ELK日志记录——Kibana组件——grok 正则捕获插件、mutate数据修改插件、multiline 多行合并插件、date 时间处理插件
grok 正则捕获插件
grok 使用文本片段切分的方式来切分日志事件
内置正则表达式调用
%{SYNTAX:SEMANTIC}
●SYNTAX代表匹配值的类型,例如,0.11可以NUMBER类型所匹配,10.222.22.25可以使用IP匹配。
●SEMANTIC表示存储该值的一个变量声明,它会存储在elasticsearch当中方便kibana做字段搜索和统计,你可以将一个IP定义为客户端IP地址client_ip_address,如%{IP:client_ip_address},所匹配到的值就会存储到client_ip_address这个字段里边,类似数据库的列名,也可以把 event log 中的数字当成数字类型存储在一个指定的变量当中,比如响应时间http_response_time,假设event log record如下:
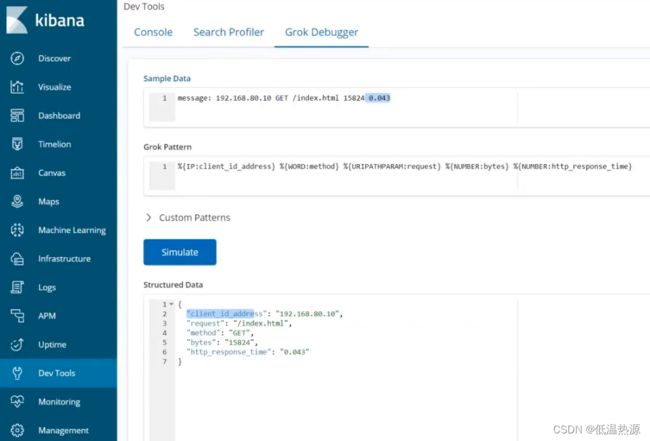
message: 192.168.80.10 GET /index.html 15824 0.043可以使用如下grok pattern来匹配这种记录
%{IP:client_id_address} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:http_response_time}对应关系
192.168.80.10 GET /index.html 15824 0.043 %{IP:client_id_address} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:http_response_time}可以输入kibana开发工具的GROK测试工具进行正则表达式测试
在logstash conf.d文件夹下面创建filter conf文件,内容如下
/etc/logstash/conf.d/01-filter.conf filter { grok { match => { "message" => "%{IP:client_id_address} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:http_response_time}" } } }以下是filter结果
client_id_address: 192.168.80.10 method: GET request: /index.html bytes: 15824 http_response_time: 0.043
logstash 官方也给了一些常用的常量来表达那些正则表达式,可以到这个 Github 地址查看有哪些常用的常量
https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patterns
USERNAME [a-zA-Z0-9._-]+ USER %{USERNAME} EMAILLOCALPART [a-zA-Z][a-zA-Z0-9_.+-=:]+ EMAILADDRESS %{EMAILLOCALPART}@%{HOSTNAME} INT (?:[+-]?(?:[0-9]+)) BASE10NUM (?[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+))) NUMBER (?:%{BASE10NUM}) BASE16NUM (?POSINT \b(?:[1-9][0-9]*)\b NONNEGINT \b(?:[0-9]+)\b WORD \b\w+\b NOTSPACE \S+ SPACE \s* DATA .*? GREEDYDATA .* QUOTEDSTRING (?>(?"(?>\\.|[^\\"]+)+"|""|(?>'(?>\\.|[^\\']+)+')|''|(?>(?>\\.|[^\\]+)+)|)) UUID [A-Fa-f0-9]{8}-(?:[A-Fa-f0-9]{4}-){3}[A-Fa-f0-9]{12} # URN, allowing use of RFC 2141 section 2.3 reserved characters URN urn:[0-9A-Za-z][0-9A-Za-z-]{0,31}:(?:%[0-9a-fA-F]{2}|[0-9A-Za-z()+,.:=@;$_!*'/?#-])+IPV4匹配?【面试题】
不能[0-9]{1-3}.[0-9]{1-3}.[0-9]{1-3}.[0-9]{1-3} 0-9三次然后四个点间隔要把每一位字符都做匹配(由于0-255)分段表示,然后用或连接。
# Networking MAC (?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC}) CISCOMAC (?:(?:[A-Fa-f0-9]{4}\.){2}[A-Fa-f0-9]{4}) WINDOWSMAC (?:(?:[A-Fa-f0-9]{2}-){5}[A-Fa-f0-9]{2}) COMMONMAC (?:(?:[A-Fa-f0-9]{2}:){5}[A-Fa-f0-9]{2}) IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)? IPV4 (?# paths PATH (?:%{UNIXPATH}|%{WINPATH}) UNIXPATH (/([\w_%!$@:.,+~-]+|\\.)*)+ TTY (?:/dev/(pts|tty([pq])?)(\w+)?/?(?:[0-9]+)) WINPATH (?>[A-Za-z]+:|\\)(?:\\[^\\?*]*)+ URIPROTO [A-Za-z]([A-Za-z0-9+\-.]+)+ URIHOST %{IPORHOST}(?::%{POSINT:port})? # uripath comes loosely from RFC1738, but mostly from what Firefox # doesn't turn into %XX URIPATH (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%&_\-]*)+ #URIPARAM \?(?:[A-Za-z0-9]+(?:=(?:[^&]*))?(?:&(?:[A-Za-z0-9]+(?:=(?:[^&]*))?)?)*)? URIPARAM \?[A-Za-z0-9$.+!*'|(){},~@#%&/=:;_?\-\[\]<>]* URIPATHPARAM %{URIPATH}(?:%{URIPARAM})? URI %{URIPROTO}://(?:%{USER}(?::[^@]*)?@)?(?:%{URIHOST})?(?:%{URIPATHPARAM})?# Months: January, Feb, 3, 03, 12, December MONTH \b(?:[Jj]an(?:uary|uar)?|[Ff]eb(?:ruary|ruar)?|[Mm](?:a|ä)?r(?:ch|z)?|[Aa]pr(?:il)?|[Mm]a(?:y|i)?|[Jj]un(?:e|i)?|[Jj]ul(?:y)?|[Aa]ug(?:ust)?|[Ss]ep(?:tember)?|[Oo](?:c|k)?t(?:ober)?|[Nn]ov(?:ember)?|[Dd]e(?:c|z)(?:ember)?)\b MONTHNUM (?:0?[1-9]|1[0-2]) MONTHNUM2 (?:0[1-9]|1[0-2]) MONTHDAY (?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9]) # Days: Monday, Tue, Thu, etc... DAY (?:Mon(?:day)?|Tue(?:sday)?|Wed(?:nesday)?|Thu(?:rsday)?|Fri(?:day)?|Sat(?:urday)?|Sun(?:day)?)# Years? YEAR (?>\d\d){1,2} HOUR (?:2[0123]|[01]?[0-9]) MINUTE (?:[0-5][0-9]) # '60' is a leap second in most time standards and thus is valid. SECOND (?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?) TIME (?!<[0-9])%{HOUR}:%{MINUTE}(?::%{SECOND})(?![0-9]) # datestamp is YYYY/MM/DD-HH:MM:SS.UUUU (or something like it) DATE_US %{MONTHNUM}[/-]%{MONTHDAY}[/-]%{YEAR} DATE_EU %{MONTHDAY}[./-]%{MONTHNUM}[./-]%{YEAR} ISO8601_TIMEZONE (?:Z|[+-]%{HOUR}(?::?%{MINUTE})) ISO8601_SECOND (?:%{SECOND}|60) TIMESTAMP_ISO8601 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}? DATE %{DATE_US}|%{DATE_EU} DATESTAMP %{DATE}[- ]%{TIME} TZ (?:[APMCE][SD]T|UTC) DATESTAMP_RFC822 %{DAY} %{MONTH} %{MONTHDAY} %{YEAR} %{TIME} %{TZ} DATESTAMP_RFC2822 %{DAY}, %{MONTHDAY} %{MONTH} %{YEAR} %{TIME} %{ISO8601_TIMEZONE} DATESTAMP_OTHER %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{TZ} %{YEAR} DATESTAMP_EVENTLOG %{YEAR}%{MONTHNUM2}%{MONTHDAY}%{HOUR}%{MINUTE}%{SECOND}# Syslog Dates: Month Day HH:MM:SS SYSLOGTIMESTAMP %{MONTH} +%{MONTHDAY} %{TIME} PROG [\x21-\x5a\x5c\x5e-\x7e]+ SYSLOGPROG %{PROG:program}(?:\[%{POSINT:pid}\])? SYSLOGHOST %{IPORHOST} SYSLOGFACILITY <%{NONNEGINT:facility}.%{NONNEGINT:priority}> HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}# Shortcuts QS %{QUOTEDSTRING}# Log formats SYSLOGBASE %{SYSLOGTIMESTAMP:timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}:# Log Levels LOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)

实例 使用 系统预定义变量 与 自定义变量 完成对日志文件的匹配
测试成功的正则表达式写入logstash配置文件中
vim /etc/logstash/conf.d/filebeat.conf filter { grok { match => [ "message" , "正则表达式" ] #match匹配 message字段 正则表达式 写在“ ”内 } }
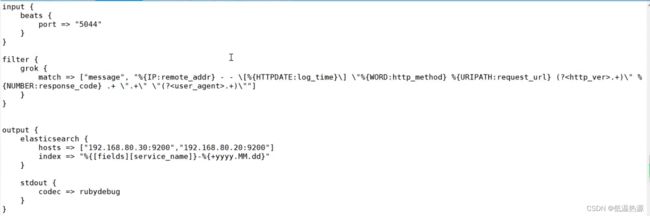
自定义表达式调用
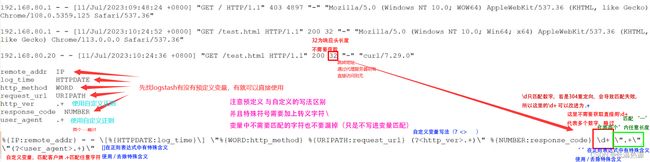
语法 (?pattern) 举例 捕获10或11和长度的十六进制数的queue_id可以使用表达式(? [0-9A-F]{10,11}) 匹配IP \d{1,3} 数字1-3次 以 . 间隔 重复4次
匹配方式(get/post) A-Z一次或多次
匹配网址 /.* / 后所有
响应时间 由于是浮点数需要匹配中间的 . [0-9\.]+ 斜杠\. 取消 . 的特殊含义 0-9和. 匹配多从
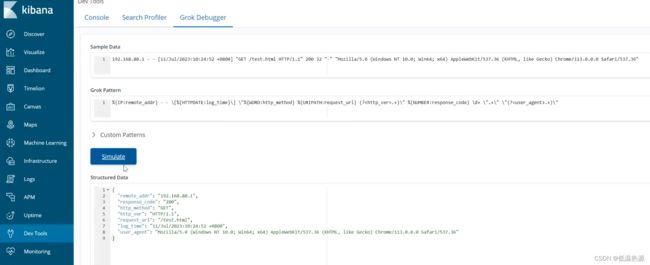
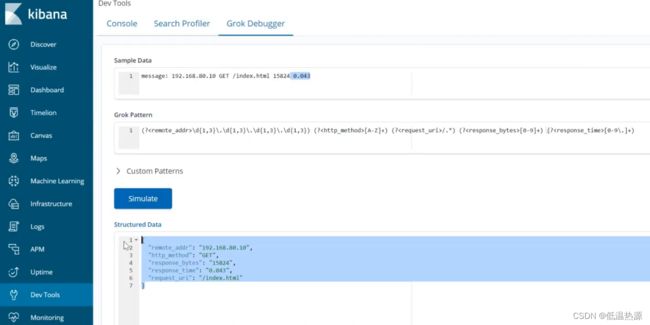
message: 192.168.80.10 GET /index.html 15824 0.043 (?\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (? [A-Z]+) (? /.*) (? [0-9]+) (? [0-9\.]+) 在kibana开发工具中测试
写入配置文件 实现过滤
/etc/logstash/conf.d/01-filter.conf filter { grok { match => { "message" => "(?%{IP}) (? [A-Z]+) (? /.*) (? [0-9]+) (? [0-9\.]+)"} } }
如果表达式匹配失败,会生成一个tags字段,字段值为 _grokparsefailure,需要重新检查上边的match配置解析是否正确。
mutate 数据修改插件
它提供了丰富的基础类型数据处理能力。可以重命名,删除,替换和修改事件中的字段。
Mutate 过滤器常用的配置选项
add_field 向事件添加新字段,也可以添加多个字段
remove_field 从事件中删除任意字段(只能删除logstash自己的或是日志的字段。可能不能删除filebeat字段)
add_tag 向事件添加任意标签,在tag字段中添加一段自定义的内容,当tag字段中超过一个内容的时候会变成数组
remove_tag 从事件中删除标签(如果存在)
convert 将字段值转换为另一种数据类型
id 向现场事件添加唯一的ID
lowercase 将字符串字段转换为其小写形式
replace 用新值替换字段
strip 删除开头和结尾的空格
uppercase 将字符串字段转换为等效的大写字母
update 用新值更新现有字段
rename 重命名事件中的字段
gsub 通过正则表达式替换字段中匹配到的值
merge 合并数组或 hash 事件
split 通过指定的分隔符分割字段中的字符串为数组
示例
●将字段old_field重命名为new_field
filter { mutate { #写法1,使用中括号括起来 rename => ["old_field" => "new_field"] #写法2,使用大括号{}括起来 rename => { "old_field" => "new_field" } } }●添加字段
filter { mutate { add_field => { "f1" => "field1value" "f2" => "field2value" } } }
●将字段删除filter { mutate { remove_field => ["message", "@version", "tags"] } }
●将filedName1字段数据类型转换成string类型,filedName2字段数据类型转换成float类型filter { mutate { #写法1,使用中括号括起来 convert => ["filedName1", "string"] #写法2,使用大括号{}括起来 convert => { "filedName2" => "float" } } }
●将filedName字段中所有"/“字符替换为”_"filter { mutate { gsub => ["filedName", "/" , "_"] } }
●将filedName字段中所有",“字符后面添加空格(替换)filter { mutate { gsub => ["filedName", "," , ", "] } }
●将filedName字段以"|"为分割符拆分数据成为数组filter { mutate { split => ["filedName", "|"] } }
●合并 “filedName1” 和 “ filedName2” 两个字段filter { merge { "filedName2" => "filedName1" } }
●用新值替换filedName字段的值filter { mutate { replace => { "filedName" => "new_value" } } }
●添加字段first,值为message数组的第一个元素的值filter { mutate { split => ["message", "|"] add_field => { "first" => "%{[message][0]}" } } }
●有条件的添加标签filter { #在日志文件路径包含 access 的条件下添加标签内容 if [path] =~ "access" { mutate { add_tag => ["Nginx Access Log"] } } #在日志文件路径是 /var/log/nginx/error.log 的条件下添加标签内容 if [path] == "/var/log/nginx/error.log" { mutate { add_tag => ["Nginx Error Log"] } } }
multiline 多行合并插件
java错误日志一般都是一条日志很多行的,会把堆栈信息打印出来,当经过 logstash 解析后,每一行都会当做一条记录存放到 ES, 那这种情况肯定是需要处理的。 这里就需要使用 multiline 插件,对属于同一个条日志的记录进行拼接。
2022-11-11 17:09:19.774[XNIo-1 task-1]ERROR com.passjava.controlle .NembercController-查询用户 活动数据失败,异常信息为: com.passjava.exception.MemberException: 当前没有配置活动规则 at com.passjava.service.impL.queryAdmin(DailyServiceImpl.java:1444) at com.passjava.service.impl.dailyserviceImpL$$FastcLass 2022-11-11 17:10:56.256][KxNIo-1 task-1] ERROR com.passjava.controlle .NemberControl1er-查询员工 饭活动数据失败,异常信息为: com.passjava.exception.MemberException: 当前没有配置活动规则 at com.passjava.service.impL.queryAdmin(DailyServiceImpl.java:1444) at com.passjava.service.impL.daiLyserviceImpL$$FastcLass
安装 multiline 插件
在线安装插件
cd /usr/share/logstash bin/logstash-plugin install logstash-filter-multiline离线安装插件
先在有网的机器上在线安装插件,然后打包,拷贝到服务器,执行安装命令打包 bin/logstash-plugin prepare-offline-pack --overwrite --output logstash-filter-multiline.zip logstash-filter-multiline 安装 bin/logstash-plugin install file:///usr/share/logstash/logstash-filter-multiline.zip检查下插件是否安装成功,可以执行以下命令查看插件列表
bin/logstash-plugin list
使用 multiline 插件
第一步:每一条日志的第一行开头都是一个时间,可以用时间的正则表达式匹配到第一行。
第二步:然后将后面每一行的日志与第一行合并。
第三步:当遇到某一行的开头是可以匹配正则表达式的时间的,就停止第一条日志的合并,开始合并第二条日志。
第四步:重复第二步和第三步。filter { multiline { pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}" negate => true what => "previous" } }●pattern:用来匹配文本的表达式,也可以是grok表达式(这里匹配年月日)
●what:如果pattern匹配成功的话,那么匹配行是归属于上一个事件,还是归属于下一个事件。previous: 归属于上一个事件,向上合并。next: 归属于下一个事件,向下合并
●negate:是否对pattern的结果取反。false:不取反,是默认值。true:取反。即 pattern匹配失败 false(此行不包含日期),则取反false变为true 合并行。
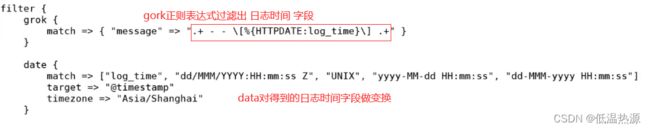
date 时间处理插件
用于分析字段中的日期,然后使用该日期或时间戳作为事件的logstash时间戳。需要配合gork模块使用(对gork分隔出的时间字段做变换)
在Logstash产生了一个Event对象的时候,会给该Event设置一个时间,字段为“@timestamp”,同时,我们的日志内容一般也会有时间,但是这两个时间是不一样的,因为日志内容的时间是该日志打印出来的时间,而“@timestamp”字段的时间是input插件接收到了一条数据并创建Event的时间,所有一般来说的话“@timestamp”的时间要比日志内容的时间晚一点,因为Logstash监控数据变化,数据输入,创建Event导致的时间延迟。这两个时间都可以使用,具体要根据自己的需求来定。
使用data模块将产生日子时间与收集日志时间统一
filter { date { match => ["access_time", "dd/MMM/YYYY:HH:mm:ss Z", "UNIX", "yyyy-MM-dd HH:mm:ss", "dd-MMM-yyyy HH:mm:ss"] #这里的access_time为grok分隔出来的字段 匹配日月年 unix 年月日 不同时间格式 target => "@timestamp" timezone => "Asia/Shanghai" } }●match:用于配置具体的匹配内容规则,前半部分内容表示匹配实际日志当中的时间戳的名称,后半部分则用于匹配实际日志当中的时间戳格式,这个地方是整条配置的核心内容,如果此处规则匹配是无效的,则生成后的日志时间戳将会被input插件读取的时间替代。
如果时间格式匹配失败,会生成一个tags字段,字段值为 _dateparsefailure,需要重新检查上边的match配置解析是否正确。●target:将匹配的时间戳存储到给定的目标字段中。如果未提供,则默认更新事件的@timestamp字段。(kibana中显示的time字段就是引用的@timestamp字段)
●timezone:当需要配置的date里面没有时区信息,而且不是UTC时间,需要设置timezone参数。
时间戳详解
●年
yyyy #全年号码。 例如:2015。
yy #两位数年份。 例如:2015年的15。●月
M #最小数字月份。 例如:1 for January and 12 for December.。
MM #两位数月份。 如果需要,填充零。 例如:01 for January and 12 for Decembe
MMM #缩短的月份文本。 例如: Jan for January。 注意:使用的语言取决于您的语言环境。 请参阅区域设置以了解如何更改语言。
MMMM #全月文本,例如:January。 注意:使用的语言取决于您的语言环境。●日
d #最少数字的一天。 例如:1月份的第一天1。
dd #两位数的日子,如果需要的话可以填零.例如:01 for the 1st of the month。●时
H #最小数字小时。 例如:0表示午夜。
HH #两位数小时,如果需要填零。 例如:午夜00。●分
m #最小的数字分钟。 例如:0。
mm #两位数分钟,如果需要填零。 例如:00。●秒
s #最小数字秒。 例如:0。
ss #两位数字,如果需要填零。 例如:00。●毫秒( 秒的小数部分最大精度是毫秒(SSS)。除此之外,零附加。)
S #十分之一秒。例如:0为亚秒值012
SS #百分之一秒 例如:01为亚秒值01
SSS #千分之一秒 例如:012为亚秒值012●时区偏移或身份
Z #时区偏移,结构为HHmm(Zulu/UTC的小时和分钟偏移量)。例如:-0700。
ZZ #时区偏移结构为HH:mm(小时偏移和分钟偏移之间的冒号)。 例如:-07:00。
ZZZ #时区身份。例如:America/Los_Angeles。 注意:有效的ID在列表中列出http://joda-time.sourceforge.net/timezones.html
案例
192.168.80.10 - - [07/Feb/2022:16:24:19 +0800] “GET /HTTP/1.1” 403 5039现在我们想转换时间,那就要写出"dd/MMM/yyyy:HH:mm:ss Z"
你发现中间有三个M,你要是写出两个就不行了,因为两个大写的M表示两位数字的月份,可是我们要解析的文本中,月份则是使用简写的英文,所以只能去找三个M。还有最后为什么要加上个大写字母Z,因为要解析的文本中含有“+0800”时区偏移,因此我们要加上去,否则filter就不能正确解析文本数据,从而转换时间戳失败。filter{ grok{ match => {"message" => ".* -\ -\ \[%{HTTPDATE:timestamp}\]"} } date{ match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"] } }运行结果
{ "host" => "localhost", "timestamp" => "07/Feb/2022:16:24:19 +0800", "@timestamp" => 2022-02-07T08:24:19.000Z, "message" => "192.168.80.10 - - [07/Feb/2022:16:24:19 +0800] \"GET /HTTP/1.1\" 403 5039", "@version" => "1" }在上面那段rubydebug编码格式的输出中,@timestamp字段虽然已经获取了timestamp字段的时间,但是仍然比北京时间晚了8个小时,这是因为在Elasticsearch内部,对时间类型字段都是统一采用UTC时间,而日志统一采用UTC时间存储,是国际安全、运维界的一个共识。其实这并不影响什么,因为ELK已经给出了解决方案,那就是在Kibana平台上,程序会自动读取浏览器的当前时区,然后在web页面自动将UTC时间转换为当前时区的时间。
案例2
测试gork过滤出日志时间字段
写入 logstash配置文件中,再用data模块将过滤出的日志时间字段做变换