Python爬虫——8.scrapy—深度爬取
还是以前面文章提到的爬取智联招聘数据为例,首先分析一下网页特征,要爬取的数据职位名称、公司名称、职位月薪这些数据是直接渲染在网页中的,所谓的深度爬取则是在只抓取一个url的情况下获取该页面上其他页面的链接,然后将这些url加入到urljoin()中进行一一爬取。
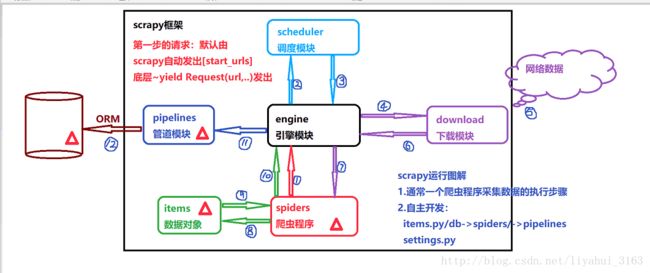
以下是简单的scrapy框架的底层图解:
1.首先,让我们先创建一个scrapy项目:
python2 -m scrapy startproject myspider
项目结构如下:
--myspider
--myspider
--spiders
--__init__.py
--__init__.py
--items.py # 数据类型模块
--middlewares.py
--settings.py # 设置模块
--pipelines.py # 管道模块,用于数据的保存
--scrapy.cfg
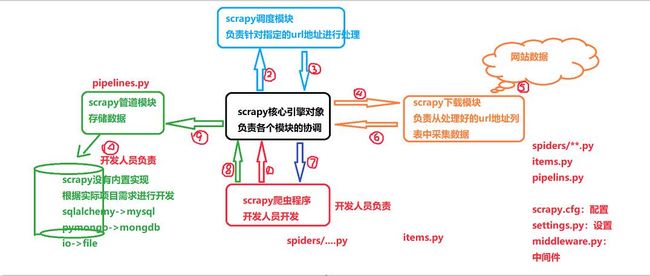
在这里,我们再来回忆一下在scrapy框内部是如何运行的
2.分析采集数据的字段,将其封装在items.py文件中
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class MyspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class ZhilianItem(scrapy.Item): ''' 在item文件中定义获取数据的字段,该类型继承自srapy.item, ''' job_name=scrapy.Field() company=scrapy.Field() salary=scrapy.Field()
3.编写爬虫程序myspider/myspider/spiders/zhilian_spider.py
# -*-coding:utf-8 -*- ''' 为了可以直接使用scrapy内置的爬虫操作,让scrapy自动采集数据,我们需要定义一个爬虫处理类 在spiders/zhilianspider.py模块中定义ZhilianSpider类型,继承自scrapy.Spider 类型中的属性:name属性~爬虫名称,用于在命令行启动爬虫时调用 类型中的属性:start_urls属性~采集数据的初始url地址[列表、元组] 类型中的属性:allowed_domains属性~采集数据的网站域名限制 类型中的方法:parse(self, response)采集完数据之后自动执行的函数 ''' import scrapy from .. import items class ZhilianSpider(scrapy.Spider): name = 'zlspider' start_urls = ["http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC&kw=%E7%88%AC%E8%99%AB&sm=0&sg=cab76822e6044ff4b4b1a907661851f9&p=1 ",] allowed_domains=['zhaopin.com'] def parse(self, response): ''' 在这里,从下载模块获取的数据response不在此函数中处理,这个函数只是将获取的第一个url加入的urljoin()中管理,暂时不做数据处理 并将scrapy.Request()请求对象提交到parse_response()函数中,此时后面若提交了与此url相同的url,则urljoin()会自动去重 避免了页面重复获取。 :param response: :return: ''' # 将url加入到urljoin中 url = response.urljoin(self.start_urls[0]) # 将请求数据交给self.parse_response()进行处理 yield scrapy.Request(url, callback=self.parse_response) def parse_response(self,response): # 采集到的数据就在response中,定义专门保存items对象即数据对象的列表 job_items = [] # xpath语法,先筛选出智联招聘每一条招聘信息,即每一行 job_list = response.xpath("//div[@id='newlist_list_content_table']/table[position()>1]/tr[1]") for select in job_list: # 在进行第一次筛选后进行进一步的筛选,依次筛选出职位信息,公司名称,职位月薪,结合网页中源代码
# 职位名称,string(.)可以获取该节点以及其子节点的文本 job_name = job.xpath("td[@class='zwmc']/div/a").xpath("string(.)").extract()[0] # 公司名称 company = job.xpath("td[@class='gsmc']/a").xpath("string(.)").extract()[0] # 薪水 salary = job.xpath("td[@class='zwyx']").xpath("string(.)").extract()[0] # 实例化items对象 job_item = items.ZhilianItem() job_item['job_name'] = job_name job_item['company'] = company job_item['salary'] = salary job_items.append(job_item) # 这个方法是将数据保存在本地文件中 # 将列表返回,通过python2 -m scrapy crawl zlspider -o job.csv # 可以将数据保存在名为job的.csv文件,即表格文件中,文件后缀名可选的有csv/json/jl/jsonline等 # return job_items # 文件打开如下: # 将数据交给Pipelines模块 yield job_item # next_pate,在当前路由页面中获取下一页的链接,得到后面所有页面的链接列表 # 该列表中包含了第一个url,由于第一个url也已经交由urljoin()管理,所以若后面urljoin()再次遇到相同的url # 就会自动去重,类似python中的集合set next_list = response.xpath("//div[@class='pagesDown']/ul/li/a/@href").extract() for page in next_list: # 将链接加入到urljoin列表中 url = response.urljoin(page) # 将请求数据交给self.parse()进行处理,递归获取数据的筛选,并通过yield job_item将数据对象提交给管道模块进行保存 yield scrapy.Request(url, callback=self.parse_response)
关于深度获取:
在获取到智联招聘第一页的url后,可以通过response.xpath()对该页面上存在的第2、3、4、5....的链接href进行获取。先获取
第一个页面,进行相应的字段筛选,构建item数据类型并交给pipeline模块进行保存到数据库,依次循环。为了保证获取到的
链接不会与第一个页面的url重复,我们在parse()函数中并没有直接对第一页数据进行筛选和提交,而是把url交给了
response.urljoin()进行管理,并且创建srapy.Request(url,callback=self.parse_response)请求对象,并将其交给parse_response
()函数进行处理,也就是将第一页爬取到的数据交给parse_response()进行数据处理,在
parse_response()函数中,首先处理了第一页的数据,并从中筛选出了所有的页面链接,包括了其他页面,同时也包括了
原来的第一页,每个url都要交个response.urljoin()进行管理,当urljoin()遇到了重复的url,会自动去重,所以这样就获取到
了完整的并且不会重复的数据。如果筛选的条件不同,导致总的页数不一样,也可以通过这种方法进行深度爬取,获取到完整的
数据。
4.管道模块:pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class MyspiderPipeline(object): def process_item(self, item, spider): return item from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker # 替换mysqldb模块 import pymysql pymysql.install_as_MySQLdb() # 在Pipeline.py文件中定义用于接收并保存数据到Mysql数据库的类型 class ZhilianPipeline(object): ''' 定义__init__函数,用于初始化数据,可用于打开文件、打开数据库连接等,必要时写 ''' def __init__(self): # 在这里与数据库建立连接 # 创建引擎对象 self.engine=create_engine("mysql://root:0@localhost/python_spider?charset=utf8") # 创建会话构建对象 Session=sessionmaker(bind=self.engine) self.session=Session() def open_spider(self,spider): ''' 爬虫开启时需要调用的函数,经常用于数据初始化 :param spider: :return: ''' pass def close_spider(self,spider): ''' 爬虫程序关闭时自动调用的而寒暑,经常用于做一些资源回收的工作, 如关闭和数据库的会话连接 :param spider: :return: ''' pass self.session.close() def process_item(self,item,spider): ''' 核心处理模块,该函数会接受爬虫程序已经封装好的item对象, 通过sql语句,将数据存储在数据库中 :param item: :param spider: :return: ''' print("正在保存数据到数据库") sql="insert into job(job_name,company,salary) values('%s','%s','%s')"\ %(item['job_name'],item['company'],item['salary']) # 执行sql语句 self.session.execute(sql) self.session.commit()