JVM简单介绍
简介
JVM是Java虚拟机, java的程序都运行在JVM中, 也是一种规范. 使用Java -version可以查看安装的Java的信息, 其中可以看到下面的信息. Java HotSpot就是其中的一个实现
JVM的运行流程
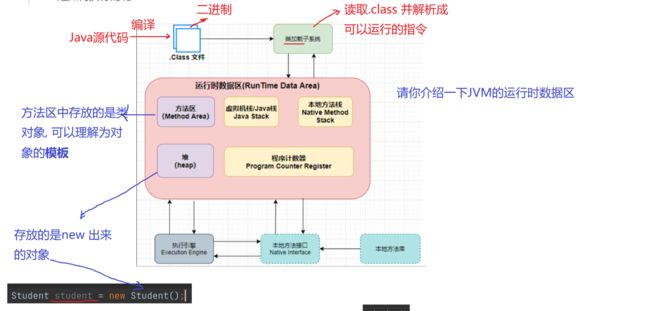
栈里放的是new出来的引用, 堆里存的是真正的对象
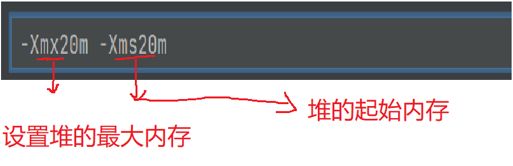
对于虚拟机栈, 每一个线程都有对应的一个java虚拟机栈. 每调用一个方法都会以一个栈帧的形式加入到线程的栈帧中, 方法执行完成之后栈帧就会出栈. 栈帧记录了一些信息, 包括局部变量表,方法的返回地址等. 栈有大小, 入栈方法太多会产生StackOverflowError错误. 可以用-Xss参数来设置栈的大小(在idea里设置). 栈主要记录的是方法的调用关系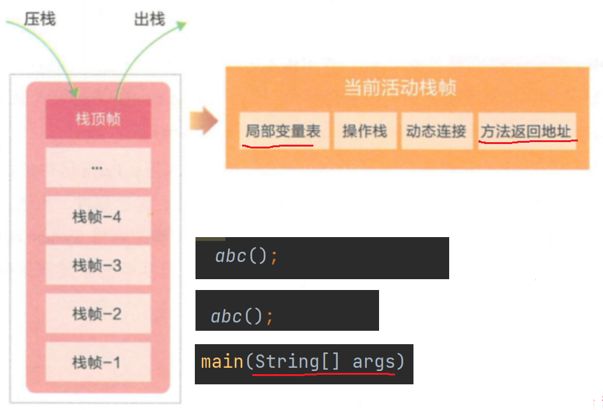
本地方法栈工作原理和Java虚拟机栈一样, 记录的是本地方法的调用关系程序计数器是记录当前线程的方法执行到了哪一行(是指代码转换成的指令的哪一行,而不是代码的哪一行).注意:图里浅紫色的方法区和堆对外是内存共享的, 因为实例化对象需要模版, 模版在方法区里, 对象的调用需要得到对象, 所以要去堆里找, 所以内存是共享的. 右边的两个栈和程序计数器, 内存不共享(因为线程之间内存不共享), 和线程强相关的都是内存私有的执行引擎是把Java字节码转换为CPU指令的本地方法接口是调用不同的系统API的
JVM类加载
类加载的过程如下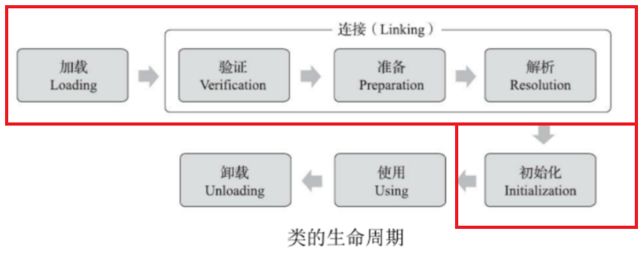
加载
读取.class文件
连接
验证
验证.class是否符合JVM规范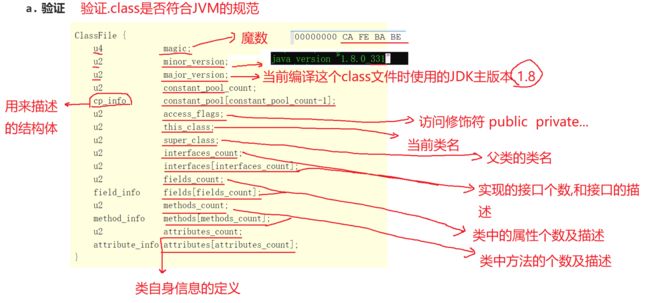
准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置初始值的阶段
解析
将已加载的类的符号引用, 解析为直接引用的过程。当Java程序引用一个类时,通常会使用符号引用来表示这个类,包括类的全限定名、方法的名称和描述符等信息。而解析阶段的目标是将这些符号引用转换为对实际内存中类、方法、字段等结构的直接引用。
初始化
初始化阶段,JVM真正开始执行类中编写的代码, 控制权在应用程序
双亲委派模型
描述的是类加载的过程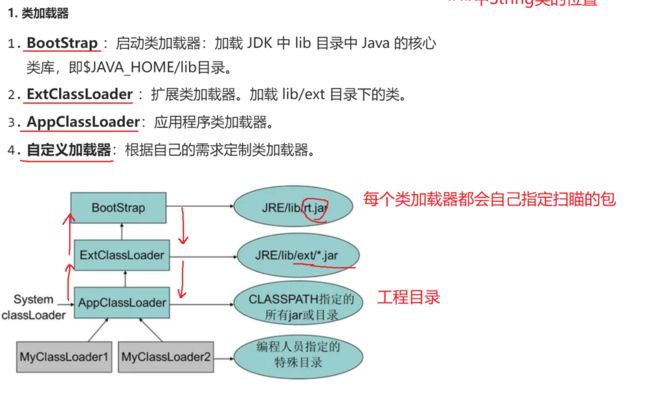
如果自定义的类与JDK中重要的类同名, 比如自己写了个String. 这样类加载的时候, 需要保证自己加载的是JDK带的这个, 而不能是自定义的, 因为这样才能保证安全(因为要是有人故意写一个同名的类会篡改JDK里的类).
所以需要使用双亲委派模型: 当一个加载器收到了类加载请求不会直接加载, 而是先一层一层告诉上层, 先从顶层找, 如果找到了类文件, 则加载当前的类, 要是没找到,才轮到下一层找, 都没找到,才从自定义的类里找模版破坏双亲委派模型: 有时候需要破坏JDK里的类. 比如JDBC就是. JDK只定义了接口, 但实现类是在第三方厂商的jar包里
垃圾回收
如何标记一个对象是垃圾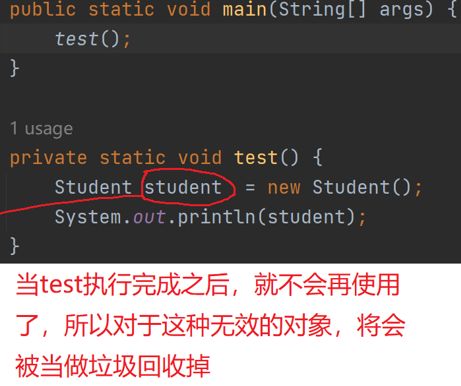
死亡对象的判断方法
引用计数法
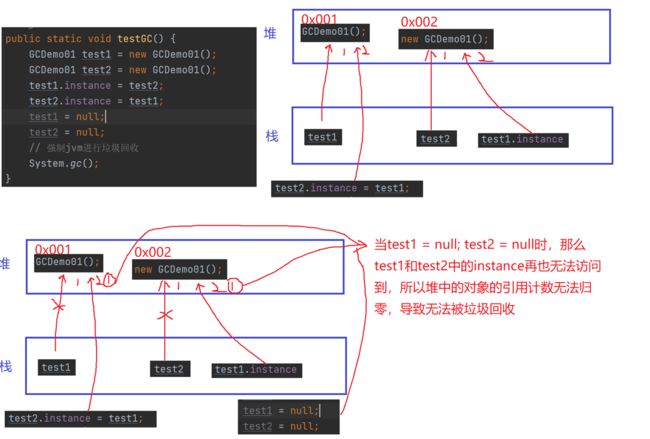
可达性分析算法
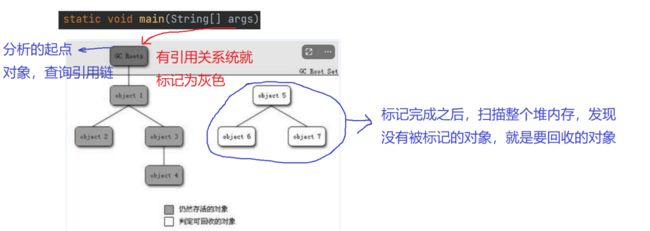
垃圾回收的过程
Minor GC(年轻代GC) Full GC(老年代GC)Major GC(全局GC)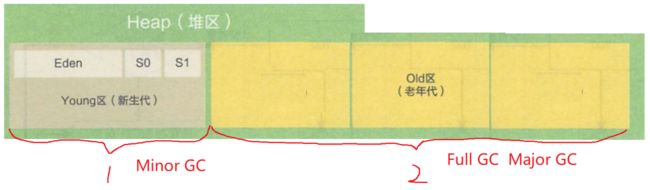
初始时,所有新创建的对象都会被分配到Eden区。
当进行Minor GC时,首先会对Eden区进行垃圾回收。垃圾回收器会标记并清理不再使用的对象,同时将仍然存活的对象复制到S0区。
在下一次Minor GC时,如果对象仍然存活,它们会从Eden区或者上一次Survivor区(From区)移动到另一个Survivor区(To区)。此时,Survivor区之间的角色会发生翻转,From区变为To区,To区变为From区。
大对象(S0,S1放不下)和经历了n次(一般默认15次)垃圾回收依然存活下来的对象会从新生代移动到老年代STW(Stop The World): 每次垃圾回收的时候, 程序都会进入暂停的状态
垃圾回收的算法
标记清除算法
(注意是灰黑白三个颜色)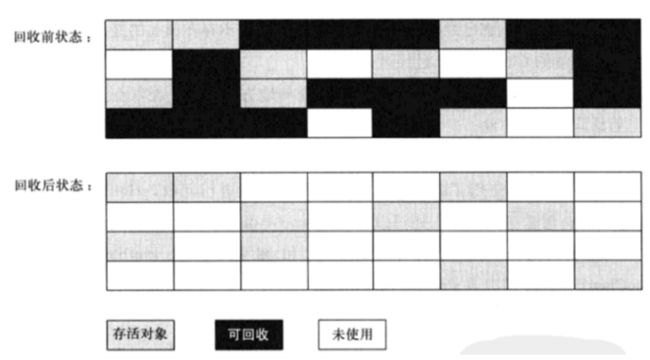

复制算法

标记整理算法
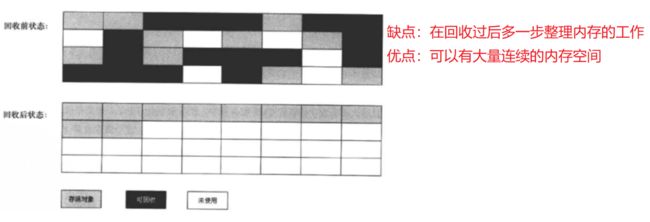
应用场景
针对不同的情况, 选用不同的算法
垃圾收集器
概览
垃圾收集器的不断更新,目的就是为了减少STW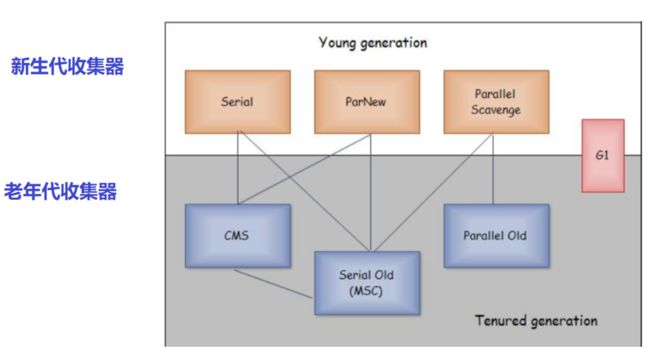
Serial收集器
Serial 收集器是最基本、发展历史最悠久的收集器,曾经(在JDK 1.3.1之前)是虚拟机新生代收集的唯 一选择。 
ParNew收集器

Parallel Scavenge收集器
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器 
CMS收集器


Parallel Old收集器×

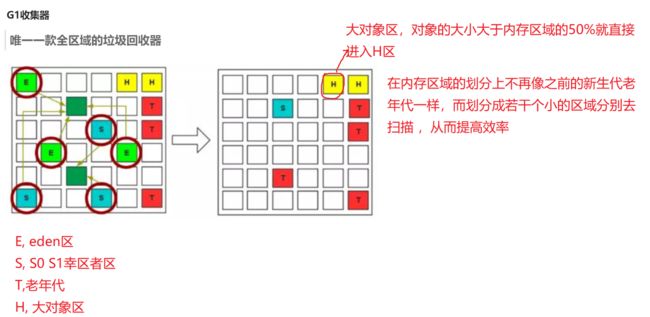
G1收集器
判断死亡方法-引用
不同的引用用不同方法来实现

