全文搜索引擎solr使用说明
solr
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr是一个高性能,采用Java开发。Solr基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的搜索引擎。
Solr可以和Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。
1、安装部署
solr可以自行启动,也可以 部署到容器中,例如tomcat,将solr.war包放到与webapps同级目录下,这里不做深入说明。
1.1 下载
官网下载安装包:https://lucene.apache.org/solr/downloads.html
1.2 安装
在windows平台上,将下载的zip包(例如:solr-7.2.1.zip),直接解压的相应目录。加压后对应的目录:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9HdXBim9-1598601781469)(images/image-20200828101809727.png)]
1.3 启动
进入bin目录,打开cmd命令窗口,然后执行命令:./solr.cmd start
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DlUVN8lD-1598601781473)(images/image-20200828101339014.png)]
端口可以在solr.in.cmd文件中进行修改,也可以在启动的时候指定端口:./solr start -p 8983
停止:./solr.cmd stop -p 8983,需要指定端口
1.4 访问
通过浏览器直接访问:http://localhost:8983
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tVrLDzTo-1598601781476)(images/image-20200828101423579.png)]

2、使用
在Solr中,有个core的概念,每一个Core、代表一个索引库、里面包含索引数据及其配置信息。
Solr中可以拥有多个Core、就像mysql中可以有多个数据库一样。
2.1 创建core
创建core有两种方法,一种是通过命令行执行,另一种从solr控制台进行创建。
2.1.1.1 命令行创建
通过cmd切换到../bin目录下
执行命令:solr create -c corename,然后回车
在/server/solr下就会出现新的文件夹corename(就是新创建的core)
同时在solr管理页面的CoreAdmin菜单中,可以看到新创建的core
2.1.1.2 控制台创建
从控制台创建,有个前提条件:需要提前创建对应的目录、以及copy相应的文件。
1)、在/server/solr下创建新文件夹,名字自定义,此处命名为testSolr,作为新建的core;
2)、找到/server/solr/configsets/_default目录下的conf文件夹,然后拷贝一份到/server/solr/testSolr目录节点下。
3)、访问solr管理页面,找到CoreAdmin菜单,点击add core
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ybLRqna0-1598601781482)(images/image-20200828111337245.png)]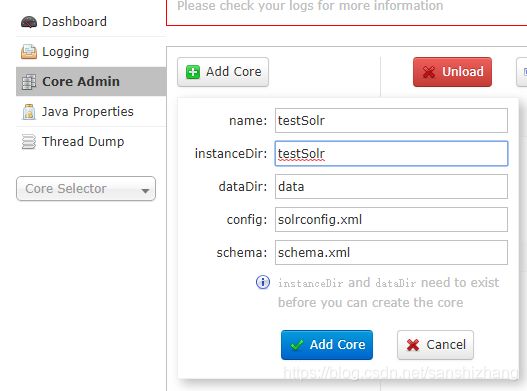
输入刚才在…/solr目录下创建的文件夹的名字,也就是需要创建的core的名字:testSolr。name和instanceDir都填写corename即可。然后点击Add Core按钮。
2.2 配置
solr允许用户从数据库中创建索引,便于用户查询。
进入对应core的conf目录下,找到data-config.xml进行配置,例如:
<dataConfig>
<dataSource name="source2" driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.61.95:3306/apartment"
user="root"
password="eyecool"
batchSize="-1"/>
<document name="lhx1">
<entity name="matchlog" pk="id" dataSource="source2" query="select id,stu_no,stu_name,apart_id,stu_sex,stu_card,in_out,match_score, match_time from ope_match_log">
<field column="id" name="id" />
<field column="stu_no" name="no" />
<field column="stu_name" name="name" />
<field column="apart_id" name="apartId" />
<field column="stu_sex" name="sex" />
<field column="stu_card" name="cardNo" />
<field column="in_out" name="inout" />
<field column="match_score" name="matchScore" />
<field column="match_time" name="matchTime" />
entity>
document>
dataConfig>
其中,dataSource配置数据库的一些信息,包括名称、驱动类、url、用户名和密码等,其他参数自行baidu。
在document中,需要配置entity、filed等信息,查询语句也在这进行配置。
2.3 查询
配置完成后,在solr控制台,选择对应的core,找到query菜单,执行query。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aQf0yllA-1598601781487)(images/image-20200828112200585.png)]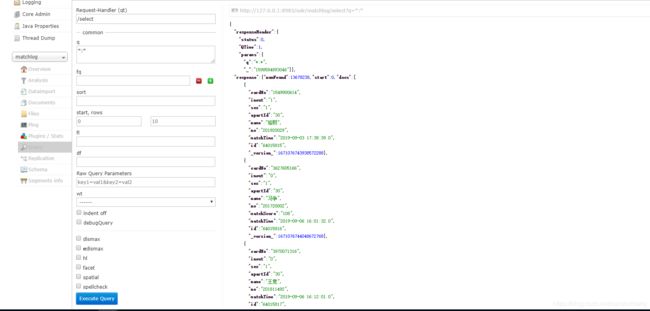
其中,q是查询条件。
2.3.1 查询语法
q 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=*:*,
fl 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort
start 返回结果的第几条记录开始,一般分页用,默认0开始
rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
sort 排序方式,例如id desc 表示按照 “id” 降序
wt (writer type)指定输出格式,有 xml, json, php等
fq (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。
df 默认的查询字段,一般默认指定。
qt (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
indent 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
2.3.2 运算符
“:” 指定字段查指定值,如返回所有值*:*
“?” 表示单个任意字符的通配
“*” 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
“~” 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。
AND、|| 布尔操作符
OR、&& 布尔操作符
NOT、!、-(排除操作符不能单独与项使用构成查询)
“+” 存在操作符,要求符号”+”后的项必须在文档相应的域中存在²
( ) 用于构成子查询
[] 包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510]
{} 不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510}
2.4 数据更新
如果数据库中的数据更新了,包括字段值更新、新增数据、删除数据,这些更新如何才能让solr知道那?
我们可以手动发送http请求,让solr进行更新:
http://localhost:8983/solr/dataimport?command=full-import; //全量重新加载
http://localhost:8983/solr/dataimport?command=delta-import&clean=false&commit=true;//增量加载没有加载过的数据
在代码中,可以创建定时任务,自己控制更新频率及更新方式。
另一种方式是下载solr-dataimportscheduler-1.1.jar包,进行配置,原理都是一样的,具体可以参考:
https://blog.csdn.net/u014017121/article/details/64453503
2.5 分词
solr默认不支持中文分词,需要下载安装第三方中文分词组件,最有名的是IKAnalyzer分词组件。
在对应的core的conf文件夹下面有两个配置文件:protwords.txt和stopwords.txt,第一个txt文件是阻止分词的内容,比如,中国,这两个字一个整体,不需要分词;第二个txt,停止词,将无功能意义的词,比如,的、得等,这些字或词需要过滤掉。
3、客户端调用
由于solr是采用java开发,自然与java无缝集成。使用前需要引入相应的jar包
<dependency>
<groupId>org.apache.solrgroupId>
<artifactId>solr-solrjartifactId>
<version>7.2.1version>
dependency>
3.1 查询
util类
package com.test.solr;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
public class SolrUtil {
/**
* 获取SolrClient
* solrj 6.5及以后版本获取方式
* @return
*/
public static HttpSolrClient getSolrClient(String url){
/*
* 设置超时时间
* .withConnectionTimeout(10000)
* .withSocketTimeout(60000)
*/
return new HttpSolrClient.Builder(url)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
}
}
使用,也可以使用SolrQuery 对象作为查询条件
package com.test.solr;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.params.MapSolrParams;
import org.apache.solr.common.params.SolrParams;
public class TestSolr {
private final static String BASE_URL = "http://127.0.0.1:8983/solr";
public static void main(String[] args) {
// TODO Auto-generated method stub
HttpSolrClient client = SolrUtil.getSolrClient(BASE_URL);
Map<String, String> param = new HashMap<String, String>();
param.put("q", "*:*");// 查询条件
param.put("start", "0");
param.put("rows", "200000");// 返回记录数
SolrParams sparam = new MapSolrParams(param);// 查询参数
try {
String corename = "matchlog";// core的名称
QueryResponse res = client.query(corename, sparam);
SolrDocumentList result = res.getResults();// 获取结果
for (SolrDocument document : result) {// 遍历返回结果
System.out.println("name==" + document.get("name") + ", student_no ==" + document.get("no"));
}
} catch (SolrServerException | IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
3.2 新增
private static void addDocument() throws Exception {
HttpSolrClient client = SolrUtil.getSolrClient(BASE_URL);
String collection = "matchlog";// 创建的core
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", 22);
doc.addField("name", "zhagnsan");
client.add(collection, doc);
UpdateResponse res = client.commit();//提交结果返回
}
支持批量提交
3.3 分词
public static List<String> getAnalysis(String sentence) {
SolrClient client = SolrUtil.getSolrClient(BASE_URL);
FieldAnalysisRequest request = new FieldAnalysisRequest("/analysis/field");
request.addFieldName("cn-name");// 字段名,随便指定一个支持中文分词的字段
request.setFieldValue("");// 字段值,可以为空字符串,但是需要显式指定此参数
request.setQuery(sentence);
FieldAnalysisResponse response = null;
try {
response = request.process(client);
} catch (Exception e) {
e.printStackTrace();
}
List<String> results = new ArrayList<String>();
Iterator<AnalysisPhase> it = response.getFieldNameAnalysis("cn-name").getQueryPhases().iterator();
while (it.hasNext()) {
AnalysisPhase pharse = (AnalysisPhase)it.next();
List<TokenInfo> list = pharse.getTokens();
for (TokenInfo info : list) {
results.add(info.getText());
}
}
return results;
}