【案例】Python金融分析-CAPM模型对股票进行分析
前言
在2009年巴菲特给股东们的信中写道:
Investors should be skeptical of history-based models. Constructed by a nerdy-sounding priesthood using esoteric terms such as beta, gamma, sigma, and the like, these models tend to look impressive. Too often, though, investors forget to examine the assumptions behind the symbols.
这句话的大概意思就是:投资者应该对基于历史的模型保持怀疑态度。因为它们是由一些书呆子气似的人所定义的,用了一些所谓的β、γ、σ等符号来表示,看起来很高端。但,投资者们通常会忘记审视这些符号背后的条件和假设。
本案例名为《基于CAPM的股票风险和预期》,是我去年上金融分析+python课程的时候做的作业,选取了S&P500上的481个股票进行分析,最终得到结论:相比于模型计算的预期,XRX是表现最好的,HBI表现最差;而就企业特定风险(firm specific risk)而言,HON的风险最低,DUK的风险最高
优劣势
CAPM理所当然是基于历史得到的模型,但它也有一定的优劣势:
- 劣势:
- 并不完全准确,实际上任何模型都是这样
- 其基于的假设可能并不现实
- 优势:
- 尽管一些其他模型(如APM、多因子模型)可能比CAPM更好,但当涉及到估计未来预期回报时,它们的有效性会下降
- CAPM模型比其他模型需要更少的复杂的信息
- 对大多数公司来说,不同模型计算得到的预期回报差别不大
符号术语
在CAPM模型中用到两个符号:β和α
- β:一项潜在投资的β值是衡量该投资将为投资组合增加多少风险的指标
- α:其实全名为Jensen’s Alpha,是一个衡量投资组合所获得的超额回报与CAPM模型建议所得的回报相比的指标
股票绩效
分析股票的绩效前,首先得分别预测β和α
预估β值
β正如前所述,是一个给定股票的风险的度量。预估β值的回归公式如下
R j = a + β R m R_j =a+βR_m Rj=a+βRm
其中 R j R_j Rj是股票在历史上的回报, R m R_m Rm是市场的回报,回归后得到的直线的斜率也就是我们要预估的β值
当然,在预估前我们还需要有更细节的东西需要处理:
- 决定一个预估期间,如2011到2020这十年
- 决定一个回报间隔,如按每天、每周或每月计算我们所需的R值
- 计算股票的收益,即 R j = ( P r i c e E n d − P r i c e B e g i n n i n g + D i v i d e n d s P e r i o d ) / P r i c e B e g i n n i n g R_j = (Price_{End} - Price_{Beginning} + Dividends_{Period})/ Price_{Beginning} Rj=(PriceEnd−PriceBeginning+DividendsPeriod)/PriceBeginning,其中 P r i c e E n d Price_{End} PriceEnd和 P r i c e B e g i n n i n g Price_{Beginning} PriceBeginning为回报间隔内最终的股价和开始的股价, D i v i d e n d s P e r i o d Dividends_{Period} DividendsPeriod仅在除息月才加入计算
- 选择一个市场指数,比如道琼斯、S&P500
有了以上的步骤就能计算出我们所需的β值了
预估α值
预估α前对CAPM进行变式如下:
R j = R f + β ( R m − R f ) = R f ( 1 − β ) + β R m R_j = R_f + β (R_m - R_f) = R_f (1-β) + β R_m Rj=Rf+β(Rm−Rf)=Rf(1−β)+βRm
其中, R f R_f Rf为Risk free值,需要进行额外的计算,在后面代码部分会展示;在上式中,我们将 R f ( 1 − β ) R_f (1-β) Rf(1−β)类比为预估β值公式中的 a a a,这样一来, a − R f ( 1 − β ) a-R_f (1-β) a−Rf(1−β)就是我们需要的Jensen’s Alpha,当 a > R f ( 1 − β ) a > R_f (1-β) a>Rf(1−β),意味着股票在回归区间的表现比预期的要好
分析绩效
基于以上指标,现给出整个流程的具体计算步骤:
- 计算一只股票在5年内的每月回报率
- 计算5年估计期内S&P500指数的月回报率
- 对这些收益做线性回归
- 得到截距a和斜率β
- 比较截距a和 R f ( 1 − β ) R_f (1-β) Rf(1−β)
- 给出结论
评估
在给出结论前,当然需要进行评估,本案例中采用 R 2 R^2 R2和 1 − R 2 1-R^2 1−R2进行评估,这是在回归中能够得到的对回归的评估数值。这里回归的 R 2 R^2 R2是一个公司的风险估计比例,归因于市场风险(即外在风险);而 1 − R 2 1-R^2 1−R2是归因于企业特定风险(firm specific risk),即内在风险;当你是一个多样化的投资者,你可能倾向于在意外在风险,当你是单一化的投资者,你可能倾向于选择firm specific risk的公司进行投资
代码解读
获取数据
下载S&P500上的股票,利用alphavantage的api来获取;输入中的symbol为股票的名称,apikey需要自己去alphavantage的官网申请
def getMonthlyStockPrices(symbol, apikey):
ts = TimeSeries( key=apikey )
data, meta_data = ts.get_monthly_adjusted( symbol ) # 获取数据
symbol_df = pd.DataFrame.from_dict( data, orient = 'index' ) # 转化为DataFrame
symbol_df = symbol_df.apply(pd.to_numeric) # 数字化
symbol_df.index = pd.to_datetime( symbol_df.index ) # 换index
symbol_df.columns = [ 'open', 'high', 'low', 'close', 'adjusted_close', 'volume', 'dividend_amt'] # 给定对应列的名称
symbol_df = symbol_df.sort_index( ascending=True ) # 排序
return symbol_df
得到的数据如下
计算rick free值
tbill_data = pd.read_excel('../../General Resources/tbilldata.xlsx', skiprows=1) # skiprows=1 跳过第一行
tbill_data.index = pd.to_datetime(tbill_data['DATE']) # DATE column 转化成 index
tbill_data = tbill_data.drop('DATE', axis=1) # 再删去DATE这个column
_15_19_byYear = tbill_data.loc['2015':'2019']['BANK DISCOUNT.2'] # 获取固定区间数据
Sum = []
for year in range(2015,2020):
Sum.append((_15_19_byYear.loc[str(year)]/100).mean())
avg_annual = np.mean(Sum)
print("avg_annual", avg_annual)
Monthly_risk_free = avg_annual/12
print("Monthly_risk_free", Monthly_risk_free)
于是得到输出为
avg_annual 0.010698813575433277
Monthly_risk_free 0.0008915677979527731
计算β、α值
# 得到β值
def getInterceptSlope(stock_ret, index_ret):
model_data = pd.concat([stock_ret, index_ret], axis=1)
model_data.columns = ['stock_ret', 'index_ret']
# fit the data with ols model
results = smf.ols('stock_ret ~ index_ret', data=model_data).fit()
intercept = results.params.Intercept
slope = results.params.index_ret
rsquared = results.rsquared
return intercept, slope, rsquared
# 得到Rf(1-β)的值
def getRiskfree_1_beta(Rf, slope_name, Slopes):
return Rf*(1-Slopes[slope_name])
# 得到单个α值
def getSingleAlpha(Intercepts,Rf_1_beta):
return Intercepts-Rf_1_beta
# 得到所有alpha值
def getAlphas(stocks, index, Rf):
Intercepts = {}
Slopes = {}
rsquareds = {}
index_ret = ((index.close.diff() + index.dividend_amt.shift())/index.close.shift()).bfill()
for stock in stocks:
stock_ret = ((stocks[stock].close.diff() + stocks[stock].dividend_amt.shift())/stocks[stock].close.shift()).bfill()
I_S = getInterceptSlope(stock_ret, index_ret)
Intercepts[stock] = I_S[0]
Slopes[stock] = I_S[1]
rsquareds[stock] = I_S[2]
Rf_1_beta = {}
for slope_name in Slopes:
Rf_1_beta[slope_name] = getRiskfree_1_beta(Rf, slope_name, Slopes)
Alphas = {}
for name in Intercepts:
Alphas[name] = getSingleAlpha(Intercepts[name],Rf_1_beta[name])
return Alphas, rsquareds
Alphas, rsquareds = getAlphas(Stocks, GSPC_index, Monthly_risk_free)
得到α和 R 2 R^2 R2的最大最小值
max_alpha = -1
max_alpha_name = 0
min_alpha = 1
min_alpha_name = 0
for alpha in Alphas:
if(Alphas[alpha]>max_alpha):
max_alpha = Alphas[alpha]
max_alpha_name = alpha
if(Alphas[alpha]<min_alpha):
min_alpha = Alphas[alpha]
min_alpha_name = alpha
print("min_alpha:", min_alpha_name, ":", min_alpha, "annual excess return:", (1+min_alpha)**12-1)
print("max_alpha:", max_alpha_name, ":", max_alpha, "annual excess return:", (1+max_alpha)**12-1)
max_rsquared = -1
max_rsquared_name = 0
min_rsquared = 1
min_rsquared_name = 0
for rsquared in rsquareds:
if(rsquareds[rsquared]>max_rsquared):
max_rsquared = rsquareds[rsquared]
max_rsquared_name = rsquared
if(rsquareds[rsquared]<min_rsquared):
min_rsquared = rsquareds[rsquared]
min_rsquared_name = rsquared
print("min_rsquared:",min_rsquared_name, ":", min_rsquared)
print("max_rsquared:",max_rsquared_name, ":", max_rsquared)
得到输出为
min_alpha: HBI : -0.027197615160351105 annual excess return: -0.2817171133835983
max_alpha: XRX : 0.04446442315931073 annual excess return: 0.6854808327225679
min_rsquared: DUK : 1.5945826779772965e-05
max_rsquared: HON : 0.6987161635840791
可视化
fig1, ax = plt.subplots(2, 2, figsize=(14,14))
index_ret = (GSPC_index.close - GSPC_index.open + GSPC_index.dividend_amt)/GSPC_index.open
# stock with max_alpha
stock_ret = ((Stocks[max_alpha_name].close.diff() + Stocks[max_alpha_name].dividend_amt.shift()\
)/Stocks[max_alpha_name].close.shift()).bfill()
ISR = getInterceptSlope(stock_ret, index_ret)
ax[0,0].scatter(index_ret, stock_ret)
ax[0,0].plot(index_ret, ISR[0]+ISR[1]*index_ret, "r")
ax[0,0].title.set_text("Return on "+max_alpha_name+"={:.4f}+{:.4f}*Return on Market".format(ISR[0],ISR[1])\
+" α(max): {:.4f}".format(max_alpha))
# stock with min_alpha
stock_ret = ((Stocks[min_alpha_name].close.diff() + Stocks[min_alpha_name].dividend_amt.shift()\
)/Stocks[min_alpha_name].close.shift()).bfill()
ISR = getInterceptSlope(stock_ret, index_ret)
ax[0,1].scatter(index_ret, stock_ret)
ax[0,1].plot(index_ret, ISR[0]+ISR[1]*index_ret, "r")
ax[0,1].title.set_text("Return on "+min_alpha_name+"={:.4f}+{:.4f}*Return on Market".format(ISR[0],ISR[1])\
+" α(min): {:.4f}".format(min_alpha))
# stock with max_rsquared
stock_ret = ((Stocks[max_rsquared_name].close.diff() + Stocks[max_rsquared_name].dividend_amt.shift()\
)/Stocks[max_rsquared_name].close.shift()).bfill()
ISR = getInterceptSlope(stock_ret, index_ret)
ax[1,0].scatter(index_ret, stock_ret)
ax[1,0].plot(index_ret, ISR[0]+ISR[1]*index_ret, "r")
ax[1,0].title.set_text("Return on "+max_rsquared_name+"={:.4f}+{:.4f}*Return on Market".format(ISR[0],ISR[1])\
+" R²(max): {:.4f}".format(max_rsquared))
# stock with min_rsquared
stock_ret = ((Stocks[min_rsquared_name].close.diff() + Stocks[min_rsquared_name].dividend_amt.shift()\
)/Stocks[min_rsquared_name].close.shift()).bfill()
ISR = getInterceptSlope(stock_ret, index_ret)
ax[1,1].scatter(index_ret, stock_ret)
ax[1,1].plot(index_ret, ISR[0]+ISR[1]*index_ret, "r")
ax[1,1].title.set_text("Return on "+min_rsquared_name+"={:.4f}+{:.4f}*Return on Market".format(ISR[0],ISR[1])\
+" R²(min): {:.4f}".format(min_rsquared))
plt.show()
得到可视化如下
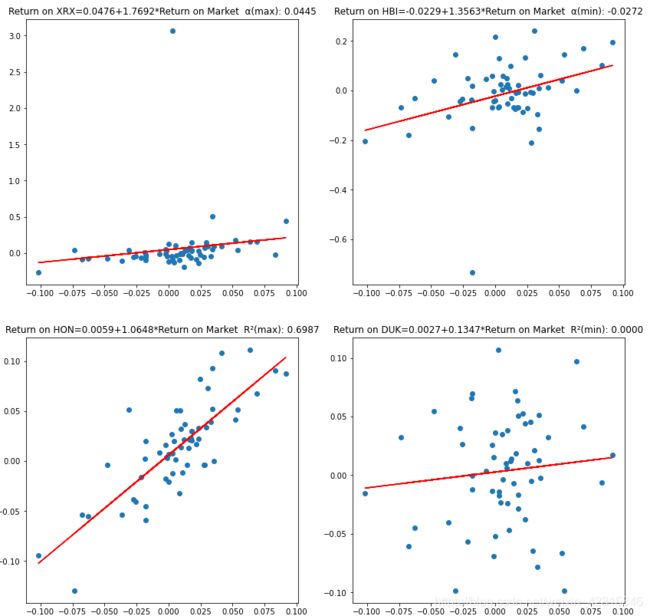
由图,最终得到结论:相比于模型计算的预期,XRX是表现最好的,HBI表现最差;而就企业特定风险而言,HON的风险最低,DUK的风险最高
源码获取
完整源码和文件见此处