NiFi数据流实践:Mysql CDC To HDFS/Hive
NiFi数据流实践:实时获取Mysql CDC数据,写入HDFS/Hive。
NiFi版本:1.22.0
Flowfile、Processor、Controller Service、Record等概念说明,详见NiFi官方文档:
Apache NiFi Documentation。
NiFi官方文档提供了详细的概念说明和使用说明,耐心通读一遍,就可以快速上手开发NiFi数据流。
数据流概览
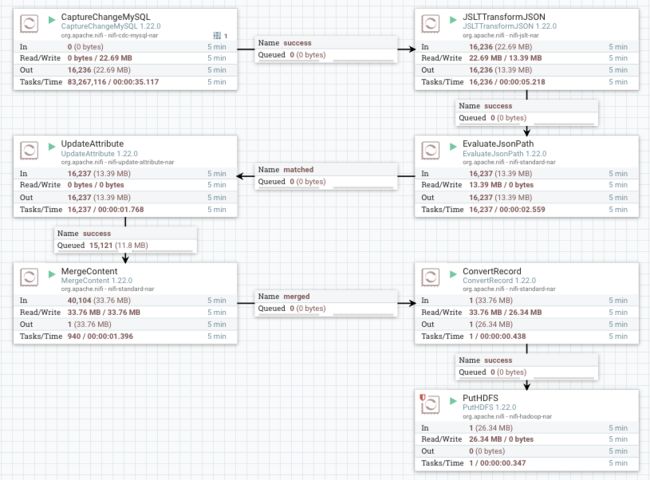
涉及到的Processors及简介:
| Processor | 简介 |
|---|---|
| CaptureChangeMySQL | 实时获取Mysql Binlog数据,输出是JSON数据 |
| JSLTTransformJSON | 转换flowfile内容中的JSON数据结构 |
| EvaluateJsonPath | 根据flowfile内容中的JSON数据,生成flowfile属性或内容。 |
| UpdateAttribute | 更新或删除flowfile属性 |
| MergeContent | 合并多个flowfile到一个flowfile |
| ConvertRecord | 转换数据格式 |
| PutHDFS | 将flowfile写入HDFS目录 |
涉及到的Controller Services及简介:
| Controller Service | 简介 |
|---|---|
| JsonTreeReader | 解析JSON数据到单独的Record对象 |
| AvroRecordSetWriter | 写Record对象数据集内容到二进制Avro格式 |
| KerberosPasswordUserService | 通过Kerberos principal和password创建Kebreos用户,提供Kerberos认证 |
Processors配置说明
下面每个Processor,未说明的Tab均使用默认值。
CaptureChangeMySQL
Scheduling Tab
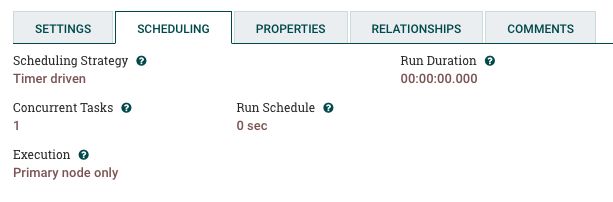
一般保持默认值即可。
注意 Run Schedule 配置,保持默认值 0 sec 即可,此时处理器会保持长期运行,符合实时数据源的需求。
如果设置成大于0的时间单位,处理器将定期启停,会出现各种各样的问题。
当设置成大于0的时间单位时,我stop之后再start,遇到的问题:
- 发现处理器不输出数据,也不报错
- 报错Mysql Binlog Server ID重复,推测是定期执行处理器,出行同时运行多个进程或线程的情况。
更多内容可参考:
https://nifi.apache.org/docs/nifi-docs/html/user-guide.html#scheduling-tab
Properties Tab
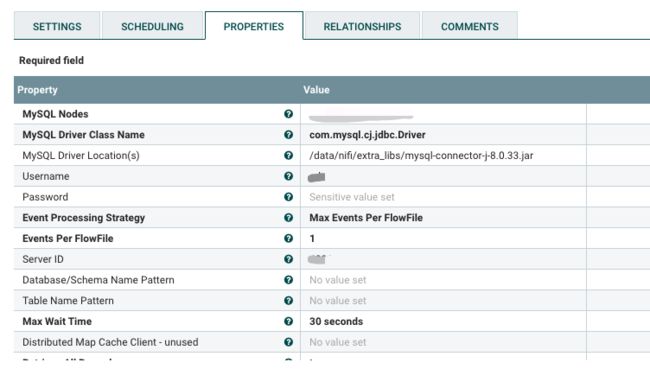
属性避坑指南:
| Property | 避坑指南 |
|---|---|
| MySQL Driver Class Name | 注意要兼容目标Mysql版本。 |
| MySQL Driver Location(s) | jdbc jar文件绝对路径。 |
| 小提示:可以在处理器配置资源文件路径的,尽量配置到处理器,灵活方便,也减少了对NiFi服务的影响。 | |
| Event Processing Strategy | 我使用的是Max Events Per FlowFile,配合 Events Per FlowFile = 1,实现每个flowfile一个cdc记录,方便后续处理。 |
| Events Per FlowFile | 我设置的是1,配合Event Processing Strategy使用。 |
| Server ID | 默认值是65535,Mysql Binlog要求每个Slave的Server ID唯一。 |
| Use Binlog GTID | 我设置了true,需要Mysql Binlog开启GTID功能,更可靠。 |
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-cdc-mysql-nar/1.22.0/org.apache.nifi.cdc.mysql.processors.CaptureChangeMySQL/index.html
JSLTTransformJSON
个人感觉 JSLTTransformJSON 比 JoltTransformJSON 更简单易用。
Properties Tab

属性避坑指南:
| Property | 避坑指南 |
|---|---|
| JSLT Transformation | 需要学习 JSLT语法。转换逻辑中可以使用flowfile属性值。 |
示例:
// JSLT Transformation配置
{
"cdc_sequence_id": ${cdc.sequence.id},
"columns": to-json({for (.columns)
.name : .value
if (is-string(.name))
}),
* : .
}
// 输入JSON,假设cdc.sequence.id=1
{
"type" : "insert",
"timestamp" : 1689237765000,
"binlog_gtidset" : "4a60a881-bad6-11ec-a01d-00163e19ca3b:1-358723163",
"database" : "test",
"table_name" : "test_table",
"table_id" : 130,
"columns" : [ {
"id" : 1,
"name" : "id",
"column_type" : -5,
"value" : 1234
}, {
"id" : 2,
"name" : "user_id",
"column_type" : 4,
"value" : 21
} ]
}
// 输出JSON,cdc_sequence_id是从flowfile属性中获取的
{
"cdc_sequence_id": 1,
"columns" : "{\"id\":1234,\"user_id\":21}",
"type" : "insert",
"timestamp" : 1689237765000,
"binlog_gtidset" : "4a60a881-bad6-11ec-a01d-00163e19ca3b:1-358723163",
"database" : "test",
"table_name" : "test_table",
"table_id" : 130
}
示例配置说明:
"cdc_sequence_id": ${cdc.sequence.id},
输出JSON结构中,key为cdc_sequence_id,value为flowfile的cdc.sequence.id属性的值。
"columns": to-json({for (.columns)
.name : .value
if (is-string(.name))
}),
输出JSON结构中,key为columns,value为输入JSON结构中columns值的转换结果。
输入JSON结果中,columns为数组,转换逻辑为:
- 遍历columns元素,将key=name的值作为key,key=value的值作为value
- key=name的值必须是字符串
- 使用to-json将结果转换为json字符串
* : .
其他输入JSON的key,value,原样写入输出JSON。
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-jslt-nar/1.22.0/org.apache.nifi.processors.jslt.JSLTTransformJSON/index.html
https://github.com/schibsted/jslt
EvaluateJsonPath
Properties Tab
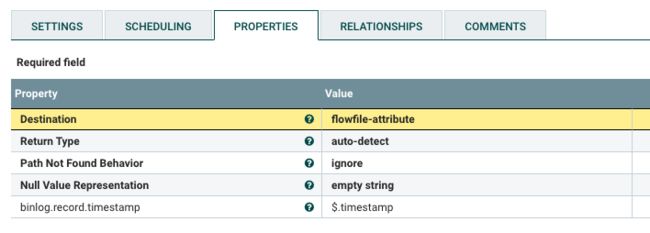
属性避坑指南:
| Property | 避坑指南 |
|---|---|
| Destination | 我只用了flowfile-attribute选项。至于使用flowfile-content修改flowfile内容,使用上面的JSLTTransformJSON或许更方便些。 |
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.22.0/org.apache.nifi.processors.standard.EvaluateJsonPath/index.html
UpdateAttribute
Properties Tab
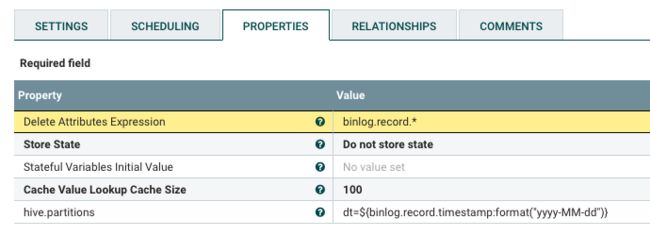
属性避坑指南:
| Property | 避坑指南 |
|---|---|
| Delete Attributes Expression | 用来删除属性,可以使用正则表达式。 |
更新属性,需要处理器处于配置状态,右上角可以点击➕,用来添加属性,可以使用NiFi Expression Language。
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-update-attribute-nar/1.22.0/org.apache.nifi.processors.attributes.UpdateAttribute/index.html
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-update-attribute-nar/1.22.0/org.apache.nifi.processors.attributes.UpdateAttribute/additionalDetails.html
https://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html
MergeContent
Properties Tab
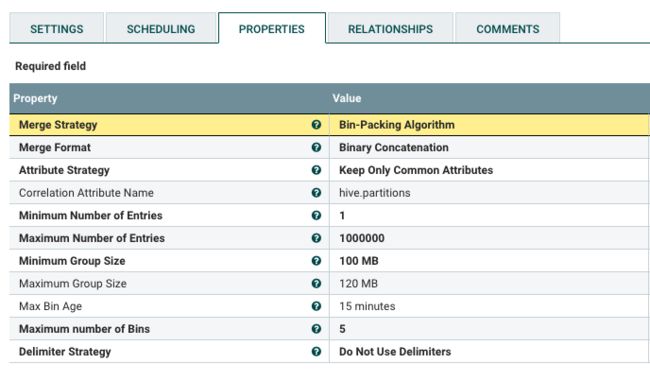
属性避坑指南:
| Property | 避坑指南 |
|---|---|
| Merge Strategy | 我是用的是Bin-Packing Algorithm,这个选项表示使用装箱算法对flowfile进行分组,相同属性的flowfile会被分到同一组中,合并进一个flowfile。 |
| Correlation Attribute Name | 指定用于控制分组的属性,该属性相同的flowfile会被分到同一组中。 |
| Minimum Number of Entries | 一个分组中最少的flowfiles数量。 |
| Maximum Number of Entries | 一个分组中最多的flowfiles数量。达到后会触发合并。 |
| Minimum Group Size | 最小的分组大小。 |
| Maximum Group Size | 最大的分组大小。达到后会触发合并。 |
| Max Bin Age | 分组最长存活时间,超时后会触发合并。 |
| Maximum number of Bins | 内存中同时存在的最大分组数量,超过这个数量时,会合并存在时间最长的分组。 |
合并机制说明:(实测观察得到的结论)
Maximum Number of Entries、Maximum Group Size、Max Bin Age和Maximum number of Bins,任何一个达到阈值,都将触发分组合并。
当以上条件都不满足时,文件数量大于Minimum Number of Entries 并且 分组大小大于Minimum Group Size时,会触发合并。
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.22.0/org.apache.nifi.processors.standard.MergeContent/index.html
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.22.0/org.apache.nifi.processors.standard.MergeContent/additionalDetails.html
ConvertRecord
Properties Tab
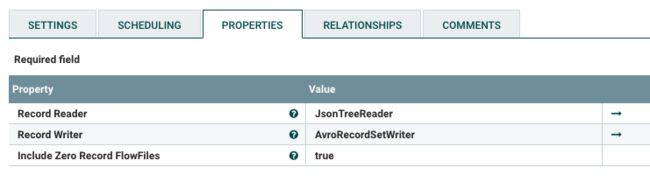
属性避坑指南:
| Property | 避坑指南 |
|---|---|
| Record Reader | 指定Record读取器,将输入数据格式转换为Record对象。 |
| Record Writer | 指定Record写入器,将Record对象转换为输出数据格式。 |
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.22.0/org.apache.nifi.processors.standard.ConvertRecord/index.html
PutHDFS
Properties Tab

属性避坑指南:
| Property | 避坑指南 |
|---|---|
| Hadoop Configuration Resources | 指定Hadoop配置资源文件,需要core-site.xml和hdfs-site.xml。示例配置:/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml |
| Kerberos User Service | 我是用这个属性进行Kerberos认证,配置了一个KerberosPasswordUserService,下文的Contrller Service会讲到这个。 |
| 也有其他属性支持Kerberos认证,可以自行研究用法。 | |
| Additional Classpath Resources | 添加额外的Classpath资源,支持目录和文件。示例配置:/opt/cloudera/parcels/GPLEXTRAS/jars |
| Directory | 要写入flowfile的HDFS目录。可以自动创建缺失的目录。 |
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-hadoop-nar/1.22.0/org.apache.nifi.processors.hadoop.PutHDFS/index.html
写入Hive的方法
主要思路:
- 创建Hive表。如果使用Hive外部表,在写入数据之后创建表也可以。
- 使用PutHDFS将数据写入Hive表在HDFS上的存储目录。如果Hive表是分区表,PutHDFS Directory属性配置的目录需要细化到最细粒度分区。
- 如果Hive表是分区表,需要使用 alter … add partition 语句添加 HDFS 目录到Hive表元数据中,这样Hive就可以读取到数据。如果Hive表不是分区表,则可以直接读取数据。
这种做法和正常写数据到Hive表没有区别,满足Hive表操作的所有特性。
示例说明:
创建Hive表:
CREATE TABLE test.test_mysql_binlog (
`binlog_gtidset` STRING,
`cdc_sequence_id` BIGINT,
`database` STRING,
`table_name` STRING,
`type` STRING,
`timestamp` BIGINT,
`columns` STRING
)
PARTITIONED BY (`dt` STRING)
STORED AS AVRO;
PutHDFS Directory 配置:
/user/hive/warehouse/test.db/test_mysql_binlog/${hive.partitions}
其中 ${hive.partitions} 是根据flowfile内容生成的flowfile属性,这样就可以实现将flowfile文件动态写入对应的分区。假设hive.partitions值为dt=2023-07-13,此时PutHDFS Directory为:
/user/hive/warehouse/test.db/test_mysql_binlog/dt=2023-07-13
假设hive.partitions值为dt=2023-07-13/database=test,此时PutHDFS Directory为:
/user/hive/warehouse/test.db/test_mysql_binlog/dt=2023-07-13/database=test
满足Hive分区格式。
当数据写入HDFS的对应的Hive分区目录,此时Hive表元数据还没有录入这个分区,可以通过如下命令添加分区:
ALTER TABLE test.test_mysql_binlog
ADD partition (dt='2023-07-13');
-- 如果分区是dt,database,需要细化到database分区层级
ALTER TABLE test.test_mysql_binlog
ADD partition (dt='2023-07-13', database='test');
-- 如果是外部表,需要指定LOCATION
ALTER TABLE test.test_mysql_binlog
ADD partition (dt='2023-07-13');
LOCATION 'hdfs://nameservice1/user/hive/warehouse/test.db/test_mysql_binlog/dt=2023-07-13;
此时Hive表就可以读到新分区的数据了。
Controller Services配置说明
JsonTreeReader
直接使用的默认配置。
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.22.0/org.apache.nifi.json.JsonTreeReader/index.html
AvroRecordSetWriter
直接使用的默认配置。
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.22.0/org.apache.nifi.avro.AvroRecordSetWriter/index.html
KerberosPasswordUserService
Properties Tab
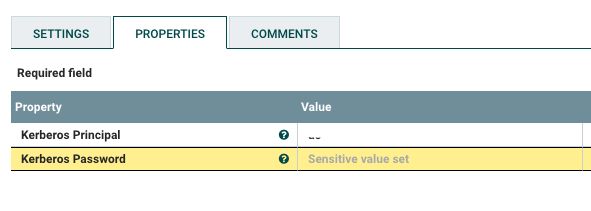
配置上 Kerberos Principal 和 Kerberos Password 即可。
参考:
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-kerberos-user-service-nar/1.22.0/org.apache.nifi.kerberos.KerberosPasswordUserService/index.html