键字等效的关键字。
参考资料:
| • | |
| • |
小结
请勿轻率地做出向自定义实体与集合转换的决定。这里有许多需要考虑的因素。例如,您对 OO 概念的熟悉程度、可用来熟悉新方法的时间以及您打算部署它的环境。虽然总体上它们有很大的优点,但并不一定适合您的特定情况。即使适合您的情况,它们的缺点也可能会打消您使用它们的念头。还要记住有许多可替代的解决方案。Jimmy Nilsson 在他的 Choosing Data Containers for .NET 中概述了其中的某些替代方案,此专栏系列包括 5 部分。
自定义实体使您获得了面向对象的编程的丰富功能,并帮助您构建了可靠、可维护的 N 层体系结构的框架。本指南的目的之一是让您从构成系统的业务实体,而不是一般的 DataSet 和 DataTable 的角度来考虑您的系统。我们还讨论了一些关键的问题,不管您选择的途径(即设计模式)、对象世界与关系世界的差异以及 N 层体系结构是什么,您都应注意这些问题。请记住,您之前花费的时间会在系统的整个生命周期内为您带来更多的回报。