【数据挖掘】推荐系统(二):基于内容的推荐
五、基于内容的系统
5.1 基本原理
基于内容的系统根据用户偏好和配置文件生成建议。他们尝试将用户与他们以前喜欢的项目相匹配。项目之间的相似程度通常根据用户喜欢的项目的属性来确定。与大多数利用目标用户和其他用户之间的评级的协作过滤模型不同,基于内容的模型侧重于目标用户自己提供的评级。从本质上讲,基于内容的方法利用不同的数据源来生成建议。
基于内容的系统的最简单形式需要以下数据源(这些要求可能会根据您尝试构建的系统的复杂性而增加):
- 项目级数据源 — 您需要与项目属性关联的强大数据源。对于我们的场景,我们有书价、num_pages、published_year等。您了解有关该项目的信息越多,它对您的系统就越有利。
- 用户级数据源 - 您需要根据您为其提供建议的项目提供某种用户反馈。此级别的反馈可以是隐式的,也可以是显式的。在我们的示例数据中,我们针对用户对他们阅读过的图书进行评分。您可以跟踪的用户反馈越多,对您的系统就越有利。
5.2 基于内容推荐的优缺点
5.2.1 优势
当可用的评级数据量不足时,基于内容的模型对于推荐项目最有利。这是因为用户可能已对具有类似属性的其他项目进行了评级。因此,即使没有大量数据,模型也应该能够利用评级和项目属性来生成建议。
5.2.2弊端
基于内容的系统有两个主要缺点。
- 根据用户消费的项目/内容,提供的建议是“显而易见的”。这是一个缺点,因为如果用户从未与特定类型的项目交互,则永远不会向用户推荐该项目。例如,如果你从未读过神秘书籍,那么通过这种方法,您将永远不会被推荐神秘书籍。这是因为该模型是特定于用户的,并且没有利用来自类似用户的知识。这减少了建议的多样性,这对许多企业来说是一个负面的结果。
- 它们无法为新用户提供建议。构建模型时,您需要项目的显式/隐式用户级数据的历史记录。通常,拥有一个大型评级数据集,以便在不过度拟合的情况下进行可靠的预测,这一点很重要。
5.3 例子
基于内容的系统的一些例子是:
- 亚马逊产品 Feed(向您推荐的产品与您之前购买的产品相似)
- Spotify 音樂推薦
有许多优秀的基于内容的系统是用算法构建的,不依赖于基于模型的方法。例如,像Hacker Rank和Reddit这样的公司以前曾使用算法方法来向用户推荐其平台上的新帖子。为基于内容的推荐器构建算法方法的关键在于为您的业务定义一组可用于对项目进行排名的规则。就Reddit而言,他们的推荐受到发布时间,喜欢数量,不喜欢数量,评论数量等的限制。这可以考虑在公式中以生成帖子的分数,高分数将产生高推荐,反之亦然。
5.3.1 实现
- 从generate_data功能(上面提供的功能)导入数据或从此处下载CSV
- 规范化book_price、book_ratings num_pages
- 一个热编码publish_year、book_genre text_lang
- 给定一个book_id输入,计算余弦相似性并返回与输入相似的前 n 本书
import pandas as pd
import numpy as np
from numpy import dot
from numpy.linalg import norm
def normalize(data):
'''
This function will normalize the input data to be between 0 and 1
params:
data (List) : The list of values you want to normalize
returns:
The input data normalized between 0 and 1
'''
min_val = min(data)
if min_val < 0:
data = [x + abs(min_val) for x in data]
max_val = max(data)
return [x/max_val for x in data]
def ohe(df, enc_col):
'''
This function will one hot encode the specified column and add it back
onto the input dataframe
params:
df (DataFrame) : The dataframe you wish for the results to be appended to
enc_col (String) : The column you want to OHE
returns:
The OHE columns added onto the input dataframe
'''
ohe_df = pd.get_dummies(df[enc_col])
ohe_df.reset_index(drop = True, inplace = True)
return pd.concat([df, ohe_df], axis = 1)
class CBRecommend():
def __init__(self, df):
self.df = df
def cosine_sim(self, v1,v2):
'''
This function will calculate the cosine similarity between two vectors
'''
return sum(dot(v1,v2)/(norm(v1)*norm(v2)))
def recommend(self, book_id, n_rec):
"""
df (dataframe): The dataframe
song_id (string): Representing the song name
n_rec (int): amount of rec user wants
"""
# calculate similarity of input book_id vector w.r.t all other vectors
inputVec = self.df.loc[book_id].values
self.df['sim']= self.df.apply(lambda x: self.cosine_sim(inputVec, x.values), axis=1)
# returns top n user specified books
return self.df.nlargest(columns='sim',n=n_rec)
if __name__ == '__main__':
# constants
PATH = '../data/data.csv'
# import data
df = pd.read_csv(PATH)
# normalize the num_pages, ratings, price columns
df['num_pages_norm'] = normalize(df['num_pages'].values)
df['book_rating_norm'] = normalize(df['book_rating'].values)
df['book_price_norm'] = normalize(df['book_price'].values)
# OHE on publish_year and genre
df = ohe(df = df, enc_col = 'publish_year')
df = ohe(df = df, enc_col = 'book_genre')
df = ohe(df = df, enc_col = 'text_lang')
# drop redundant columns
cols = ['publish_year', 'book_genre', 'num_pages', 'book_rating', 'book_price', 'text_lang']
df.drop(columns = cols, inplace = True)
df.set_index('book_id', inplace = True)
# ran on a sample as an example
t = df.copy()
cbr = CBRecommend(df = t)
print(cbr.recommend(book_id = t.index[0], n_rec = 5))六、混合推荐系统
6.1 原理和直觉
推荐系统的各种方法都有其自身的优点和缺陷。通常,其中许多方法在单独使用时可能看起来很严格,尤其是当有多个数据源可用于该问题时。混合推荐系统旨在使用不同的可用数据源来生成可靠的推理。
混合推荐系统有两种主要设计,并行和顺序。并行设计为多个推荐系统提供输入,每个推荐组合在一起生成一个输出。顺序设计将输入参数提供给单个推荐引擎,输出按顺序传递给下一个推荐器。有关两种设计的可视化表示,请参阅下图。
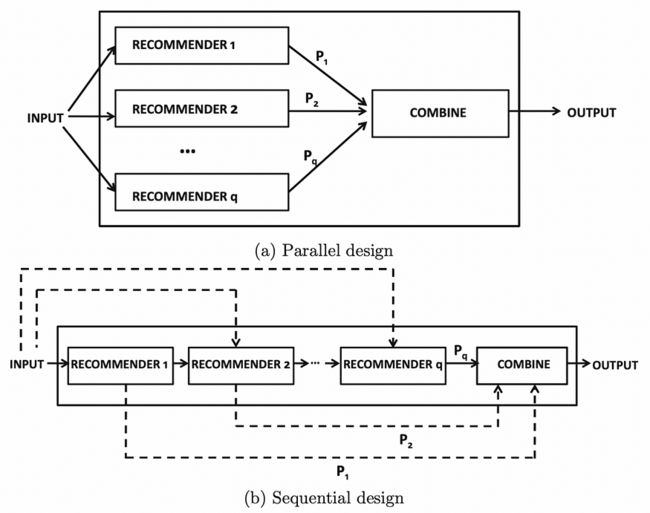
并行和顺序推荐系统架构。图片由C.C. Aggarwal提供,推荐系统:教科书
6.2 系统优缺点
6.2.1 优势
混合系统结合了不同的模型,以克服一种模型与另一种模型的缺点。这总体上减少了使用单个模型的弱点,并有助于生成更可靠的建议。这为用户提供了更强大和个性化的建议。
6.2.2 弊端
这些类型的模型通常具有很高的计算复杂性,并且需要包含评级和其他属性的大型数据库才能保持最新状态。如果没有最新的指标(用户参与度、评级等),就很难重新训练并提供来自不同用户的更新项目和评级的新建议。
6.3 案例
Netflix 是一家使用混合推荐系统的公司,他们根据相似用户的观看和搜索风格(协同过滤)以及具有相似特征的电影(基于内容)向用户生成推荐。
6.3.1 实现
- 从generate_data功能(上面提供的功能)导入数据或从此处下载CSV
- 使用基于内容的模型 (cosine_similarity) 计算 50 本最相似的书籍
- 使用协作
过滤模型 (SVD) 计算用户可能为这 50 本书提供的预测评分 - 返回预测评分最高的前 n 本图书
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from surprise import SVD, Reader, Dataset, accuracy
from surprise.model_selection import train_test_split
def hybrid(reader_id, book_id, n_recs, df, cosine_sim, svd_model):
'''
This function represents a hybrid recommendation system, it will have the following flow:
1. Use a content-based model (cosine_similarity) to compute the 50 most similar books
2. Compute the predicted ratings that the user might give these 50 books using a collaborative
filtering model (SVD)
3. Return the top n books with the highest predicted rating
params:
reader_id (Integer) : The reader_id
book_id (Integer) : The book_id
n_recs (Integer) : The number of recommendations you want
df (DataFrame) : Original dataframe with all book information
cosine_sim (DataFrame) : The cosine similarity dataframe
svd_model (Model) : SVD model
'''
# sort similarity values in decreasing order and take top 50 results
sim = list(enumerate(cosine_sim[int(book_id)]))
sim = sorted(sim, key=lambda x: x[1], reverse=True)
sim = sim[1:50]
# get book metadata
book_idx = [i[0] for i in sim]
books = df.iloc[book_idx][['book_id', 'book_rating', 'num_pages', 'publish_year', 'book_price', 'reader_id']]
# predict using the svd_model
books['est'] = books.apply(lambda x: svd_model.predict(reader_id, x['book_id'], x['book_rating']).est, axis = 1)
# sort predictions in decreasing order and return top n_recs
books = books.sort_values('est', ascending=False)
return books.head(n_recs)
if __name__ == '__main__':
# constants
PATH = '../data/data.csv'
# import data
df = pd.read_csv(PATH)
# content based
rmat = df.pivot_table(
columns = 'book_id',
index = 'reader_id',
values = 'book_rating'
).fillna(0)
#Compute the cosine similarity matrix
cosine_sim = cosine_similarity(rmat, rmat)
cosine_sim = pd.DataFrame(cosine_sim, index=rmat.index, columns=rmat.index)
# collaborative filtering
reader = Reader()
data = Dataset.load_from_df(df[['reader_id', 'book_id', 'book_rating']], reader)
# split data into train test
trainset, testset = train_test_split(data, test_size=0.3,random_state=10)
# train
svd = SVD()
svd.fit(trainset)
# run the trained model against the testset
test_pred = svd.test(testset)
# get RMSE
accuracy.rmse(test_pred, verbose=True)
# generate recommendations
r_id = df['reader_id'].values[0]
b_id = df['book_id'].values[0]
n_recs = 5
print(hybrid(r_id, b_id, n_recs, df, cosine_sim, svd))如果你想要一个关于如何以上面未显示的不同方式实现混合推荐系统的分步指南,你可以参考我的文章 使用 Node2Vec 构建链接预测推荐引擎。
七、结束语
请注意,这只是对推荐引擎的介绍。还有更多类型和方法来构建强大的推荐引擎,本文未涵盖这些内容。一些值得注意的是通过链接预测、算法方法、贝叶斯模型、马尔可夫模型等生成建议......
本文的目的是直观地理解和实现用于推荐系统(协同过滤、基于内容和混合)的基本方法。协同过滤是通过识别来自许多用户的偏好和信息来预测用户兴趣的过程,而基于内容的系统根据用户的偏好和配置文件生成建议。混合系统通常是许多推荐系统的组合。
我将在下面列出一些值得思考的内容,以评估建议的质量。这些问题在本文中没有回答,但在构建良好的推荐系统时是必不可少的。
- 如何跟踪推荐的流失率、响应能力、参与度和新颖性?
- 在知道用户 X 时间未与前一个推荐交互后,何时应向用户显示新推荐?
- 当用户对新产品进行评分或互动时,它会立即或稍后影响您的推荐系统?
- 随着用户与平台互动的增加,推荐会如何变化?
- 您如何知道您的建议不会将用户限制在业务的次要部分?
我特意尝试实现每种推荐系统的不同版本,以便更广泛地了解它们的实现。可以在此处查看用于生成这些结果的所有代码和数据。