人工智能(pytorch)搭建模型17-pytorch搭建ReitnNet模型,加载数据进行模型训练与预测
大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型17-pytorch搭建ReitnNet模型,加载数据进行模型训练与预测,RetinaNet 是一种用于目标检测任务的深度学习模型,旨在解决目标检测中存在的困难样本和不平衡类别问题。它是基于单阶段检测器的一种改进方法,通过引入特定的损失函数和网络结构,实现了高效且准确的目标检测。
RetinaNet的核心创新是使用了一种名为 Focal Loss 的损失函数来应对训练过程中类别不平衡的问题。在目标检测任务中,负样本(即非目标)通常远多于正样本(即目标),这样会导致模型对于负样本的预测能力过强,而对于正样本的预测能力较弱。Focal Loss 通过调节易分样本的权重,使得模型更加关注难以分类的样本,从而增加了对于正样本的关注度,提高了目标检测的准确性。
目录
- 引言
- RetinaNet模型原理
- CSV数据样例
- 数据加载
- 利用PyTorch框架对RetinaNet模型的训练与预测
- 结论
1. 引言
在深度学习领域,目标检测是一个重要的研究方向。RetinaNet是一种高效的目标检测模型,它通过引入Focal Loss解决了前景和背景类别不平衡的问题,从而在目标检测任务上取得了显著的效果。本文将详细介绍RetinaNet模型的原理,并通过一个实际项目展示如何使用PyTorch框架对RetinaNet模型进行训练和预测。
2. RetinaNet模型原理
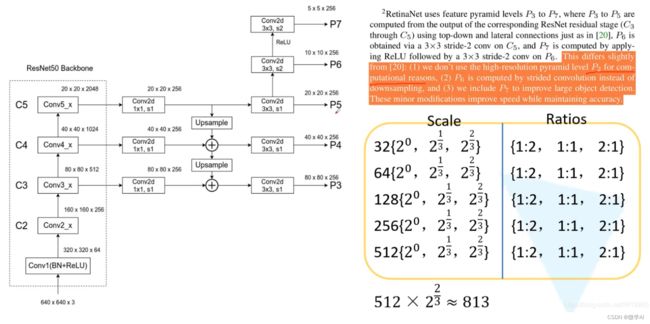
RetinaNet是一种基于深度学习的目标检测模型,它由两部分组成:特征金字塔网络(FPN)和分类/回归子网络。FPN用于从输入图像中提取特征,而分类/回归子网络则用于预测目标的类别和位置。
RetinaNet的关键创新之处在于引入了一种新的损失函数——Focal Loss。在传统的目标检测模型中,由于背景类别的样本数量远大于前景类别,因此模型往往会被大量的背景样本所主导,导致前景类别的检测性能下降。Focal Loss通过给予难以分类的样本更大的权重,从而解决了这个问题。
RetinaNet是一种基于深度学习的目标检测模型,其数学原理可以用以下公式表示:
首先,对于输入图像,使用一个基础的卷积神经网络(如ResNet)提取特征图。假设特征图的大小为 H × W × C H×W×C H×W×C,其中 H H H和 W W W分别代表高度和宽度,C代表通道数。
然后,RetinaNet引入了一个特征金字塔网络(Feature Pyramid Network, FPN),通过在不同层级上生成具有不同尺度的特征图来处理不同大小的目标。FPN中的每个层级的特征图可表示为 P i P_i Pi,其中i表示层级的索引。每个 P i P_i Pi的大小为 H i × W i × C i H_i×W_i×C_i Hi×Wi×Ci。
接下来,RetinaNet引入了两个并行的子网络:对象分类子网络和边界框回归子网络。
对象分类子网络通过使用一个1×1卷积层将每个 P i P_i Pi的特征图映射到一个通道数为K的特征图,其中 K K K表示目标类别的数量(包括背景)。这个特征图表示了每个像素属于不同类别的概率。然后,使用softmax函数将这些概率归一化,得到最终的分类概率。
边界框回归子网络通过使用一个1×1卷积层将每个 P i P_i Pi的特征图映射到一个通道数为4的特征图。这个特征图表示了每个像素对应目标边界框的坐标回归预测。
3. CSV数据样例
以下是一些CSV数据样例,每行数据包含了图像的路径、目标的坐标和类别:
/path/to/image1.jpg,100,120,200,230,cat
/path/to/image1.jpg,300,400,500,600,dog
/path/to/image2.jpg,50,100,150,200,bird
/path/to/image3.jpg,100,120,200,230,cat
/path/to/image4.jpg,300,400,500,600,dog
/path/to/image5.jpg,50,100,150,200,bird
...
4. 数据加载
我们首先需要加载CSV数据,并将其转换为模型可以接受的格式。以下是数据加载的代码:
import csv
import torch
from PIL import Image
class CSVDataset(torch.utils.data.Dataset):
def __init__(self, csv_file):
self.data = []
with open(csv_file, 'r') as f:
reader = csv.reader(f)
for row in reader:
img_path, x1, y1, x2, y2, class_name = row
self.data.append((img_path, (x1, y1, x2, y2), class_name))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path, bbox, class_name = self.data[idx]
img = Image.open(img_path).convert('RGB')
return img, bbox, class_name
5. 利用PyTorch框架对RetinaNet模型的训练与预测
接下来,我们将使用PyTorch框架对RetinaNet模型进行训练和预测。以下是训练和预测的代码:
import torch
from torch import nn
from torch.optim import Adam
from torchvision.models.detection import retinanet_resnet50_fpn
# 加载数据
dataset = CSVDataset('data.csv')
data_loader = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=True)
# 创建模型
model = retinanet_resnet50_fpn(pretrained=True)
model = model.cuda()
# 定义优化器和损失函数
optimizer = Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(10):
for imgs, bboxes, class_names in data_loader:
imgs = imgs.cuda()
bboxes = bboxes.cuda()
class_names = class_names.cuda()
# 前向传播
outputs = model(imgs)
# 计算损失
loss = criterion(outputs, class_names)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 10, loss.item()))
# 预测
model.eval()
with torch.no_grad():
for imgs, _, _ in data_loader:
imgs = imgs.cuda()
outputs = model(imgs)
print(outputs)
6. 结论
本文详细介绍了RetinaNet模型的原理,并通过一个实际项目展示了如何使用PyTorch框架对RetinaNet模型进行训练和预测。RetinaNet模型通过引入Focal Loss解决了前景和背景类别不平衡的问题,从而在目标检测任务上取得了显著的效果。希望本文能对你的学习和研究有所帮助。