目标检测常用的评价指标
目标检测常用的评价指标
- 1 IoU(Intersection over Union)
- 2 GIoU(Generalized IoU)
- 3 DIoU(Distance-IoU)
- 4 CIoU(Complete-IoU)
- 5 EIoU(Efficient-IoU)
- 6 SIoU
- 7 Wise-IoU
- 8 α-IoU
在目标检测任务中,常用到一个指标 I o U IoU IoU,即交并比,IoU可以很好的描述一个目标检测模型的好坏。在训练阶段 I o U IoU IoU 可以作为 a n c h o r − b a s e d anchor-based anchor−based 方法中,划分正负样本的依据;同时也可用作损失函数;在推理阶段, N M S NMS NMS 中会用到 I o U IoU IoU。同时 I o U IoU IoU有着比较严重的缺陷,于是出现了 G I o U GIoU GIoU、 D I o U DIoU DIoU、 C I o U CIoU CIoU、 E I o U EIoU EIoU,下面我们一起看一下这几种 I o U IoU IoU。
1 IoU(Intersection over Union)
I o U IoU IoU 的计算是用预测框 A A A 和真实框 B B B 的交集除以二者的并集,其公式为:
I o U = A ∩ B A ∪ B IoU=\frac{A\cap B}{A\cup B} IoU=A∪BA∩B
I o U IoU IoU 的值越高也说明 A A A 框与 B B B 框重合程度越高,代表模型预测越准确。反之, I o U IoU IoU 越低模型性能越差。
损失函数:
L I o u = 1 − I o U L_{Iou}=1-IoU LIou=1−IoU
优点:
- I o U IoU IoU具有尺度不变性:简单来讲就是两个框按照任意比例同时缩放,求出的IOU值不变
- 结果非负,且范围是 [ 0 , 1 ] [0, 1] [0,1]
缺点:
- 如果两个目标没有重叠, I o U IoU IoU 将会为 0 0 0,并且不会反应两个目标之间的距离,在这种无重叠目标的情况下,如果 I o U IoU IoU 用作于损失函数,梯度为 0 0 0,无法优化,且无法判断两个框之间靠的非常近还是非常远。另外,如果有多个预测框与真实框都没有交集,计算出来的 I o U IoU IoU 都为 0 0 0,损失都为 1 1 1,但是下图中明显可以看到预测框 1 1 1与真实框更加接近,损失更小才对。

- I o U IoU IoU 无法精确的反映两者的重合度大小。如下图所示,三种情况 I o U IoU IoU 都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。

2 GIoU(Generalized IoU)
为了解决 I o U IoU IoU 作为损失函数时的两个缺点,提出了 G I o U GIoU GIoU ,在 I o U IoU IoU 后面增加了一项,计算两个框的 最小外接矩形 ,用于表征两个框的距离,从而解决了两个目标没有交集时梯度为零的问题,公式为:
G I o U = I o U − C − ( A ∪ B ) C GIoU=IoU-\frac{C-(A\cup B)}{C} GIoU=IoU−CC−(A∪B)
其中 C 是两个框的最小外接矩形的面积
当 I o U = 0 IoU=0 IoU=0 时:
G I o U = − 1 + A ∪ B C GIoU=-1+\frac{A\cup B}{C} GIoU=−1+CA∪B

损失函数:
L G I o u = 1 − G I o U L_{GIou}=1-GIoU LGIou=1−GIoU
取两种极端情况: A A A、 B B B 重合以及 A A A、 B B B 不相交且 C C C 为无穷大, G I o U GIoU GIoU 的取值范围为 [ − 1 , 1 ] [-1,1] [−1,1]。 L G I o u L_{GIou} LGIou的取值范围为 [ 0 , 2 ] [0,2] [0,2]
当 A A A、 B B B 两框不相交时, A ∪ B A\cup B A∪B 不变,最大化 G I o U GIoU GIoU 就是最小化 C C C,这样就会促使两个框不断靠近。
优点:
- 当 I o U = 0 IoU=0 IoU=0 时,仍然可以很好的表示两个框的距离。
- G I o U GIoU GIoU 不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
缺点:
- 虽然 G I o U GIoU GIoU 可以缓解重叠情况下的梯度消失问题,但它仍有一些局限性,当两个框属于包含关系时, G I o U GIoU GIoU会退化成 I o U IoU IoU,无法区分其相对位置关系,无法衡量有包含关系时的框回归损失,如下图,三个回归框具有相同的 G I o U GIoU GIoU,但是显然第二个框的回归效果更好。

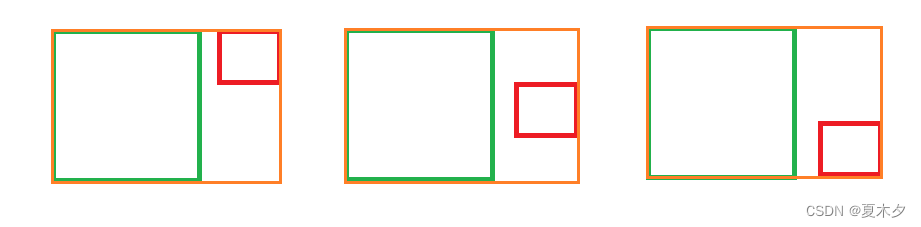
- 由于 G I o U GIoU GIoU 仍然严重依赖 I o U IoU IoU,因此在两个垂直方向(上、下),误差很大,很难收敛。两个框在相同距离的情况下,水平垂直方向时,此部分面积 C C C 最小,对 l o s s loss loss 的贡献也就越小,从而导致在垂直水平方向上回归效果较差。 如下图,三种情况下 G I o U GIoU GIoU 的值一样, G I o U GIoU GIoU 将很难区分这种情况。
3 DIoU(Distance-IoU)
针对上述 G I o U GIoU GIoU 的两个问题,将 G I o U GIoU GIoU 中最小外接框来最大化重叠面积的惩罚项修改成最小化两个 B B o x BBox BBox 中心点的标准化距离从而加速损失的收敛过程,这就诞生了 D I o U DIoU DIoU。
D I o U DIoU DIoU 要比 G I o U GIoU GIoU 更加符合目标框回归的机制,将目标与预测之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像 I o U IoU IoU 和 G I o U GIoU GIoU 一样出现训练过程中发散等问题。
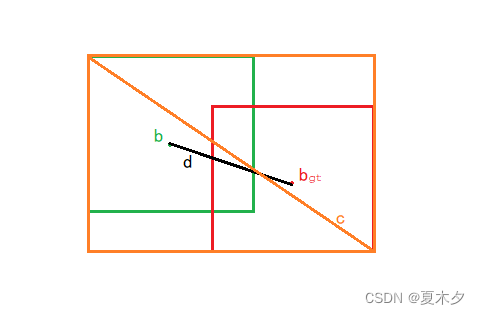
D I o U = I o U − ρ 2 ( b , b g t ) c 2 DIoU=IoU-\frac{\rho^{2}\left(b, b^{gt}\right)}{c^{2}} DIoU=IoU−c2ρ2(b,bgt)
其中 b b b、 b g t b^{gt} bgt分别代表了预测框、真实框的中心点,且 ρ \rho ρ 代表的是计算两个中心点间的欧式距离, c c c 代表的事能够同时包含预测框和真实框的最小外接矩形的对角线长度。
损失函数:
L D I o u = 1 − D I o U L_{DIou}=1-DIoU LDIou=1−DIoU
优点:
- D I o U l o s s DIoU loss DIoUloss 可以直接最小化两个目标框的距离,因此比 G I o U l o s s GIoU loss GIoUloss 收敛(减小并趋于稳定)快得多。
- 对于包含两个框在水平方向和垂直方向上这种情况, D I o U DIoU DIoU 损失可以使回归非常快。
- D I o U DIoU DIoU 还可以替换普通的 I o U IoU IoU 评价策略,应用于 N M S NMS NMS 中,使得 N M S NMS NMS 得到的结果更加合理和有效。
缺点:
- 虽然 D I o U DIoU DIoU 能够直接最小化预测框和真实框的中心点距离加速收敛,但是 B o u n d i n g b o x Bounding box Boundingbox 的回归还有一个重要的因素 纵横比 暂未考虑。如下图,三个红框的面积相同,但是长宽比不一样,红框与绿框中心点重合,这时三种情况的 D I o U DIoU DIoU 相同,证明 D I o U DIoU DIoU 不能很好的区分这种情况。

4 CIoU(Complete-IoU)
C I o U CIoU CIoU 与 D I o U DIoU DIoU 出自同一篇论文, C I o U CIoU CIoU 大多数用于训练。 D I o U DIoU DIoU 的作者考虑到,在两个框中心点重合时, c c c 与 d d d 的值都不变。所以此时需要引入框的宽高比:
C I o U = I o U − ( ρ 2 ( b , b g t ) c 2 + α v ) CIoU=IoU-\left(\frac{\rho^{2}\left(b, b^{g t}\right)}{c^{2}}+\alpha v\right) CIoU=IoU−(c2ρ2(b,bgt)+αv)
其中 α \alpha α 是权重参数, v v v 用来度量宽高比的一致性:
α = v ( 1 − I o U ) + V \alpha =\frac{v}{(1-IoU)+V} α=(1−IoU)+Vv
V = 4 π 2 ( arctan w g t h g t − arctan w h ) 2 V=\frac{4}{\pi^2 } (\arctan\frac{w_{gt}}{h_{gt}} -\arctan \frac{w}{h})^2 V=π24(arctanhgtwgt−arctanhw)2
损失函数:
L C I o u = 1 − C I o U L_{CIou}=1-CIoU LCIou=1−CIoU
优点:
- 考虑了框的纵横比,可以解决 D I o U DIoU DIoU 的问题。
缺点:
- 通过 C I o U CIoU CIoU 公式中的 v v v 反映的纵横比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化相似性。
5 EIoU(Efficient-IoU)
为了解决 C I o U CIoU CIoU 的问题,有学者在 C I o U CIoU CIoU 的基础上将纵横比拆开,提出了 E I O U L o s s EIOU Loss EIOULoss,并且加入 F o c a l Focal Focal 聚焦优质的预测框,与 C I o U CIoU CIoU 相似的, E I o U EIoU EIoU 是损失函数的解决方案,只用于训练。
E I O U EIOU EIOU 的惩罚项是在 C I O U CIOU CIOU 的惩罚项基础上将纵横比的影响因子拆开分别计算目标框和预测框的长和宽,该损失函数包含三个部分:重叠损失,中心距离损失,宽高损失,前两部分延续 C I o U CIoU CIoU 中的方法,但是宽高损失直接使目标框与预测框的宽度和高度之差最小,使得收敛速度更快。
惩罚项公式如下:
L E I o U = L I o U + L d i c + L a s p = 1 − I o U + ρ 2 ( b , b g t ) c w 2 + c h 2 + ρ 2 ( w , w g t ) c w 2 + ρ 2 ( h , h g t ) c h 2 \begin{align} L_{EIoU} & = L_{IoU}+L_{dic}+L_{asp} \\ & = 1-IoU+\frac{\rho ^2(b,b^{gt})}{c_w^2+c_h^2} +\frac{\rho ^2(w,w^{gt})}{c_w^2}+\frac{\rho ^2(h,h^{gt})}{c_h^2} \end{align} LEIoU=LIoU+Ldic+Lasp=1−IoU+cw2+ch2ρ2(b,bgt)+cw2ρ2(w,wgt)+ch2ρ2(h,hgt)
其中 c w c_w cw、 c h c_h ch 是覆盖两个 B o x Box Box 的最小外接框的宽度和高度
通过整合 E I o U EIoU EIoU l o s s loss loss 和 F o c a l Focal Focal L 1 L1 L1 l o s s loss loss ,最终得到了最终的 F o c a l − E I o U l o s s Focal-EIoU loss Focal−EIoUloss,其中 γ \gamma γ 是一个用于控制曲线弧度的超参
L F o c a l − E I o U = I o U γ L E I o U L_{Focal-EIoU}=IoU^\gamma L_{EIoU} LFocal−EIoU=IoUγLEIoU
优点:
- 将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,加速了收敛提高了回归精度。
- 引入了 F o c a l L o s s Focal Loss FocalLoss 优化了边界框回归任务中的样本不平衡问题,即减少与目标框重叠较少的大量锚框对 B B o x BBox BBox 回归的优化贡献,使回归过程专注于高质量锚框。
总结 \mathbf{ {\color{Red} 总结}} 总结
