02.分布式日志采集ELK+Kafka
课程标题:<基于ELK+Kafka构建分布式日志采集系统>
1.传统日志采集存在哪些缺点
2.elk+kafka日志采集的原理
3.基于docker compose 安装elk+kafka环境
4.基于AOP+并发队列实现日志的采集
20点25分准时开始
分布式日志采集产生背景
在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下。
因此我们需要集中化的管理日志,ELK则应运而生。
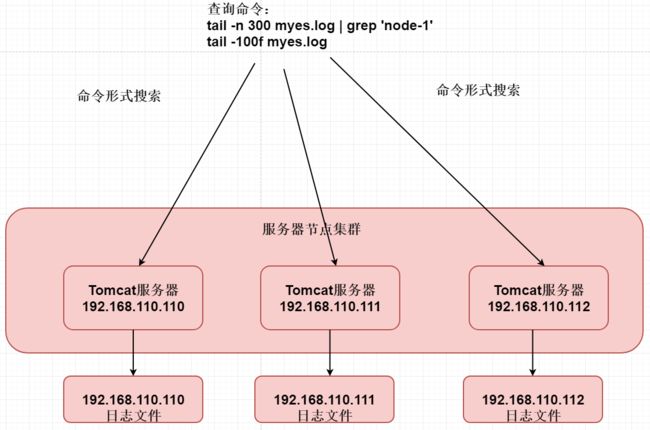
传统方式服务器搜索日志命令:tail -200f 日志文件名称
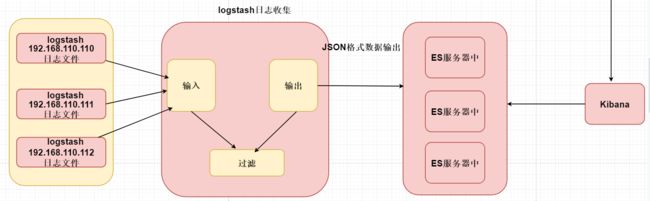
ELK+Kafka组成
Elk E= ElasticSeach(存储日志信息)
l Logstash(搬运工)
K Kibana连接到我们ElasticSeach图形化界面查询日志
Elk+kafka实现分布式日志采集
为什么需要将日志存储在ElasticSeach 而不是MySQL中呢
ElasticSeach 底层使用到倒排索引存储数据 ,在 搜索日志效率比mysql要高的。
elk+kafka原理
\1. springboot项目会基于aop的方式拦截系统中日志
请求与响应日志信息—前置或者环绕通知;
\2. 将该日志投递到我们kafka中 注意该过程一定要是异步的形式,如果是同步形式会影响到整体
接口的响应速度。
\3. Logstash 数据源—kafka 订阅kafka的主题 获取日志消息内容
\4. Logstash 在将日志消息内容输出到es中存放
5.开发者使用Kibana连接到ElasticSeach 查询存储日志内容。
为什么ELK需要结合Kafka
如果只整合elk 不结合kafka这样的话 每个服务器节点上都会安装Logstash做读写日志IO操作,可能性能不是很好,而且比较冗余。
ELK+Kafka环境构建
docker compose构建ELK+Kafka环境
整个环境采用 docker compose 来实现构建
注意:环境 cpu 多核 内存 4GB以上
kafka环境的安装:
1.使用docker compose 安装 kafka
对docker compose 不熟悉可以查看:http://www.mayikt.com/front/couinfo/301/0#
docker compose 安装包 https://note.youdao.com/ynoteshare1/index.html?id=b72a076dc75471fb86deba42924a0a3d&type=note
docker 相关学习文档:http://note.youdao.com/noteshare?id=e99e3eba0355e7c9905d0395d20b9f27&sub=962FA9CD33974C77A948376958D4B3DD
\2. docker compose文件
\3. mkdir dockerkakfa
4.cd dockerkakfa
5.创建docker-compose.yml
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
restart: always
kafka:
image: wurstmeister/kafka:2.12-2.3.0
ports:
- "9092:9092"
environment:
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.75.129:9092
- KAFKA_LISTENERS=PLAINTEXT://:9092
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
kafka-manager:
image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面
environment:
ZK_HOSTS: 192.168.75.129 ## 修改:宿主机IP
ports:
- "9001:9000" ## 暴露端口
elasticsearch:
image: daocloud.io/library/elasticsearch:6.5.4
restart: always
container_name: elasticsearch
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- 9200:9200
kibana:
image: daocloud.io/library/kibana:6.5.4
restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- elasticsearch_url=http://192.168.75.129:9200
depends_on:
- elasticsearch
docker run zookeeper容器
docker run kafka容器
docker run kafka容器ElasticSeach
docker run Kibana容器
docker run Logstash容器
使用容器编排技术
6.关闭防火墙
systemctl stop firewalld
service iptables stop
7.docker-compose up 执行即可。

没有这个命令 需要先安装docker-compose
注意:构建elk+kafka环境过程中,需要非常多的依赖镜像。

如果es启动报错: 无法启动大多数内存不足的原因
建议虚拟机内存4G以上
es 启动报错:max virtual memory areas vm.max_count(65530) is too
解决步骤:
1.先切换到root用户;
2.执行命令:
sysctl -w vm.max_map_count=262144
可以查看结果:
sysctl -a|grep vm.max_map_count
会显示如下信息:
vm.max_map_count = 262144
注意:
上述方法修改之后,如果重启虚拟机将失效,所以:
一劳永逸的解决办法:
在/etc/sysctl.conf文件的最后添加一行代码:
vm.max_map_count=262144
即可永久修改。
验证elk+kafka 环境
docker ps

访问:zk 192.168.75.143:2181
访问:es http://192.168.75.143:9200/
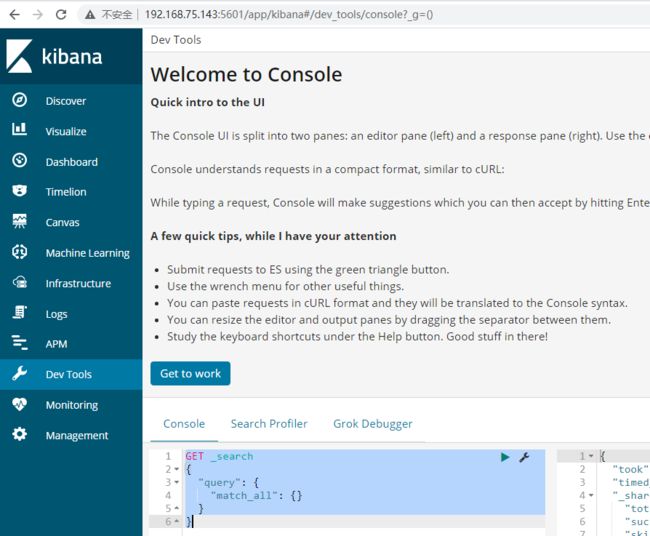
访问:kibana http://192.168.75.143:5601/app/kibana#/dev_tools/console?_g=()


安装 logstash
上传logstash-6.4.3.tar.gz到服务中
tar zxvf logstash-6.4.3.tar.gz
cd logstash-6.4.3
bin/logstash-plugin install logstash-input-kafka
bin/logstash-plugin install logstash-output-elasticsearch
注意:安装
bin/logstash-plugin install logstash-input-kafka
bin/logstash-plugin install logstash-output-elasticsearch
本机电脑需要有JDK的环境,如果没有JDK环境直接安装 logstash-input-kafka 或者logstash-output-elasticsearch会报错的


创建 在 logstash config 目录 创建 kafka.conf
input {
kafka {
bootstrap_servers => "192.168.75.143:9092"
topics => "mayikt-log"
}
}
filter {
#Only matched data are send to output.
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "192.168.75.143:9200" #ElasticSearch host, can be array.
index => "my_logs" #The index to write data to.
}
}
进入logstash bin 目录 执行 ./logstash -f …/config/kafka.conf
springboot项目整合elk+kafka
maven依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.66</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
aop拦截系统日志
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import javax.servlet.http.HttpServletRequest;
import com.alibaba.fastjson.JSONObject;
import com.mayikt.container.LogContainer;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
@Aspect
@Component
public class AopLogAspect {
@Value("${server.port}")
private String serverPort;
// 申明一个切点 里面是 execution表达式
@Pointcut("execution(* com.mayikt.api.service.*.*(..))")
private void serviceAspect() {
}
//
@Autowired
private LogContainer logContainer;
//
// 请求method前打印内容
@Before(value = "serviceAspect()")
public void methodBefore(JoinPoint joinPoint) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
JSONObject jsonObject = new JSONObject();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("request_url", request.getRequestURL().toString());
jsonObject.put("request_method", request.getMethod());
jsonObject.put("signature", joinPoint.getSignature());
jsonObject.put("request_args", Arrays.toString(joinPoint.getArgs()));
// IP地址信息
jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
JSONObject requestJsonObject = new JSONObject();
requestJsonObject.put("request", jsonObject);
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("log_type", "info");
// 将日志信息投递到kafka中
String log = requestJsonObject.toJSONString();
// ListenableFuture> send = kafkaTemplate.send("mayikt-log",ctx);
logContainer.addLog(log);
}
//
// // 在方法执行完结后打印返回内容
// @AfterReturning(returning = "o", pointcut = "serviceAspect()")
// public void methodAfterReturing(Object o) {
// ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
// .getRequestAttributes();
// HttpServletRequest request = requestAttributes.getRequest();
// JSONObject respJSONObject = new JSONObject();
// JSONObject jsonObject = new JSONObject();
// SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
// jsonObject.put("response_time", df.format(new Date()));
// jsonObject.put("response_content", JSONObject.toJSONString(o));
// // IP地址信息
// jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
// jsonObject.put("log_type", "info");
// respJSONObject.put("response", jsonObject);
// // 将日志信息投递到kafka中
kafkaTemplate.send("mayikt-log",respJSONObject.toJSONString());
logContainer.put(respJSONObject.toJSONString());
// }
//
//
/**
* 异常通知
*
* @param point
*/
@AfterThrowing(pointcut = "serviceAspect()", throwing = "e")
public void serviceAspect(JoinPoint point, Exception e) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
JSONObject jsonObject = new JSONObject();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("request_url", request.getRequestURL().toString());
jsonObject.put("request_method", request.getMethod());
jsonObject.put("signature", point.getSignature());
jsonObject.put("request_args", Arrays.toString(point.getArgs()));
jsonObject.put("error", e.toString());
// IP地址信息
jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
jsonObject.put("log_type", "info");
JSONObject requestJsonObject = new JSONObject();
requestJsonObject.put("request", jsonObject);
// 将日志信息投递到kafka中
String log = requestJsonObject.toJSONString();
logContainer.addLog(log);
}
//
public static String getIpAddr(HttpServletRequest request) {
//X-Forwarded-For(XFF)是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。
String ipAddress = request.getHeader("x-forwarded-for");
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("WL-Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getRemoteAddr();
if (ipAddress.equals("127.0.0.1") || ipAddress.equals("0:0:0:0:0:0:0:1")) {
//根据网卡取本机配置的IP
InetAddress inet = null;
try {
inet = InetAddress.getLocalHost();
} catch (UnknownHostException e) {
e.printStackTrace();
}
ipAddress = inet.getHostAddress();
}
}
//对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (ipAddress != null && ipAddress.length() > 15) { //"***.***.***.***".length() = 15
if (ipAddress.indexOf(",") > 0) {
ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
}
}
return ipAddress;
}
}
配置文件内容
spring:
application:
###服务的名称
name: mayikt-elkkafka
jackson:
date-format: yyyy-MM-dd HH:mm:ss
kafka:
bootstrap-servers: 192.168.75.143:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default_consumer_group #群组ID
enable-auto-commit: true
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
server:
port: 9000
