云原生日志Agent/Aggregator
Loggie是一个基于Golang的轻量级、高性能、云原生日志采集Agent和中转处理Aggregator,支持多Pipeline和组件热插拔,提供了:
● 一栈式日志解决方案: 同时支持日志中转、过滤、解析、切分、日志报警等
● 云原生的日志形态: 快速便捷的容器日志采集方式,原生的Kubernetes CRD动态配置下发
● 生产级的特性: 基于长期的大规模运维经验,形成了全方位的可观测性、快速 排障、异常预警、自动化运维能力
我们可以基于Loggie,打造一套的云原生可扩展的全链路日志数据平台。
概念
核心数据流
● Source: 输入源,表示一个具体的输入源,一个Pipeline可以有多个不同的输入源。比如file source表示日志文件采集源,Kafka source为读取Kafka的输入源。
● Sink: 输出源,表示一个具体的输出源,一个Pipeline仅能配置一种类型的输出源,但是可以有多个并行实例。比如Elasticsearch sink表示日志数据将发送至远端的Elasticsearch。
● Interceptor: 拦截器,表示一个日志数据处理组件,不同的拦截器根据实现可以进行日志的解析、切分、转换、限流等。一个Pipeline可以有多个Interceptor,数据流经过多个Interceptor被链式处理。
● Queue: 队列,目前有内存队列。
● Pipeline: 管道,source/interceptor/queue/sink共同组成了一个Pipeline,不同的Pipeline数据隔离。
管理与控制
● Discovery: 动态配置的下发,目前主要为Kubernetes下的日志配置,可以通过创建LogConfig等CRD实例的方式来采集容器日志。后续将陆续支持主机形态下的各种配置中心对接。
● Monitor EventBus: 各组件均可以通过publish数据到EventBus Topic中,由特定的Listener监听Topic并进行消费处理。主要用于监控数据的暴露或发送。
● Reloader: 用于配置的动态更新。
特性
新一代的云原生日志采集和传输方式
基于CRD的快速配置和使用
Loggie包含 LogConfig/ClusterLogConfig/Interceptor/Sink CRD,只需简单的创建一些YAML文件,即可搭建一系列的数据采集、传输、处理、发送流水线。
apiVersion: loggie.io/v1beta1
kind: LogConfig
metadata:
name: tomcat
namespace: default
spec:
selector:
type: pod
labelSelector:
app: tomcat
pipeline:
sources: |
- type: file
name: common
paths:
- stdout
- /usr/local/tomcat/logs/*.log
sinkRef: default
interceptorRef: default

支持多种部署架构
● Agent: 使用DaemonSet部署,无需业务容器挂载Volume即可采集日志文件
● Sidecar: 支持Loggie sidecar无侵入自动注入,无需手动添加到Deployment/StatefulSet部署模版
● Aggregator: 支持Deployment独立部署成中转机形态,可接收聚合Loggie Agent发送的数据,也可单独用于消费处理各类数据源
但不管是哪种部署架构,Loggie仍然保持着简单直观的内部设计。

轻量级和高性能
基准压测对比
配置Filebeat和Loggie采集日志,并发送至Kafka某个Topic,不使用客户端压缩,Kafka Topic配置Partition为3。
在保证Agent规格资源充足的情况下,修改采集的文件个数、发送客户端并发度(配置Filebeat worker和Loggie parallelism),观察各自的CPU、Memory和Pod网卡发送速率。
| Agent | 文件大小 | 日志文件数 | 发送并发度 | CPU | MEM (rss) | 网卡发包速率 |
|---|---|---|---|---|---|---|
| Filebeat | 3.2G | 1 | 3 | 7.5~8.5c | 63.8MiB | 75.9MiB/s |
| Filebeat | 3.2G | 1 | 8 | 10c | 65MiB | 70MiB/s |
| Filebeat | 3.2G | 10 | 8 | 11c | 65MiB | 80MiB/s |
| Loggie | 3.2G | 1 | 3 | 2.1c | 60MiB | 120MiB/s |
| Loggie | 3.2G | 1 | 8 | 2.4c | 68.7MiB | 120MiB/s |
| Loggie | 3.2G | 10 | 8 | 3.5c | 70MiB | 210MiB/s |
自适应sink并发度
打开sink并发度配置后,Loggie可做到:
● 根据下游数据响应的实际情况,自动调整下游数据发送并行数,尽量发挥下游服务端的性能,且不影响其性能。
● 在上游数据收集被阻塞时,适当调整下游数据发送速度,缓解上游阻塞。
轻量级流式数据分析与监控
日志本身是一种通用的,和平台、系统无关的数据,如何更好的利用到这些数据,是Loggie关注和主要发展的核心能力。

实时解析和转换
只需配置transformer interceptor,通过配置函数式的action,即可实现:
● 各种数据格式的解析(json, grok, regex, split…)
● 各种字段的转换(add, copy, move, set, del, fmt…)
● 支持条件判断和处理逻辑(if, else, return, dropEvent, ignoreError…)
可用于:
● 日志提取出日志级别level,并且drop掉DEBUG日志
● 日志里混合包括有json和plain的日志形式,可以判断json形式的日志并且进行处理
● 根据访问日志里的status code,增加不同的topic字
示例:
interceptors:
- type: transformer
actions:
- action: regex(body)
pattern: (?<ip>\S+) (?<id>\S+) (?<u>\S+) (?<time>\[.*?\]) (?<url>\".*?\") (?<status>\S+) (?<size>\S+)
- if: equal(status, 404)
then:
- action: add(topic, not_found)
- action: return()
- if: equal(status, 500)
then:
- action: dropEvent()
检测识别与报警
帮你快速检测到数据中可能出现的问题和异常,及时发出报警。
支持匹配方式:
● 无数据:配置的时间段内无日志数据产生
● 匹配
模糊匹配
正则匹配
● 条件判断
字段比较:equal/less/greater…
支持部署形态:
● 在数据采集链路检测:简单易用,无需额外部署
● 独立链路检测两种形态:独立部署Aggregator,消费Kafka/Elasticsearch等进行数据的匹配和报警
均可支持自定义webhook对接各类报警渠道
业务数据聚合与监控
很多时候指标数据Metrics不仅仅是通过prometheus exporter来暴露,日志数据本身也可以提供指标的来源。 比如说,通过统计网关的access日志,可以计算出一段时间间隔内5xx或者4xx的statusCode个数,聚合某个接口的qps,计算出传输body的总量等等。
该功能正在内测中示例:
- type: aggregator
interval: 1m
select:
# 算子:COUNT/COUNT-DISTINCT/SUM/AVG/MAX/MIN
- {key: amount, operator: SUM, as: amount_total}
- {key: quantity, operator: SUM, as: qty_total}
groupby: ["city"]
# 计算:根据字段中的值,再计算处理
calculate:
- {expression: " ${amount_total} / ${qty_total} ", as: avg_amount}
全链路的快速排障与可观测性
● Loggie提供了可配置的、丰富的数据指标,还有dashboard可以一键导入到grafana中
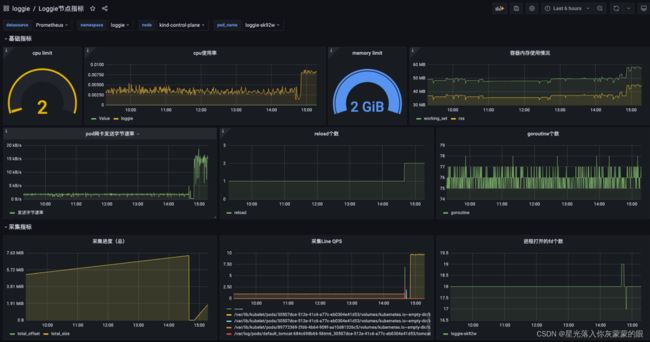
● 使用Loggie terminal和help接口快速便捷的排查Loggie本身的问题,数据传输过程中的问题

FAQs
Loggie vs Filebeat/Fluentd/Logstash/Flume
| Loggie | Filebeat | Fluentd | Logstash | Flume | |
|---|---|---|---|---|---|
| 开发语言 | Golang | Golang | Ruby | JRuby | Java |
| 多Pipeline | 支持 | 单队列 | 单队列 | 支持 | 支持 |
| 多输出源 | 支持 | 不支持,仅一个Output | 配置copy | 支持 | 支持 |
| 中转机 | 支持 | 不支持 | 支持 | 支持 | 支持 |
| 日志报警 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| Kubernetes容器日志采集 | 支持容器的stdout和容器内部日志文件 | 只支持容器stdout | 只支持容器stdout | 不支持 | 不支持 |
| 配置下发 | Kubernetes下可通过CRD配置,主机场景配置中心陆续支持中 | 手动配置 | 手动配置 | 手动配置 | 手动配置 |
| 监控 | 原生支持Prometheus metrics,同时可配置单独输出指标日志文件、发送metrics等方式 | API接口暴露,接入Prometheus需使用额外的exporter | 支持API和Prometheus metrics | 需使用额外的exporter | 需使用额外的exporter |
| 资源占用 | 低 | 低 | 一般 | 较高 | 较高 |
部署
1. 准备Kubernetes环境
可以使用现有Kubernetes集群,或者部署Kubernetes。本地推荐使用Kind搭建Kubernetes集群。
本文的操作需要在本地使用:
kubectl(下载)
helm(下载)
请确保本地有kubectl和helm可执行命令。
2. 部署Loggie DaemonSet
你可以在 installation 页面查看所有发布的部署chart。
可以选择下载chart再部署:
VERSION=v1.4.0
helm pull https://github.com/loggie-io/installation/releases/download/$VERSION/loggie-$VERSION.tgz && tar xvzf loggie-$VERSION.tgz
尝试修改一下其中的values.yaml。 请将以上的
如果你的环境中已经创建了loggie namespace,可以忽略其中的 -nloggie 和 --create-namespace 参数。当然,你也可以使用自己的namespace,将其中loggie替换即可。
helm install loggie ./loggie -nloggie --create-namespace
当然你也可以直接部署:
# 请将下面的替换成具体的版本号
helm install loggie -nloggie --create-namespace https://github.com/loggie-io/installation/releases/download/$VERSION/loggie-$VERSION.tgz
为了方便体验最新的Fix和特性,我们提供了main分支每次合并后的镜像版本,可通过 <这里>
(https://hub.docker.com/r/loggieio/loggie/tags) 进行选择。
同时你可以在helm install命令中增加 --set image=loggieio/loggie:vX.Y.Z 来指定具体的Loggie镜像。
● Kubernetes版本问题
failed to install CRD crds/crds.yaml: unable to recognize “”: no matches for kind “CustomResourceDefinition” in version “apiextensions.k8s.io/v1”
如果你在helm install的时候出现类似的问题,说明你的Kubernetes版本较低,不支持apiextensions.k8s.io/v1版本CRD。Loggie暂时保留了v1beta1版本的CRD,请删除charts中v1beta1版本,rm loggie/crds/crds.yaml,重新install。

3. 采集日志
Loggie定义了Kubernetes CRD LogConfig,一个LogConfig表示采集一类Pods的日志采集任务。
3.1 创建被采集的Pods
我们先创建一个Pod用于被采集日志的对象。接下来将采集这个Nginx Pod的标准输出stdout日志。
kubectl create deploy nginx --image=nginx
3.2 定义输出源Sink
接着我们创建一个Loggie定义的 CRD Sink 实例,表明日志发送的后端。为了方便演示,这里我们将日志发送至Loggie Agent自身的日志中并打印。
cat << EOF | kubectl apply -f -
apiVersion: loggie.io/v1beta1
kind: Sink
metadata:
name: default
spec:
sink: |
type: dev
printEvents: true
EOF
可以通过 kubectl get sink 查看到已创建的Sink。
3.3 定义采集任务
Loggie定义CRD LogConfig,表示一个日志采集任务。我们创建一个LogConfig示例如下所示:
cat << EOF | kubectl apply -f -
apiVersion: loggie.io/v1beta1
kind: LogConfig
metadata:
name: nginx
namespace: default
spec:
selector:
type: pod
labelSelector:
app: nginx
pipeline:
sources: |
- type: file
name: mylog
paths:
- stdout
sinkRef: default
EOF
可以看到,上面使用了sinkRef引用了刚才创建的sink default CR。当然,我们还可以直接在Logconfig中使用sink字段,示例如下:
cat << EOF | kubectl apply -f -
apiVersion: loggie.io/v1beta1
kind: LogConfig
metadata:
name: nginx
namespace: default
spec:
selector:
type: pod
labelSelector:
app: nginx
pipeline:
sources: |
- type: file
name: mylog
paths:
- stdout
sink: |
type: dev
printEvents: true
codec:
type: json
pretty: true
EOF
创建完之后,我们可以使用kubectl get lgc查看到创建的CRD实例。同时,我们还可以通过kubectl describe lgc nginx查看LogConfig的事件,以获取最新的状态
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal syncSuccess 52s loggie/kind-control-plane Sync type pod [nginx-6799fc88d8-5cb67] success
上面的nginx LogConfig通过其中的spec.selector来匹配采集哪些Pod的日志,这里我们使用app: nginx选择了刚才创建的nginx Pod。
spec.pipeline则表示Loggie的Pipeline配置,我们只采集容器标准输出的日志,所以在paths中填写stdout即可。
4. 查看日志
首先找到所在的nginx pod节点:
kubectl get po -owide -l app=nginx
然后我们找到该节点的Loggie:
kubectl -nloggie get po -owide |grep ${node}
可以通过:
kubectl -nloggie logs -f ${logge-pod}
查看Loggie打印出的日志,里面展示了采集到的nginx标准输出日志。
更全面的部署介绍:Kubernetes下部署Loggie
Kubernetes下日志采集最佳实践:Kubernetes下的日志采集
使用Loggie采集容器日志
Loggie如何采集容器日志?
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义CRD表示自己的期望状态,并借助一些framework开发Controller,使用Controller将我们的期望变成现实。
基于这个思路,一个服务需要采集哪些日志,需要什么样的日志配置,是用户的期望,而这就需要我们开发一个日志采集的Controller去实现。
所以,用户只需要在我们定义的CRD LogConfig中,填写需要采集哪些Pods的日志,在Pod中的日志路径是什么。
核心架构如下图所示:

Loggie会感知到Pod和CRD的事件,进行配置的动态更新。同时,Loggie可以根据日志文件路径挂载的Volume,找到相应在节点的文件进行采集。另外还可以根据配置,自动将Pod上的Env/Annotation/Label加入到日志里作为元信息。
同时相比粗暴的所有节点挂载相同路径进行通配采集的方式,也解决了没法针对单个服务精细化配置、采集无关日志的问题。
当然带来的好处不仅仅这些,Loggie在动态配置下发、监控指标等方面都可以基于Kubernetes进行相应的适配和支持。
CRD使用说明
Loggie目前有以下几种CRD:
LogConfig: namespace级别CRD,用于采集Pod容器日志,其中主要填写采集的source配置,以及关联的sink和interceptor。
ClusterLogConfig: cluster级别CRD,表示集群级别的采集Pod容器日志,采集Node节点上的日志,以及为某个Loggie集群下发通用的pipeline配置。
Sink: 表示一个sink后端,需要在ClusterLogConfig/LogConfig中被关联。
Interceptor: 表示一个interceptors组,需要在ClusterLogConfig/LogConfig中被关联。
使用CRD的流程架构如下所示:

If you do, you have a fifty percent chance. If you don’t, you don’t