36.RocketMQ之Broker如何实现磁盘文件高性能读写
highlight: arduino-light
Broker读写磁盘文件的核心技术:mmap
Broker中大量的使用mmap技术去实现CommitLog这种大磁盘文件的高性能读写优化的。
通过之前的学习,我们知道了一点,就是Broker对磁盘文件的写入主要是借助直接写入os cache来实现性能优化的,因为直接写入os cache,相当于就是写入内存一样的性能,后续等os内核中的线程异步把cache中的数据刷入磁盘文件即可。
那么今天我们就要对这个过程中涉及到的mmap技术进行一定的分析。
1.传统文件IO:4次数据拷贝
首先我们先来给大家分析一下,假设RocketMQ没有使用mmap技术,就是使用最传统和基本的普通文件IO操作去进行磁盘文件的读写,那么会存在什么样的性能问题?
答案是:多次数据拷贝问题
首先,假设我们有一个程序,这个程序需要对磁盘文件发起IO操作读取他里面的数据到自己这儿来,那么会经过以下一个顺序:
首先从磁盘上把数据读取到内核IO缓冲区里去,然后再从内核IO缓存区里读取到用户进程私有空间里去,然后我们才能拿到这个文件里的数据。
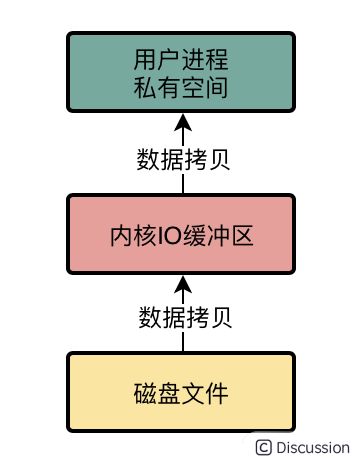
为了读取磁盘文件里的数据,是不是发生了两次数据拷贝?
没错,所以这个就是普通的IO操作的一个弊端,必然涉及到两次数据拷贝操作,对磁盘读写性能是有影响的。
那么如果我们要将一些数据写入到磁盘文件里去呢?
那这个就是一样的过程了,必须先把数据写入到用户进程私有空间里去,然后从这里再进入内核IO缓冲区,最后进入磁盘文件里去
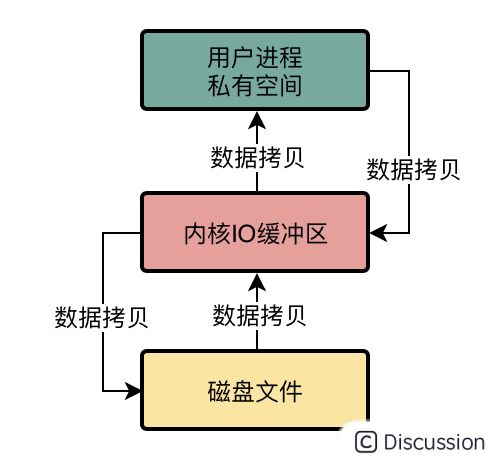
在数据进入磁盘文件的过程中,是不是再一次发生了两次数据拷贝?
没错,所以这就是传统普通IO的问题,有4次数据拷贝问题。
2.基于mmap+pageCache技术优化
mmap是什么
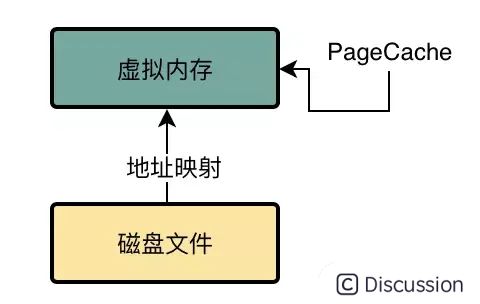
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系.
对文件进行mmap后,会在进程的虚拟内存分配地址空间,创建与磁盘的映射关系。 实现这样的映射后,就可以以指针的方式读写操作映射的虚拟内存,系统则会自动回写磁盘;相反,内核空间对这段区域的修改也直接反映到用户空间,从而可以实现不同进程间的数据共享。与传统IO模式相比,减少了一次用户态copy到内核态的操作。
mmap+write
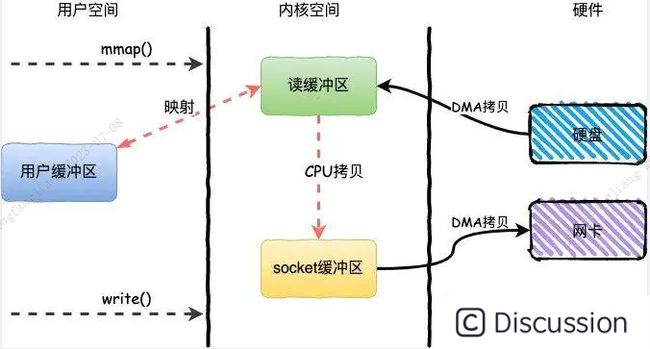
mmap+write简单来说就是使用mmap替换了read+write中的read操作,减少了一次CPU的拷贝。
mmap主要实现方式是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
本来是read + write是4切4拷。
现在变成了1次映射 + 3次拷贝 + 4切
1.从磁盘通过DMA拷贝到内核缓存区 2.从内核映射到用户缓存区 3.写的时候直接基于内核缓存区写到socket缓冲区 4.再从socket缓冲区到网卡引擎
接着我们来看一下,RocketMQ如何利用mmap技术配合page cache技术进行文件读写优化的?
首先,RocketMQ底层对CommitLog、ConsumeQueue之类的磁盘文件的读写操作,基本上都会采用mmap技术来实现。
如果具体到代码层面,就是基于JDK NIO包下的MappedByteBuffer的map()函数,来将磁盘文件CommitLog文件,或者ConsumeQueue文件映射到内存里来
这里我必须给大家解释一下,这个所谓的内存映射是什么意思
其实有的人可能会误以为是直接把那些磁盘文件里的数据给读取到内存里来了,类似这个意思,但是并不完全是对的。
因为刚开始你建立映射的时候,并没有任何的数据拷贝操作,其实磁盘文件还是停留在那里,只不过他把物理上的磁盘文件的一些地址和用户进程私有空间的一些虚拟内存地址进行了一个映射
``` mmap 把文件映射到用户空间里的虚拟内存,省去了从内核缓冲区复制到用户空间的过程,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,这样的文件读写文件方式少了数据从内核缓存到用户空间的拷贝,效率很高。
第一步:mmap系统调用使得文件内容被DMA引擎复制到内核缓冲区。然后该缓冲区与用户进程共享,在内核和用户内存空间之间不进行任何拷贝。
第二步:写系统调用使得内核将数据从原来的内核缓冲区复制到与套接字相关的内核缓冲区。
第三步:第三次拷贝发生在DMA引擎将数据从内核套接字缓冲区传递给协议引擎时。
通过使用mmap而不是read,我们将内核需要拷贝的数据量减少了一半。当大量的数据被传输时,这将有很好的效果。 ```
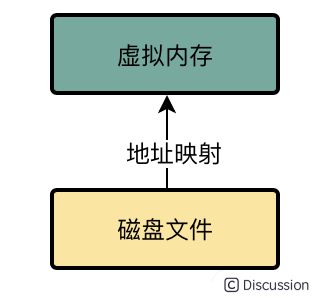
这个地址映射的过程,就是JDK NIO包下的MappedByteBuffer.map()函数干的事情,底层就是基于mmap技术实现的。
另外这里给大家说明白的一点是,这个mmap技术在进行文件映射的时候,一般有大小限制,在1.5GB~2GB之间
所以RocketMQ才让CommitLog单个文件在1GB,ConsumeQueue文件在5.72MB,不会太大。
这样限制了RocketMQ底层文件的大小,就可以在进行文件读写的时候,很方便的进行内存映射了。
然后接下来要给大家讲的一个概念,就是之前给大家说的PageCache,实际上在这里就是对应于虚拟内存
所以我们在下面的图里就给大家画出了这个示意。 !
mmap优点
1、对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,用内存读写取代I/O读写,提高了文件读取效率。
2、实现了用户空间和内核空间的高效交互方式。两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
3、提供进程间共享内存及相互通信的方式。不管是父子进程还是无亲缘关系的进程,都可以将自身用户空间映射到同一个文件或匿名映射到同一片区域。从而通过各自对映射区域的改动,达到进程间通信和进程间共享的目的。
同时,如果进程A和进程B都映射了区域C,当A第一次读取C时通过缺页从磁盘复制文件页到内存中;但当B再读C的相同页面时,虽然也会产生缺页异常,但是不再需要从磁盘中复制文件过来,而可直接使用已经保存在内存中的文件数据。
4、可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助硬盘空间协助操作,补充内存的不足。但是进一步会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
相比磁盘空间,内存那么小,Mmap操作是不是很占用内存空间?
需要注意的是,进行Mmap映射时,并不是直接申请与磁盘文件一样大小的内存空间;而是使用进程的地址空间与磁盘文件地址进行映射,当真正的文件读取是当进程发起读或写操作时。
当进行IO操作时,发现用户空间内不存在对应数据页时(缺页),会先到交换缓存空间(swap cache)去读取,如果没有找到再去磁盘加载(调页)。
需要注意的是,进行Mmap映射时,并不是直接申请与磁盘文件一样大小的内存空间;而是使用进程的地址空间与磁盘文件地址进行映射,当真正的文件读取是当进程发起读或写操作时。
当进行IO操作时,发现用户空间内不存在对应数据页时(缺页),会先到交换缓存空间(swap cache)去读取,如果没有找到再去磁盘加载(调页)。
mmap有哪些应用场景?
进程间通信: 从自身属性来看,mmap具有提供进程间共享内存及相互通信的能力,各进程可以将自身用户空间映射到同一个文件的同一片区域,通过修改和感知映射区域,达到进程间通信和进程间共享的目的。
大数据高效存取: 对于需要管理或传输大量数据的场景,内存空间往往是不够用的,这时可以考虑使用Mmap进行高效的磁盘IO,弥补内存的不足。例如RocketMQ,MangoDB等主流中间件中都用到了Mmap技术;总之,但凡需要用磁盘空间替代内存空间的时候都可以考虑使用Mmap。
参考:高效IO解决方案-mmap给你想要的快
基于mmap+pagecache实现高性能的文件读写
接下来就可以对这个已经映射到内存里的磁盘文件进行读写操作了,比如要写入消息到CommitLog文件,你先把一个CommitLog文件通过MappedByteBuffer的map()函数映射其地址到你的虚拟内存地址。
接着就可以对这个MappedByteBuffer执行写入操作了,写入的时候他会直接进入PageCache中,然后过一段时间之后,由os的线程异步刷入磁盘中,如下图我们可以看到这个示意。
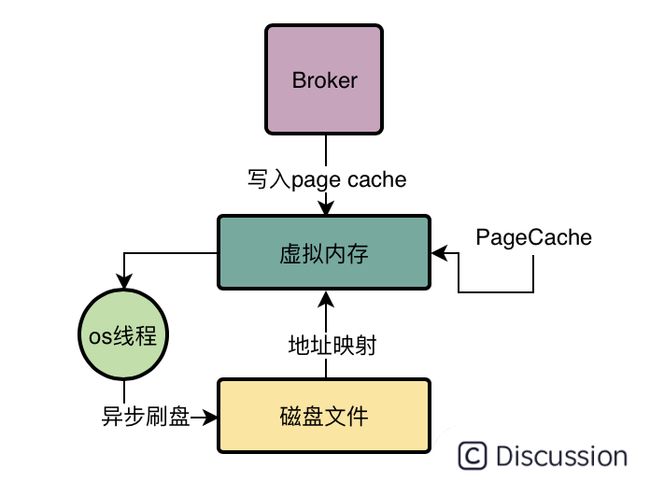
看到这里我们有没有发现什么问题?
对了!就是上面的图里,似乎只有一次数据拷贝的过程,他就是从PageCache里拷贝到磁盘文件里而已!这个就是你使用mmap技术之后,相比于传统磁盘IO的一个性能优化。
接着如果我们要从磁盘文件里读取数据呢?
那么此时就会判断一下,当前你要读取的数据是否在PageCache里?
如果在的话,就可以直接从PageCache里读取了!
比如刚写入CommitLog的数据还在PageCache里,此时你Consumer来消费肯定是从PageCache里读取数据的。
但是如果PageCache里没有你要的数据,那么此时就会从磁盘文件里加载数据到PageCache中去,如下图
而且PageCache技术在加载数据的时候,还会将你加载的数据块的临近的其他数据块也一起加载到PageCache里去。

大家可以看到,在你读取数据的时候,其实也仅仅发生了一次拷贝,而不是两次拷贝,所以这个性能相较于传统IO来说,肯定又是提高了。
3.预映射机制 + 文件预热机制
接着给大家说几个Broker针对上述的磁盘文件高性能读写机制做的一些优化:
(1)内存预映射机制:Broker会针对磁盘上的各种CommitLog、ConsumeQueue文件预先分配好MappedFile,也就是提前对一些可能接下来要读写的磁盘文件,提前使用MappedByteBuffer执行map()函数完成映射,这样后续读写文件的时候,就可以直接执行了。
(2)文件预热:在提前对一些文件完成映射之后,因为映射不会直接将数据加载到内存里来,那么后续在读取尤其是CommitLog、ConsumeQueue的时候,其实有可能会频繁的从磁盘里加载数据到内存中去。
所以在执行完map()函数之后,会进行madvise系统调用,就是提前尽可能多的把磁盘文件加载到内存里去。
通过上述优化,才真正能实现一个效果,就是写磁盘文件的时候都是进入PageCache的,保证写入高性能;
同时尽可能多的通过map + madvise的映射后预热机制,把磁盘文件里的数据尽可能多的加载到PageCache里来,后续对CosumeQueue、CommitLog进行读取的时候,才能尽可能从内存里读取数据。
4.磁盘顺序读写
磁盘如果使用得当,磁盘的速度完全可以匹配上网络的数据传输速度。目前的高性能磁盘,顺序写速度可以达到600MB/s, 超过了一般网卡的传输速度。但是磁盘随机写的速度只有大概100KB/s,和顺序写的性能相差6000倍!
因为有如此巨大的速度差别,好的消息队列系统会比普通的消息队列系统速度快多个数量级。RocketMQ的消息用顺序写,保证了消息存储的速度。