Linux--虚拟内存地址空间(转载)
目录
一.进程地址空间
2.验证上述进程地址空间
3.Linux vs Windows
二.了解虚拟内存地址空间
0.通过代码引出虚拟内存地址空间概念
1.什么是虚拟内存地址空间
2.虚拟内存地址空间的设计方式
三.深入虚拟内存地址空间
1.虚拟内存地址空间与物理内存之间的映射
2.一个程序经过编译器到进程运行时的过程(帮助理解虚拟与物理之间映射关系)
3.虚拟内存地址空间存在的价值
四.重新理解fork函数
1.为什么会有两个返回值
2.为什么会有一个变量同时接收了两个返回值
3.写时拷贝
4.父子进程之间的关系
5.fork如何实现的调用fork之后父子进程代码共享
一.进程地址空间
我们先不谈虚拟内存与物理内存,当一个进程运行起来时,它的地址空间分布是什么样的呢?
1.进程地址空间分布图

2.验证上述进程地址空间
在Linux环境下验证!

代码:
#include
#include
int g_val1 = 10;
int g_val2 = 20;
int g_val3;
int g_val4;
int main(int argc, char* argv[], char* env[])
{
//任务:验证进程地址空间
//代码区
printf("code address:%p\n", main);
//只读常量区
const char* p1 = "hello";
printf("only read:%p\n", p1);
const char* p2 = "hello world";
printf("only read:%p\n", p2);
//全局区
printf("init global g_val1:%p\ninit global g_val2:%p\n", &g_val1, &g_val2);
printf("uninit global g_val3:%p\nuninit global g_val4:%p\n", &g_val3, &g_val4);
//堆区
char* tmp1 = (char*)malloc(10);
char* tmp2 = (char*)malloc(10);
char* tmp3 = (char*)malloc(10);
char* tmp4 = (char*)malloc(10);
printf("heap:%p\n", tmp1);
printf("heap:%p\n", tmp2);
printf("heap:%p\n", tmp3);
printf("heap:%p\n", tmp4);
//栈区
printf("stack:%p\n", &tmp1);
printf("stack:%p\n", &tmp2);
printf("stack:%p\n", &tmp3);
printf("stack:%p\n", &tmp4);
//命令行参数
for(int i = 0; i < argc; i++)
{
printf("argv[%d]:%p\n", i, argv[i]);
}
//环境变量
for(int i = 0; env[i]; i++)
{
printf("env[%d]:%p\n", i, env[i]);
}
return 0;
} 3.Linux vs Windows
1).以上对于进程地址空间的验证,是在linux环境下.
在windows下会跑出不一样的结果,因为windows基于安全考虑,做了特殊处理
二.了解虚拟内存地址空间
0.通过代码引出虚拟内存地址空间概念
代码:
代码描述:
1.先创建一个全局变量g_val,并且初始化为100
2.创建子进程后,在子进程内部将g_val改为200
3.观察父子进程的g_val值以及g_val地址
#include
#include
int g_val = 100;//全局变量
int main()
{
pid_t id = fork();
if(id == 0)
{
//子进程
g_val = 200;
printf("I am child, pid:%d, ppid:%d, g_val:%d, &g_val:%p\n", getpid(), getppid(), g_val, &g_val);
}
else
{
//父进程
printf("I am father, pid:%d, ppid:%d, g_val:%d, &g_val:%p\n", getpid(), getppid(), g_val, &g_val);
}
return 0;
} ![]()
结果:
![]()
结论:
我们惊奇的发现,父子进程所打印的g_val的地址是一样的,但是!!里面却存了不同的值!!!
(注意一点:我们这里所打印的地址,是进程运行起来之后,由进程内部的printf系统调用所打印出来的,所以本质打印的这个地址是动态的)
为什么同一块空间,里面存放的不同的值呢?
经过进一步思考与猜测,那就是这个地址不是真实的物理地址! 而是虚拟地址!
在后面会给出对于这一现象的详细解释
1.什么是虚拟内存地址空间
现象:
每一个进程,都拥有自己的虚拟内存地址空间
虚拟内存地址空间的本质,就是我们上面验证的那个进程地址空间,这俩是一个东西
每一个进程都不知道外部其他进程的存在,都认为自己独享物理内存,并且拥有4G的空间
但实际上,并不是真正拥有4G内存,而是按需分配物理内存!
类比:
其实,这本质不就是老板给员工画的一张饼吗?
我们假设的认为:
操作系统 --- 老板
进程 --- 员工
虚拟内存地址空间 --- 老板给员工画的饼
物理内存 --- 真正的好处(例如:真的升职了,真的加薪了)
可以看出,虚拟内存地址空间只是操作系统给进程许诺,你拥有了全部的4G内存,但这仅仅只是是许诺而已,并没有执行!
而实际情况则是按需所取,如果进程过分索取内存的话,操作系统有权利拒绝!
这便可以很形象的表现出这四者之间的关系!
2.虚拟内存地址空间的设计方式
我们都知道,管理的本质是先描述,再组织
例如我们学过的进程,进程是如何被管理起来的呢?
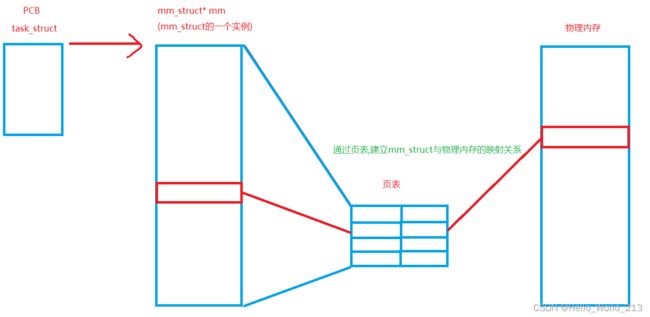
答案是:先描述,再组织. 先通过进程控制块(PCB)(在linux中的具体表现形式:task_struct)将进程描述起来,然后将这些PCB以某种数据结构的形式组织起来,这样操作系统便将所有的进程管理了起来!
那么,虚拟内存地址空间是如何设计的呢?
以及它在linux中的具体表现形式是什么?
它是如何被管理的?
1.虚拟内存地址空间是如何设计的
实际上,虚拟内存地址空间的本质就是一种数据结构,并且将来要和特定的进程关联起来.
这种数据结构在linux中表现为mm_struct
与特定的进程关联起来是某个进程PCB中有一个指针指向mm_struct
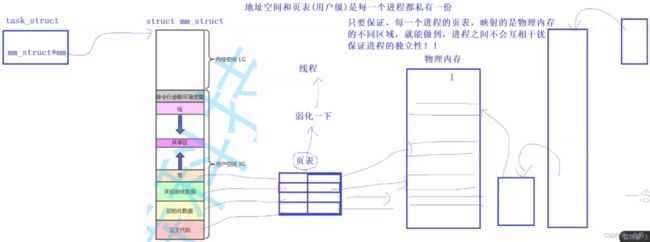
2.mm_struct的本质是什么(大概了解)
其内部会有区域划分(这只是一部分)

3.对于虚拟内存地址空间的管理
先描述,再组织
先描述:通过mm_struct描述起来,mm_struct就是一个结构体,这个结构体内部包含各种数据结构,各种边界判定
再组织:进程PCB有一个指针指向mm_struct,便将进程与其虚拟地址空间一一对应起来,同时mm_struct内部有很多数据结构也能够自行组织
三.深入虚拟内存地址空间
1.虚拟内存地址空间与物理内存之间的映射
虚拟内存与物理内存映射图
2.一个程序经过编译器到进程运行时的过程(帮助理解虚拟与物理之间映射关系)
1).我们写的一个程序,在编译器编译成功之后,形成了一个.exe可执行文件(这是一个二进制文件)并且存储在磁盘上
提问:虚拟地址空间中的地址从何而来?磁盘中的.exe文件有没有地址呢?
答:虚拟地址空间中的地址,是编译器给的! 编译器在编译的时候,就已经为每一行代码都编好了地址(这个编好的地址是每一行代码的地址,是代码区的,并不是堆栈,堆栈在进程运行时才产生),并且在形成.exe文件的时候,代码/地址,此时已经全部存在于.exe文件中.
2).当我们准备执行这个.exe文件时,点击执行的那一刹那,程序就正式成为了一个进程,此时操作系统会为这个进程创建虚拟内存地址空间与页表,并且加载部分数据到物理内存,然后通过页表将虚拟内存与物理内存映射起来
2).0).创建虚拟内存地址空间时,会先将.exe文件中编译器给编好的地址放到代码区和全局区,然后在执行过程中,在生成对应的堆区和栈区
2).1).cpu读取/分析/执行指令时,会先去找虚拟地址,然后通过页表映射关系,找到物理地址
2).2).一些运行时的报错:比如说对只读变量做了修改,或者对野指针进行访问的非法操作
这些报错是谁报出来的?硬件,比如内存:其实是随时都仅仅只是简单的读写操作,并没有监管这么一说,那实际的报错,其实是
操作系统的介入,在页表映射的时候会记录有映射到这个物理内存空间中的权限,从而操作系统就可以根据权限来做出判断
3).当实际访问的时候,发现对应的物理地址没有数据或者代码,就直接发生缺页中断,此时操作系统执行页面调入与内存管理算法,完成之后,进行填充页表,完成映射
重点提取:
0.程序编译好生成.exe文件存在磁盘上,此时.exe内已经有地址了
1.编译器给程序生成了虚拟地址(代码区/全局区)
2.cpu执行的是虚拟地址
3.物理内存只需要按需载入
4.物理内存很傻,只是随时随地可以读取,而是在页表映射中给相应的物理内存空间赋予权限
3.虚拟内存地址空间存在的价值
从安全的角度来看: 有效保护物理内存
如果直接使用物理内存,必然会发生进程A可以访问或修改进程B的数据,甚至可以影响内核程序
使用虚拟内存然后映射到物理内存这一机制,使得每个进程彼此互不干扰甚至不知道对方的存在
同时由于中间层(虚拟内存与页表)的介入,使得可以直接拒绝(通过OS)一些危险操作
从而OS可以杀掉一些危险进程,起到保护其他进程与OS内核的作用
从管理模式的角度来看: 完成了对于进程管理模块与内存管理模块的解耦合
什么是解耦合:
如果我将所有代码都写到main函数内,这就是高耦合
如果我将代码分功能分模块的写到不同函数内,然后在main函数中只是调用这些函数,这就是低耦合
所谓的耦合,就是关联性的意思
虚拟内存地址空间 --- 只负责进程管理
物理内存 --- 只负责内存管理
两者互不干扰
也就是说,代码和数据被加载到物理内存上时,并不用考虑区域的问题,而是随意加载物理内存的任意位置
无论加载到哪里,都可以让虚拟地址通过映射关系,找到所对应的所在物理内存上的位置
虚拟内存地址空间+页表 可以将在物理内存中乱序的指令有序化(因为虚拟地址空间负责进程管理,它是有序的)
从效率的角度来看: 避免了不必要的空间浪费
对于空间浪费的认识:
如果我说申请了多余的空间,毫无疑问这肯定是浪费了空间
而如果说,我申请了一块空间,但这块空间没有很及时的被使用,这依旧也造成了空间浪费
有了虚拟内存地址空间与页表的介入之后,如果我们申请了一块空间,这样的申请只能说是一种约定,相当于告诉物理内存
我之后要使用这块空间,物理内存知道了,但没有立刻开辟出来,而是当我们在使用这块空间时,发现实际并没有这块空间,此时
就会发生缺页中断,然后分配物理内存,建立映射关系,再继续执行
这种延时分配的策略,提高了整机的效率,使内存的利用率几乎是100%
以上这些逻辑是由操作系统自动完成,用户不会感知到,并且对于用户来说也无需担心!
从进程独立性的角度来看: 真正意义上的实现了进程之间互不干扰,互相独立
由于每个进程都拥有自己的虚拟内存地址空间与页表,并且当cpu在执行时,总是执行虚拟地址再找到物理地址,所以对于这个 进程来说,它是不知道外部世界的,因为cpu根本不会访问外部地址(物理地址),总是通过进程内的虚拟地址找到对应的物理地
址
从进程挂起的角度来看: 实现了对进程分批加载分批换入换出,进而提高硬件的上限
既然可以实现延时分配内存的策略,自然也就同样可以支持分批换入换出操作
(本质都是当实际映射到的物理内存空间不存在时,通过缺页中断,来执行页面调入和内存管理算法,填充页表,完成映射)
现实生活中的例子: 当前时代的游戏,随便就有几十G大小,而我们的内存只有4G/8G/16/32G...(内存的成本非常高)
如何让高达几十甚至几百G的游戏运行起来?
很显然将几十/几百G全部加载到内存,成本消耗巨大,普通人是承受不起的,这时发现我们8G的电脑都是可以运行并且
很流畅的,这就应用到了OS对进程分批加载,并且将需要的部分换入,不需要的部分换出.让8G的内存达到了几十G的效果
如果这个进程短时间内不会被执行,就叫做阻塞
进程的数据和代码被换出,就叫做挂起
所以进程阻塞之后,进程的代码和数据就会被挂起!!!!!!
四.重新理解fork函数
1.为什么会有两个返回值
fork是系统调用,fork函数内部会创建子进程,当fork函数准备return时,子进程便已经被创建出来了,子进程被创建出来之后的代码父子共享(原理在第5点会介绍),此时父进程需要return,而刚刚被创建出来的子进程也要执行return,给子进程返回0,给父进程返回子进程的pid

2.为什么会有一个变量同时接收了两个返回值
我们知道了为什么表面上同一个函数为什么会有两个返回值之后
那么同一个变量,是如何接收两个不同的返回值,并且还能同时作出判断的呢???
这在我们不知道虚拟内存地址空间之前,是无法理解的
现在我们便可以给出合理并且正确的解释:
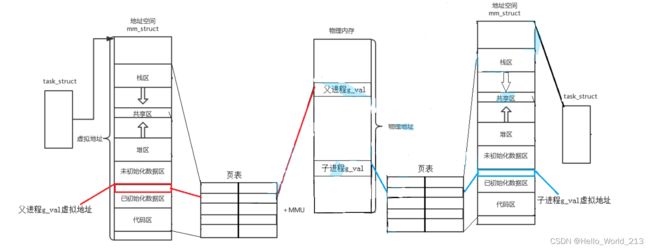
1).当我们创建出子进程,子进程会拷贝(或继承)父进程的虚拟地址空间
(为什么会继承父进程的虚拟地址空间呢? 因为在编译器编译的时候,只编译了父进程,给父进程生成了.exe文件,并且给每一行代码都进行了编址,那么在父进程运行时,子进程凭空出现,自己成的虚拟地址又怎么样让它生成呢?直接简单粗暴,拷贝父进程的!)
2).假设接收返回值的变量命名为id,这时子进程和父进程对于id这个变量拥有相同的虚拟地址(因为子继承的父),并且通过映射指向的是同一块物理内存空间
3).当第二次进行对id的写入时,会通过虚拟地址然后通过映射机制找到物理内存,并且知道这一次写入的(第二次写入)是父还是子,发现第一次已经写入过一次了,所以第二次就会重新为其开辟新的空间并且建立新的映射关系,此时父子表面上对于id的虚拟地址是相同的,但是实际指向的物理内存却是两块不同的空间
画图解释:
3.写时拷贝
创建子进程时只需要将未来会写入的数据再重新拷贝一份
但是操作系统并不知道哪些数据将来会被写入,即便是知道了提前就开辟好一块新的空间并且拷贝,这样长时间占用内存却不使用的情况也会造成空间浪费
所以操作系统所采用的方法是写时拷贝,只有当数据被写入时,才会发生拷贝
这一理念在C++的深浅拷贝中也有所体现!
4.父子进程之间的关系
1).子进程被创建出来时,会拷贝父进程的虚拟地址空间
2).共享子进程被创建完之后的代码(fork之后),也就是父子都从那一刻同时执行之后的代码
3).父与子是两个独立的进程,具有独立性,不相互影响不相互依赖
4).代码是只读的,所以代码层面上的共享,对于他俩的独立性而言没有影响
5).数据是可以被修改的,所以必须分离
5.fork如何实现的调用fork之后父子进程代码共享
由于进程具有并发性,所以随时有可能中断,所以必须要有多个硬件(寄存器)来存放当前进程执行到的数据与状态(例如进程执行到的位置),以便将来用于继续执行还未执行完的进程,这种寄存器内,存储的数据称为:进程的上下文数据
其中EIP寄存器,就是用来存放cpu将要读取的下一条指令的地址
创建好子进程之后,子进程认为从EIP开始执行,所以就会从父进程的EIP记录处为起始,开始继续向下执行指令