Kubernetes 启动Pod的方法-Pod的调度算法-Pod间的通信-k8s的控制器-Pod资源控制-发布Service服务
目录
Pod
参考文档:Pod | Kubernetes
Pod配置文件:simple-pod.yaml
对master进行如下操作
Pod的状态有:
参考文档:(70条消息) Pod生命周期中的状态解释_pod状态_闹玩儿扣眼珠子的博客-CSDN博客
进入Pod内的nginx容器:
当我们创建一个Pod,其中的步骤是什么?(启动Pob的流程)
大概步骤:
k8s的 控制器有哪些:
创建Pod过程中提出的问题:
Scheduler在做任务的时候,使用了那些调度算法呢?
根据Pod的调度策略和方法:(K8s有哪些调度算法?)
Pod与Pod之间如何进行通信?
k8s启动Pod
1、启动nginx的Pod
2、控制器deployment的使用
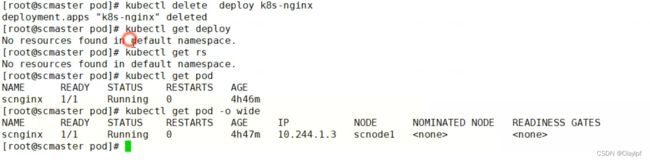
我们如果想停止Pod的运行,我们删除ReplicaSet 控制器是没有用的(因为删除掉后deployment控制器会重新启用ReplicaSet 控制器),我们必须删除deployment控制器(命令:kubectl delete deployment)
3、conctroller 控制器
参考文档:DaemonSet | Kubernetes
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。
下面的 daemonset.yaml 文件描述了一个运行 fluentd-elasticsearch(日志收集) Docker 镜像的 DaemonSet:
我们为什么要设置容忍度呢,其实原因很简单,因为k8s会对master进行污点标记,导致Pod无法在master运行,但是我们的日志收集的目的是可以在所有节点上运行的,因此设置容忍度可以使这个Pod在master上也能正常运行
污点和容忍度:
参考文档:污点和容忍度 | Kubernetes
配置一:
配置二:
先检查key是否匹配,匹配是看operator是exists或者equal,这表示匹配,就会允许在有污点的node节点上启动这个Pod,effect可以理解为如果key不匹配,就不允许调度到这个污点节点。
4、Pod的资源控制
参考文档:为容器和 Pod 分配内存资源 | Kubernetes
指定内存请求和限制
创建一个命名空间,以便将本练习中创建的资源与集群的其余部分隔离。
你将创建一个拥有一个容器的 Pod。 容器将会请求 100 MiB 内存,并且内存会被限制在 200 MiB 以内。 这是 Pod 的配置文件:
开始创建 Pod:
验证 Pod 中的容器是否已运行:
查看 Pod 相关的详细信息:
运行 kubectl top 命令,获取该 Pod 的指标数据(前提是你已经有在运行中的 metrics-server)
删除 Pod:
支持容器访问策略和容器带宽限制:istio组件
5、一个Pod里面运行多个容器:
Pod 的配置文件:
创建multi_c.yaml文件存储Pod
开始创建 Pod:
验证 Pod 中的容器是否已运行:
内部访问我创建的nginx容器:
6、将创建的Pod发布出去:
参考文档: 服务(Service) | Kubernetes
定义一个内有nginx容器的Pod,并创建成功
开始创建 Pod:
查看是否创建成功:
创建Service服务,暴露我们的nginx容器服务(发布服务(服务类型))
开始创建 Pod(service服务):
Service发布成功了
访问发布的Pod
我们只需要随便访问k8s集群里的任何一台node节点服务器,包括master
访问nginx容器的模拟图:(外面的用户访问Pod的数据流程:)
Pod
参考文档:Pod | Kubernetes
Pod配置文件:simple-pod.yaml
apiVersion: v1 #k8s里的api版本 --》用来给我们的k8s传参的
kind: Pod #k8s里的资源对象类型:pod deployment replicaSET daemonSET service等对象
metadata: #定义的元数据、起描述资源对象的数据
name: nginx #pod的名字
spec: #详细的信息、指定的信息
containers: #容器
- name: scnginx #容器名 可以存在多个容器
image: nginx:1.14.2 #镜像及其版本
ports: #容器暴露的端口
- containerPort: 80 #具体的端口
#- name redis #指定第二个容器为redis
# image: nginx:1.14.2
# ports:
# - containerPort: 80对master进行如下操作
[root@master pod]# pwd
/root/pod
[root@master pod]# ls
nginx.yaml
[root@master pod]# cat nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: scnginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
[root@master pod]# kubectl apply -f nginx.yaml
pod/scnginx created
[root@master pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
k8s-nginx-6d779d947c-f72hf 1/1 Running 0 5h57m
k8s-nginx-6d779d947c-hnhf5 1/1 Running 0 5h57m
k8s-nginx-6d779d947c-xgjzg 1/1 Running 0 5h57m
scnginx 0/1 ContainerCreating 0 14s
[root@master pod]# 如上所示,我使用了nginx.yaml文件创建了一个关于nginx的pod,其中的pod的状态
Pod的状态有:
Pending(等待中):Pod 已经被创建,但还未被调度到任何节点上运行。
Running(运行中):Pod 已经被调度到节点上并且至少有一个容器正在运行。
Succeeded(已成功):Pod 中的所有容器已经成功地完成任务并且终止。
Failed(已失败):Pod 中的所有容器已经执行失败,并且已终止。
Unknown(未知):无法获取 Pod 的状态信息。ImagePullBackoff:镜像拉取失败(ImagePullBackoff )
CrashLoopBackOff :运行时程序崩溃( CrashLoopBackOff ),频繁重启
配置错误,比如挂载的Volume不存在( RunContainerError),导致容器运行错误
Pending:磁盘挂载失败( Pending ),比如容器挂载的puvc并没有Pend特定的pv
OOMKilled:你需要申请的CPU和内存资源超过了宿主机的允许
ContainerCreating:正在创建容器的过程中
参考文档:(70条消息) Pod生命周期中的状态解释_pod状态_闹玩儿扣眼珠子的博客-CSDN博客
进入Pod内的nginx容器:
我们又如何进入我们所创建的nginx容器呢?
[root@master pod]# kubectl get pod -o wide #查看Pod的详细信息
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k8s-nginx-6d779d947c-f72hf 1/1 Running 0 6h10m 10.244.1.4 node1
k8s-nginx-6d779d947c-hnhf5 1/1 Running 0 6h10m 10.244.3.2 node3
k8s-nginx-6d779d947c-xgjzg 1/1 Running 0 6h10m 10.244.2.2 node2
scnginx 1/1 Running 0 14m 10.244.2.3 node2
[root@master pod]# kubectl exec -it scnginx bash #进入scnginx容器内
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@scnginx:/#
建议使用: kubectl exec -it scnginx -- bash
当我们创建一个Pod,其中的步骤是什么?(启动Pob的流程)
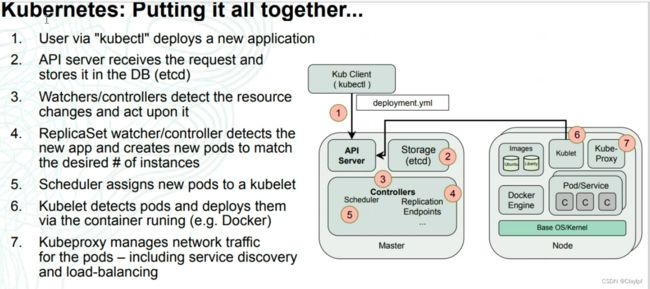
1. 用户通过“kubectl”部署一个新的应用程序(如nginx.yaml文件)
2. API服务器(API Server)接收请求并将其存储(Storage)在数据库中(etcd)
3.观察者/控制器 检测资源变化并对其采取行动
4.ReplicaSet监视器/控制器 检测到新的应用程序,并创建新的pod来匹配所需的实例数
5. 调度器(Scheduler)将新的pod分配给kubelet
6. Kubelet 检测 pod并通过容器运行(例如Docker)部署它们。(在Node上运行)
7. Kubeproxy管理pod的网络流量——包括服务发现和负载平衡。(在Node上运行)

大概步骤:
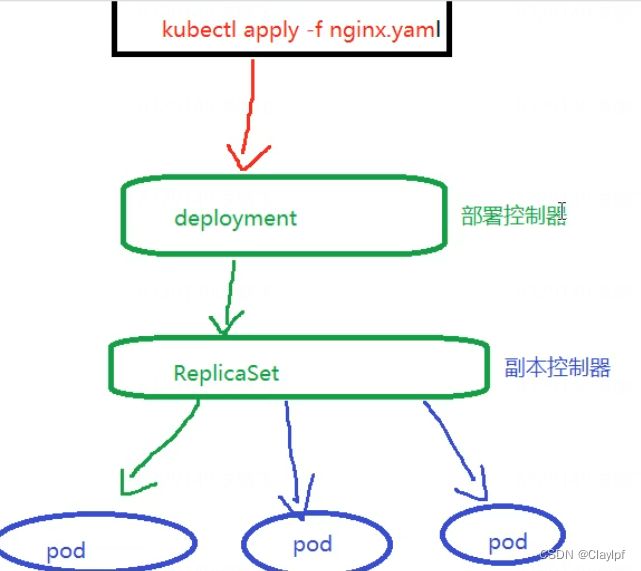
1、先是执行命令kubectl apply -f nginx.yaml
2、成功创建部署控制器deployment,控制器会去检测需要的资源
3、部署控制器deployment会再去帮助我们创建 副本控制器(ReplicaSet)
4、然后副本控制器会帮助我们去监控Pod数量,一旦少了 副本控制器还会帮我们再启一个Pod。
5、Kubelet 检测到需要被创建的Pod,会分配资源(如Docker创建)将Pod创建(在Node上)
6、Kubeproxy最后会管理Pod需要的内存、流量,保障Pod稳定运行(在Node上)
k8s的 控制器有哪些:
Kubernetes 中有多个控制器(Controller),用于确保系统中的资源状态与期望状态保持一致。以下是 Kubernetes 中常见的控制器:
ReplicaSet 控制器:用于管理 Pod 的副本数,确保指定数量的 Pod 副本处于运行状态。
Deployment 控制器:基于 ReplicaSet 控制器,提供了滚动更新和回滚功能,用于管理应用程序的发布和更新。
StatefulSet 控制器:用于管理有状态应用的部署,确保有序的创建、更新和删除 Pod。
DaemonSet 控制器:确保在集群的每个节点上都运行一个 Pod 的副本,常用于运行守护进程或日志收集器等任务。
Job 控制器:用于一次性任务的执行,确保任务成功完成后自动终止,如批处理任务或定时任务。
CronJob 控制器:基于 Job 控制器,用于按计划定期执行任务,如定时清理任务或数据备份任务。
Namespace 控制器:用于创建和管理命名空间,将集群内的资源隔离和分类。
创建Pod过程中提出的问题:
1、kubelet是定期主动访问api server知道有哪些pod需要启动,还是Scheduler主动去通知kubelet去访问api server的呢?
2、etcd数据库发生了变化,那些控制器是如何知道的呢?是其他程序通知的,还是定时检查的呢?
3、这么多的控制的,那么哪些控制器先启动,哪些控制器后启动呢,他们的启动顺序是怎样的呢?(deployment、replicaSet、Scheduler)
其他控制器(daemonSet:会在每台node节点上启动一个Pod,不会启动多了,flannel上就有)
(job:批量处理的控制器)
(cronjob:计划任务的控制器)
Scheduler在做任务的时候,使用了那些调度算法呢?
为什么master上没有启动业务app pod?
因为这是Scheduler调度器会根据调度策略,避免了在master上建立Pod
污点:taint(会导致这个node节点机器不接受这个被污点标记的Pod)
根据Pod的调度策略和方法:(K8s有哪些调度算法?)
1、deployment:全自动调度:会根据node的综合算力(cpu、内存、带宽、已经运行的Pod等)
2、node selector:定向调度
3、nodeaffinity:它会尽量把不同的Pod的放到一台node节点机器上 --》affinity(亲和度)
4、podaffinity:它会尽量把相同的Pod的放到一起去(yaml文件中才会存在)
5、taints和tolerations:污点和容忍
Pod与Pod之间如何进行通信?
其实我看可以看做docker宿主机和内部容器间的通信流程
我们使用的技术是overlay(基础是vxlan)(flannel)、ipip和BGP(cailco)
k8s启动Pod
1、启动nginx的Pod
kubectl create deployment k8s-nginx --image=nginx -r 32、控制器deployment的使用
查看deployment的使用
[root@master pod]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
k8s-nginx 3/3 3 3 8h
[root@master pod]#
我们如果想停止Pod的运行,我们删除ReplicaSet 控制器是没有用的(因为删除掉后deployment控制器会重新启用ReplicaSet 控制器),我们必须删除deployment控制器(命令:kubectl delete deployment)
3、conctroller 控制器
参考文档:DaemonSet | Kubernetes
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。
当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
下面的 daemonset.yaml 文件描述了一个运行 fluentd-elasticsearch(日志收集) Docker 镜像的 DaemonSet:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# 这些容忍度设置是为了让该守护进程集在控制平面节点上运行
# 如果你不希望自己的控制平面master节点运行 Pod,可以删除它们
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log我们为什么要设置容忍度呢,其实原因很简单,因为k8s会对master进行污点标记,导致Pod无法在master运行,但是我们的日志收集的目的是可以在所有节点上运行的,因此设置容忍度可以使这个Pod在master上也能正常运行
污点和容忍度:
参考文档:污点和容忍度 | Kubernetes
节点亲和性 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点 (这可能出于一种偏好,也可能是硬性要求)。 污点(Taint) 则相反——它使节点能够排 Pod。
容忍度(Toleration) 是应用于 Pod 上的。容忍度允许调度器调度带有对应污点的 Pod。 容忍度允许调度但并不保证调度:作为其功能的一部分, 调度器也会评估其他参数。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod, 是不会被该节点接受的。
污点:给node和master节点打污点
容忍度:pod去容忍污点节点
你可以使用命令 kubectl taint 给node节点增加一个污点。比如:
kubectl taint nodes node1 key1=value1:NoSchedule
给节点 node1 增加一个污点,它的键名是 key1,键值是 value1,效果是 NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到 node1 这个节点。
若要移除上述命令所添加的污点,你可以执行:
kubectl taint nodes node1 key1=value1:NoSchedule-你可以在 Pod 规约中为 Pod 设置容忍度。 下面两个容忍度均与上面例子中使用 kubectl taint 命令创建的污点相匹配, 因此如果一个 Pod 拥有其中的任何一个容忍度,都能够被调度到 node1:
配置一:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
#equal 就需要写key和value
配置二:
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
#exists 就不需要写value先检查key是否匹配,匹配是看operator是exists或者equal,这表示匹配,就会允许在有污点的node节点上启动这个Pod,effect可以理解为如果key不匹配,就不允许调度到这个污点节点。
这里是一个使用了容忍度的 Pod:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule" operator 的默认值是 Equal。
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
- 如果
operator是Exists(此时容忍度不能指定value),或者- 如果
operator是Equal,则它们的value应该相等。
详细请看官方文档:污点和容忍度 | Kubernetes
4、Pod的资源控制
参考文档:为容器和 Pod 分配内存资源 | Kubernetes
指定内存请求和限制
创建一个命名空间,以便将本练习中创建的资源与集群的其余部分隔离。
kubectl create namespace mem-example要为容器指定内存请求,请在容器资源清单中包含 resources: requests 字段。 同理,要指定内存限制,请包含 resources: limits。
你将创建一个拥有一个容器的 Pod。 容器将会请求 100 MiB 内存,并且内存会被限制在 200 MiB 以内。 这是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
requests:
memory: "100Mi" #该 Pod 中容器的内存请求为 100 MiB,内存限制为 200 MiB。
limits:
memory: "200Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
#配置文件的 args 部分提供了容器启动时的参数。 "--vm-bytes", "150M" 参数告知容器尝试分配 150 MiB 内存。开始创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit.yaml --namespace=mem-example

验证 Pod 中的容器是否已运行:
kubectl get pod memory-demo --namespace=mem-example

查看 Pod 相关的详细信息:
kubectl get pod memory-demo --output=yaml --namespace=mem-example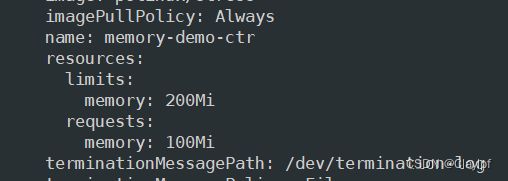
运行 kubectl top 命令,获取该 Pod 的指标数据(前提是你已经有在运行中的 metrics-server)
添加 metrics-server:(73条消息) k8s集群安装metrics-server_k8s安装metrics_MssGuo的博客-CSDN博客
kubectl top pod memory-demo --namespace=mem-example输出结果显示:Pod 正在使用的内存大约为 162,900,000 字节,约为 150 MiB。 这大于 Pod 请求的 100 MiB,但在 Pod 限制的 200 MiB之内。
NAME CPU(cores) MEMORY(bytes)
memory-demo 162856960
删除 Pod:
kubectl delete pod memory-demo --namespace=mem-example
支持容器访问策略和容器带宽限制:istio组件
5、一个Pod里面运行多个容器:
Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
- name: webleader2
image: docker.io/nginx
resources:
requests:
cpu: 100m
memory: "100Mi"
limits:
memory: "200Mi"
ports:
- containerPort: 80创建multi_c.yaml文件存储Pod
[root@master pod]# vim multi_c.yaml
开始创建 Pod:
[root@master pod]# kubectl apply -f multi_c.yaml
pod/memory-demo created
验证 Pod 中的容器是否已运行:
[root@master pod]# kubectl get pod -n mem-example #表示有两个容器在这个命名空间运行
NAME READY STATUS RESTARTS AGE
memory-demo 2/2 Running 0 56s
内部访问我创建的nginx容器:
[root@master pod]# curl 10.244.3.4
Welcome to nginx!
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.
For online documentation and support please refer to
nginx.org.
Commercial support is available at
nginx.com.
Thank you for using nginx.
[root@master pod]#
6、将创建的Pod发布出去:
参考文档: 服务(Service) | Kubernetes
定义一个内有nginx容器的Pod,并创建成功
[root@master pod]# cat my_nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 3
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
[root@master pod]#
开始创建 Pod:
[root@master pod]# kubectl apply -f my_nginx.yaml 查看是否创建成功:
[root@master pod]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k8s-nginx-6d779d947c-f72hf 1/1 Running 0 16h 10.244.1.4 node1
k8s-nginx-6d779d947c-hnhf5 1/1 Running 0 16h 10.244.3.2 node3
k8s-nginx-6d779d947c-xgjzg 1/1 Running 0 16h 10.244.2.2 node2
my-nginx-cf54cdbf7-8sbns 1/1 Running 0 13m 10.244.1.5 node1
my-nginx-cf54cdbf7-ptjw7 1/1 Running 0 8s 10.244.3.5 node3
my-nginx-cf54cdbf7-wf48x 1/1 Running 0 13m 10.244.2.4 node2
scnginx 1/1 Running 0 10h 10.244.2.3 node2
[root@master pod]#
创建Service服务,暴露我们的nginx容器服务(发布服务(服务类型))
[root@master pod]# cat my_service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: NodePort
ports:
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- port: 8080
targetPort: 80
protocol: TCP
name: http
selector:
run: my-nginx
[root@master pod]#
开始创建 Pod(service服务):
[root@master pod]# kubectl apply -f my_service.yaml
service/my-nginx created
[root@master pod]#
Service发布成功了
[root@master pod]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 443/TCP 19h
my-nginx NodePort 10.6.55.120 8080:32465/TCP 63s
[root@master pod]#
访问发布的Pod
我们只需要随便访问k8s集群里的任何一台node节点服务器,包括master
curl http://192.168.2.150:32465 #master的IP地址 + 端口
访问nginx容器的模拟图:(外面的用户访问Pod的数据流程:)
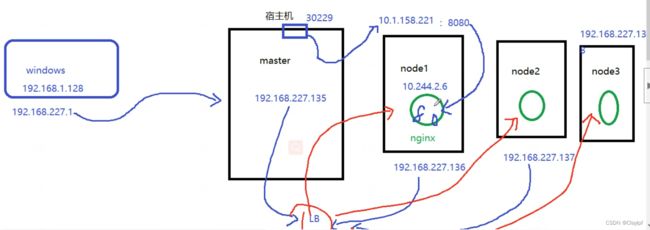
如上图所示: 浏览器访问 192.168.2.150:32465 --》访问到 node1/2/3上 my-nginx 10.6.55.120:8080 --》最后访问到node节点里面的Pod内的nginx容器 10.244.1.5:80
其实中间还会存在一台LB(负载均衡器)来分发流量给node1/2/3节点