什么是从人类反馈中强化学习(RLHF)?
自从OpenAI公司发布ChatGPT以来,人们对大型语言模型(LLM)的这一重大进步感到兴奋。虽然ChatGPT与其他最先进的大型语言模型大小相同,但其性能要高得多,并且承诺支持新的应用程序或颠覆取代原有的应用程序。
ChatGPT的惊人表现背后的主要原因之一是得益于其训练技术:从人类反馈中强化学习(RLHF)。虽然RLHF在大型语言模型方面已经展现了令人印象深刻的结果,但可以追溯到发布的首个GPT,而首个GPT应用程序并不是用于自然语言处理。
以下是人们需要了解的关于RLHF以及它如何应用于大型语言模型的知识。
什么是RLHF?
强化学习(RL)是机器学习的一个领域,其中代理通过与环境的交互来学习策略。代理采取行动(包括什么都不做)。这些行动会影响代理所处的环境,而环境进而转换到新的状态并返回奖励。奖励是使强化学习代理能够调整其行动策略的反馈信号。当代理进行训练时,它会调整自己的策略,并采取一系列行动,使其回报最大化。
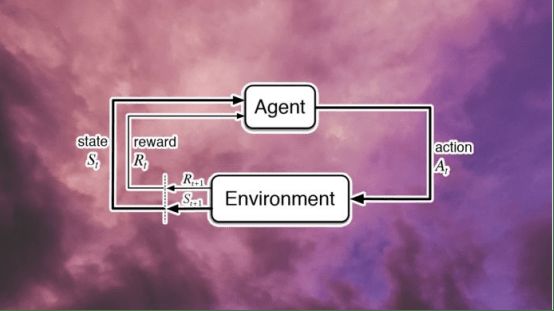
设计正确的奖励系统是强化学习的关键挑战之一。在某些应用中,奖励将会延迟很久。考虑一个用于下国际象棋的强化学习代理,只有在击败对手后才能获得积极的奖励,这可能需要下数十步棋才获得。在这种情况下,代理将会浪费大量的初始训练时间随机移动,直到它偶然发现获胜的组合。在其他应用程序中,奖励甚至不能用数学或逻辑公式来定义(当讨论语言模型时,将会详细讨论这一点)。
来自人类反馈的强化学习通过将人类纳入训练过程来增强强化学习代理的训练,这有助于解释奖励系统中无法衡量的元素。
为什么不总是用RLHF?首先,其扩展性很差。一般来说,机器学习的一个重要优势是它能够随着计算资源的可用性进行扩展。随着计算机发展得越来越快,数据变得越来越可用,因此能够以更快的速度训练更大的机器学习模型,而依赖人类训练强化学习系统成为瓶颈。
因此,大多数RLHF系统依赖于自动化系统和人工提供的奖励信号的组合。计算奖励系统为强化学习代理提供主要反馈。人类管理者或者偶尔提供额外的奖励/惩罚信号,或者提供训练奖励模型所需的数据。
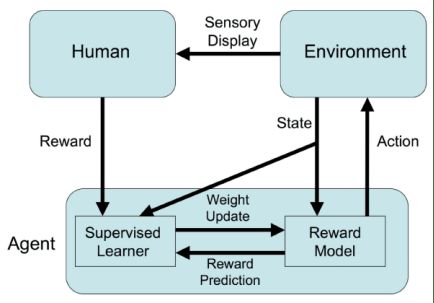
RLHF的示例
假设创造一个烹饪披萨饼的机器人,可以将一些可测量的元素整合到自动奖励系统中(例如,披萨饼的厚度、酱汁和奶酪的数量等)。但为了确保披萨美味可口,需要人类品尝,并在训练过程中为机器人烹饪的披萨饼打分。
语言作为强化学习问题
大型语言模型已被证明非常擅长于多种任务,包括文本摘要、问题回答、文本生成、代码生成、蛋白质折叠等等。在非常大的范围内,大型语言模型可以进行零样本和小样本学习,完成它们没有受过训练的任务。Transformer模型(大型语言模型中使用的架构)的一大成就是它能够通过无监督学习进行训练。
然而,尽管大型语言模型取得了令人着迷的成就,但它们与其他机器学习模型有着共同的基本特征。它们的核心是非常大的预测机器,旨在猜测序列中的下一个令牌(提示符)。在一个非常大的文本语料库上训练,大型语言模型开发了一个数学模型,可以产生(大部分)连贯和一致的长文本。
语言的最大挑战在于,在很多情况下,提示有很多正确答案。但是,根据大型语言模型的用户、应用程序和场景的不同,并不是这些方法都是可取的。不幸的是,大型文本语料库上的无监督学习并不能使模型与它将用于的所有不同应用程序保持一致。
幸运的是,强化学习可以帮助大型语言模型朝着正确的方向前进。但首先把语言定义为强化学习问题:
- 代理:语言模型是强化学习代理,必须学习创建最佳文本输出。
- 动作空间:动作空间是大型语言模型可以生成的可能语言输出的集合(非常大)。
- 状态空间:环境的状态包括用户提示和大型语言模型的输出(非常大)。
- 奖励:奖励衡量大型语言模型的响应与应用程序场景和用户意图的一致性。
上述强化学习系统中的所有元素都是微不足道的,除了奖励系统。与下国际象棋、围棋甚至机器人问题不同,奖励语言模型的规则并没有很好地定义。幸运的是,在RLHF的帮助下,可以为语言模型创建良好的奖励系统。
用于语言模型的RLHF
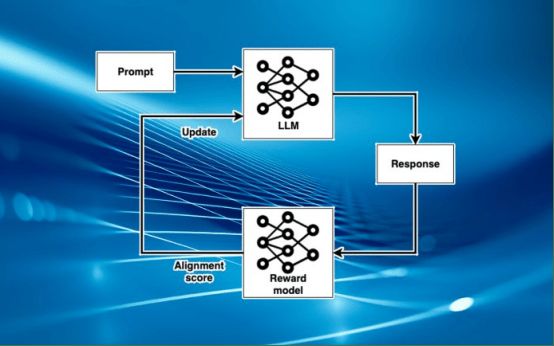
语言模型的RLHF由三个阶段组成。首先,从一个预先训练好的语言模型开始,这是非常重要的,因为大型语言模型需要大量的训练数据。用人类的反馈从零开始训练它们几乎是不可能的。通过无监督学习预训练的大型语言模型已经有了坚实的语言模型,并将创建连贯的输出,尽管其中一些或许多可能与用户的目标和意图不一致。
在第二阶段,为强化学习系统创建了一个奖励模型。在这个阶段,训练另一个机器学习模型,它接受主要模型生成的文本,并生成质量分数。第二个模型通常是另一个大型语言模型,它已被修改为输出标量值而不是文本标记序列。
为了训练奖励模型,必须创建一个由大型语言模型生成的文本标记为质量的数据集。为了组成每个训练示例,给主要的大型语言模型一个提示,并让它生成几个输出。然后,让评估人员对生成的文本进行从最好到最差的排序。然后,训练奖励模型来预测大型语言模型文本的分数。通过训练大型语言模型的输出和排名分数,奖励模型创建了人类偏好的数学表示。
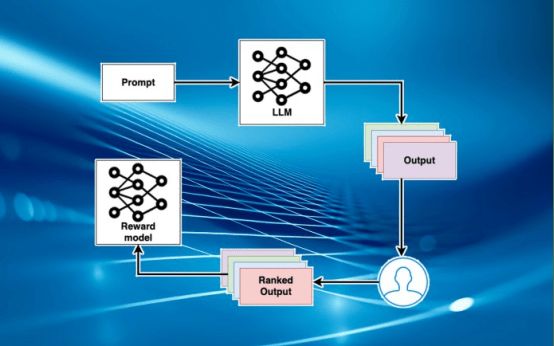
在最后阶段,创建了强化学习循环。主要大型语言模型的副本成为强化学习代理。在每个训练集中,大型语言模型从训练数据集中获取几个提示并生成文本。然后,它的输出被传递给奖励模型,奖励模型提供一个分数来评估其与人类偏好的一致性。大型语言模型随后被更新,以创建在奖励模型中得分更高的输出。
虽然这是RLHF用于语言模型的通用框架,但不同的实现也会进行修改。例如,由于更新主要的大型语言模型的成本非常昂贵,机器学习团队有时会冻结它的许多层以降低训练成本。
RLHF对语言模型的另一个考虑是保持奖励优化和语言一致性之间的平衡。奖励模式是对人类偏好的不完美近似。像大多数强化学习系统一样,代理大型语言模型可能会找到一条捷径,在违反语法或逻辑一致性的同时最大化奖励。为了防止发生这种情况,机器学习工程团队在强化学习循环中保留了原始大型语言模型的副本。原始大型语言模型输出与强化学习训练的大型语言模型输出的输出之间的差异(也称为KL散度)作为负值集成到奖励信号中,以防止模型与原始输出偏离太多。
ChatGPT如何使用RLHF
OpenAI公司还没有公布ChatGPT的技术细节。但是可以从有关ChatGPT博客文章和InstructGPT的详细信息中了解很多内容,而InstructGPT也使用RLHF。
ChatGPT使用以上描述的通用RLHF框架,并进行了一些修改。在第一阶段,工程师们对预先训练好的GPT-3.5模型进行了“监督微调”。他们雇佣了一组人类作家,并要求他们对一系列提示给出答案。他们使用提示答案对数据集来微调大型语言模型。据报道,OpenAI公司在这些数据上花费了大量资金,这也是ChatGPT优于其他类似大型语言模型的部分原因。
在第二阶段,OpenAI公司根据标准程序创建了奖励模型,对提示生成多个答案,并由人工注释器对其进行排序。
在最后阶段,使用近端策略优化(PPO) 强化学习算法来训练主要的大型语言模型。OpenAI公司没有提供进一步的细节,例如它是否冻结了模型的任何部分,或者它如何确保强化学习训练的模型不会偏离原始分布太多。
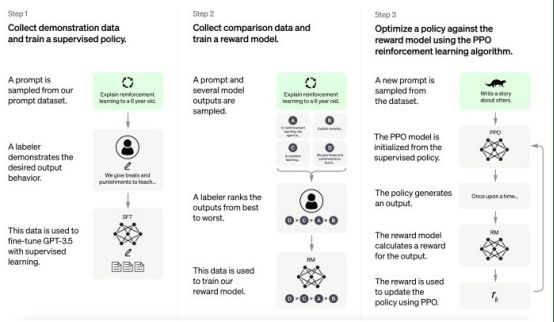
ChatGPT的训练流程
RLHF对语言模型的限制
虽然RLHF是一种非常有效的技术,但它也有一些局限性。人工劳动总是成为机器学习管道的瓶颈。人工标记数据缓慢而成本昂贵,这就是无监督学习一直是机器学习研究人员长期追求的目标的原因。
在某些情况下,可以从机器学习系统的用户那里获得免费标签。这就是在ChatGPT和其他类似的大型语言模型界面中看到的赞成/反对投票按钮的作用。另一种技术是从在线论坛和社交网络中获取标记数据。例如,许多Reddit帖子都是以问题形式发布的,最佳的答案会得到更高的支持率。然而,这样的数据集仍然需要清理和修改,但这样做成本昂贵并且缓慢,而且也不能保证所需要的数据在一个在线来源中就能得到。
大型科技公司和资金雄厚的实验室(例如OpenAI和DeepMind)有能力投入巨资创建特殊的RLHF数据集。但规模较小的企业将不得不依赖开源数据集和网络抓取技术。
RLHF也不是完美的解决方案。人类的反馈可以帮助大型语言模型避免产生有害或错误的结果,但人类的偏好并不是明确的,永远不可能创造符合所有社会和社会结构的偏好和规范的奖励模式。
然而,RLHF提供了一个框架,可以更好地将大型语言模型与人类保持一致。到目前为止,已经看到RLHF与ChatGPT等通用模型结合在一起工作,而RLHF将成为一种非常有效的技术,用于优化特定应用的大型语言模型。
原文标题:What is reinforcement learning from human feedback (RLHF)?,作者:Ben Dickson