MySql数据库的学习
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
参考博客:MySQL 教程 | 菜鸟教程 (runoob.com)
一、什么是数据库?
数据库(Database,DB)是按照数据结构来组织、存储和管理数据的仓库。它本身可以看作是一个电子化的文件柜,用户可以对文件中的数据进行增加、删除、修改、查找等操作。数据库通常以电子形式存储在计算机系统中,并且通常由数据库管理系统(DBMS)来控制。
RDBMS即关系数据库管理系统(Relational Database Management System)。它的特点包括:
1. 数据以表格的形式出现。
2. 每行为各种记录名称。
3. 每列为记录名称所对应的数据域。
4. 许多的行和列组成一张表单。
5. 若干的表单组成database。
RDBMS 术语:
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 键(key): 键的值在当前列中具有唯一性。
由于:菜鸟教程的例子是根据PHP 的学习。所以这里我们推荐另一个网站:
SQL 教程 (w3schools.com)
二、开始学习使用mysql 语句。
一些最重要的 SQL 命令
SELECT- 从数据库中提取数据 selectUPDATE- 更新数据库中的数据 updateDELETE- 从数据库中删除数据 deleteINSERT INTO- 将新数据插入数据库 insert intoCREATE DATABASE- 创建一个新数据库 create databaseALTER DATABASE- 修改数据库 alter databaseCREATE TABLE- 创建一个新表 create tableALTER TABLE- 修改表格 alter tableDROP TABLE- 删除表 drop tableCREATE INDEX- 创建索引(搜索键) create indexDROP INDEX- 删除索引 drop index
select语句:
记住:select distinct comnlus from Customers
该语句用于仅返回不同(不同)的值。SELECT DISTINCT
在表中,一列通常包含许多重复值;有时您只想列出不同的(不同的)值。
以下 SQL 语句从“客户”中选择国家/地区为 不是“德国”也不是“美国”:
SELECT * FROM Customers
WHERE NOT Country = 'Germany' AND NOT Country = 'USA';
按关键字排序的 MySQL
关键字用于按升序或 降序。ORDER BY
默认情况下,关键字按升序对记录进行排序。若要按降序对记录进行排序,请使用关键字。ORDER BY DESC
以下 SQL 语句从“客户”表中选择所有客户, 按“国家/地区”升序排序,按“客户名称”列降序排序:
SELECT * FROM Customers
ORDER BY Country ASC, CustomerName DESC;
MySQL 更新语句
它是确定将更新多少条记录的子句。WHERE
以下 SQL 语句将 将国家/地区为“墨西哥”的所有记录的邮政编码更新为 00000:
UPDATE Customers
SET PostalCode = 00000
WHERE Country = 'Mexico';
MySQL 限制条款
该子句用于指定要返回的记录数。LIMIT
以下 SQL 语句从“客户”表中选择前三条记录, 其中国家是“德国”:
例
SELECT * FROM Customers
WHERE Country='Germany'
LIMIT 3;
MySQL MIN() 和 MAX() 函数
该函数返回所选列的最小值。MIN()
该函数返回所选列的最大值。MAX()
以下 SQL 语句查找最便宜产品的价格:(加了as,后面是别名的意思。)
SELECT MIN(Price) AS SmallestPrice
FROM Products;
计数() 语法
该函数返回与指定条件匹配的行数。COUNT()
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
AVG() 语法
该函数返回数字列的平均值。AVG()
FRFROM Products;
SUM() 语法
该函数返回数字列的总和。SUM()
以下 SQL 语句查找“数量”字段的总和 在“订单详情”表中:
SELECT SUM(Quantity)
FROM OrderDetails;
MySQL LIKE 运算符
运算符在子句中用于搜索列中的指定模式。LIKE WHERE
有两个通配符通常与运算符结合使用: LIKE
- 百分号 (%) 表示零个、一个或多个字符
- 下划线符号 (_) 表示一个字符
百分号和下划线也可以组合使用!
以下 SQL 语句选择具有 ContactName 的所有客户 以“a”开头,以“o”结尾:
例
SELECT * FROM Customers
WHERE ContactName LIKE 'a%o';
以下 SQL 语句选择具有 CustomerName 的所有客户 做 不以“a”开头:
例
SELECT * FROM Customers
WHERE CustomerName NOT LIKE 'a%';
MySQL 通配符(% _ )
通配符用于替换字符串中的一个或多个字符。
通配符与运算符一起使用。运算符在子句中用于搜索列中的指定模式。 LIKELIKE WHERE
以下 SQL 语句选择“城市”以任意字符开头,后跟“ondon”的所有客户:
例
SELECT * FROM Customers
WHERE City LIKE '_ondon';
MySQL IN 运算符
运算符允许您在一个子句中指定多个值。IN WHERE
运算符是多个条件的简写。IN OR
以下 SQL 语句选择位于“德国”、“法国”的所有客户 或“英国”:
SELECT * FROM Customers
WHERE Country IN ('Germany', 'France', 'UK');
以下 SQL 语句选择来自同一客户的所有客户 作为供应商的国家:
例
SELECT * FROM Customers
WHERE Country IN (SELECT Country FROM Suppliers);
MySQL BETWEEN 运算符
运算符选择给定范围内的值。这些值可以是数字、文本或日期。BETWEEN
运算符是包含的:包括开始值和结束值。BETWEEN
以下 SQL 语句选择价格介于 10 和 20 之间的所有产品 1. 此外;请勿显示分类 ID 为1、2、3的商品:
例
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20
AND CategoryID NOT IN (1,2,3);
以下 SQL 语句选择订单日期介于 '01-1996-31' 和 '1996年<>月<>日':
例
SELECT * FROM Orders
WHERE OrderDate BETWEEN '1996-07-01' AND '1996-07-31';
MySQL 别名
别名用于为表或表中的列指定临时名称。
别名通常用于使列名更具可读性。
别名仅在该查询期间存在。
使用关键字创建别名。AS
以下 SQL 语句创建两个列别名,一个用于客户 ID 列,一个用于“客户名称”列:
SELECT CustomerID AS ID, CustomerName AS Customer
FROM Customers;
以下 SQL 语句创建一个名为“Address”的别名,该别名组合了四列(地址、邮政编码、 城市和国家):
例
SELECT CustomerName, CONCAT_WS(', ', Address, PostalCode, City, Country) AS Address
FROM Customers;
以下 SQL 语句从客户那里选择所有订单 客户 ID = 4(在喇叭周围)。我们使用“客户”和“订单”表,以及 分别给它们“c”和“o”的表别名(这里我们使用 别名以缩短 SQL):
例:
SELECT o.OrderID, o.OrderDate, c.CustomerName
FROM Customers AS c, Orders AS o
WHERE c.CustomerName='Around the Horn' AND c.CustomerID=o.CustomerID;
等同于:
SELECT Orders.OrderID, Orders.OrderDate, Customers.CustomerName
FROM Customers, Orders
WHERE Customers.CustomerName='Around the Horn' AND Customers.CustomerID=Orders.CustomerID;
MySQL 连接表
子句用于合并两个或多个表中的行,基于 它们之间的相关列。JOIN
MySQL 中支持的联接类型
INNER JOIN:返回两个表中具有匹配值的记录LEFT JOIN:返回左侧表中的所有记录,以及右侧表中的匹配记录RIGHT JOIN:返回右侧表中的所有记录,以及左侧表中的匹配记录CROSS JOIN:返回两者的所有记录 表
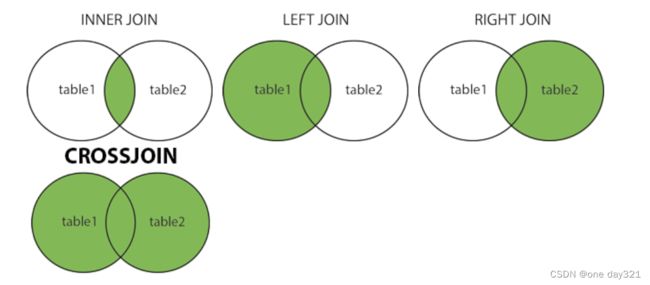
创建以下 SQL 语句(包含一个 ), 选择在两个表(Orders、Customers )中具有匹配值的记录: INNER JOIN
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
连接三个表:
以下 SQL 语句选择包含客户和托运人的所有订单 信息:
例
SELECT Orders.OrderID, Customers.CustomerName, Shippers.ShipperName
FROM ((Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID)
INNER JOIN Shippers ON Orders.ShipperID = Shippers.ShipperID);
以下 SQL 语句将选择所有客户以及他们可能拥有的任何订单:LEFT JOIN
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID
ORDER BY Customers.CustomerName;
以下 SQL 语句将返回所有员工及其任何订单 可能已经放置了:RIGHT JOIN
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID;
MySQL 分组依据语句
该语句将具有相同值的行分组到摘要中 行,例如“查找每个国家/地区的客户数量”。GROUP BY
该语句通常与聚合函数 (、、、、) 一起使用,以按一列或多列对结果集进行分组。GROUP BYCOUNT()MAX()MIN()SUM()AVG()
以下 SQL 语句列出了每个国家/地区的客户数量:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
以下 SQL 语句列出了每个国家/地区的客户数量, 从高到低排序:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;
使用联接示例分组依据
以下 SQL 语句列出了每个发件人发送的订单数:
例
SELECT Shippers.ShipperName, COUNT(Orders.OrderID) AS NumberOfOrders FROM Orders
LEFT JOIN Shippers ON Orders.ShipperID = Shippers.ShipperID
GROUP BY ShipperName;
MySQL CASE 语句
该语句通过条件,并在第一个条件为 遇见了(就像一个如果-然后-其他语句)。因此,一旦条件为真,它就会停止 读取并返回结果。如果没有条件为真,则返回 子句中的值。CASEELSE
如果没有部分且没有条件为真,则返回 NULL。ELSE
以下 SQL 将按城市对客户进行排序。但是,如果城市为 NULL,则按国家/地区排序:
例
SELECT CustomerName, City, Country
FROM Customers
ORDER BY
(CASE
WHEN City IS NULL THEN Country
ELSE City
END);
三、学习MySQL 创建数据库语句
和前面使用mysql语句不一样。这里是创建数据库。
SQL 创建数据库语句
该语句用于创建新的 SQL 数据库。CREATE DATABASE
语法
CREATE DATABASE databasename;
SQL 删除数据库语句
该语句用于删除现有 SQL 数据库。DROP DATABASE
语法
DROP DATABASE databasename;
SQL 备份数据库语句
该语句在 SQL Server 中用于创建现有 SQL 数据库的完整备份。BACKUP DATABASE
语法
BACKUP DATABASE databasename
TO DISK = 'filepath';
例如:
BACKUP DATABASE testDB
TO DISK = 'D:\backups\testDB.bak';
使用差异备份示例 (differential)
以下 SQL 语句创建数据库“testDB”的差异备份:
例
BACKUP DATABASE testDB
TO DISK = 'D:\backups\testDB.bak'
WITH DIFFERENTIAL;
提示:差异备份可减少备份时间(因为仅备份更改)。
SQL 创建表语句
该语句用于在数据库中创建新表。CREATE TABLE
语法
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
....
);
下面的示例创建一个名为“人员”的表,其中包含五列:人员 ID、姓氏、名字、 地址和城市:
CREATE TABLE Persons (
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
PersonID 列的类型为 int,将保存一个整数。
“姓氏”、“名字”、“地址”和“城市”列是 键入 varchar 并将保存字符,以及这些字段的最大长度 是 255 个字符。
以下 SQL 创建一个名为“TestTables”的新表(即 “客户”表的副本):
例
CREATE TABLE TestTable AS
SELECT customername, contactname
FROM customers;
SQL 删除表语句
该语句用于删除数据库中的现有表。DROP TABLE
语法
DROP TABLE table_name;
SQL 更改表语句
该语句用于添加、删除或修改现有表中的列。ALTER TABLE
该语句还用于添加和删除各种约束 现有表。ALTER TABLE
若要在表中添加列,请使用以下语法:
ALTER TABLE table_name
ADD column_name datatype;
若要删除表中的列,请使用以下语法(请注意,一些 数据库系统不允许删除列):
ALTER TABLE table_name
DROP COLUMN column_name;
以下 SQL 从“客户”表中删除“电子邮件”列:
例
ALTER TABLE Customers
DROP COLUMN Email;
在“人员”表中添加一个名为“出生日期”的列。(这是约束,后面,就开始讲约束。)
我们使用以下 SQL 语句:
ALTER TABLE Persons
ADD DateOfBirth date; (DateOfBirth 是列,date是数据类型)
请注意,新列“出生日期”的类型为 date,并且将包含 日期。数据类型指定列可以保存的数据类型。
SQL 创建约束
可以在使用该语句创建表时或创建表后指定约束 与声明。CREATE TABLEALTER TABLE
语法
CREATE TABLE table_name (
column1 datatype constraint,
column2 datatype constraint,
column3 datatype constraint,
....
);
SQL 约束
SQL 约束用于为表中的数据指定规则。
约束用于限制可以进入表的数据类型。这 确保表中数据的准确性和可靠性。如果约束和数据操作之间存在任何冲突, 操作已中止。
约束可以是列级别或表级别。列级约束 应用于列,表级约束应用于整个表。
SQL 中通常使用以下约束:
NOT NULL- 确保列不能具有 NULL 值UNIQUE- 确保列中的所有值 不同PRIMARY KEY- a 和 . 唯一标识表中的每一行NOT NULLUNIQUEFOREIGN KEY- 防止破坏表之间链接的操作CHECK- 确保 列中的值满足特定条件DEFAULT- 设置列的默认值 如果没有值 已指定CREATE INDEX- 用于从数据库中创建和检索数据 很快
SQL 非空约束
默认情况下,列可以保存 NULL 值。
约束强制列不接受 NULL 值。NOT NULL
这将强制字段始终包含值,这意味着如果不向此字段添加值,则无法插入新记录或更新记录
以下 SQL 确保“ID”、“姓氏”和 “名字”列 创建“人员”表时将不接受空值:
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255) NOT NULL,
Age int
);
SQL 唯一约束
约束可确保列中的所有值都不同。UNIQUE
和约束都为一列或一组列的唯一性提供了保证。UNIQUEPRIMARY KEY
约束自动具有约束。PRIMARY KEYUNIQUE
但是,每个表可以有多个约束,但每个表只能有一个约束。UNIQUEPRIMARY KEY
以下 SQL 在创建“人员”表时对“ID”列创建约束:UNIQUE
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
UNIQUE (ID)
);
SQL 主键约束
约束唯一标识表中的每条记录。PRIMARY KEY
主键必须包含唯一值,并且不能包含 NULL 值。
一个表只能有一个主键;在表中,此主键可以 由单列或多列(字段)组成。
以下 SQL 在创建“人员”表时在“ID”列上创建一个:PRIMARY KEY
MySQL:
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PRIMARY KEY (ID)
);
(constraint)
若要允许命名约束,以及在多个列上定义约束,请使用以下 SQL 语法:PRIMARY KEYPRIMARY KEY
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
CONSTRAINT PK_Person PRIMARY KEY (ID,LastName)
);
SQL 外键约束
约束用于防止会破坏表之间的链接的操作。FOREIGN KEY
A 是一个表中的字段(或字段集合),它指的是 在另一个表中。FOREIGN KEYPRIMARY KEY
带有外键的表称为子表,该表 主键称为引用表或父表。
以下 SQL 在创建“订单”表时在“人员 ID”列上创建一个:FOREIGN KEY
MySQL:
CREATE TABLE Orders (
OrderID int NOT NULL,
OrderNumber int NOT NULL,
PersonID int,
PRIMARY KEY (OrderID),
FOREIGN KEY (PersonID) REFERENCES Persons(PersonID)
);
SQL 检查约束
约束用于限制可以放置在列中的值范围。CHECK
如果在列上定义约束,则 将仅允许此列的某些值。CHECK
如果在表上定义约束,则可以根据行中其他列中的值来限制某些列中的值。CHECK
以下 SQL 在创建“人员”表时对“年龄”列创建约束。 该约束确保人员的年龄必须为 18 岁或以上:CHECKCHECK
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
CHECK (Age>=18)
);
自动增量字段
自动增量允许在将新记录插入表中时自动生成唯一编号。
通常,这是我们希望在每次插入新记录时自动创建的主键字段。
以下 SQL 语句将“人员 ID”列定义为“人员”表中的自动递增主键字段:
CREATE TABLE Persons (
Personid int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PRIMARY KEY (Personid)
);
默认情况下,的起始值为 1,对于每条新记录,起始值将递增 1。AUTO_INCREMENT
要让序列以另一个值开头,请使用以下 SQL 语句:AUTO_INCREMENT
ALTER TABLE Persons AUTO_INCREMENT=100;
SQL 日期数据类型
MySQL带有以下数据类型,用于在数据库中存储日期或日期/时间值:
DATE- 格式 年年-月-DDDATETIME- 格式: 年-月-日 hh:mi:SSTIMESTAMP- 格式: 年-月-日 hh:mi:SSYEAR- 格式 YYYY 或 YY
SQL 注入
SQL 注入是一种代码注入技术,可能会破坏数据库。
SQL注入是最常见的网络黑客技术之一。
SQL 注入是通过网页输入在 SQL 语句中放置恶意代码。