分布式日志采集(elk+kafka)
目的
分布式系统的日志,每个服务器节点web服务都会产生各自的日志文件,如果想要整合或者排查日志,就需要到每个节点下逐一查看日志文件这样会比较麻烦。所以需要一个方案将日志采集放到一个位置进行存储和查询。 这里就可以使用elk+kafka的方式解决。
elk(elasticsearch、logstash、kibana)的首字母缩写。elasticsearch用来存储采集的日志数据,logstash负责采集日志,kibana作为es的可视化分析查询工具。
原理
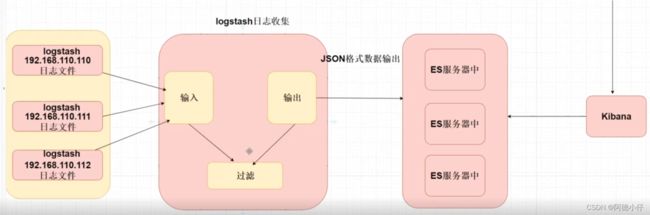
eIk 采集日志的原理:
1.需要在每个服务器上安装 logstash
2.logstash需要配置固定读取某个日志文件
3.logstash将我们的日志文件格式化为json 的格式输出到es 中
4.开发者使用kibana连接到es中查询存储日志内容
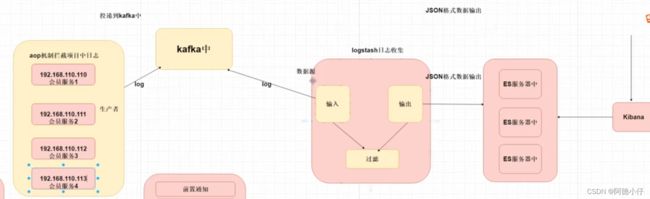
elk+kafka 原理:
1.springboot 项目会基于 aop 的方式拦截系统中日志
日志(错误日志)
错误日志:异常通知
请求与响应日志信息---前置或者环绕通知。
2.将该日志投递到我们 kafka 中注意该过程一定要是异步的形式
3.Logstash 数据源---kafka 订阅 kafka 的主题获取日志消息内容
4.在将日志消息内容输出到es 中存放
5.开发者使用Kibana 连接到 ElasticSeach 查询存储日志内容
elk+kafka的环境搭建
elaticsearch和kibana的安装使用的docker,也可以自己下载安装包进行安装
elaticsearch
安装elasticsearch
1.下载 ES 镜像问题
docker pull elasticsearch
2.运行ESdocker run -it --name elasticsearch -d -p 9200:9200 -p 9300:9300 -p 5601:5601 elasticsearch
3. 测试运行结果
http://192.168.163.129:9200/

如果出现以下报错就是创建的es容器有冲突,需要删除已有的es容器或者镜像重命名

logstash
Logstash 是一个开源数据收集引擎,具有实时管道功能。Logstash 可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Logstash 输入数据源:、本地文件、Kafka、Redis、mysql
Logstash 输出数据源:Es、Mongdb、Redis、Mysql
安装步骤:
1.上传 logstash-6.4.3.tar.gz 到服务中
2.tar -zxvf logstash-6.4.3.tar.gz
3.cd logstash-6.4.3
4.bin/logstash-plugin install logstash-input-kafka
5.bin/logstash-plugin install logstash-output-elasticsearch
配置文件mylog.conf:

启动:

kibana
docker run -it -d -e ELASTICSEARCH URL=http://127.0.0.1:9200 --name kibana --network=container:elasticsearch kibana
测试运行结果
http://192.168.163.129:5601/app/kibana#
kafka
这里我们用window版本的,如果是在Linux环境。可以自行了解安装
kafka依赖zookeeper,所以需要先装zk:


演示代码
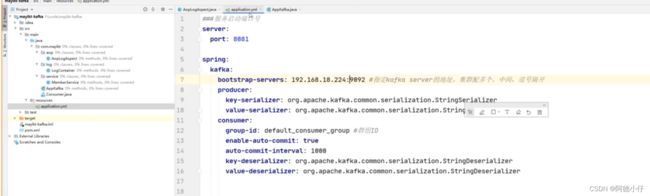
演示使用springboot框架,aop前置通知采集请求信息入kafka

kafka的spring-boot配置信息:
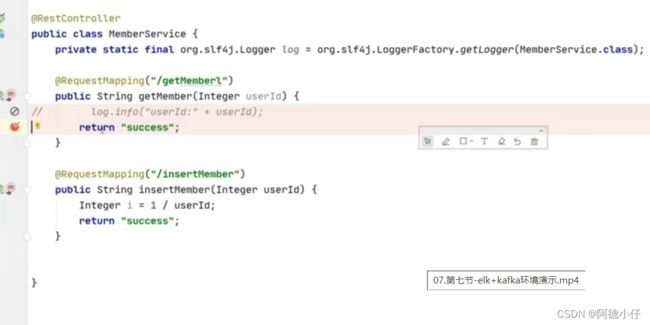
浏览器访问:127.0.0.1:8881/项目名称/getMeberl,aop前置通知会把请求信息封装投递给kafka,logstash从kafka里自动拿到数据存入到es中,使用kibana查看存储的数据,如图:
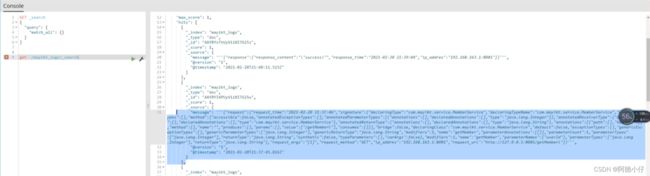
复制出来放到格式化工具里

为什么要使用es存储日志
es是一种搜索服务器,底层是基于Lucene,支持倒排索引,做搜索的效率是特别高的。基于业务需要还是可以考虑选择Mongdb、Redis、Mysql。后面会更新一篇flume采集入hdfs做大数据存储、分析、统计
为什么elk要结合kafka
1.如果单纯的使用 elk 的话,服务器节点扩容 需要每个服务器上安装我们Logstash步骤比较冗余
2.Logstash 读取本地日志文件,可能会对本地的磁盘 io 性能会有一定影响。
优化
图中可以看出请求触发aop,前置通知中往kafka里send消息,如果kafka出现异常、网络抖动都会影响主流程的一个请求响应效率和是否出异常的问题。所以需要把数据放到内存队列中,然后开一个线程,在另一个线程里循环从内存队列里取数据入kafka这样不会影响请求的正常执行业务和响应。