bevfomer/maptr模型中时序对齐模块的改进
1 原理介绍
当前在自动驾驶感知领域,最流行的算法就是基于bev原理的检测算法,其中基于bev目标检测的典型算法是bevformer,基于bev建图的典型算法是maptr。为了提升模型性能,两者均使用了完全相同的bev时序对齐模块以实现bev时序检测。其bev时序对齐模块的原理比较难懂,具体原理解释如下图所示。
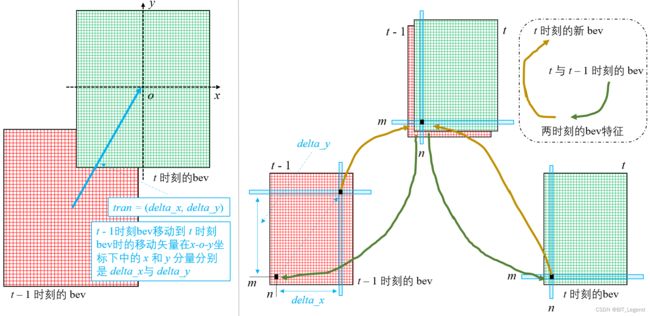
上面左图为 t - 1 时刻和 t 时刻的bev图,两幅bev图角度相同,仅存在空间位移,空间位移矢量tran在 t 时刻的x-o-y坐标系中的 x 和 y 分量分别是 delta_x 和 delta_y。上面右图为时序对齐原理,具体来说,首先将两幅bev图沿通道维拼接在一起得到拼接bev,然后更新每一个空间位置处的通道向量值,得到新的融合后的 t 时刻新bev图。以空间位置(n, m)举例,为求出在 t 时刻新bev图中(n, m)位置处的通道向量值,首先从拼接bev图中得到(n, m)处的通道向量值,然后计算出 k 个相对特征索引位置及权重,然后在 t 时刻bev特征图中,直接在(n, m)处基于相对特征索引位置及权重得到所需特征1,然后在 t - 1 时刻bev特征图中,在(n+delta_x, m+delta_y)处基于相对特征索引位置及权重得到所需特征2,最后将两个特征求均值得到 t 时刻新bev图中(n, m)位置处的通道向量值。实际情况下, t - 1 时刻和 t 时刻的两幅bev图不一定有相同角度,所以在实施如上对齐过程之前,需要首先对 t - 1 时刻的bev特征图进行旋转,使得 t - 1 时刻和 t 时刻的两幅bev图具有相同角度。
但是如上方案存在一个问题,两幅bev图沿通道维拼接在一起得到拼接bev,这个拼接bev是没有做过时空对齐的,所以在拼接bev图中的(n, m)处的通道向量值也是没有时空对齐的,这个通道向量值的上半部分( t 时刻特征)和下半部分( t - 1 时刻特征)所对应的空间位置不一致,实际下半部分所对应的空间位置更靠前,这个在道理上讲不太合理,按理这个通道向量值的上半部分和下半部分所对应的空间位置都应该是(n, m)才合理。为此,我们提出了改进方案,具体原理如下图所示。
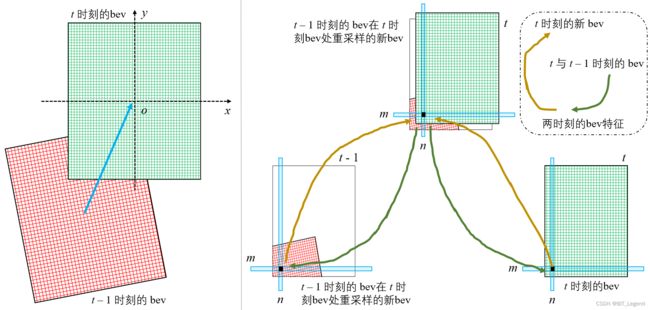
上面左图为 t - 1 时刻和 t 时刻的bev图,两幅bev图角度不同,既存在角度变化也存在空间位移。上面右图为时序对齐原理,具体来说,首先将 t - 1 时刻的bev图在 t 时刻的bev图空间位置处进行重采样,得到在 t 时刻的bev图空间位置处的 t - 1 时刻新bev图,然后将 t - 1 时刻新bev图和 t 时刻的bev图沿通道维拼接在一起得到拼接bev,这个拼接bev已经完成了时空对齐,然后更新每一个空间位置处的通道向量值,得到新的融合后的 t 时刻新bev图。以空间位置(n, m)举例,为求出在 t 时刻新bev图中(n, m)位置处的通道向量值,首先从拼接bev图中得到(n, m)处的通道向量值,然后计算出 k 个相对特征索引位置及权重,然后在 t 时刻bev特征图中,直接在(n, m)处基于相对特征索引位置及权重得到所需特征1,然后在 t - 1 时刻新bev特征图中,在(n, m)处基于相对特征索引位置及权重得到所需特征2,最后将两个特征求均值得到 t 时刻新bev图中(n, m)位置处的通道向量值。至此完成bev时序对齐和融合。
2 代码展示
为了看懂如下代码,需要首先理解自动驾驶中所用到的所有坐标系,以及这些坐标系之间的转换方法,具体参考:无人驾驶中常用坐标系及相互转换的数学原理介绍_BIT_Legend的博客-CSDN博客
关于如下代码中部分关键参数的解析,可以参照如下代码原理详解

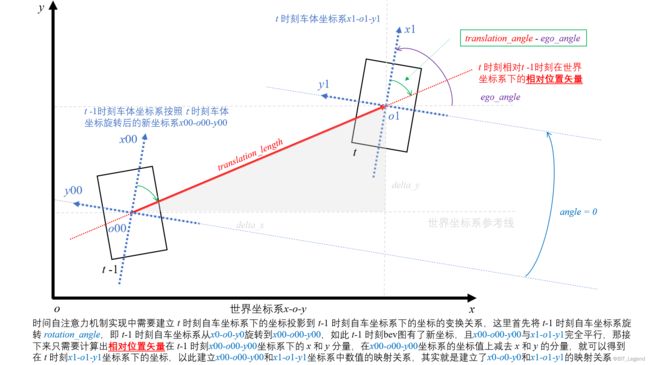

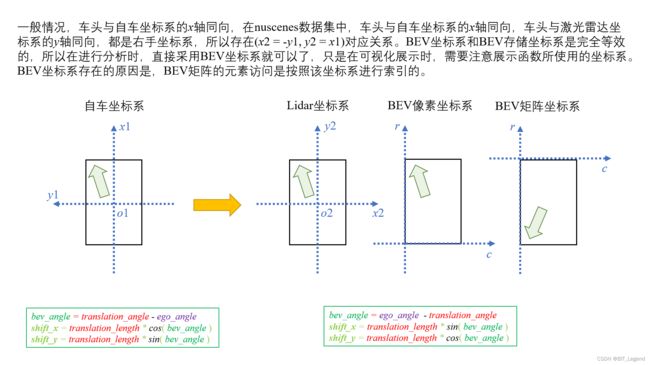
如下原始代码是在argoverse数据集上使用的,如果想要应用在nuscenes数据集上使用则需要按照下图进行修改,修改原理参照:无人驾驶中常用坐标系及相互转换的数学原理介绍_BIT_Legend的博客-CSDN博客
(1) 原始代码
# transformer.py (get_bev_features)
bs = mlvl_feats[0].size(0) # (bs, num_cams, C, H, W)
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1) # (hh*ww, c) -> (hh*ww, bs, c) (100*200, bs, c)
bev_pos = bev_pos.flatten(2).permute(2, 0, 1) # (bs, c, hh, ww) -> (hh*ww, bs, c) (100*200, bs, c)
if not self.use_shift and not prev_bev: # (2, bs) -> (bs, 2)
shift = bev_queries.new_tensor(
[[0] * bs, [0] * bs]).permute(1, 0) # xy, bs -> bs, xy 如果不使用shift,意味着不使用时间序列,那t-1帧与t帧相同,所以不用任何平移0(代码默认必须有t-1帧,所以默认用t帧代替,那就是自注意)
if self.use_can_bus: # 时序时,只需将query进行转向,不用平移query,只需要reference配合就可以实现空间位置对应(重要,仔细想清楚!!!!)
# obtain rotation angle and shift with ego motion # img_metas [dict([len_cam]*len_cam)] * bs
delta_x = np.array([each['can_bus'][0]
for each in kwargs['img_metas']]) # [bs] 前后两帧绝对距离的x分量-世界坐标系 正向为正值,反向为负值
delta_y = np.array([each['can_bus'][1]
for each in kwargs['img_metas']]) # [bs] 前后两帧绝对距离的y分量-世界坐标系 正向为正值,反向为负值
ego_angle = np.array(
[each['can_bus'][-2] / np.pi * 180 for each in kwargs['img_metas']]) # [bs] 当前n帧的转世界坐标系的角度变化,也可以认为是n帧本车坐标系在全局坐标系下的绝对角度,逆时针为正,顺时针为负 0~360
grid_length_y = grid_length[0]
grid_length_x = grid_length[1]
translation_length = np.sqrt(delta_x ** 2 + delta_y ** 2) # [bs] 前后两帧绝对距离 行车向量的绝对值,正值
translation_angle = np.arctan2(delta_y, delta_x) / np.pi * 180 # [bs] 前后两帧绝对距离矢量的绝对角度-世界坐标系 行车向量的绝对角度,-180~180,起于x轴,逆时针为正,顺时针为负
bev_angle = translation_angle - ego_angle # [bs] ego是n帧本车坐标系在全局坐标系下的绝对角度,起于x轴,trans是前后两帧绝对距离矢量的绝对角度,起于x轴,所以本角度是起于n帧自车坐标系x轴止于距离矢量的角度
shift_y = translation_length * \
np.sin(bev_angle / 180 * np.pi) / grid_length_y / bev_h # [bs] n帧的车体坐标系原点在n-1帧的车体坐标系中的y坐标-相对值 有正负
shift_x = translation_length * \
np.cos(bev_angle / 180 * np.pi) / grid_length_x / bev_w # [bs] n帧的车体坐标系原点在n-1帧的车体坐标系中的x坐标-相对值 有正负
shift_y = shift_y * self.use_shift
shift_x = shift_x * self.use_shift
shift = bev_queries.new_tensor(
[shift_x, shift_y]).permute(1, 0) # xy, bs -> bs, xy
if prev_bev is not None:
if prev_bev.shape[1] == bev_h * bev_w:
prev_bev = prev_bev.permute(1, 0, 2) # (bs, hh*ww, c) -> (hh*ww, bs, c)
if self.rotate_prev_bev:
for i in range(bs):
# num_prev_bev = prev_bev.size(1)
rotation_angle = kwargs['img_metas'][i]['can_bus'][-1] # 前后两帧相对角度-世界坐标系
tmp_prev_bev = prev_bev[:, i].reshape(
bev_h, bev_w, -1).permute(2, 0, 1) # (hh*ww, c) -> (hh, ww, c) -> (c, hh, ww)
tmp_prev_bev = rotate(tmp_prev_bev, rotation_angle) # (c, hh, ww) 默认图片中心轴旋转,矩阵存储格式旋转而非右手坐标系旋转,逆时针为正,旋转坐标系和旋转坐标等效,只是旋转角度相反
tmp_prev_bev = tmp_prev_bev.permute(1, 2, 0).reshape( # (c, hh, ww) -> (hh, ww, c) -> (hh*ww, 1, c)
bev_h * bev_w, 1, -1)
prev_bev[:, i] = tmp_prev_bev[:, 0] # (hh*ww, 1, c) -> (hh*ww, bs, c)
# add can bus signals
can_bus = bev_queries.new_tensor( # 向bev_queries中添加can_bus信息,这些信息主要是包含前后两帧的相对位置变化,也有当前帧的绝对位置信息
[each['can_bus'] for each in kwargs['img_metas']]) # (bs, 18)
can_bus = self.can_bus_mlp(can_bus)[None, :, :] # (bs, 18) -> (bs, c) -> (1, bs, c)
bev_queries = bev_queries + can_bus * self.use_can_bus # (hh*ww, bs, c) = (hh*ww, bs, c) + (1, bs, c).repeat 前三个数和最后一个数是相对值,其他数是绝对值,理论上都是相对值才好(2) 代码改进1
# transformer.py (get_bev_features)
bs = mlvl_feats[0].size(0) # (bs, num_cams, C, H, W)
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1) # (hh*ww, c) -> (hh*ww, bs, c) (100*200, bs, c)
bev_pos = bev_pos.flatten(2).permute(2, 0, 1) # (bs, c, hh, ww) -> (hh*ww, bs, c) (100*200, bs, c)
shift = bev_queries.new_tensor([[0] * bs, [0] * bs]).permute(1, 0) # (2, bs) -> (bs, 2) xy, bs -> bs, xy
if self.use_can_bus and torch.is_tensor(prev_bev):
_, _, c = prev_bev.size() # (bs, hh*ww, c)
# obtain rotation angle and shift with ego motion # img_metas [dict([len_cam]*len_cam)] * bs
delta_x = np.array([each['can_bus'][0] for each in kwargs['img_metas']]) # [bs] 前后两帧绝对距离的x分量-世界坐标系 正向为正值,反向为负值
delta_y = np.array([each['can_bus'][1] for each in kwargs['img_metas']]) # [bs] 前后两帧绝对距离的y分量-世界坐标系 正向为正值,反向为负值
delta_translation_global = bev_queries.new_tensor(
[delta_x, delta_y]).permute(1, 0).reshape(bs, 2, 1) # (2, bs) -> (bs, 2) -> (bs, 2, 1) 前后两帧绝对距离矢量
curr_angle = np.array([each['can_bus'][-2] for each in kwargs['img_metas']]) # [bs] 当前n帧的转世界坐标系的角度变化,也可以认为是n帧本车坐标系在全局坐标系下的绝对角度,逆时针为正,顺时针为负
curr_transform_matrix = np.array([[np.cos(-curr_angle),-np.sin(-curr_angle)],
[np.sin(-curr_angle), np.cos(-curr_angle)]]) # (2, 2, bs) 世界坐标转换为当前帧自车坐标
curr_transform_matrix = bev_queries.new_tensor(
curr_transform_matrix).permute(2, 0, 1) # (bs, 2, 2)
delta_translation_curr = torch.matmul(
curr_transform_matrix, delta_translation_global).squeeze() # (bs, 2, 1) -> (bs, 2) = (bs, 2, 2)* (bs, 2, 1) (真实坐标)
delta_translation_curr /= bev_queries.new_tensor([[grid_length[1], grid_length[0]]]) # (bs, 2) = (bs, 2) / (1, 2) (格子数)
delta_translation_curr = delta_translation_curr.round().tolist() # (bs, 2) List
prev_curr_angle = [each['can_bus'][-1] for each in kwargs['img_metas']] # 前后两帧相对角度-世界坐标系
prev_bev = prev_bev.reshape(bs, bev_h, bev_w, c).permute(0, 3, 1, 2) # (bs, hh*ww, c) -> (bs, hh, ww, c) -> (bs, c, hh, ww)
prev_bev_new = prev_bev.new_tensor(prev_bev) # (bs, c, hh, ww)
for i in range(bs):
prev_bev_new[i] = affine(prev_bev[i],
angle=-prev_curr_angle[i],
translate=[-delta_translation_curr[i][0], delta_translation_curr[i][1]], # 只能是整数,会带来误差
scale=1,
shear=0,
interpolation=InterpolationMode.BILINEAR,
fill=[0.0,]) # (bs, c, hh, ww)
prev_bev = prev_bev_new.permute(2, 3, 0, 1).reshape(bev_h*bev_w, bs, c) # (bs, c, hh, ww) -> (hh, ww, bs, c) -> (hh*ww, bs, c)
if self.use_can_bus:
# add can bus signals
can_bus = bev_queries.new_tensor( # 向bev_queries中添加can_bus信息,这些信息主要是包含前后两帧的相对位置变化,也有当前帧的绝对位置信息
[each['can_bus'] for each in kwargs['img_metas']]) # (bs, 18)
can_bus = self.can_bus_mlp(can_bus)[None, :, :] # (bs, 18) -> (bs, c) -> (1, bs, c)
bev_queries = bev_queries + can_bus * self.use_can_bus # (ww*hh, bs, c) = (ww*hh, bs, c) + (1, bs, c).repeat 前三个数和最后一个数是相对值,其他数是绝对值,理论上都是相对值才好
# visual bev
#############################################################################################################################################################################################
prev_bev_new = prev_bev.permute(1, 2, 0).reshape(bs, c, bev_h, bev_w) # (hh*ww, bs, c) -> (bs, c, hh*ww) -> (bs, c, hh, ww)
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
ax = axes.ravel()
ax[0].imshow(prev_bev_new.cpu()[0, 0, :, :], cmap='gray')
ax[0].set_title('batch 0, channel 0')
# plt.grid(False)
ax[1].imshow(prev_bev_new.cpu()[0, 9, :, :], cmap='gray')
ax[1].set_title('batch 0, channel 9')
fig.suptitle('visual bev')
# plt.grid(False)
plt.savefig('./visual_bev.png')在如上代码中,使用了torch的affine函数,该函数在旋转时可以实现双线性差值采样,但是在平移时只能实现整数平移,会存在取整误差,所以我们又基于torch的grid_sample函数实现了新一版代码,具体如下。关于torch中affine函数和grid_sample函数的测试参考:torch中affine函数与grid_sample函数的注解_BIT_Legend的博客-CSDN博客
(3) 代码改进2
# transformer.py (get_bev_features)
bs = mlvl_feats[0].size(0) # (bs, num_cams, C, H, W)
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1) # (hh*ww, c) -> (hh*ww, bs, c) (100*200, bs, c)
bev_pos = bev_pos.flatten(2).permute(2, 0, 1) # (bs, c, hh, ww) -> (hh*ww, bs, c) (100*200, bs, c)
shift = bev_queries.new_tensor([[0] * bs, [0] * bs]).permute(1, 0) # (2, bs) -> (bs, 2) xy, bs -> bs, xy
if self.use_can_bus and torch.is_tensor(prev_bev):
_, _, c = prev_bev.size() # (bs, hh*ww, c)
# obtain rotation angle and shift with ego motion # img_metas [dict([len_cam]*len_cam)] * bs
delta_x = np.array([each['can_bus'][0] for each in kwargs['img_metas']]) # [bs] 前后两帧绝对距离的x分量-世界坐标系 正向为正值,反向为负值
delta_y = np.array([each['can_bus'][1] for each in kwargs['img_metas']]) # [bs] 前后两帧绝对距离的y分量-世界坐标系 正向为正值,反向为负值
delta_translation_global = bev_queries.new_tensor(
[delta_x, delta_y]).permute(1, 0).reshape(bs, 2, 1) # (2, bs) -> (bs, 2) -> (bs, 2, 1) 前后两帧绝对距离矢量 (真实坐标)
curr_angle = np.array([each['can_bus'][-2] for each in kwargs['img_metas']]) # [bs] 当前n帧的转世界坐标系的角度变化,也可以认为是n帧本车坐标系在全局坐标系下的绝对角度,逆时针为正,顺时针为负
curr_transform_matrix = np.array([[np.cos(-curr_angle),-np.sin(-curr_angle)],
[np.sin(-curr_angle), np.cos(-curr_angle)]]) # (2, 2, bs) 世界坐标转换为当前帧自车坐标
curr_transform_matrix = bev_queries.new_tensor(
curr_transform_matrix).permute(2, 0, 1) # (bs, 2, 2)
delta_translation_curr = torch.matmul(
curr_transform_matrix, delta_translation_global) # (bs, 2, 1) = (bs, 2, 2)* (bs, 2, 1) 前后两帧相对矢量-当前自车坐标系 (真实坐标)
curr_y, curr_x = torch.meshgrid(
torch.linspace(0, bev_h-1, bev_h, dtype=bev_queries.dtype, device=bev_queries.device),
torch.linspace(0, bev_w-1, bev_w, dtype=bev_queries.dtype, device=bev_queries.device)) # (hh, ww), (hh, ww)
curr_y = curr_y.reshape(-1)[None] # (1, hh*ww)
curr_x = curr_x.reshape(-1)[None] # (1, hh*ww)
curr_xy = torch.stack((curr_x, curr_y), -1) # (1, hh*ww, 2)
curr_xy = curr_xy.repeat(bs, 1, 1).unsqueeze(3) # (1, hh*ww, 2) -> (bs, hh*ww, 2) -> (bs, hh*ww, 2, 1)
curr_center = bev_queries.new_tensor([[(bev_w-1)/2], [(bev_h-1)/2]]) # (2, 1)
curr_xy -= curr_center[None, None, :, :] # (bs, hh*ww, 2, 1) = (bs, hh*ww, 2, 1) - (1, 1, 2, 1).repeat (格子数)
curr_xy *= bev_queries.new_tensor([[[[grid_length[1]], [grid_length[0]]]]]) # (bs, hh*ww, 2, 1) = (bs, hh*ww, 2, 1) * (1, 1, 2, 1).repeat (真实坐标)
mid_xy = curr_xy + delta_translation_curr.unsqueeze(1) # (bs, hh*ww, 2, 1) = (bs, hh*ww, 2, 1) + (bs, 1, 2, 1).repeat (真实坐标)
prev_curr_angle = np.array(
[each['can_bus'][-1]/180*np.pi for each in kwargs['img_metas']]) # [bs] 前后两帧相对角度-世界坐标系
prev_transform_matrix = np.array(
[[np.cos(prev_curr_angle),-np.sin(prev_curr_angle)],
[np.sin(prev_curr_angle), np.cos(prev_curr_angle)]]) # (2, 2, bs)
prev_transform_matrix = bev_queries.new_tensor(
prev_transform_matrix).permute(2, 0, 1).unsqueeze(1) # (bs, 1, 2, 2)
prev_xy = torch.matmul(prev_transform_matrix, mid_xy) # (bs, hh*ww, 2, 1) = (bs, 1, 2, 2) * (bs, hh*ww, 2, 1) (真实坐标)
prev_xy = prev_xy.unsqueeze(3).reshape(bs, bev_h, bev_w, 2) # (bs, hh*ww, 2, 1) -> (bs, hh*ww, 2) -> (bs, hh, ww, 2) (真实坐标)
prev_xy /= bev_queries.new_tensor([[[[grid_length[1], grid_length[0]]]]]) # (bs, hh, ww, 2) = (bs, hh, ww, 2) / (1, 1, 1, 2) (格子数)
prev_center = bev_queries.new_tensor([(bev_w-1)/2, (bev_h-1)/2]) # (2,)
prev_xy += prev_center[None, None, None, :] # (bs, hh, ww, 2) = (bs, hh, ww, 2) + (1, 1, 1, 2) (格子数)
prev_xy /= bev_queries.new_tensor([[[[bev_w-1, bev_h-1]]]]) # (bs, hh, ww, 2) = (bs, hh, ww, 2) / (1, 1, 1, 2) (相对坐标 0~1)
prev_xy = prev_xy * 2 -1 # (bs, hh, ww, 2) (相对坐标 -1~1)
prev_bev = prev_bev.reshape(bs, bev_h, bev_w, c).permute(0, 3, 1, 2) # (bs, hh*ww, c) -> (bs, hh, ww, c) -> (bs, c, hh, ww)
prev_bev_new = grid_sample(prev_bev, prev_xy, align_corners=True) # (bs, c, hh, ww) prev_xy是采样点的x和y坐标,对应是列标和行标
prev_bev = prev_bev_new.permute(2, 3, 0, 1).reshape(bev_h*bev_w, bs, c) # (bs, c, hh, ww) -> (hh, ww, bs, c) -> (hh*ww, bs, c)
if self.use_can_bus:
# add can bus signals
can_bus = bev_queries.new_tensor( # 向bev_queries中添加can_bus信息,这些信息主要是包含前后两帧的相对位置变化,也有当前帧的绝对位置信息
[each['can_bus'] for each in kwargs['img_metas']]) # (bs, 18)
can_bus = self.can_bus_mlp(can_bus)[None, :, :] # (bs, 18) -> (bs, c) -> (1, bs, c)
bev_queries = bev_queries + can_bus * self.use_can_bus # (ww*hh, bs, c) = (ww*hh, bs, c) + (1, bs, c).repeat 前三个数和最后一个数是相对值,其他数是绝对值,理论上都是相对值才好
# visual bev
#############################################################################################################################################################################################
prev_bev_new = prev_bev.permute(1, 2, 0).reshape(bs, c, bev_h, bev_w) # (hh*ww, bs, c) -> (bs, c, hh*ww) -> (bs, c, hh, ww)
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
ax = axes.ravel()
ax[0].imshow(prev_bev_new.cpu()[0, 0, :, :], cmap='gray')
ax[0].set_title('batch 0, channel 0')
# plt.grid(False)
ax[1].imshow(prev_bev_new.cpu()[0, 9, :, :], cmap='gray')
ax[1].set_title('batch 0, channel 9')
fig.suptitle('visual bev')
# plt.grid(False)
plt.savefig('./visual_bev.png')