深入理解netfilter和iptables
目录
Netfilter的设计与实现
内核数据包处理流
netfilter钩子
钩子触发点
NF_HOOK宏与Netfilter裁定
回调函数与优先级
iptables
内核空间模块
xt_table的初始化
ipt_do_table()
复杂度与更新延时
用户态的表,链与规则
conntrack
Netfilter(结合iptables)使应用程序能注册处理规则来使内核协议栈处理数据包,使能高效的网络转发和过滤。很多常用的主机端防火墙比如K8S的转发服务就是用iptables实现的。
很多关于netfilter的介绍性文章只是概括了主要部分,对于基础的内核实现方面涉及的不多。这篇文章就是主要针对Linux 2.6版本的内核代码,也许会和最新的5.x版本有很大的不同,但基本的设计思想不会改变并且不会影响对原理的理解。
这篇文章假设读者对TCP/IP有基本的理解。
Netfilter的设计与实现
netfilter是实现在Linux内核里的一种网络数据包处理框架。为了彻底地理解netfilter是如何工作的,我们首先要了解Linux内核里数据包处理流程。
内核数据包处理流
在内核里,数据包的处理流程可根据TCP/IP模型大体分为多层,例如内核代码链被调用来处理网路数据包,下面以IPv4的TCP数据包举例。
1、在设备物理层上,网卡通过DMA将接收到的网络数据包写入RX Ring缓存区。在一系列的中断和调度后,操作系统内核调用__skb_dequeue将数据包添加到响应设备的处理队列里,并将数据包转换成sk_buffer类型。这样数据包就能用sk_buffer表示了,最终调用netif_receive_skb功能来根据协议类型解析数据包并跳转到对应的数据包处理函数。流程以下图展示:

2、假设收到的数据包是网络层数据包,那对应的响应处理函数就是ip_rcv,也就是数据包处理进入网络层。ipv_rcv会检查IP报文头并丢弃错误包,或必要时组合分片的报文。随后ip_rcv_finish函数被执行来路由报文(决定该报文是本地接收还是转发给其他主机)。假设数据包的目的地址是本机,那么下步dst_input函数会调用ip_local_deliver函数。ip_local_deliver函数会根据IP头里的协议号决定数据包的协议类型,并最终调用对应类型的数据包处理函数。在这个例子中,对于TCP协议tcp_v4_rcv函数会被调用,这样数据包处理就进入了传输层。
3、tcp_v4_rcv函数会读取数据包的TCP头,并校验checksum值,然后再报文对应的TCP控制字段填充一些必要的状态值,包括TCP序列号和SACK值。下步调用__tcp_v4_lookup函数查询报文对应的套接字,如果找不到对应的套接字或者套接字的状态是TCP_TIME_WAIT,数据包就被丢弃。如果套接字可用,会调用tcp_prequeue函数让数据包进入prequeue队列,以便于用户态的用户程序能处理。传输层的处理流程超出了本书的范围,实际是很复杂的。
netfilter钩子
让我们继续,netfilter的主要部分就是netfilter钩子。
钩子触发点
针对不同的协议(IPv4,IPv6,或ARP等),Linux内核网络协议栈会沿着协议栈的处理路径上在预定义的节点触发对应的钩子函数。以IPv4协议举例,不同协议的处理数据流里的触发点位置和对应的钩子名字入下图所示:

这些所谓的钩子在代码中实际上是枚举类型的
enumnf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS
};每个钩子都放在了内核协议栈的特定触发点上,以下图IPv4举例。

上图中钩子的详细描述如下:
NF_INET_PRE_ROUTING:这个钩子在IPv4栈的ip_rcv函数里执行或在IPv6栈的ipv6_rcv函数里执行。对于所有进来的数据包来说,是第一个触发的钩子节点(事实上,新版本的Linux添加了INGRSS作为最早的钩子触发节点),在路由判断前执行。
NF_INET_LOCAL_IN: 这个钩子在IPv4栈的ip_local_deliver函数里执行或在IPv6栈的ip6_input函数里执行。在路由判断后,所有目的地址是本机的进来的数据包都会触发该钩子函数。
NF_INET_FORWARD:这个钩子是在IPv4栈的ip_forward函数内执行或在IPv6栈的ip6_forward函数内执行。在路由判断后,所有非本机接收的进来数据包都会触发该钩子函数。
NF_INET_LOCAL_OUT:这个钩子在IPv4栈的__ip_local_out函数内执行或在IPv6栈的__ipv6_local_out函数内执行。所有本地生成的准备发出去的数据包在进入网络协议栈后都会触发该钩子函数。
NF_INET_POST_ROUTING:这个钩子在IPv4栈的ip_output函数内执行或在IPv6栈的ip6_finish_output2函数内执行。所有本地生成的准备发出去的或者需要转发的数据包在路由判断后触发该钩子函数。
NF_HOOK宏与Netfilter裁定
宏NF_HOOK被所有的钩子触发节点调用。代码展示如下:
static inline int NF_HOOK(uint8_t pf, unsigned int hook, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int(*okfn)(struct sk_buff *))
{
return NF_HOOK_THRESH(pf, hook, skb, in, out, okfn, INT_MIN);
}NF_HOOK参数介绍如下:
- pf: 数据包的协议族, 比如IPv4为NEPROTO_IPv4
- hook: 上面展示过的netfilter钩子枚举类型,比如NF_INET_PRE_ROUTING 或 NF_INET_LOCAL_OUT
- skb: 正在处理的数据包SKB结构体
- in: 数据包的输入网络设备
- out: 数据包的输出网络设备
- okfn: 钩子将结束时会被调用的函数指针,通常为数据包处理流程里下一个处理函数。
NF_HOOK的返回值是如下所示并解释特定含义
- NF_ACCEPT: 通常继续在处理路径上(事实上是
NF-HOOK传进来的最后一个参数okfn会被执行)。- NF_DROP: 丢弃数据包并终止处理。
- NF_STOLEN: 数据包被转发并终止处理。
- NF_QUEUE: 将数据包入队列给应用程序处理。
- NF_REPEAT: 重新进行本钩子函数处理。
回到源代码,IPv4内核网络协议栈会在代码模块内调用NF_HOOK()。
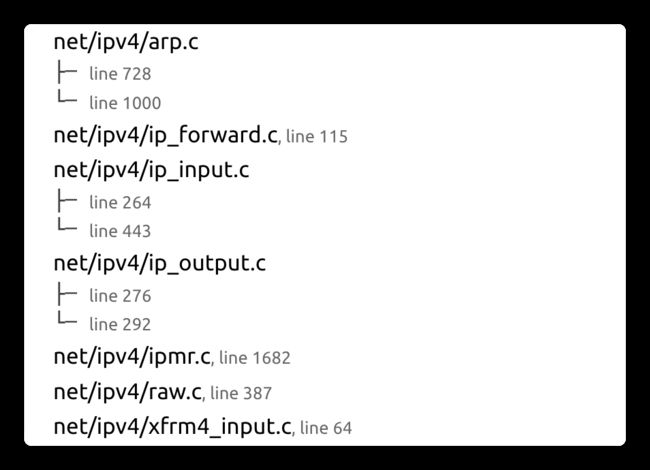
比如net/ipv4/ip_forward.c源代码内的数据包转发为例,NF_HOOK宏会在ip_forward函数的最后被调用,NF_INET_FOEWARD钩子作为NF_HOOK的输入参数,ip_forward_finish作为okfn参数输入做为下一步处理函数。
int ip_forward(struct sk_buff *skb)
{
.....
if (rt->rt_flags&RTCF_DOREDIRECT && !opt->srr && !skb_sec_path(skb))
ip_rt_send_redirect(skb);
skb->priority = rt_tos2priority(iph->tos);
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev,
rt->dst.dev, ip_forward_finish);
.....
}回调函数与优先级
netfilter的另一个组件是钩子回调函数。
内核网络协议栈使用钩子来代表指定的触发节点并用钩子(枚举值)作为索引值(NF_INET_FORWARD)来调用回调函数响应钩子节点。
内核里的其他模块可以通过netfilter提供的API向指定的钩子上注册回调函数。同一个钩子可以注册多个回调函数,并且在注册的时候能指定优先级参数priority来制定执行时按优先级来调用。
为一个钩子注册回调函数,第一步是定义nf_hook_ops结构体,示例如下:
struct nf_hook_ops {
struct list_head list;
/* User fills in from here down. */
nf_hookfn *hook;
struct module *owner;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};结构体定义里有是三种重要的成员解释如下:
- hook: 被注册的回调函数,函数的参数跟NF_HOOK参数类似,能通过okfn参数与其他函数串联在一起。
- hooknum: 被注册的钩子的枚举值
- priority: 回调函数的优先级,最小值优先。
定义了上述结构体后,一个或者多个回调函数用int nf_register_hook(struct nf_hook_ops *reg);函数或者int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n);来注册。同一个netfiler下的所有nf_hook_ops都是注册的时候按优先级顺序形成链表,所以注册程序会根据优先级在链表中找到nf_hook_ops的合适位置并做链表插入动作。
当NF_HOOK宏被执行来触发指定的钩子时,nf_iterate函数会被调用来遍历链表里的nf_hook_ops以响应该钩子,且每个带hookfn成员的nf_hook_ops都会按序执行。如下图所示:

这种回调函数按链工作的方式也是导致netfilter钩子被称为chain的原因,这种关系尤其反应在iptables的介绍章节。
每个调用函数都必须返回netfilter裁定值;如果裁定值是NF_ACCEPT,nf_iterate会继续调用下一个nf_hook_ops的回调函数知道所有的回调函数被调用完且都是NF_ACCEPT返回值。如果裁定值是NF_DROP,它机会打破传输直接返回NF_DROP;如果裁定值是NF_REPEAT,回调函数会被重新执行。nf_iterate的返回值会被NF_HOOK当做返回值使用,网络协议栈会根据该返回值决定是否继续处理。具体流程如下图所示:
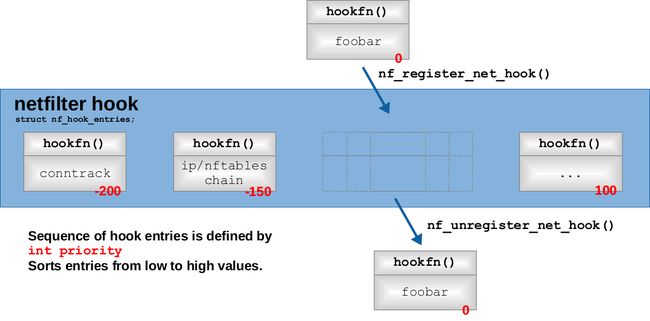
netfiler钩子的回调函数机制有以下特点:
- 回调函数会依优先级执行,且只有前面的回调函数返回NF_ACCEPT,下一步回调函数才会被执行。
- 如何一个回调函数可以中断该钩子的回调函数执行链且请求整个网络协议栈中止函数处理。
iptables
基于内核netfilter提供的钩子回调函数机制,netfilter的作者Rusty Russell也开发了iptables来管理用户规则应用到用户态的数据包。
iptbles主要分成以下两个部分:
- 用户态的ipatbels命令给用户提供了通向内核iptables模块的管理接口。
- 内核空间的ipatbles模块在内存空间上分配了规则表,能创建或注册规则表。
内核空间模块
xt_table的初始化
在内核网络协议栈,ipatbles通过xt_table结构体有条不紊地管理了大量的数据包处理规则。一个xt_table对应一个规则表,即用户空间下发的规则表。
- 作用于不同的netfilter钩子
- 在同一个钩子上不同的规则表有不同的优先级
基于规则的最终目的,ipatbels会默认初始化四个不同的规则表,名字为raw,filter,nat和mangle。下面示例了xt_table的初始化和调用过程。
过滤表的定义如下:
#define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | \
(1 << NF_INET_FORWARD) | \
(1 << NF_INET_LOCAL_OUT))
static const struct xt_table packet_filter = {
.name = "filter",
.valid_hooks = FILTER_VALID_HOOKS,
.me = THIS_MODULE,
.af = NFPROTO_IPV4,
.priority = NF_IP_PRI_FILTER,
};
/* net/ipv4/netfilter/iptable_filter.c */iptable_filter.c里的初始化函数iptable_filter_init函数会调用xt_hook_link为表packet_filter(struct xt_table类型)绑定必要的钩子函数iptable_filter_init。
struct nf_hook_ops *xt_hook_link(const struct xt_table *table, nf_hookfn *fn)
{
unsigned int hook_mask = table->valid_hooks;
uint8_t i, num_hooks = hweight32(hook_mask);
uint8_t hooknum;
struct nf_hook_ops *ops;
int ret;
ops = kmalloc(sizeof(*ops) * num_hooks, GFP_KERNEL);
if (ops == NULL)
return ERR_PTR(-ENOMEM);
for (i = 0, hooknum = 0; i < num_hooks && hook_mask != 0;
hook_mask >>= 1, ++hooknum) {
if (!(hook_mask & 1))
continue;
ops[i].hook = fn;
ops[i].owner = table->me;
ops[i].pf = table->af;
ops[i].hooknum = hooknum;
ops[i].priority = table->priority;
++i;
}
ret = nf_register_hooks(ops, num_hooks);
if (ret < 0) {
kfree(ops);
return ERR_PTR(ret);
}
return ops;
}
EXPORT_SYMBOL_GPL(xt_hook_link);
static int __init iptable_filter_init(void)
{
int ret;
ret = register_pernet_subsys(&iptable_filter_net_ops);
if (ret < 0)
return ret;
/* Register hooks */
filter_ops = xt_hook_link(&packet_filter, iptable_filter_hook);
if (IS_ERR(filter_ops)) {
ret = PTR_ERR(filter_ops);
unregister_pernet_subsys(&iptable_filter_net_ops);
}
return ret;
}
执行如下的初始化过程:
- 为xt_table作用的每个钩子遍历.valid_hooks属性,比如filter有3个钩子NF_INET_LOCAL_IN, NF_INET_FORWARD和NF_INET_LOCAL_OUT。
- 为每个钩子,按xt_table的优先级属性注册回调函数到钩子。
不同表的优先级值枚举如下所示:
enum nf_ip_hook_priorities {
NF_IP_PRI_RAW = -300,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
};当一个数据包达到钩子触发节点,所有被不同的规则表注册到该钩子的回调函数都会被有序执行,根据以上的优先级顺序执行。

ipt_do_table()
注册到filter表的钩子回调函数iptable_filter_hook会执行公共的规则检查函数ipt_do_table。ipt_do_table函数接收skb,hook和xt_table作为参数,并执行由后两个参数针对数据包选定的规则集,返回netfilter裁定值作为回调函数的返回值。
在深入规则执行前,有必要理解下内存里规则集是如何表示的。每个规则都包含三个部分
- ipt_entry结构体的next_offset成员指向下一个ipt_entry的内存偏移地址处。
- 0个或多个ipt_entry_match结构体,每个都可以动态增添额外数据。
- 一个ipt_entry_target结构体,每个都可以动态增添额外数据。
ipt_entry结构体定义如下:
struct ipt_entry {
struct ipt_ip ip;
unsigned int nfcache;
/* ipt_entry + matches 在内存中的大小*/
u_int16_t target_offset;
/* ipt_entry + matches + target 在内存中的大小 */
u_int16_t next_offset;
/* 跳转后指向前一规则 */
unsigned int comefrom;
/* 数据包计数器 */
struct xt_counters counters;
/* 长度为0数组的特殊用法,作为 match 的内存地址 */
unsigned char elems[0];
}; ipt_do_table first jumps to the corresponding ruleset memory area based on the hook type and the xt_table.private.entries property, and performs the following procedure.

- first check whether the IP initial of the packet matches the
.ipt_ipattribute of the first ruleipt_entry, if it does not match according to thenext_offsetattribute jump to the next rule.- If the IP initial matches, all
ipt_entry_matchobjects defined by the rule are checked in turn, and the match function associated with the object is called, with the result of returning to the callback function (and whether to drop the packet), jumping to the next rule, or continuing the check, depending on the return value of the call.ipt_entry_targetis read after all checks are passed, and according to its properties returns the netfilter vector to the callback function, continues to the next rule or jumps to another rule at the specified memory address. non-standardipt_entry_targetwill also call the bound function, but can only return the vector value and cannot jump to another rule.
复杂度与更新延时
The above data structure and execution provides iptables with the power to scale, allowing us to flexibly customize the matching criteria for each rule and perform different behaviors based on the results, and even stack-hop between additional rulesets.
Because each rule is of varying length, has a complex internal structure, and the same ruleset is located in contiguous memory space, iptables uses full replacement to update rules, which allows us to add/remove rules from user space with atomic operations, but non-incremental rule updates can cause serious performance problems when the rules are orders of magnitude larger: if a large If you use the iptables approach to implementing services in a large Kubernetes cluster, when the number of services is large, updating even one service will modify the iptables rule table as a whole. The full commit process is protected by kernel lock, so there is a significant update latency.
用户态的表,链与规则
用户态的iptables命令行工具可以从给定的表里读出数据显示在终端,添加新的规则(实际是替换整个规则表内容)等。
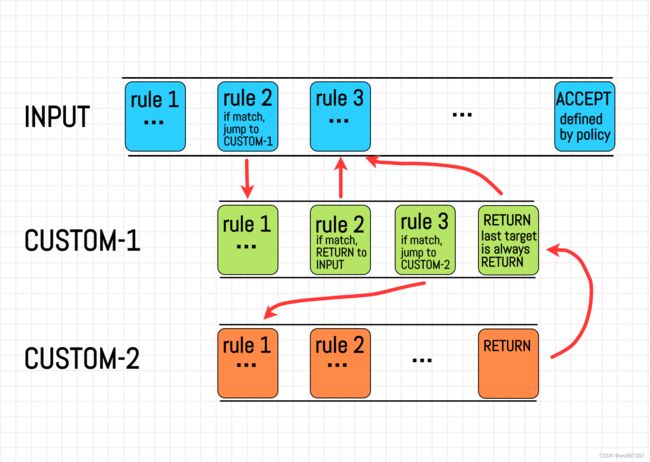
iptables主要操作如下对象:
- table: corresponds to the
xt_tablestructure in kernel space. All operations of iptable are performed on the specified table, which defaults to filter.- chain: The set of rules that the specified table calls through a specific netfilter hook, and you can also customize the rule set and jump from the hook rule set.
- rule: corresponds to
ipt_entry,ipt_entry_matchandipt_entry_targetabove, defining the rules for matching packets and the behavior to be performed after the match.- match: A highly scalable custom match rule.
- target: A highly scalable custom post-match behavior.
代码调用过程描述如下,链和规则按如下图表执行:
iptables的一些特殊用法和命令,你可以参考如下的链接:Common Firewall Rules and Commands | DigitalOcean.
conntrack
It is not enough to filter packets by the first part of the layer 3 or 4 information, sometimes it is necessary to further consider the state of the connection. netfilter performs connection tracking with another built-in module conntrack to provide more advanced network filtering functions such as filtering by connection, address translation (NAT), etc. Because of the need to determine the connection status, conntrack has a separate implementation for protocol characteristics, while the overall mechanism is the same.
I was going to continue with conntrack and NAT, but I decided against it because of its length. I will write another article explaining the principles, applications and Linux kernel implementation of conntrack when I have time.
翻译原文如下:
In-depth understanding of netfilter and iptables - SoByte