Kylin知识点总结
Kylin
1、Apache Kylin概览
1.1 什么是Kylin
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
1.2 Kylin的简介
Kylin的出现就是为了解决大数据系统中TB级别数据的数据分析需求,它提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的Hive表。其核心是预计算,计算结果存在HBase中。
作为大数据分析神器,它也需要站在巨人的肩膀上,依赖HDFS、MapReduce/Spark、Hive/Kafka、HBase等服务。
1.3 Kylin的优势
Kylin的主要优势为以下几点:
- 可扩展超快
OLAP引擎:Kylin是为减少在Hadoop/Spark上百亿规模数据查询延迟而设计 Hadoop ANSI SQL接口:Kylin为Hadoop提供标准SQL支持大部分查询功能- 交互式查询能力:通过
Kylin,用户可以与Hadoop数据进行亚秒级交互,在同样的数据集上提供比Hive更好的性能 - 多维立方体(
MOLAP Cube):用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体 - 与
BI工具无缝整合:Kylin提供与BI工具的整合能力,如Tableau,PowerBI/Excel,MSTR,QlikSense,Hue和SuperSet - 其它特性:
Job管理与监控;压缩与编码;增量更新;利用HBase Coprocessor;基于HyperLogLog的Dinstinc Count近似算法;友好的web界面以管理,监控和使用立方体;项目及表级别的访问控制安全;支持LDAP、SSO
1.4 基本原理
Kylin的核心思想是预计算。
理论基础是:以空间换时间。即多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube并存储到HBase中,供查询时直接访问。
大致流程:将数据源(比如Hive)中的数据按照指定的维度和指标,由计算引擎Mapreduce离线计算出所有可能的查询结果(即Cube)存储到HBase中。HBase中每行记录的Rowkey由各维度的值拼接而成,度量会保存在column family中。为了减少存储代价,这里会对维度和度量进行编码。查询阶段,利用HBase列存储的特性就可以保证Kylin有良好的快速响应和高并发
Apache Kylin的工作原理是对数据模型做Cube预计算,并利用计算的结果加速查询。具体工作过程如下:
指定数据模型,定义维度和度量
预计算Cube,计算所有Cuboid并保存为物化视图(存储到hbase中)
执行查询时,读取Cuboid,运算,产生查询结果
高效OLAP分析:
Kylin的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算
利用预计算的结果来执行查询,相比非预计算的查询技术,其速度一般要快一到两个数量级,在超大的数据集上优势更明显
数据集达到千亿乃至万亿级别时,Kylin的速度可以超越其他非预计算技术1000倍以上
1.5 维度和度量
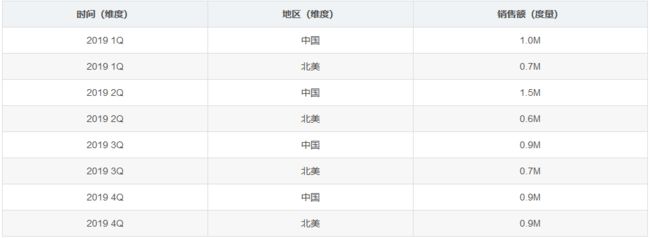
维度就是观察数据的角度,例如:
- 电商的销售数据,可以从时间的维度来观察,也可以细化从时间和地区的维度来观察
- 统计时,可以把维度值相同的记录聚合在一起,然后应用聚合函数做累加、平均、去重计数等聚合计算
度量就是被聚合的统计值,也是聚合运算的结果

1.6 数据立方体
数据立方体只是多维模型的一个形象的说法
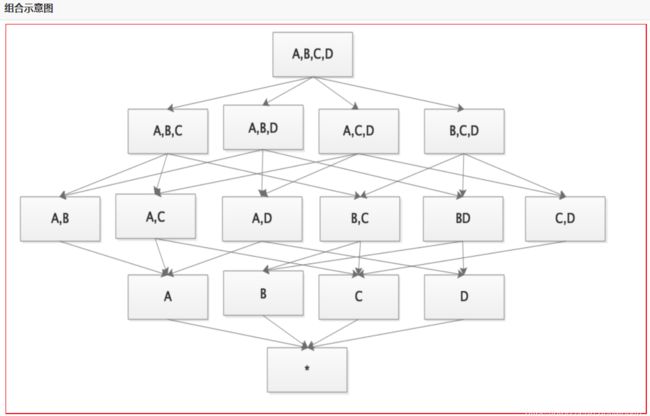
- 为什么叫立方体?
- 立方体本身只有三维,但多维模型不仅限于三维模型,可以组合更多的维度
- 为了与传统关系型数据库的二维表区别开来,才有了数据立方体的叫法
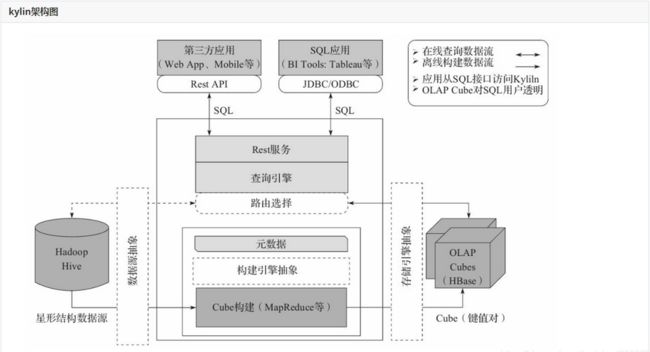
1.7 技术架构
-
数据源主要是Hadoop Hive,数据以关系表的形式输入,且必须符合星形模型,保存着待分析的用户数据。根据元数据的定义,构建引擎从数据源抽取数据,并构建Cube
-
Kylin可以使用MapReduce或者Spark作为构建引擎。构建后的Cube保存在右侧的存储引擎中,一般选用HBase作为存储
-
完成了离线构建后,用户可以从上方查询系统发送SQL进行查询分析
-
Kylin提供了各种Rest API、JDBC/ODBC接口。无论从哪个接口进入,SQL最终都会来到Rest服务层,再转交给查询引擎进行处理
-
SQL语句是基于数据源的关系模型书写的,而不是Cube
- Kylin在设计时,刻意对查询用户屏蔽了Cube的概念
- 分析师只需要理解简单的关系模型就可以使用Kylin,没有额外的学习门槛,传统的SQL应用也很容易迁
- 查询引擎解析SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于Cube的物理执行计划,最后查询预计算生成的Cube并产生结果,整个过程不会访问原始数据源
1.8 Kylin特点
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
1)标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
2)支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
3)亚秒级响应:Kylin拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
4)可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
5)BI工具集成
Kylin可以与现有的BI工具集成,具体包括如下内容。
ODBC:与Tableau、Excel、PowerBI等工具集成
JDBC:与Saiku、BIRT等Java工具集成
RestAPI:与JavaScript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
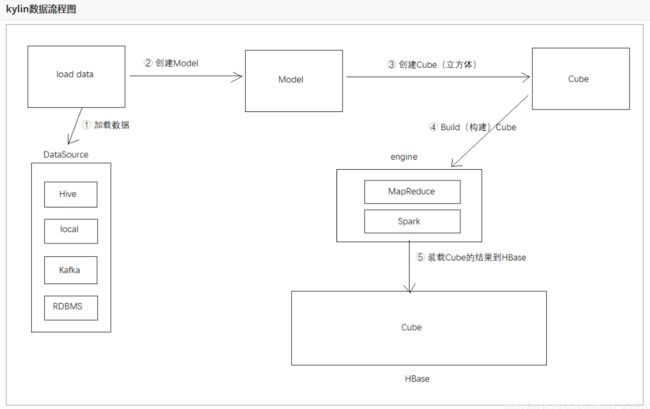
1.9 Kylin的总体架构
2、Kylin环境搭建
2.1 安装地址
1)官网地址
http://kylin.apache.org/cn/
2)官方文档
http://kylin.apache.org/cn/docs/
3)下载地址
http://kylin.apache.org/cn/download/
2.2 安装部署
提示说明:启动kylin之前,要启动如下所有命令
hive --service metastore &
hive --service hiveserver2 &
mr-jobhistory-daemon.sh start historyserver
将其上传服务器(目录随意)
#解压文件
[root@node1 ~]# tar -zxvf apache-kylin-2.5.1-bin-hbase1x.tar.gz -C /usr/local/
# 修改名称
[root@node1 local]# mv apache-kylin-2.5.1-bin-hbase1x/ kylin-2.5.1
# 启动 注意:启动之前要将HADOOP_HOME,HIVE_HOME,HBASE_HOME,HIVE_CONF配置好环境变量
[root@node1 kylin-2.5.1]# ./bin/kylin.sh start
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-msS2gQq7-1654304435820)(Kylin.assets/1619593891565.png)]
查看Web UI is at http://:7070/kylin
在http://qianfeng011:7070/kylin查看Web页面
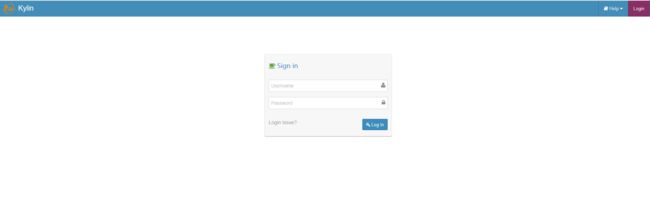
输入用户名密码:用户名为:ADMIN,密码为:KYLIN(系统已填)
关闭:kylin.sh stop
3、基础入门操作
创建hive表
create table if not exists default.class1(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by ',';
create table if not exists default.student(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by ',';
进入hive添加数据
hive (default)> load data local inpath "/root/class1.txt" into table default.class1;
hive (default)> load data local inpath "/root/student.txt" into table default.student;
3.1 同步Hive表
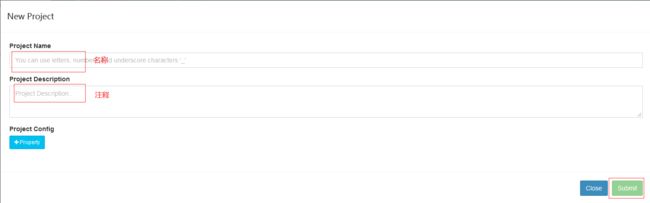
创建project
同步hive数据
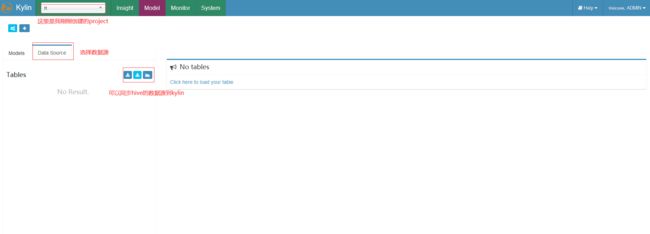
同步之前我们要查看Hive有哪些表


查看数据
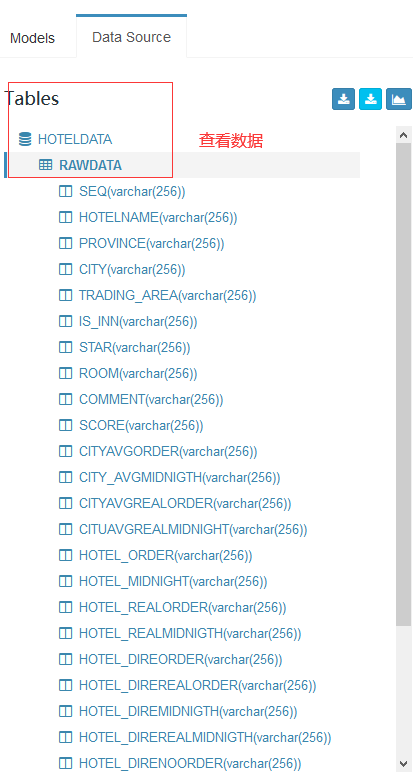
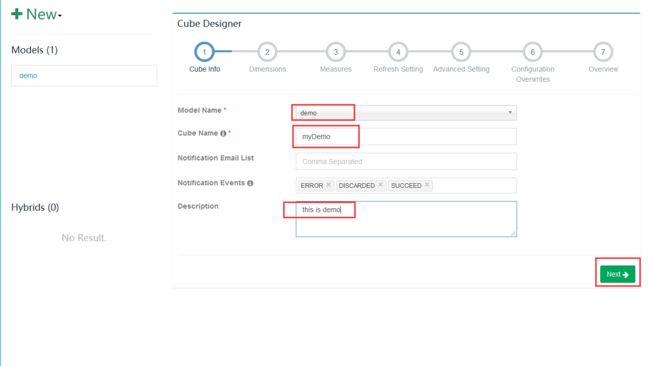
3.2 创建Model
首先我们选择创建New Model选项

设置名和注释,然后下一步
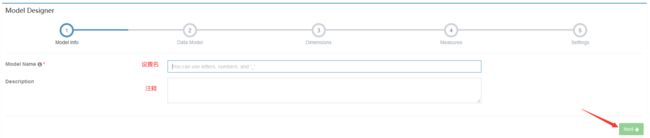
添加事实表
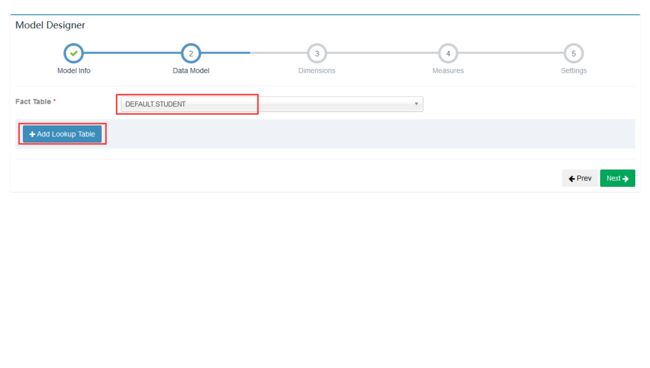
添加维度表及join字段
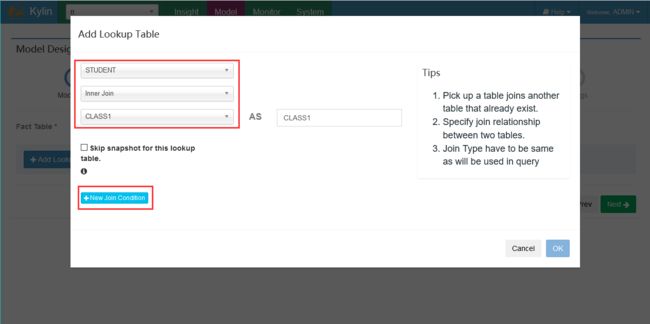
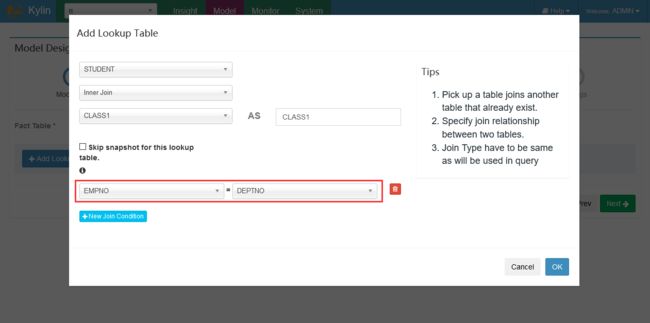
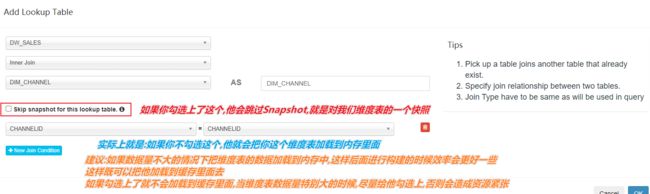
选择维度信息
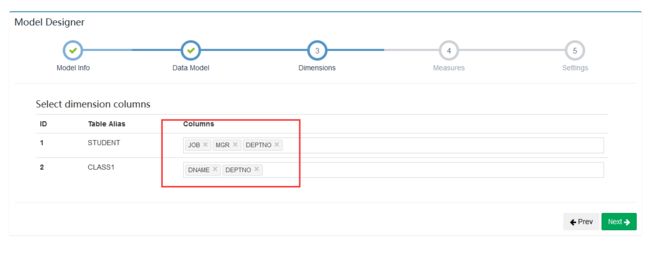
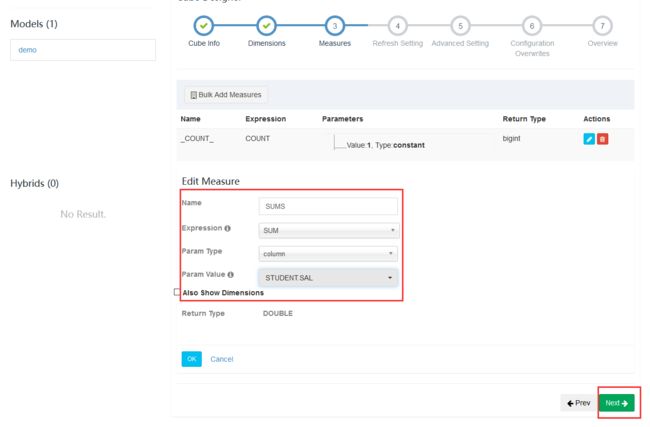
选择度量
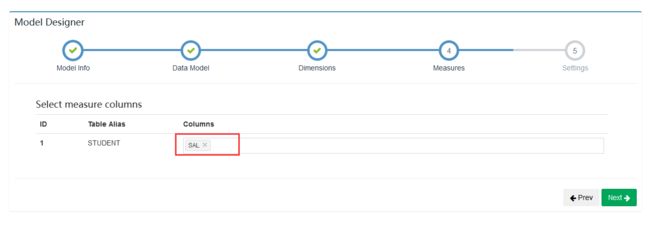
添加分区信息及过滤条件之后“Save”
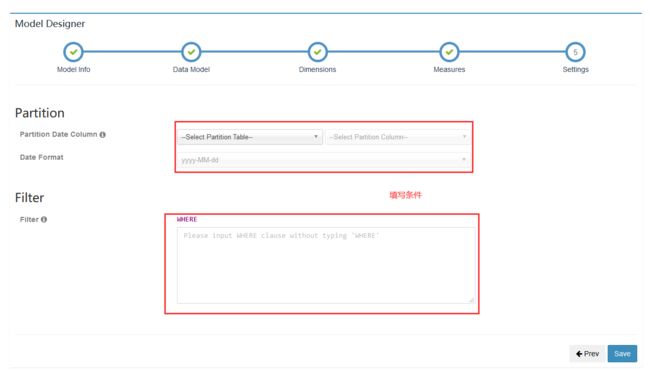
创建成功

3.3 创建Cube

选择模块创建cube
添加维度


添加需要做预计算的内容
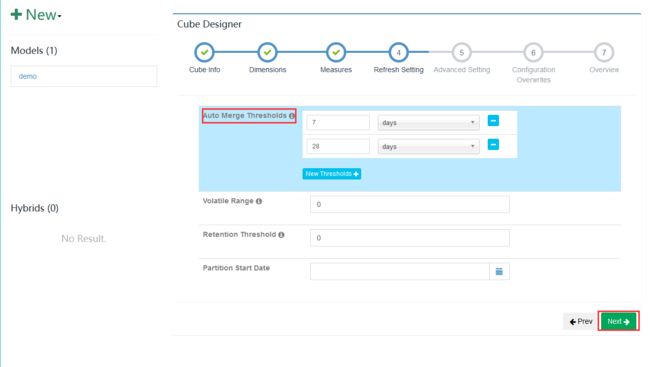
动态合并更新(默认即可,如果有需要可以修改条件)
多功能模块(默认)
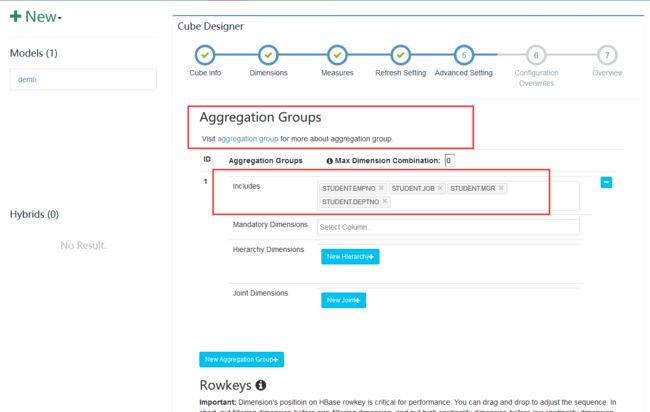
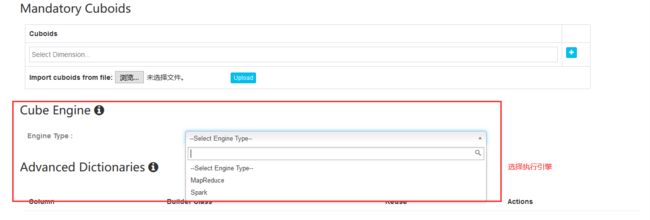
默认
创建信息

触发执行
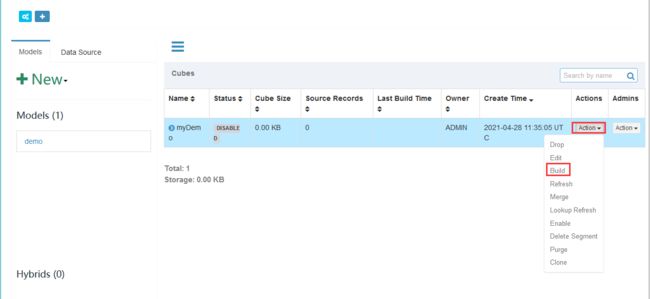
查看

进入hive查看cube表

执行完毕
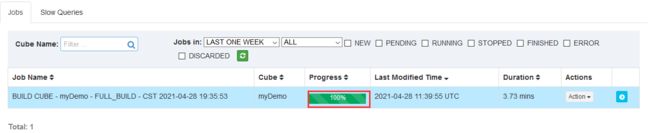
执行完毕后hive的cube消失

4、Hive和Kylin性能对比
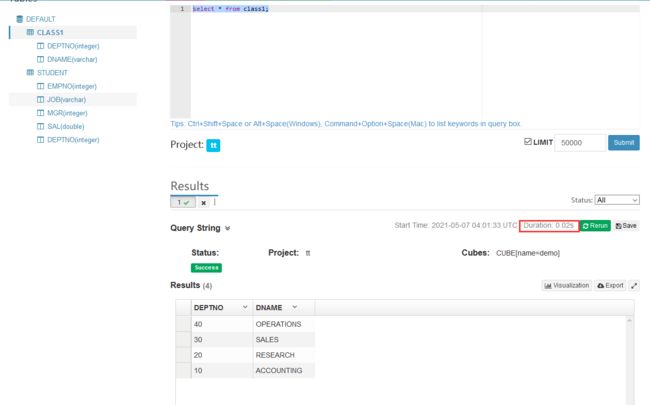
进入hive执行
select * from class1;

打开kylin页面
自带可视化
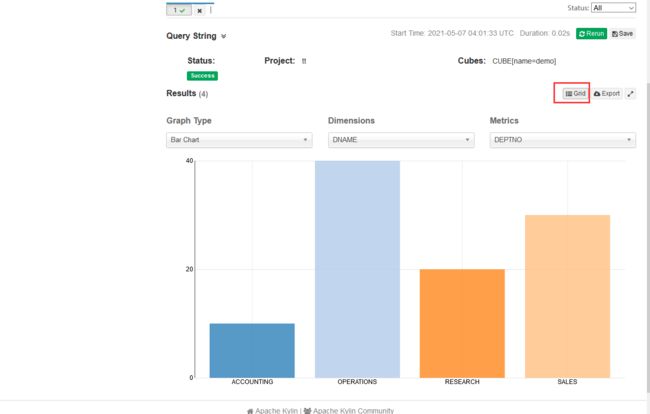
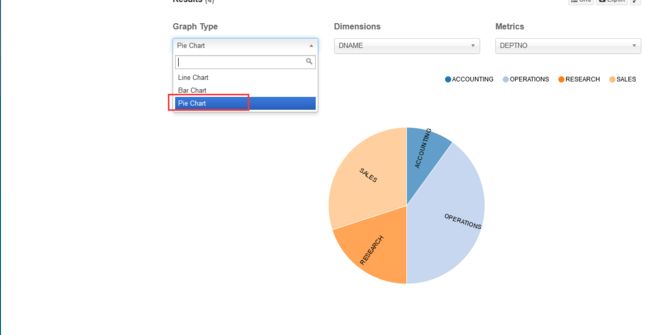
数据导出
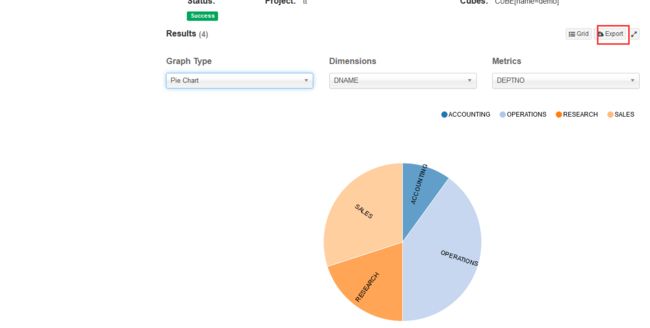
5、Kylin高阶操作
5.1 理解Cube,Cuboid与Segment的关系
Kylin将Cube划分为多个Segment(对应就是HBase中的一个表)
每个Segment用起始时间和结束时间来标志
Segment代表一段时间内源数据的预计算结果。
一个Segment的起始时间等于它之前那个Segment的结束时间,同理,它的结束时间等于它后面那个Segment的起始时间。
同一个Cube下不同的Segment除了背后的源数据不同之外,其他如结构定义,构建过程,优化方法,存储方式等都完全相同
| segment示意图 |
|---|
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FQhfqENT-1654304436182)(Kylin.assets/1620377995503.png)] |
一个Cube,可以包含多个Cuboid,而Segment是指定时间范围的Cube,可以理解为Cube的分区。对应就是HBase中的一张表。该表中包含了所有的Cuboid
例如:以下为针对某个Cube的Segment
| Segment名称 | 分区时间 | HBase表名 |
|---|---|---|
| 202110110000000-202110120000000 | 20211011 | KYLIN_41Z8123 |
| 202110120000000-202110130000000 | 20211012 | KYLIN_5AB2141 |
| 202110130000000-202110140000000 | 20211013 | KYLIN_7C1151 |
| … | … | … |
5.2 全量构建与增量构建
全量构建
全量构建:
Cube中只存在唯一的一个Segment
该Segment没有分割时间的概念,也就没有起始时间和结束时间
对于全量构建来说,每当需要更新Cube数据的时候,它不会区分历史数据和新加入的数据,也就是说,在构建的时候会导入并处理所有的原始数据
增量构建
增量构建:
只会导入新Segment指定的时间区间内的原始数据,并只对这部分原始数据进行预计算
5.2.1 全量构建与增量构建的对比
| 全量构建 | 增量构建 |
|---|---|
| 每次更新时都需要更新整个数据集 | 每次只对需要更新的时间范围进行更新,因此离线计算量相对较小 |
| 查询时不需要合并不同Segment的结果 | 查询时需要合并不同Segment的结果,因此查询性能会受影响 |
| 不需要后续的Segment合并 | 累计一定量的Segment之后,需要进行合并 |
| 适合小数据量或全表更新的Cube | 适合大数据量的Cube |
5.2.2 全量构建与增量构建的Cube查询方式对比
全量构建Cube
查询引擎只需向存储引擎访问单个Segment所对应的数据,无需进行Segment之间的聚合
为了加强性能,单个Segment的数据也有可能被分片存储到引擎的多个分区上,查询引擎可能仍然需要对单个Segment不同分区的数据做进一步的聚合
增量构建Cube
由于不同时间的数据分布在不同的Segment之中,查询引擎需要向存储引擎请求读取各个Segment的数据
增量构建的Cube上的查询会比全量构建的做更多的运行时聚合,通常来说增量构建的Cube上的查询会比全量构建的Cube上的查询要慢一些
对于小数据量的Cube,或者经常需要全表更新的Cube,使用全量构建需要更少的运维精力,以少量的重复计算降低生产环境中的维护复杂度。而对于大数据量的Cube,例如,对于一个包含两年历史数据的Cube,如果需要每天更新,那么每天为了新数据而去重复计算过去两年的数据就会变得非常浪费,在这种情况下需要考虑使用增量构建
5.3 增量Cube的创建
增量构建Cube过程
-
指定分割时间列
增量构建Cube的定义必须包含一个时间维度,用来分割不同的Segment,这样的维度称为分割时间列(Partition Date Column)
-
增量构建过程
- 在进行增量构建时,将增量部分的起始时间和结束时间作为增量构建请求的一部分提交给Kylin的任务引
- 任务引擎会根据起始时间和结束时间从Hive中抽取相应时间的数据,并对这部分数据做预计算处理
- 将预计算的结果封装成为一个新的Segment,并将相应的信息保存到元数据和存储引擎中。一般来说,增量部分的起始时间等于Cube中最后一个Segment的结束时间
导入文件到hive中,执行sql语句
-- 一、初始化Hive数据库、表结构
-- 1. 创建数据库、创建表
-- 2. 创建用户维度表
-- 3. 创建订单事实表
-- 1. 创建数据库、创建表
create database if not exists `kylin_dw`;
-- 2. 创建用户维度表
create table `kylin_dw`.`dim_user`(
id string,
name string
)
row format delimited fields terminated by ',';
-- 3. 创建订单事实表
create table `kylin_dw`.`fact_order`(
order_id string,
user_id string,
price int
)
partitioned by (dt string)
row format delimited fields terminated by ',';
-- 二、装载数据
load data local inpath '/root/data_dim_user.txt' overwrite into table `kylin_dw`.`dim_user`;
load data local inpath '/root/data_order_20211011.txt' overwrite into table `kylin_dw`.`fact_order` partition(dt='20211011');
load data local inpath '/root/data_order_20211012.txt' overwrite into table `kylin_dw`.`fact_order` partition(dt='20211012');
load data local inpath '/root/data_order_20211013.txt' overwrite into table `kylin_dw`.`fact_order` partition(dt='20211013');
load data local inpath '/root/data_order_20211014.txt' overwrite into table `kylin_dw`.`fact_order` partition(dt='20211014');
创建增量Cube的过程和创建普通Cube的过程基本类似,只是增量Cube会有一些额外的配置要求
先将数据同步过来
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D0NWzWIw-1654304435834)(Kylin.assets/1620379871395.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aRD88QEZ-1654304435835)(Kylin.assets/1620380226608.png)]
-
配置Model
增量构建的Cube需要指定分割时间列。例如:将日期分区字段添加到维度列中将日期分区字段添加到维度列中
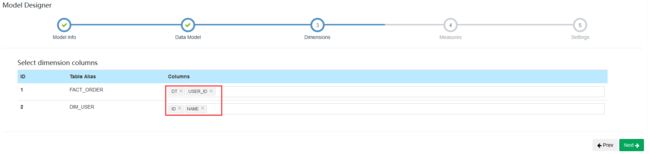
在设置中,配置分区列,并指定日期格式
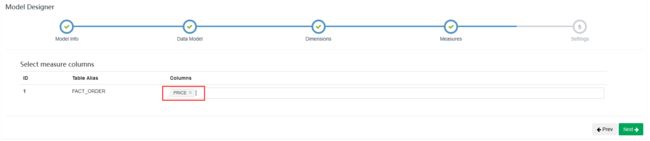
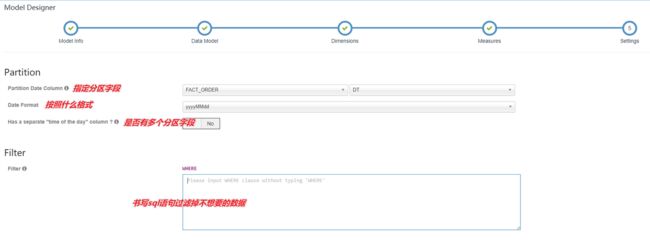
- 构建Cube(和之前的类似)
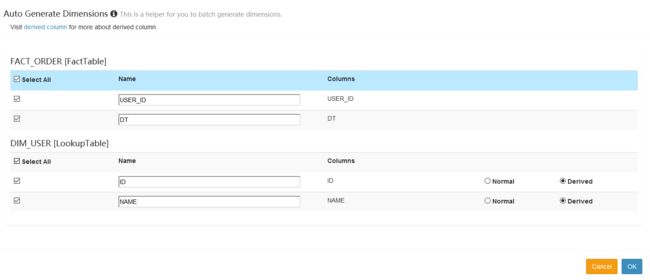
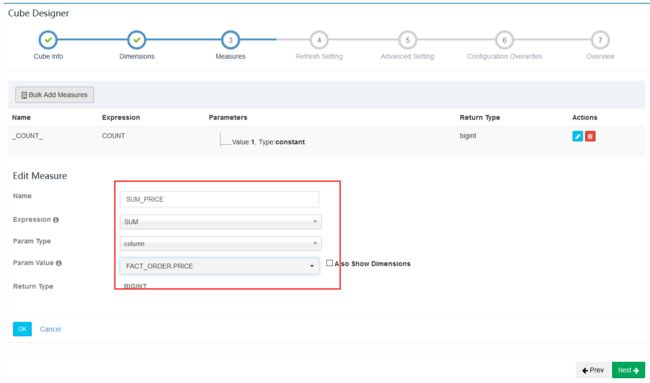
剩余全部下一步直到创建完成

-
执行测试
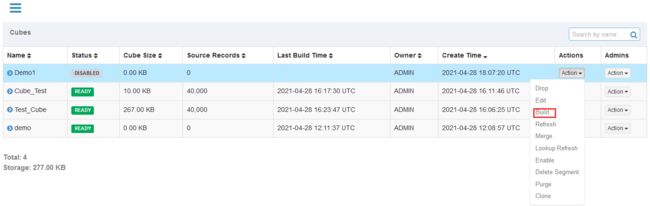
进行build弹窗填写开始时间,结束时间:构建20211011-20211012
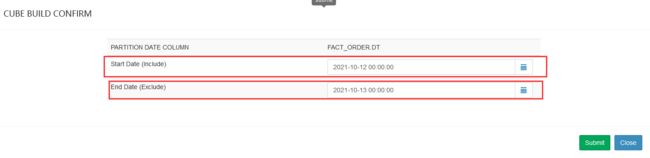
注意:这里不包含结束时间,起始时间(包含)、结束时间(不保存)
执行成功后,查看log
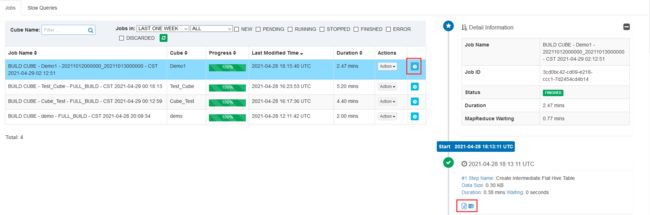
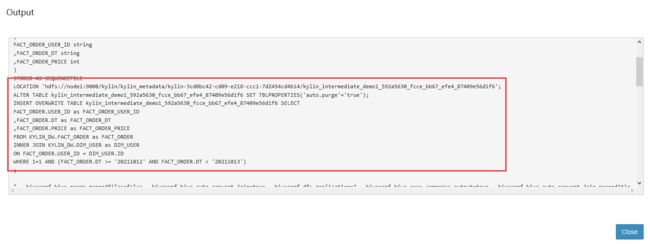
SQL日志
~~~
INSERT OVERWRITE TABLE kylin_intermediate_demo1_592a5630_fcce_bb67_efe4_87409e56d1f6 SELECT
FACT_ORDER.USER_ID as FACT_ORDER_USER_ID
,FACT_ORDER.DT as FACT_ORDER_DT
,FACT_ORDER.PRICE as FACT_ORDER_PRICE
FROM KYLIN_DW.FACT_ORDER as FACT_ORDER
INNER JOIN KYLIN_DW.DIM_USER as DIM_USER
ON FACT_ORDER.USER_ID = DIM_USER.ID
WHERE 1=1 AND (FACT_ORDER.DT >= '20211012' AND FACT_ORDER.DT < '20211013')
;
~~~
4. 查看Segment
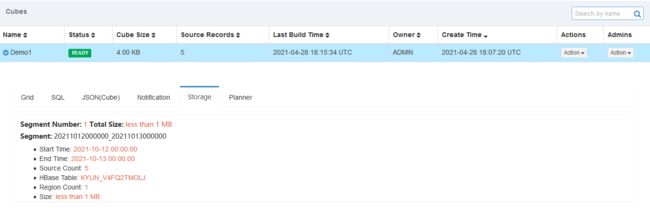
5. 构建 20211013、20211014的Cube数据

6. 查看增量构建Cube对应的Segment
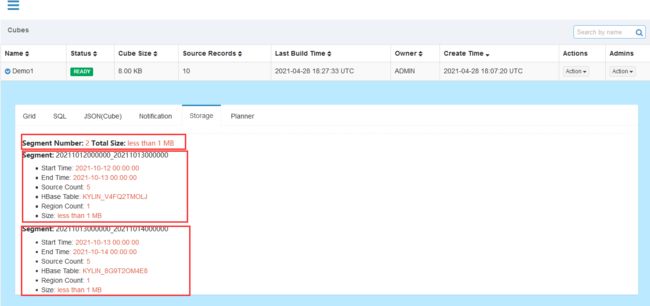
**问题**
~~~
增量构建有一个问题,我们一起来看看
通过页面查看cube中的storage看到有多个segment
一个segment对应Hbase一张表
每一次增量构建中在Hbase产生一张表,后面比如我要查询最近一个月或者最近多长时间的数据时候
这个时候你要扫描的为一天一个Hbase表,你要扫描的Hbsae表就比较多了,那这个时候一定会影响查询的性能
通过Cube碎片管理来弥补增量构建带来的问题,使用碎片管理就是减少segment的数量的
~~~
5.4 Cube碎片管理
增量构建的问题:
日积月累,增量构建的Cube中的Segment越来越多,该Cube的查询性能也会越来越慢,因为需要在单点的查询引擎中完成越来越多的运行时聚合。为了保持查询性能:
- 需要定期地将某些Segment合并在一起
- 或者让Cube根据Segment保留策略自动地淘汰那些不会再被查询到的陈旧Segment
管理Cube碎片
上述案例,每天都会生成一个Segment,对应就是HBase中的一张表。增量构建的Cube每天都可能会有新的增量。这样的Cube中最终可能包含上百个Segment,这将会导致Kylin性能受到严重的影响。
- 从执行引擎的角度来说,运行时的查询引擎需要聚合多个Segment的结果才能返回正确的查询结果
- 从存储引擎的角度来说,大量的Segment会带来大量的文件,给存储空间的多个模块带来巨大的压力,例如Zookeeper、HDFS Namenode等
因此,有必要采取措施控制Cube中Segment的数量。
5.4.1 手动触发合并Segment
Kylin提供了一种简单的机制用于控制Cube中Segment的数量:合并Segments。在Web GUI中选中需要进行Segments合并的Cube
操作步骤:
-
单击Action→Merge
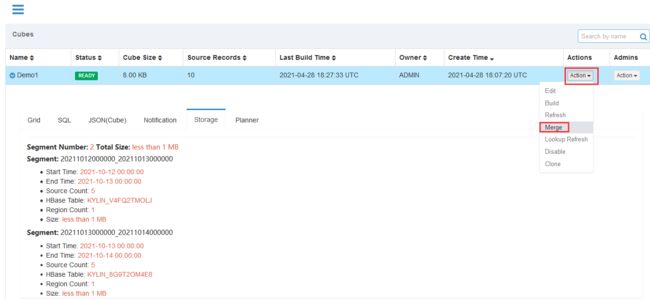
-
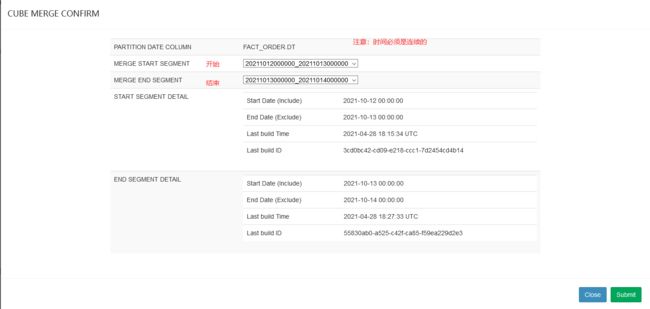
选中需要合并的Segment,可以同时合并多个Segment,但是这些Segment必须是连续的
单击提交后系统会提交一个类型为“MERGE”的构建任务,它以选中的Segment中的数据作为输入,将这些Segment的数据合并封装成为一个新的Segment。新的Segment的起始时间为选中的最早的Segment的起始时间,它的结束时间为选中的最晚的Segment的结束时间。

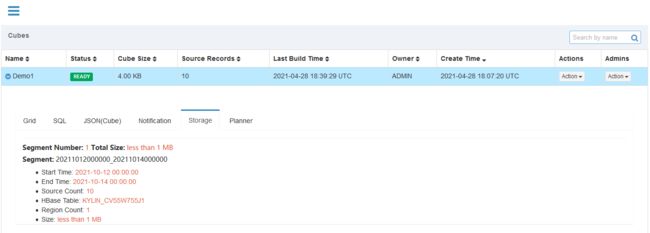
注意事项
在MERGE类型的构建完成之前,系统将不允许提交这个Cube上任何类型的其他构建任务 在MERGE构建结束之前,所有选中用来合并的Segment仍然处于可用的状态 当MERGE构建结束的时候,系统将选中合并的Segment替换为新的Segment,而被替换下的Segment等待将被垃圾回收和清理,以节省系统资源 -
删除Segment
使用WebUI删除Cube的segment
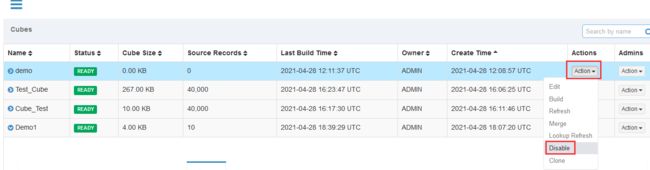
5.4.2 自动合并
手动维护Segment很繁琐,人工成本很高,Kylin中是可以支持自动合并Segment
在Cube Designer的“Refresh Settings”的页面中有:
- Auto Merge Thresholds
- Retention Threshold
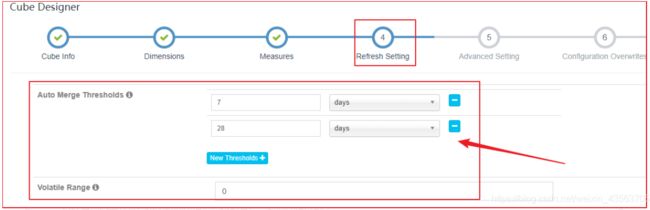
两个设置项可以用来帮助管理Segment碎片。这两项设置搭配使用这两项设置可以大大减少对Segment进行管理的麻烦。
5.4.3 Auto Merge Thresholds
- 允许用户设置几个层级的时间阈值,层级越靠后,时间阈值就越大
- 每当Cube中有新的Segment状态变为 READY的时候,会自动触发一次系统自动合并
- 合并策略
-
- 尝试最大一级的时间阈值,例如:针对(7天、28天)层级的日志,先检查能否将连续的若干个Segment合并成为一个超过28天的大Segment
- 如果有个别的Segment的时间长度本身已经超过28天,系统会跳过Segment
- 如果满足条件的连续Segment还不能够累积超过28天,那么系统会使用下一个层级的时间阈值重复寻找
示例1 - 理解Kylin自动合并策略
* 假设自动合并阈值设置为7天、28天
* 如果现在有A-H8个连续的Segment,它们的时间长度为28天(A)、7天(B)、1天(C)、1天(D)、1天(E)、1天(F)、1天(G)、1天(H)
* 此时,第9个Segment I加入,时间长度为1天。
自动合并策略为:
1、Kylin判断时候能将连续的Segment合并到28天这个阈值,由于Segment A已经超过28天,会被排除
2、剩下的连续Segment,所有时间加一起 B + C + D + E + F + G + H + I (7 + 1 + 1 + 1 + 1 + 1 + 1 + 1 = 14) < 28天,无法满足28天阈值,开始尝试7天阈值
3、跳过A(28)、B(7)均超过7天,排除
4、剩下的连续Segment,所有时间加一起 C + D + E + F + G + H + I(1 + 1 + 1 + 1 + 1 + 1 + 1 = 7)达到7天阈值,触发合并,提交Merge任务。并构建一个Segment X(7天)
5、合并后,Segment为:A(28天)、B(7天)、X(7天)
6、继续触发检查,A(28天)跳过,B + X(7 + 7 = 14)< 28天,不满足第一阈值,重新使用第二阈值触发
7、跳过B、X,尝试终止
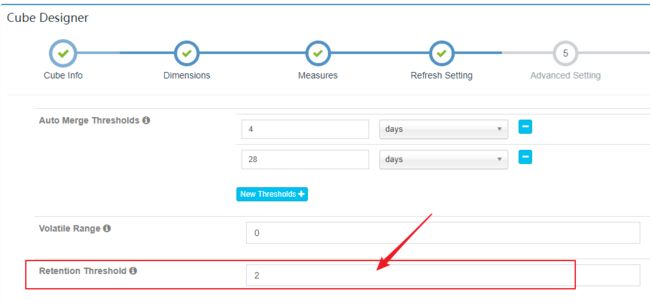
5.4.4 配置保留Segment
自动合并是将多个Segment合并为一个Segment,以达到清理碎片的目的。保留Segment则是及时清理不再使用的Segment
在很多场景中,只会对过去一段时间内的数据进行查询,例如:
- 对于某个只显示过去1年数据的报表
- 支撑它的Cube其实只需要保留过去一年类的Segment即可
- 由于数据在Hive中已经存在备份,则无需在Kylin中备份超过一年的历史数据
可以将Retention Threshold设置为365。每当有新的Segment状态变为READY的时候,系统会检查每一个Segment。如果它的结束时间距离最晚的一个Segment的结束时间已经大于等于“Retention Threshold”,那么这个Segment将被视为无需保留。系统会自动地从Cube中删除这个Segment

配置方式
6、Cube优化指南
为什么要进行剪枝优化?
在没有采取任何的优化措施的时候,Kylin会对每一个维度组合进行预计算,若有4个维度,则会有将近2^4 = 16个Cuboid需要进行计算。但是我们知道很多维度是:
1.不需要参与计算或者说不常用的
2.与其他的维度有一定的包含关系的
3.一定会跟其他维度一起进行查询的
如果有10个维度那会有2^10=1024个Cuboid需要进行计算,虽然每个Cuboid的大小存在很大的差异,但是单单想到Cuboid的数量就足以让人想象这样大小的Cube对于构建引擎、存储引擎的压力会有多么巨大,所以在构建维度较多的Cube时,剪枝优化是非常重要的。
6.1 使用衍生维度
即使用维度表的主键(也就是事实表的外键)来代替维度表的非主键维度,这种方式牺牲一部分运行时间性能来节省Cube的空间占用目的。
示例:
有两张表 用户维度表(dim_user)、订单事实表(fact_order),要根据各个维度建立MOLAP立方体
用户维度表(dim_user)
| ID | 姓名 | 出生年份 | 政治面貌 | 职业 | 性别 | 民族 | 省份 | 市 | 区 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 张三 | 1999 | 团员 | 程序员 | 男 | 汉族 | 北京 | 北京市 | 东城区 |
| 2 | 李四 | 1989 | 党员 | 学生 | 女 | 回族 | 北京 | 北京市 | 昌平区 |
| 3 | 王五 | 1990 | 党员 | 程序员 | 男 | 汉族 | 北京 | 北京市 | 昌平区 |
| 4 | 赵六 | 1997 | 党员 | 快递员 | 男 | 傣族 | 上海 | 上海市 | 闵行区 |
订单事实表(fact_order)
| 订单id | 用户ID | 价格 |
|---|---|---|
| O0001 | 1 | 1000 |
| O0002 | 1 | 2000 |
| O0003 | 3 | 3000 |
问题:
生成Cube时,如果指定维度表中的:姓名、出生年份、政治面貌、职业、性别、民族、省份、市、区等维度生成Cube,这些维度相互组合,会造成较大的Cube膨胀率
注意:
使用衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
| 衍生维度 |
|---|
| 姓名 |
| 出生年份 |
| 政治面貌 |
| 职业 |
| 性别 |
| 民族 |
| 省份 |
| 市 |
| 区 |
优化:
选择衍生维度

创建Cube的时候,这些维度如果指定为衍生维度,Kylin将会排除这些维度,而是使用维度表的主键来代替它们创建Cuboid。后续查询的时候,再基于主键的聚合结果,再进行一次聚合。
优化效果:维度表的N个维度组合成的cuboid个数会从2的N次方降为2。
不适用的场景:
- 如果从维度表主键到某个维度表维度所需要的聚合工作量非常大,此时作为一个普通的维度聚合更合适,否则会影响Kylin的查询性能
6.2 使用聚合组
聚合组假设一个Cube的所有维度均可以根据业务需求划分为若干组(或者一个组),由于同一组合内更有可能被同一查询到,因此会表现出更强大的内在关联
每一个组内,会包含三种可选的维度:
1.强制维度(Mandatory)
若为强制维度,则该分组中每一个Cubiod都会包含这个维度,若该维度一定会出现在查询中,则应当将其设置为强制维度
例如:
设置成强制维度。这样该聚合组产生的cuboid都要有这个维度。
打个比方,该聚合组里有a,b,c三个维度,将a设置成强制维度,则该聚合组会产生 a,ab,ac,abc 4种cuboid,
而不会产生b , c , bc 这三个cuboid,减少了3个。
2.层级维度(Hierachy)
每一个层级中应包含2-n个维度,这n个维度会以()、(N1)、(N1,N2)、…、(N1, N2,…,Nn)这N+1种情况进行组合
设置成层级维度。如果一个聚合组的维度中有层级关系,比如省--市--区--街道,就可以设置层级维度。
层级维度不允许子层级出现的时候父层级不出现,比如,你可以 group by 省,市 但是你不能 group by 市, 也不能 group by 省 ,区
举例,该聚合组有 a b c 三个维度 且设置成层级维度 a>b>c. 则该聚合组会产生 a, ab, abc 三个cuboid
不会产生 b,c,bc,ac 这4个cuboid,减少了4个。
3.联合维度(Joint)
每一个联合维度包括两个或者更多的维度,联合维度内的维度,要么不出现,要么必须一起出现。不同的联合之间不应当有共同的维度
设置成联合维度,这些维度要么一起出现,要么都不出现。
举例,该聚合组有 a b c 三个维度,且设置 ab为联合维度,则该聚合组会产生 c,ab,abc 三个cuboid
而不会产生 a,b ,ac,bc, 减少了4个。
4.粒度优化
粒度优化对应的是提高Cube的并发度,其设置是在自定义属性中的
一共有三个属性可以提高并发度。
1.kylin.hbase.region.cut(共使用几个分区)
2.kylin.hbase.region.count.min(最少使用几个分区)
3.kylin.hbase.region.count.max(最多使用几个分区)
根据相对应的情况调高最少使用分区,降低最大使用分区,能够有效增加系统的并行度。
5.(其他)RowKey优化
和Hbase 的RowKey优化类似
1.在查询的过程中,被用作过滤条件的维度可能放在其他维度的前面
2.经常出现的维度应该放在前面
3.基数比较大的维度应该放在前面
6.3 优化案例
需求:对膨胀数据进行调优
SQL准备
-- 创建订单数据库、表结构
create database if not exists `kylin_dw2`;
-- 1. 地理维度表
create table `kylin_dw2`.`dim_address`(
id int,
province string,
city string,
region string
)
row format delimited fields terminated by ',' stored as TEXTFILE;
-- 2. 时间维度表
create table `kylin_dw2`.`dim_date`(
year int,
quarter string,
month int,
day int
)
row format delimited fields terminated by ',' stored as TEXTFILE;
-- 3. 订单数据
create table `kylin_dw2`.`fact_order`(
orderId int,
price int,
province string,
city string,
region string,
year int,
month int,
day int
)
row format delimited fields terminated by ',' stored as TEXTFILE;
-- 加载数据文件
load data local inpath '/root/data_address.csv' overwrite into table `kylin_dw2`.`dim_address`;
load data local inpath '/root/data_date.csv' overwrite into table `kylin_dw2`.`dim_date`;
load data local inpath '/root/data_order.csv' overwrite into table `kylin_dw2`.`fact_order`;
进入KylinWeb界面
首先同步hive表到Kylin



创建Model

指定表关联

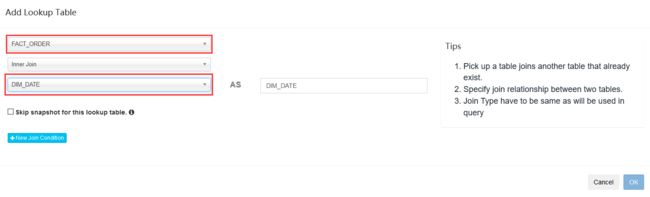
指定关联条件
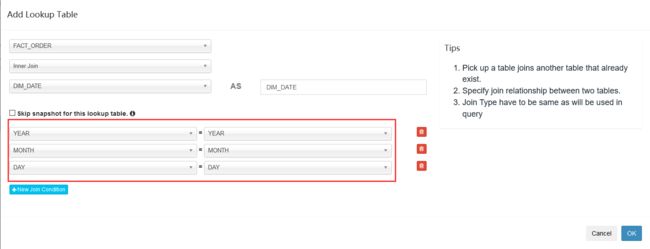
另一个表
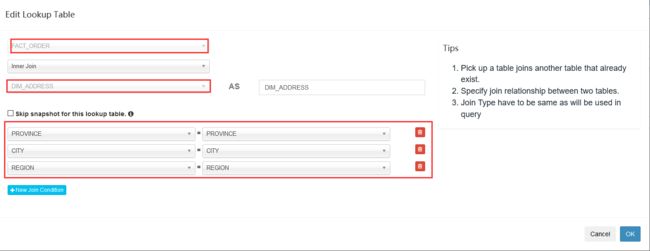
指定维度
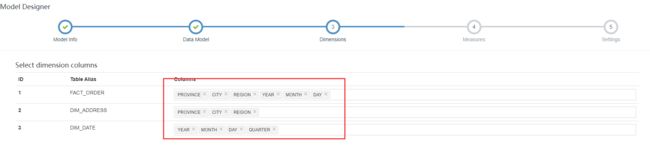
指定度量
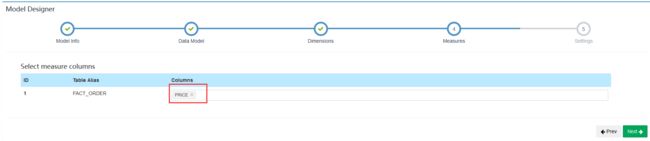
MOlde创建完毕

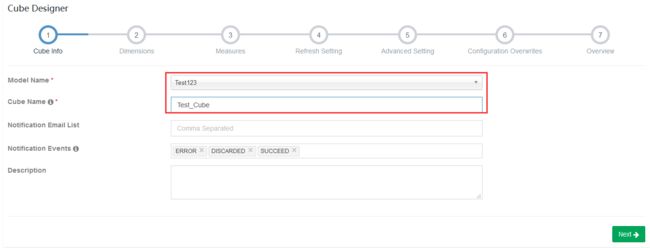
创建Cube
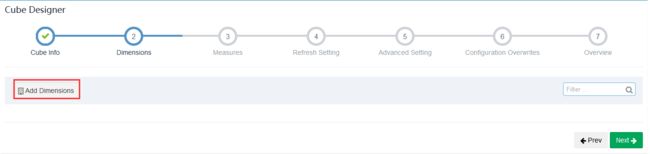
1 未优化方式

选择维度
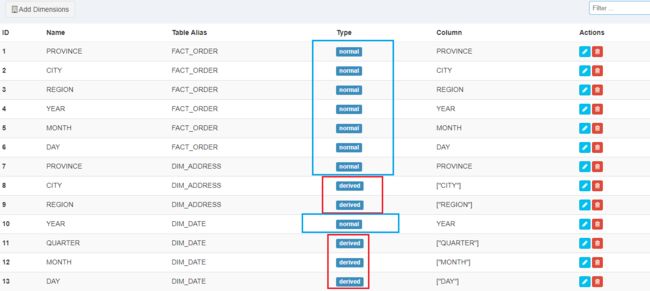
添加度量
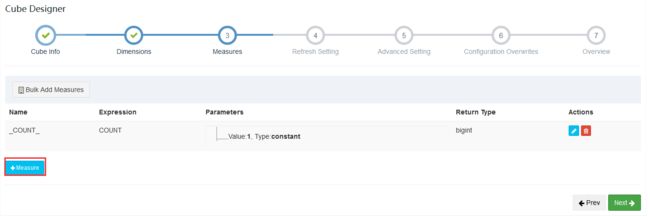
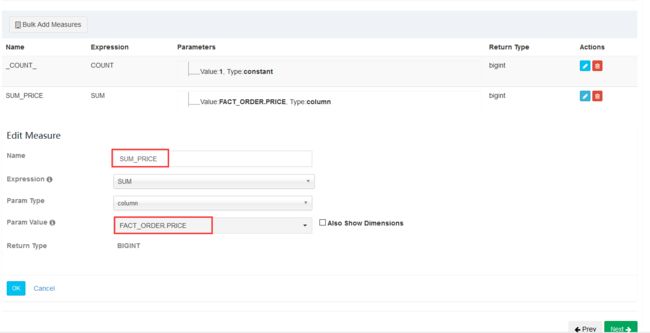
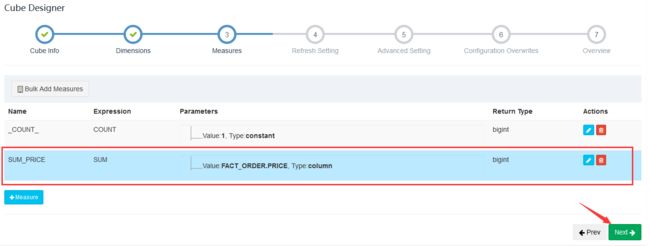
后续不用修改直接保存

2 优化后方式
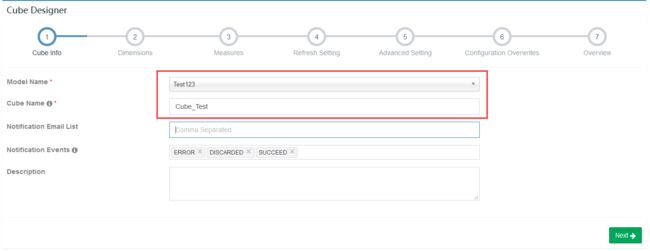
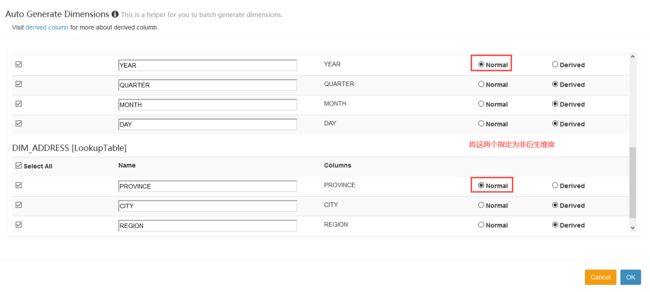
选择衍生维度
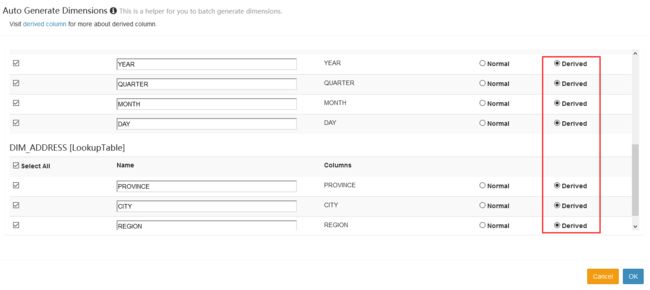
选择度量
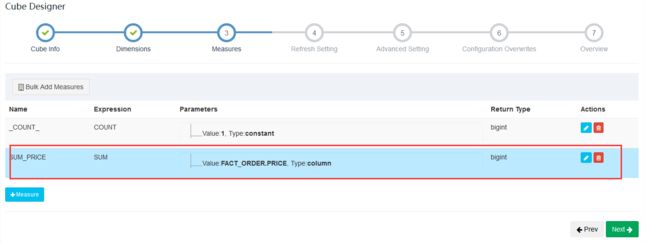
注意:指定聚合组:选择层级维度
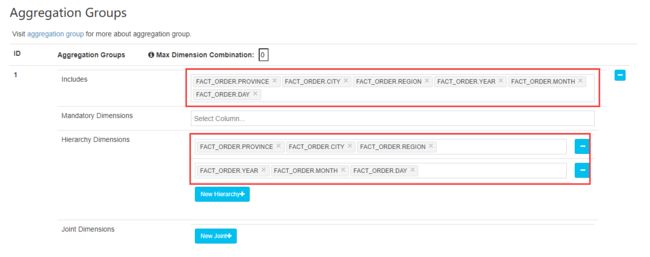
创建完成

3 执行测试
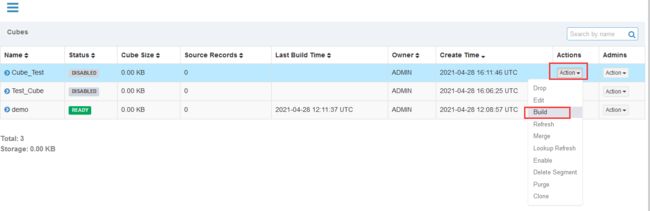
测试结果

查看cuboid数量
bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader CUBE_NAME
# CUBE_NAME 想要查看的Cube的名字
查询优化
./bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader Cube_Test

查询未优化
./bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader Test_Cube
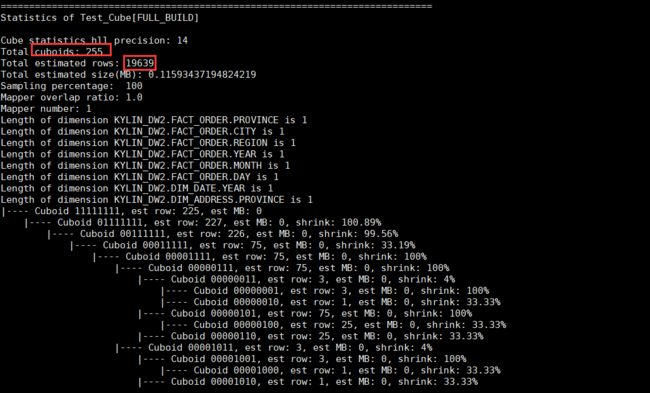
- 估计Cuboid大小的精度(Hll Precision)
- 总共的Cuboid数量
- Segment的总行数估计
- Segment的大小估计,Segment的大小决定mapper、reducer的数量、数据分片数量等
7、工具集成
JDBC集成
- 要将数据以可视化方式展示出来,需要使用Kylin的JDBC方式连接执行SQL,获取Kylin的执行结果
- 使用Kylin的JDBC与JDBC操作MySQL一致
- 用户名密码:ADMIN/KYLIN
需求:
通过JDBC方式,查询按照日期、区域、产品维度统计订单总额/总数量结果
创建工程导入Pom
org.apache.kylin
kylin-jdbc
2.5.1
代码
package com.qf;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class KylinTest {
public static void main(String[] args) throws Exception {
//Kylin_JDBC 驱动
String KYLIN_DRIVER = "org.apache.kylin.jdbc.Driver";
//Kylin_URL 连接字符串:jdbc:kylin://ip地址:7070/项目名称(project)
String KYLIN_URL = "jdbc:kylin://node1:7070/tt";
//Kylin的用户名
String KYLIN_USER = "ADMIN";
//Kylin的密码
String KYLIN_PASSWD = "KYLIN";
//添加驱动信息
Class.forName(KYLIN_DRIVER);
//获取连接
Connection connection = DriverManager.getConnection(KYLIN_URL, KYLIN_USER, KYLIN_PASSWD);
//预编译SQL
PreparedStatement ps = connection.prepareStatement("select * from kylin_dw.dim_user");
//执行查询
ResultSet resultSet = ps.executeQuery();
//遍历打印
while (resultSet.next()) {
System.out.println(resultSet.getString(1)+" "+resultSet.getString(2));
}
}
}
结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oQ6bH7Xd-1654304435850)(Kylin.assets/1620384050310.png)]
import java.sql.ResultSet;
public class KylinTest {
public static void main(String[] args) throws Exception {
//Kylin_JDBC 驱动
String KYLIN_DRIVER = “org.apache.kylin.jdbc.Driver”;
//Kylin_URL 连接字符串:jdbc:kylin://ip地址:7070/项目名称(project)
String KYLIN_URL = “jdbc:kylin://node1:7070/tt”;
//Kylin的用户名
String KYLIN_USER = “ADMIN”;
//Kylin的密码
String KYLIN_PASSWD = “KYLIN”;
//添加驱动信息
Class.forName(KYLIN_DRIVER);
//获取连接
Connection connection = DriverManager.getConnection(KYLIN_URL, KYLIN_USER, KYLIN_PASSWD);
//预编译SQL
PreparedStatement ps = connection.prepareStatement(“select * from kylin_dw.dim_user”);
//执行查询
ResultSet resultSet = ps.executeQuery();
//遍历打印
while (resultSet.next()) {
System.out.println(resultSet.getString(1)+" "+resultSet.getString(2));
}
}
}
结果
[外链图片转存中...(img-oQ6bH7Xd-1654304435850)]