可视化fcn-8s head的输出
"""可视化head的输出【可视化的结果是灰度图像"""
image = Image.open(imgPath).convert("RGB")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_image = transform(image).unsqueeze(0)
model = fcn_vgg16(aux=False, num_classes=21, pretrain_backbone=True)
# model.load_state_dict(torch.load("/home/hyq/hyq/projects/fcn/checkpoints/fcn_vgg_model_0.pth"), strict=False)
model.eval()
with torch.no_grad():
out = model.backbone(input_image)
layer3_out, layer4_out, layer5_out = out['layer3'],out['layer4'], out['layer5']
# 经过FCN头部结构
head_out = model.head(layer5_out)
# 将特征图转换为可视化格式
feature_map = head_out[0].detach().cpu()
# 显示原图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")
# 显示特征图
plt.subplot(1, 2, 2)
plt.imshow(feature_map[0], cmap='jet')
# plt.imshow(feature_map[0], cmap='gray')
plt.colorbar()
plt.title("Feature Map After Head")
plt.tight_layout()
plt.show()
plt.savefig('test_out_head.png')
可视化结果:
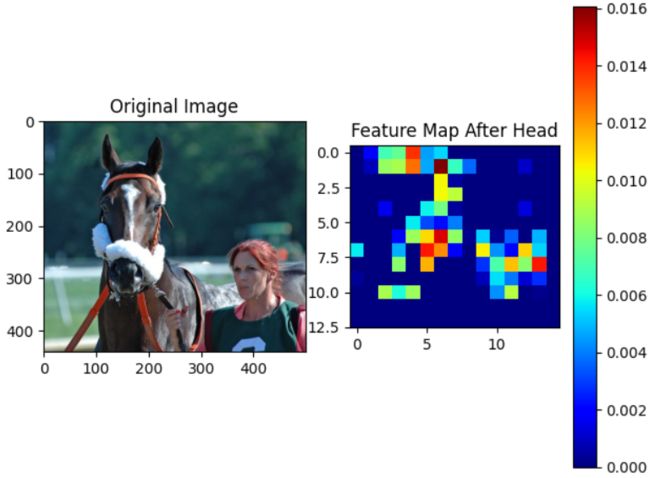
# model_fcn8s模型
from torch import nn
import torchvision
import torch
#vgg块
def vgg_block(in_channels, out_channels, num):
block = []
for _ in range(num):
block.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=1))
block.append(nn.ReLU(inplace=True))
in_channels = out_channels
block.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*block)
class VGG(nn.Module):
def __init__(self, num_classes, struct, in_channel=3):
super(VGG, self).__init__()
blk = []
out_channels = []
conv_nums = []
for conv_num, out_channel in struct:
out_channels.append(out_channel)
conv_nums.append(conv_num)
#便于后续取出某层的输出
self.layer1 = vgg_block(in_channel, out_channels[0], conv_nums[0])
self.layer2 = vgg_block(out_channels[0], out_channels[1], conv_nums[1])
self.layer3 = vgg_block(out_channels[1], out_channels[2], conv_nums[2])
self.layer4 = vgg_block(out_channels[2], out_channels[3], conv_nums[3])
self.layer5 = vgg_block(out_channels[3], out_channels[4], conv_nums[4])
# blk=[nn.Flatten(),
# nn.Linear(7*7*512,4096),
# nn.Dropout(0.5),
# nn.ReLU(),
# nn.Linear(4096,4096),
# nn.Dropout(0.5),
# nn.ReLU(),
# nn.Linear(4096,num_classes)]
# self.top = nn.Sequential(*blk)
self.__init_net()
def forward(self,x):
x = self.layer1(x)
# print(f"backbone_layer1: {type(x.shape)}")
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.top(x)
return x
def __init_net(self):
for layer in self.modules():
if type(layer) == nn.Conv2d:
nn.init.kaiming_normal_(layer.weight,mode='fan_out',nonlinearity='relu')
elif type(layer) == nn.Linear:
nn.init.xavier_normal_(layer.weight)
elif type(layer) == nn.BatchNorm2d:
nn.init.constant_(layer.weight,1) #均值为0
nn.init.constant_(layer.bias,0) #方差为1
class FCN_Head(nn.Module):
# 网络结构中的FC6和FC7
def __init__(self,in_channel,out_channel):
super(FCN_Head, self).__init__()
self.fc6 = nn.Sequential(
nn.Conv2d(in_channel,out_channel,kernel_size=7,stride=1,padding=3),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Dropout(0.1)
)
self.fc7 = nn.Sequential(
nn.Conv2d(out_channel,out_channel,kernel_size=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Dropout(0.1)
)
def forward(self,x):
x = self.fc6(x)
x = self.fc7(x)
return x
class FCN(nn.Module):
# FCN-8s
def __init__(self,backbone,head,num_classes,channel_nums):
super(FCN, self).__init__()
self.backbone = backbone
self.head = head
#调整通道数
self.layer3_conv = nn.Conv2d(channel_nums[0],num_classes,kernel_size=1) #256
self.layer4_conv = nn.Conv2d(channel_nums[1],num_classes,kernel_size=1) #512
self.layer5_conv = nn.Conv2d(channel_nums[2],num_classes,kernel_size=1) #4096
#转置卷积层1
self.transpose_conv1 =nn.Sequential(
nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(num_classes),
nn.ReLU()
)
# 转置卷积层2
self.transpose_conv2 = nn.Sequential(
nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(num_classes),
nn.ReLU()
)
# 转置卷积层3
self.transpose_conv3 = nn.Sequential(
nn.ConvTranspose2d(num_classes,num_classes,kernel_size=16,stride=8,padding=4),
nn.BatchNorm2d(num_classes),
nn.ReLU()
)
def forward(self,x):
#out = OrderedDict {layer4:{},layer5:{},layer3:{}}
out = self.backbone(x)
layer5_out, layer4_out, layer3_out = out['layer5'], out['layer4'], out['layer3']
layer5_out = self.head(layer5_out)
layer5_out = self.layer5_conv(layer5_out)
layer4_out = self.layer4_conv(layer4_out)
layer3_out = self.layer3_conv(layer3_out)
x = self.transpose_conv1(layer5_out)
x = self.transpose_conv2(x + layer4_out) # x.shape Size is ([20, 21, 96, 140])
# print(f"x.shape:{x.shape}")
x = self.transpose_conv3(x + layer3_out)
return x
def fcn_vgg16(aux, num_classes=21, pretrain_backbone=False):
# a = ["layer1.0.weight", "layer1.0.bias", "layer1.2.weight", "layer1.2.bias", "layer2.0.weight", "layer2.0.bias", "layer2.2.weight", "layer2.2.bias", "layer3.0.weight", "layer3.0.bias", "layer3.2.weight", "layer3.2.bias", "layer3.4.weight", "layer3.4.bias", "layer4.0.weight", "layer4.0.bias", "layer4.2.weight", "layer4.2.bias", "layer4.4.weight", "layer4.4.bias", "layer5.0.weight", "layer5.0.bias", "layer5.2.weight", "layer5.2.bias", "layer5.4.weight", "layer5.4.bias"]
# b = ["features.0.weight", "features.0.bias", "features.2.weight", "features.2.bias", "features.5.weight", "features.5.bias", "features.7.weight", "features.7.bias", "features.10.weight", "features.10.bias", "features.12.weight", "features.12.bias", "features.14.weight", "features.14.bias", "features.17.weight", "features.17.bias", "features.19.weight", "features.19.bias", "features.21.weight", "features.21.bias", "features.24.weight", "features.24.bias", "features.26.weight", "features.26.bias", "features.28.weight", "features.28.bias"]
#vgg16结构
struct = [(2, 64), (2, 128), (3, 256), (3, 512), (3, 512)]
backbone = VGG(num_classes=num_classes,struct=struct)
if pretrain_backbone is True:
# d = torch.load("/home/hyq/hyq/projects/fcn/vgg16-397923af.pth")
# d1 = {}
# m = dict(zip(b, a))
# for k, v in d.items():
# if k not in b:
# continue
# d1[m[k]] = v
backbone.load_state_dict(torch.load("/home/hyq/hyq/projects/fcn/vgg16-397923af.pth"), strict=False)
# backbone.load_state_dict(d1)
return_layers = {'layer3':"layer3",'layer4':'layer4','layer5':"layer5"}
backbone = torchvision.models._utils.IntermediateLayerGetter(backbone, return_layers)
# x = torch.randn((1,3,224,224))
# x = backbone(x)
head = FCN_Head(in_channel=512,out_channel=8*512)
#layer3 layer4 fcn_head输出通道数
model = FCN(backbone=backbone, head=head, num_classes=num_classes, channel_nums=[256,512,4096])
return model