作者:hzc989
原文来源: https://tidb.net/blog/69dd056c
【是否原创】是
【首发渠道】TiDB 社区
【目录】
一、引言
二、基础前情回顾
三、era without clustered index
四、era with clustered index
五、聚簇索引使用体验
六、总结
【正文】
引言
TiDB 5.0 上新,主要围绕稳定性、可靠性开展的一个「大版本更新」,目前也比较明确——提供金融级稳定服务、提升用户体验,因此新推出的功能不多,但其中提到了一点 Introduce the clustered index feature 引人关注与思考——原来 TiDB 此前是没有支持聚簇索引的,聚簇索引这样一个作为我们在 MySQL InnoDB 引擎时代习以为常的数据结构,那么 TiDB 之前又是怎么做的呢?为什么现在又要把 clustered index 引入进来呢?我们一起来扒一扒 clustered index in TiDB 的前世今生与爱恨情愁吧
基础前情回顾
要了解 clustered index ,让我们先来回顾一些基础知识吧。如下内容我是通过 《TiDB in Action》 学习总结的,它是基于 4.0 的的最佳实践,建议 TiDB DBA 和应用开发者花一点时间认真阅读学习它哈。
TiDB ,正确来说是 TiKV ,选择使用 Key-Value 模型作为数据的存储模型,并提供有序遍历方法。两个关键点:
- 保存的数据是一个巨大的 Map,也即存储的是
Key-Value Pairs(键值对) - 这个键值对中的 key 是有序的,按照二进制顺序有序
表数据与 KV 映射关系
在 TiDB 中,数据表中的每行数据,都被映射成一个 (Key, Value) 键值对,规则如下:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
-
tablePrefix和recordPrefixSep都是特定的字符串常量,用于在 Key 空间内区分其他数据 -
TableID是 TiDB 为每个表分配的一个表 ID,目的是保证同一个表数据放在一起,方便全表扫描、范围查询等查找任务 -
RowID是表内唯一的整数,有如下两种情况- 当表有单列整数型主键时,TiDB 使用主键值来作为这一行数据的行 ID
- 如非上述情况,即没有主键/联合主键/主键非整数型,TiDB 自行分配这个行 ID
小延伸:
当 TiDB 自行分配这个 Row ID 时,TiDB 会默认使用一个自增的 Row ID ,而如果此时大量执行 INSERT 语句就会导致数据被集中写入单个 Region,造成写入 热点问题 。
此时,我们就可以通过设置 SHARD_ROW_ID_BITS ( 介绍文档 )来控制这个 Row ID 的生成,使之以分片形式产生,而不是单调递增。
索引数据与 KV 映射关系
索引数据同样被映射成一个 (Key, Value) 键值对来存储。
TiDB 同时支持主键和二级索引(包括唯一索引和非唯一索引)。按照索引是否唯一,有如下两种情况,存储规则如下:
主键或唯一索引, Key 存储的是索引信息,而 Value 则存储上述行数据中的 Row ID ,因此我们可以根据这样一个键值对结构,快速定位到对应 Row ID
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID
非唯一索引,由于索引非唯一,它可能对应多行数据。
KV 存储结构决定了 Key 在整个数据 mapping 中唯一,因此实际上我们没法完全利用到 KV 这种数据结构来分别存储索引信息和 Row ID 了。
于是就把他们都直接一起存储于 Key 空间中,而 Value 则为空,具体规则如下:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
Value: null
Era without clustered index
在我们对 TiDB 中的数据和索引与 KV 结构的存储关系等进行了 review 之后,显而易见,我们知道了在 TiDB 没有聚簇索引特性支持的时代,表的主键索引和它的行数据是「分开存储」的—— 具体来就是对应到表中每一行数据,他们都是分别存储在两个 KV 之上的。如下图是我按照自己的理解画的一个行数据与它的主键索引对应关系的极简示意图,不一定完全准确大家看得懂就行:
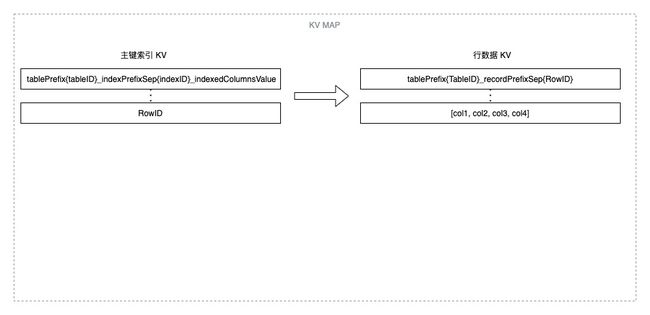
作为对比如下图是 MySQL 的索引组织表示意图,从图中可以看出主键索引跟行数据直接是存储在一起的(行数据在叶子节点),其实这也可以理解到了为什么聚簇索引在一部分 DBMS 中也叫做索引组织表。
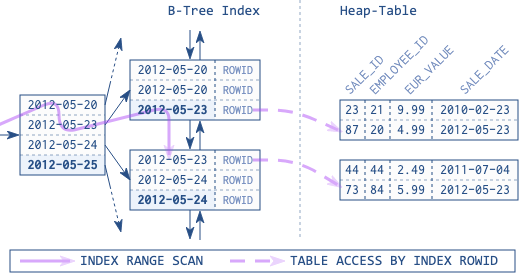
因此在没有索引组织表的情况下,会有如下场景的损耗:
- 插入数据时,需要额外同时写入索引数据
- 在仅涉及主键的数据查询时,需要先通过主键索引 KV 获得
RowID,再凭借这个RowID去拿到行数据
Era with clustered index
聚簇索引 (clustered index) 是 TiDB 从 v5.0 开始引入的特性,用于控制含有主键的表数据的存储方式。
通过使用聚簇索引,TiDB 可以更好地组织数据表,从而提高某些查询的性能。
具体而言,也就是 TiDB 把主键索引与行数据存储在同一个 KV 结构里,如下图继续给出一个极简的 KV 示意图作为与上图非聚簇索引的对比:

P.S. 由于没有找到基于 5.0 的 TiDB in action ,此图中列出的 Key 编码格式,我是照搬了 《TiDB in Action based on 4.0》 中主键和唯一索引的编码格式,并不一定准确哟~
但大家应该能通过上图,理解到 Clustered Index 这种索引组织表的好处——它省去了二次查询的步骤,Value 中直接存储了行数据,将主键和行数据「有机结合」地存在在一起了。
聚簇索引相关设置
引入了 Clustered Index ,必然会有相关的参数配置或 system variables 外放出来供用户自定义,有需要细致了解可直接查阅 用户文档
tidb_enable_clustered_index 默认设置为 INT_ONLY ,此时会受配置项 alter-primary-key (是否支持添加/删除主键,默认为 false) 控制:
-
如果该配置项取值为 true,则所有主键默认使用非聚簇索引
-
为 false,则会有两种情况
- 由单个整数类型的列构成的主键默认使用聚簇索引
- 其他类型的主键默认使用非聚簇索引
聚簇索引的优劣势
在对聚簇索引形式有一定理解后,我们可以来总结它的使用场景优劣势了,整体来说聚簇索引应该会在性能和吞吐量都有较大优势,具体而言有如下优劣势:
优势
- 插入数据时会减少一次从网络写入索引数据
- 仅涉及主键的查询,减少一次或多次从网络读取数据
劣势
- 批量插入大量取值相邻的主键时,可能会产生较大的写热点问题(比如当表结构设计的主键为自增整形值时)——但这点,其实
- 当使用大于 64 位的数据类型作为主键时,可能导致表数据需要占用更多的存储空间。该现象在存在多个二级索引时尤为明显。
聚簇索引使用体验
创建验证
此处主要是参照 官网用户文档 进行基础创建测试,按照命令指引 step by step 进行创建测试。
发现了一个 bug?
在测试过程基本符合描述中的创建成功,但也发现了一个问题:我使用的是 v5.0.2,在使用可执行的注释语法指定创建「非聚簇索引属性」时,当 column 为单列主键时,不受语法控制仍然创建出了 CLUSTERED INDEX ,具体表现如下图所示:
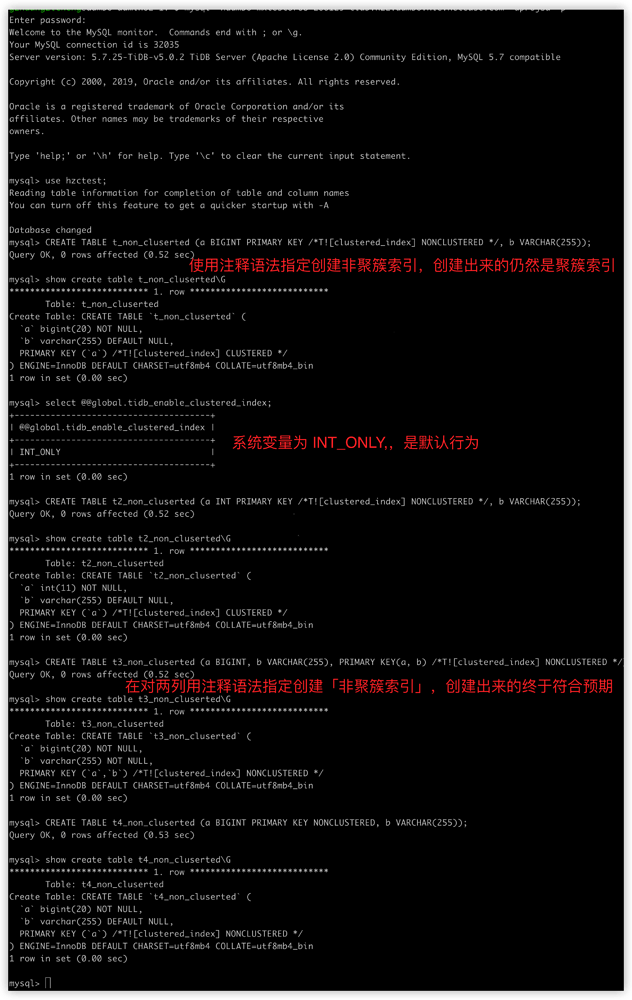
20210722 更新:经确认这个并不是一个 bug, mysql client 的问题,mysql shell 登录的时候加 --comments 可以解决,可以参考 注释语法官方文档 中注意部分的解释
在 MySQL 客户端中,TiDB 可执行注释语法会被默认当成注释被清除掉。在 MySQL 客户端 5.7.7 之前的版本中,Hint 也会被默认当成注释被清除掉。推荐在启动客户端时加上
--comments选项,例如mysql -h 127.0.0.1 -P 4000 -uroot --comments。
性能测试验证
仅涉及主键的查询
我使用了 sysbench 的 point_select 脚本进行了仅涉及主键查询的测试验证,集群配置规格与测试参数如下:
-
5.0.2 版本集群规格
- 6C/36G TiDB * 3
- 6C/60G TiKV * 3
-
测试参数
-
--time=600: 测试用时 10 分钟 -
--tables=10 --table-size=10000000:测试样例是 10 张 1 千万行的 sysbench 测试表数据 -
--threads=100:使用的并发线程数是 100
-
他们的QPS和 95% Latency 表现分别如下:
-
clustered index: 41344.37,3.07 -
non-clustered index: 35059.15,3.55
也就是说使用聚簇索引,point select 性能提升约 17.9%,Latency 下降了13.5%,测试结果表明符合预期。
同时,我也简单抓取了一个 dashboard 的 key visualizer 截图,如图所示前面部分是在插入准备数据,后面 10 分钟才是 point-select,左下角为 non-clustered index 数据库的表现,右上角则为 clustered index 的表现。可以看出来,在 point select 场景下,聚簇索引的流量图稍微更明亮一丢丢。

大批量插入数据
接下来,我使用 sysbench bulk_insert 来做一次对于插入数据的测试验证。
还是跟上面用的同一个测试集群,此次为简便测试,仅针对一张表进行测试:
总共运行 600 秒的测试数据如下(由于 95% latency 均为 0.00 ,此处采纳 avg 作为比对数据):
-
clustered index: 完成 1713 条插入 Queries,avg Latency 0.01 ms -
non-clustered index: 完成1318条插入 Queries, avg Latency 0.02 ms
同时,查看两张表的对比,使用聚簇索引表结构的 max(id) 远大于非聚簇索引的 max(id) ,如下图:
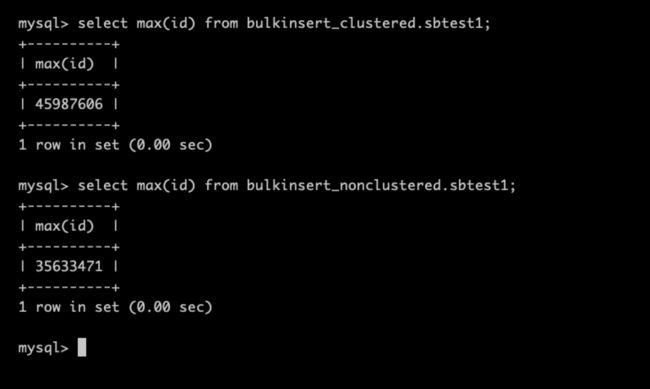
这也符合我们对于聚簇索引具有「性能和吞吐量都有较大优势」的预期。
然后是查看对比 dashboard 的流量热力图。
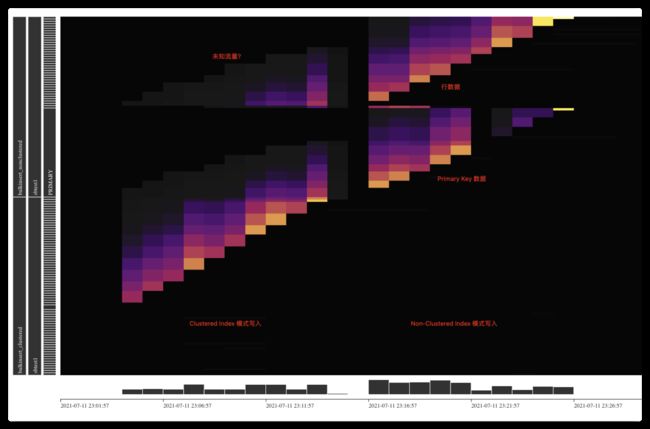
从流量图可以看出(先忽略左上角吧,我是先后进行插入测试的,分开了两个库使用的同名数据表,左上角是未知流量哈哈):
- Clustered index 模式插入时,流量图只有行数据一块热力了,但是会有比较明显的热点现象
- 而使用Non-Clustered Index 模式插入时,流量图可以看到会分成行数据流量块和 Primary key 数据流量块,同样也会有比较明显的热点现象,这是因为 sysbench 的表主键是自增整形 ID,TiDB 其实会拿它来做 RowID,依然是逃不掉热点问题,除非是将主键调整成
auto_random
小彩蛋
在进行上述测试验证时,我尝试使用 set 语法对系统变量 tidb_enable_clustered_index 进行开启或关闭操作,过程中发现一个小彩蛋——后续该系统变量将只支持 ON/OFF 的设定, INT_ONLY 将会被废弃,如下图示

如上 warning 信息,我在官方文档上没有找到任何说明和提示,莫非 INT_ONLY 只是一个过渡性选项?
回头结合配置项 alter-primary-key 的 说明文档 中的说法可能不难理解,此处说说我的个人猜想与理解:
后续 TiDB 对于是否能够增删修改主键的行为,将不再通过 alter-primary-key 配置项来控制,而是会改为通过 clustered index 相关设定来实现
-
clustered index:因为是索引组织表,不再支持修改主键 -
non-clustered index: 如有修改主键相关需求,请使用非聚簇索引
总结
TiDB 5.0 上线聚簇索引新特性,在批量插入数据和仅涉及主键查询等场景下可以为我们提升性能和吞吐。但其中的涉及到聚簇索引的系统变量和配置项设置方面,显得有点生硬或粗暴让人有些许难以理解。并且它的默认值 INT_ONLY 还使用到了一个被废弃掉(或者说是半废弃状态?)的配置项 alter-primary-key ,期待 TiDB 官方后续能够 优化相关设置用法。