HTTP协议
一、定义
是一种超文本传输协议, 应用层协议
HTTP 往往是基于传输层的 TCP 协议实现的. (HTTP1.0, HTTP1.1, HTTP2.0 均为TCP, HTTP3 基于 UDP 实现) 目前我们主要使用的还是 HTTP1.1 和 HTTP2.0 . 当前课堂上讨论的 HTTP 以 1.1 版本为主. 我们平时打开一个网站, 就是通过 HTTP 协议来传输数据的.
当我们在浏览器中输入一个 搜狗搜索的 “网址” (URL) 时, 浏览器就给搜狗的服务器发送了一个 HTTP 请 求, 搜狗的服务器返回了一个 HTTP 响应. 这个响应结果被浏览器解析之后, 就展示成我们看到的页面内容. (这个过程中浏览器可能会给服务器发 送多个 HTTP 请求, 服务器会对应返回多个响应, 这些响应里就包含了页面 HTML, CSS, JavaScript, 图片, 字体等信息).
二、工作过程
当我们在浏览器中输入一个 “网址”, 此时浏览器就会给对应的服务器发送一个 HTTP 请求. 对方服务器收到这个请求之后, 经过计算处理, 就会返回一个 HTTP 响应. 事实上, 当我们访问一个网站的时候, 可能涉及不止一次的 HTTP 请求/响应 的交互过程. 可以通过 chrome 的F12开发者工具观察到这个详细的过程.
https 是在 http 基础之上做了一个加密解密的工作, 后面再介绍.
三、抓包工具的原理
Fiddler 相当于一个 “代理”. 浏览器访问 sogou.com 时, 就会把 HTTP 请求先发给 Fiddler, Fiddler 再把请求转发给 sogou 的服务器. 当 sogou 服务器返回数据时, Fiddler 拿到返回数据, 再把数据交给浏览器. 因此 Fiddler 对于浏览器和 sogou 服务器之间交互的数据细节, 都是非常清楚的
四、协议格式
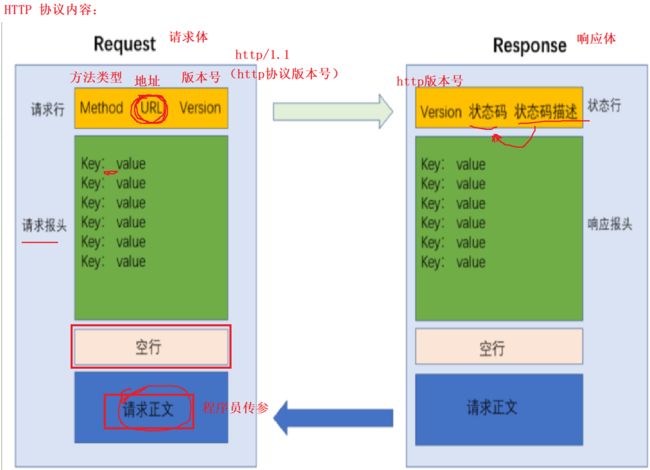

为什么 HTTP 报文中要存在 “空行”?
因为 HTTP 协议并没有规定报头部分的键值对有多少个. 空行就相当于是 “报头的结束标记”, 或者是 “报头和正文之间的分隔符”. HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的. 如果没有这个空行, 就会出现 “粘包问题”.
五、HTTP请求
URL 基本格式
平时我们俗称的 “网址” 其实就是说的 URL (Uniform Resource Locator 统一资源定位符). 互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它. 
例子
使用ping命令查看域名对应的IP地址
- 在开始菜单中输入 cmd , 打开 命令提示符
2. 在 cmd 中输入 ping v.bitedu.vip , 即可看到域名解析的结果.
关于 URL encode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义. 一个中文字符由 UTF-8 或者 GBK 这样的编码方式构成, 虽然在 URL 中没有特殊含义, 但是仍然需要进行转义. 否则浏览器可能把 UTF-8/GBK 编码中的某个字节当做 URL 中的特殊符号.
转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一 位,前面加上%,编码成%XY格式
认识 “方法” (method)
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源. 在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求. 另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求. 

认识 “状态码” (status code)
200 成功、 404 Not Found 、 403 Forbidden(拒绝访问)、 500 Internal Server Error 服务器内部错误、 504 Gateway Timeout 服务器过载大、 302 Move temporarily 临时重定向、 301 Moved Permanently 永久重定向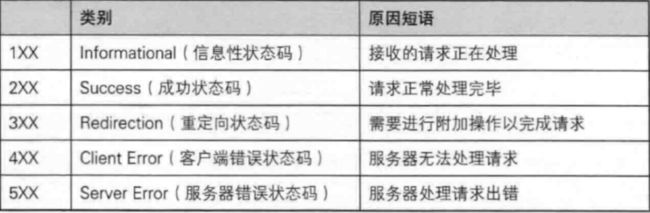
六、cookie


七、HTTPS
https与http协议区别在于,https协议在数据传输过程中使用了SSL/TLS协议进行加密和身份验证
http默认端口号80,https默认端口号443
https=http+加密+认证+完整性保护