字符串 - 正则表达式
文章目录
- 1、不可变 String
-
-
- 1.1 String 对象为什么不可变?
- 1.2 不可变有什么好处?
-
- 2、“+” 和 concat()
- 3、StringBuilder 和 StringBuffer(字符串变量)
- 4、格式化输出
-
-
- 4.1 printf() 与 System.out.format()
- 4.2 Formatter 类
-
-
- 4.2.1 格式化说明符
- 4.2.2 Formatter 转换
-
- 4.3 String.format()
-
- 5、正则表达式
-
-
- 5.1 正则表达式语法
- 5.2 Pattern 类
-
-
- 5.2.1 Pattern.compile() 和 Pattern.split()
- 5.2.2 Pattern.matches()
- 5.2.3 Pattern.matcher()
-
- 5.3 Matcher 类
-
-
- 5.3.1 Matcher.matches() 与 Matcher.lookingAt()
- 5.3.2 Matcher.find() 与 Matcher.start()、Matcher.end()、Matcher.group()
- 5.3.3 组(Groups)
- 5.3.4 替换操作
- 5.3.5 reset()
-
- 5.4 示例
-
-
- 5.4.1 常用的正则表达式
- 5.4.2 正则表达式匹配邮箱
-
-
- 6、Scanner 扫描输入
-
-
- 6.1 Scanner 定界符
- 6.2 用正则表达式扫描
-
1、不可变 String
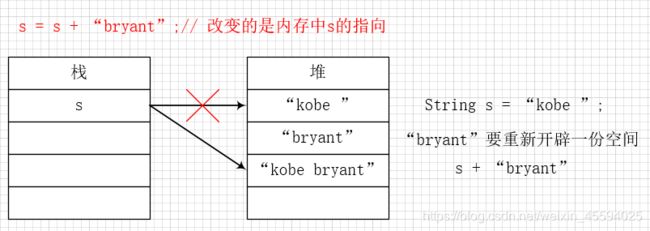
String 对象是不可变的。String 类中每一个看起来会修改 String 值的方法,实际上都是创建了一个全新的 String 对象,以包含修改后的字符串内容,而最初的 String 对象丝毫未动。
下图为对字符串进行操作时内存的变化:
1.1 String 对象为什么不可变?
String 类由 final 修饰,使得 String 类不能被继承;实际存储字符串的是一个 char 类型的数组,也由 final 修饰,分配空间之后内存地址不变;涉及这个数组的操作都使用了拷贝数组元素的方法,就保证了不能在内部修改字符数组。所以 String 对象在初始化之后是不可变的。
1.2 不可变有什么好处?
- String 对象都放在字符串常量池中,创建一个 String 对象时,先检查有没有这个对象,有的话就直接拿来用,没有的话再创建,可以节省堆空间。
- String 对象的哈希码被频繁使用,字符串不变性保证了 hash 码的唯一性,可以放心的进行缓存,也就意味着不用每次都计算新的 hash 码。
- String 被许多 Java 类库用来做参数,比如url、文件路径等,假设 String 对象是可变的,会有安全隐患。
2、“+” 和 concat()
为 String 对象重载的 “+” 操作符可以用来连接字符串,比如:
String s = "kobe";
String name = s + "bryant";
编译器在使用 “+” 连接字符串时,自动引入了 java.lang.StringBuilder 类,通过该类的 append() 方法完成字符串的拼接,因为 StringBuilder 更高效。
String 类的 concat() 方法也能实现字符串的拼接,例如:
String s1 = "Kobe ";
String s2 = "Bryant";
String s = s1.concat(s2);
System.out.println(s);
输出:
Kobe Bryant
concat() 是 String 类提供的方法,使用的是 String 类的内部实现。
简单的字符串操作,使用 “+” 或者 concat() 就可以;如果要进行的字符串操作比较复杂(比如可能使用到循环),那最好创建一个 StringBuilder 对象,用它来构造最终的结果。
3、StringBuilder 和 StringBuffer(字符串变量)
StringBuilder 类是 Java SE5 引入的,在这之前 Java 用的是 StringBuffer。两个类的方法相似,用法也相同。不同之处在于 StringBuffer 是线程安全的,因此开销大些。多数情况下都使用 StringBuilder 类,速度快,效率高。
除了 append() 方法,StringBuilder 类还提供了 insert()、replace()、substring()、reverse()、delete() 等方法,方便字符串的操作,并且可以通过 toString() 方法将其转换为 String 对象。
4、格式化输出
Java SE5 推出了 C 语言中 printf() 风格的格式化输出这一功能。
4.1 printf() 与 System.out.format()
printf() 并不使用重载的 “+” 操作符来连接字符串,而是使用特殊的占位符来表示要连接的数据的位置,然后将要插入字符串的参数,用逗号隔开,跟在后面。
例如,想把两个数 x x x、 y y y 以 “[x y]” 的形式打印输出,就可以用如下语句实现:
System.out.printf("[%d %f]", x, y);
这一行代码在运行的时候,先将 x x x 插入到 %d 的位置,然后将 y y y 插入到 %f 的位置,\n 表示换行。引号中的 %d 和 %f 就是占位符,也叫格式修饰符,它们不仅说明了插入数据的位置,还说明了插入数据的类型(%d 表示 x x x 是一个整数,%f 表示 y y y 是一个浮点数)。
Java SE5 引入的 format() 方法与 printf() 等价。它们只需要一个简单的格式化字符串,加上一串参数即可,每个参数对应一个占位符。
示例:
public class SimpleFormat {
public static void main(String[] args) {
int x = 5;
double y = 3.141592;
System.out.println("[" + x + " " + y + "]");
System.out.printf("[%d %f]\n", x, y);
System.out.format("[%d %f]\n", x, y);
}
}
输出:
[5 3.141592]
[5 3.141592]
[5 3.141592]
4.2 Formatter 类
在 Java 中,新的格式化功能由 java.util.Formatter 类处理。创建一个 Formatter 对象时要向其构造器传递一个参数,该参数说明了最终的结果向哪里输出。之后通过该对象调用 format() 方法对字符串进行格式化。
示例:
public class SimpleFormatter {
public static void main(String[] args) {
// 将结果输出至 System.out
Formatter f1 = new Formatter(System.out);
f1.format("Number %d is %s!\n", 24, "kobe");
f1.format("Number %d is %s!\n", 23, "jordan");
// 使用 PrintStream、OutputStream、File 等
PrintStream out = System.out;
Formatter f2 = new Formatter(out);
f2.format("Number %d is %s!\n", 3, "pual");
f2.format("Number %d is %s!\n", 30, "curry");
}
}
输出:
Number 24 is kobe!
Number 23 is jordan!
Number 3 is pual!
Number 30 is curry!
4.2.1 格式化说明符
通过在 format() 中的格式化字符串中添加空格,来确保一个域至少达到某个长度。例如:
Formatter f1 = new Formatter(System.out);
f1.format("Number %d is %s!\n", 24, "kobe");
f1.format("Number %d is %s!\n", 23, "jordan");
// 输出
Number 24 is kobe!
Number 23 is jordan!
如果想要更好地控制空格与对齐,就需要更加精细复杂的占位符。这里给出一个抽象语法:
% [ f l a g s ] [ w i d t h ] [ . p r e c i s i o n ] c o n v e r s i o n \%[flags][width][.precision]conversion %[flags][width][.precision]conversion
- flags 标志位:默认情况下,数据是右对齐;如果 flags 设置为 “-”,就是左对齐;
- width:指明一个域的最小尺寸;
- .precision:指明一个域的最大尺寸;
- conversion:指明数据类型。
注意:
- width 可以应用于各种类型的数据转换。比如,应用于字符串时,表示字符串的长度;应用于整数时,表示整数的位数。
- precision 和 width 使用方式一样,但不是所有的类型都可以用 precision。比如,应用于字符串时,表示输出字符的最大数量;应用于浮点数时,表示小数点后要显示的数的位数(默认是 6 位小数),如果小数位数过多则舍入,太少则在末尾补零;整数没有小数部分,所以 precision 不能用于整数。
看两个例子:
- “%-15s” :"-" 表示左对齐,“s” 表示该占位符对应的数据是字符串,“15” 表示字符串的长度为 15;
- “%10.2f” :没有 flags 位,那就是默认的右对齐,“f” 表示该占位符对应的数据是浮点数,“10” 表示整数部分有十位,".2" 表示小数点后保留两位。
示例,打印一份收据:
public class Receipt {
public static void main(String[] args) {
Formatter f = new Formatter(System.out);
// 表头
f.format("%-10s %5s %10s\n", "Item" , "Qty", "Price");
f.format("%-10s %5s %10s\n", "----" , "---", "-----");
// 内容
f.format("%-10s %5d %10.2f\n", "basketball" , 1, 230.00);
f.format("%-10s %5d %10.2f\n", "bag" , 2, 50.0000);
f.format("%-10s %5d %10.2f\n", "pen" , 3, 7.5);
}
}
// 输出:
Item Qty Price
---- --- -----
basketball 1 230.00
bag 2 50.00
pen 3 7.50
4.2.2 Formatter 转换
Formatter 常用的类型转换有:
- %:字符 “%”;
- d:整数型(十进制);
- c:Unicode 字符;
- b:布尔值;
- s:String;
- e:浮点数(科学计数);
- x:整数(十六进制);
- h:散列码;
示例:
public class Conversion {
public static void main(String[] args) {
Formatter f = new Formatter(System.out);
int i = 65;
f.format("d: %d\n", i);
f.format("s: %s\n", i);
f.format("b: %b\n", i);
f.format("c: %c\n", i);
f.format("h: %h\n", i);
System.out.println("=============");
char u = 'a';
f.format("s: %s\n", u);
f.format("b: %b\n", u);
f.format("c: %c\n", u);
}
}
// 输出
d: 65
s: 65
b: true
c: A
h: 41
=============
s: a
b: true
c: a
4.3 String.format()
String.format() 是一个 static 方法,它接受与 Formatter.format() 方法一样的参数,但返回一个 String 对象。如果你只需要使用 format() 方法一次,使用 String.format() 更方便。
5、正则表达式
5.1 正则表达式语法
不同语言中的正则表达式都有一些细微的区别。在其它语言中,\\ 表示“我想在正则表达式中插入一个普通的(字面上的)反斜线,请不要给它任何特殊意义。” 而在 Java 中,\\ 的意思是“我要插入一个正则表达式的反斜线,所以其后的字符具有特殊意义。” 例如,如果你想表示一位数字,那么正则表达式应该是 \\d;如果你想插入一个普通的反斜线,则应该这样 \\\\。不过,换行符和制表符之类的东西只需使用单反斜线:\n、\t。
下面列出一些常用的正则表达式,要了解更多的正则表达式,可以参考 JDK 文档中的 java.util.regex.Pattern 类。
(1)字符:
| - | - |
|---|---|
| X | 指定字符 X |
| \t | 制表符 Tab |
| \n | 换行符 |
| \r | 回车 |
| \f | 换页 |
(2)边界匹配符:
| - | - |
|---|---|
| ^ | 一行的开始 |
| $ | 一行的结束 |
| \b | 词的边界 |
| \B | 非词的边界 |
| \G | 前一个匹配的结束 |
(3)逻辑操作符
| - | - |
|---|---|
| XY | Y 跟在 X 后面 |
| X|Y | X 或 Y |
(4)字符类:
| - | - |
|---|---|
| . | 匹配任意字符 |
| [abc] | 匹配包含 a、b 和 c 的任何字符(和 a|b|c 作用相同)。例如,[abc] 匹配 “kobe” 中的 “b”。 |
| [^abc] | 匹配除了 a、b 和 c 之外的任何字符(否定)。例如,[^abc] 匹配 “kobe” 中的 “k”、“o”、“e”。 |
| [a-zA-Z] | 匹配从 a 到 z 或从 A 到 Z 的任何字符(范围) |
| [abc[hij]] | 匹配任意 a、b、c、h、i 和 j 字符(与 a|b|c|h|i|j 作用相同)(合并) |
| [a-z&&[hij]] | 匹配任意 h、i 和 j(相当于 a-z 和 [hij] 的交集) |
| \s | 空白符(空格、Tab、回车、换行和换页) |
| \S | 非空白符([^\s]) |
| \d | 数字[0-9] |
| \D | 非数字[^0-9] |
| \w | 词字符[a-zA-Z0-9] |
| \W | 非词字符[^\w] |
(5)量词:
| 量词 | 如何匹配 |
|---|---|
| X? | 匹配一个或零个 X。例如,do(es)? 与 “do” 和 “does” 匹配。 |
| X* | 匹配零个或多个 X。例如,zo* 与 “z” 和 “zoo” 匹配。 |
| X+ | 匹配一个或多个 X。例如,zo+ 与 “zo” 和 “zoo” 匹配,但与 “z” 不匹配。 |
| X{n} | 匹配恰好 n 次 X。例如,o{2} 与 “food” 中的两个 “o” 匹配,但与 “Bob” 中的一个 “o” 不匹配。 |
| X{n,} | 匹配至少 n 次 X。例如,o{2,} 与 “fooooood” 中的 “o” 匹配,但与 “Bob” 中的一个 “o” 不匹配。 |
| X{n,m} | 匹配 X 至少 n 次,且不超过 m 次。 |
注意:
- 通常,用圆括号将正则表达式的各部分括起来,以免混淆。例如:abc+ 和 (abc)+。abc+ 表示:匹配 ab,后面跟随 1 各 或多个 c;(abc)+ 表示:匹配 1 个或多个 abc 序列。
5.2 Pattern 类
调用 java.util.regex 包下的 Pattern 类和 Matcher 类,我们能够构造出功能强大的正则表达式对象。
5.2.1 Pattern.compile() 和 Pattern.split()
Pattern 类用于创建一个正则表达式对象,但它的构造器是私有的,要通过 Pattern.compile(String regex) 方法创建一个正则表达式对象。该方法是 static 方法,它会根据传入的 String 类型的正则表达式生成一个 Pattern 对象。
Pattern 类的 split(CharSequence input) 方法从匹配正则表达式的地方分割输入字符串,并返回分割后的字符串数组。String.split() 方法就是通过 Pattern.split() 方法实现的。
示例:
public class PatternTest {
public static void main(String[] args) {
// 从匹配多个数字的地方分割输入字符串
Pattern p = Pattern.compile("\\d+");
String[] strings = p.split("2020年7月25日");
for(String s : strings){
System.out.println(s);
}
}
}
// 输出:
年
月
日
5.2.2 Pattern.matches()
Pattern.matches(String regex, CharSequence input) 是一个静态方法,返回布尔值,用以检查 regex 是否匹配整个 input 参数。该方法适合用于只匹配一次,且匹配全部字符串。
示例:
Pattern.matches("\\d+", "24"); // true
Pattern.matches("\\d+", "kobe24"); // false:不能匹配到 “kobe”
5.2.3 Pattern.matcher()
Pattern 类只能做一些简单的匹配操作,要向得到更强的正则匹配操作,就要将 Pattern 与 Matcher 一起合作使用。
Pattern.matcher(CharSequence input) 方法返回一个 Matcher 对象。Matcher 类的构造方法也是私有的,只能通过 Pattern.matcher(CharSequence input) 方法得到该类的实例。如:
Pattern p = Pattern.compile("\\d+");
Matcher m = p.matcher("223344");
再通过 m 调用 Matcher 类的各种方法进行正则匹配。
5.3 Matcher 类
5.3.1 Matcher.matches() 与 Matcher.lookingAt()
两个匹配方法均返回 boolean 类型。匹配成功返回 true,匹配失败返回 false。
- matches(): 判断输入字符串是否匹配正则表达式;
- lookingAt(): 判断输入字符串的开始部分是否匹配正则表达式;
示例一:matches()
// 匹配词字符
Pattern p = Pattern.compile("\\w+");
Matcher m1 = p.matcher("kobe");
System.out.println(m1.matches()); // true
Matcher m2 = p.matcher("24");
System.out.println(m2.matches()); // true
Matcher m3 = p.matcher("''");
System.out.println(m3.matches()); // false
示例二:lookingAt()
// 判断字符串是否以词字符开头
Pattern p1 = Pattern.compile("\\w+");
Matcher m4 = p.matcher("kobe bryant");
System.out.println(m4.lookingAt());
Matcher m5 = p.matcher("@163");
System.out.println(m5.lookingAt());
5.3.2 Matcher.find() 与 Matcher.start()、Matcher.end()、Matcher.group()
- Matcher.find(): 在输入字符串中查找多个匹配,它就像迭代器那样向前遍历输入字符串;如果匹配成功,则可以通过 group()、start() 和 end() 方法获取更多信息。
- Matcher.find(int index): find() 方法也接收一个整数参数,该参数表示字符串中字符的位置,并以其作为搜索的起点;
- Matcher.group(): 返回前一次匹配到的子字符串;
- Matcher.start(): 匹配成功后, start() 返回先前匹配的起始位置的索引;
- Matcher.end(): 匹配成功后,end() 返回所匹配的最后字符的索引加一的值。
示例:
public class Matcher_find {
public static void main(String[] args) {
String s = "how are you";
Pattern p = Pattern.compile("[a-z]+");
Matcher m = p.matcher(s);
// find() 与 start()、end()、group() 测试
while(m.find()){
System.out.println(m.group() + " start = " + m.start() + " end = " + m.end());
}
System.out.println();
// find(i) 测试
int i = 0;
while(m.find(i)){
System.out.print(m.group() + " ");
i++;
}
}
}
// 输出:
how start = 0 end = 3
are start = 4 end = 7
you start = 8 end = 11
how ow w are are re e you you ou u
注:
find(int index) 会以传入的 index 作为搜索的起点。例如,匹配 “how” 的时候,刚开始 i=0,从 “h” 位置开始搜索,因此返回 “how” 这个 group;接着 i++,第二次搜索时从 “o” 位置开始搜索,因此返回 “ow” 这个 group… … 所以,find(int index) 方法能根据其参数的值,不断重新设定搜索的起始位置。
5.3.3 组(Groups)
上面用到的 group() 方法就是 组 的一个方法。
组 是用括号划分的正则表达式,可以根据编号来引用某个组。组号为 0 表示整个表达式,组号为 1 表示被第一对括号括起来的组,依次类推。例如,表达式 A(B(C))D 中有三个组:组 0 是 ABCD,组 1 是 BC,组 2 是 C。
Matcher 对象提供了一系列方法,用以获取与组有关的信息:
- public int groupCount(): 返回该匹配器的模式中的分组数目,第 0 组不包括在内;
- public String group(): 返回前一次匹配操作的第 0 组(即整个匹配);
- public String group(i): 返回在前一次匹配操作期间指定组号的组;
- public int start(i): 返回在前一次匹配操作中寻找到的组的起始索引;
- public int end(i): 返回在前一次匹配操作中寻找到的组的最后一个字符的索引加一的值。
示例:
public class GroupTest {
public static void main(String[] args) {
String s = "m24kobe";
String regex = "\\w(\\d\\d)(\\w+)";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(s);
if(m.find()){
for(int i = 0; i <= m.groupCount(); i++){
System.out.println("group " + i + ": " + m.group(i) +
", m.start(" + i + ") = " + m.start(i) +
", m.end(" + i + ") = " + m.end(i));
}
}
}
}
// 输出:
group 0: m24kobe, m.start(0) = 0, m.end(0) = 7
group 1: 24, m.start(1) = 1, m.end(1) = 3
group 2: kobe, m.start(2) = 3, m.end(2) = 7
5.3.4 替换操作
- replaceFirst(String replacement): 以参数字符串 replacement 替换第一个匹配成功的部分;
- replaceAll(String replacement): 以参数字符串 replacement 替换所有匹配成功的部分。
示例:
public class ReplaceTest {
public static void main(String[] args) {
String regex = "[a-z]+";
String s = "pual 3 pual 3 pual 3";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(s);
System.out.println("source: " + s);
String s1 = m.replaceFirst("wade");
System.out.println("replaceFirst: " + s1);
String s2 = m.replaceAll("wade");
System.out.println("replaceAll: " + s2);
}
}
// 输出:
source: pual 3 pual 3 pual 3
replaceFirst: wade 3 pual 3 pual 3
replaceAll: wade 3 wade 3 wade 3
5.3.5 reset()
通过 reset() 方法,可以将现有的 Matcher 对象应用于一个新的字符序列。
示例:
public class ResetTest {
public static void main(String[] args) {
String regex = "[a-zA-Z]+";
String s = "Just do it!!!";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(s);
while(m.find()){
System.out.print(m.group() + " ");
}
System.out.println();
m.reset("Anything is possible!");
while(m.find()){
System.out.print(m.group() + " ");
}
}
}
// 输出:
Just do it
Anything is possible
5.4 示例
5.4.1 常用的正则表达式
(1)数字:
^-?\\d+$:整数^-?\\d+$:正整数^\\d+$:非负整数
5.4.2 正则表达式匹配邮箱
合法的 E-mail 地址要求:
- 有且只有一个 “@” 符号;
- 开头和结尾必须是词字符,不能出现 “@” 或者 “.” 之类的特殊字符;
- “@” 前后不能直接与特殊字符相连,比如不能出现 “@.” 或者 “.@”;
- “@” 前后的字符串中可以有 “_”、“.” 之类的字符;
- “@” 之后的字符串表示域名,最多三级,如 “@163.com.cn”。
示例:
public class EmailTest {
public static void main(String[] args) {
// 邮箱测试集
String[] emails = {"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]", // 点开头
"[email protected].", // 点结尾
"[email protected]", // @后是点
"[email protected]", // @前是点
"z_k.@163com", // 没有点
"[email protected]", // 连续两个点
};
/**
* 正则表达式
*
* \\w+:表示多个词字符开头;
* (\\w|[.]\\w)+:表示中间可以只有词字符,也可以有 .词字符 的组合;
* @\\w+:表示 @ 之后紧跟的是词字符;
* ([.]\\w+){1,3}:表示以 .词字符 结尾,表示域名
*/
String regex = "^\\w+(\\w|[.]\\w)+@\\w+([.]\\w+){1,3}$";
for(int i = 0; i < emails.length; i++){
if(emails[i].matches(regex)){
System.out.println(emails[i] + " ===》 " + emails[i].matches(regex));
}else{
System.out.println(emails[i] + " ===》 " + emails[i].matches(regex));
}
}
}
}
// 输出:
zk@163.com ===》 true
z_k@163.com ===》 true
zk.24@163.com ===》 true
zk.24.manba@163.com.cn ===》 true
.zk.24@163.com.cn ===》 false
.zk.24@163.com.cn. ===》 false
z_k@.163.com ===》 false
z_k.@163.com ===》 false
z_k.@163com ===》 false
z_k.@163..com ===》 false
6、Scanner 扫描输入
java.io 可以完成从文件或标准输入读取数据,Java SE5 新增了 Scanner 类,大大减轻了扫描输入的工作负担。
Scanner 的构造器可以接收任何类型的输入对象,包括 File 对象、InputStream 以及 String 等等。有了 Scanner,所有的输入、分词以及翻译的操作都隐藏在不同类型的 next 方法中:
- 普通的 next() 方法返回下一个 String;
- 所有的基本数据类型(除 char 之外)都有对应的 next 方法,如 nextInt()、nextByte()、nextDouble() 等等;
- 所有的 next 方法,只有在找到一个完整的分词之后才会返回;
- hasNext() 方法用以判断下一个输入分词是否所需的类型;
- 默认情况下,Scanner 根据空白字符对输入进行分词。
示例:
public class ScannerTest {
public static void main(String[] args) {
Scanner scanner = new Scanner("1 2 3 4 5");
while(scanner.hasNext()){
System.out.println(scanner.nextInt());
}
}
}
// 输出:
1
2
3
4
5
6.1 Scanner 定界符
默认情况下,Scanner 根据空白字符对输入进行分词。也可以用正则表达式指定自己所需的定界符,使用 useDelimiter(String pattern) 方法来设置定界符。
示例:
public class ScannerTest {
public static void main(String[] args) {
Scanner scanner = new Scanner("kobe, pual, curry, jordan");
// 使用逗号(以及逗号前后任意的空白字符)作为定界符
scanner.useDelimiter("\\s*,\\s*");
while(scanner.hasNext()){
System.out.println(scanner.next());
}
}
}
// 输出:
kobe
pual
curry
jordan
6.2 用正则表达式扫描
除了能够扫描基本类型外,我们还可以使用自定义的正则表达式进行扫描。下面的例子将扫描一个防火墙日志文件中记录的威胁数据:
public class ThreatAnalyze {
static String threatData = "58.27.82.161@02/10/2020\n" +
"58.27.82.161@02/10/2020\n" +
"204.45.234.40@02/10/2020\n" +
"58.27.82.161@02/10/2020\n" +
"58.27.82.161@02/10/2020\n";
public static void main(String[] args) {
Scanner scanner = new Scanner(threatData);
String pattern = "(\\d+[.]\\d+[.]\\d+[.]\\d+)@(\\d{2}/\\d{2}/\\d{4})";
while(scanner.hasNext(pattern)){
scanner.next(pattern);
MatchResult match = scanner.match();
String ip = match.group(1);
String date = match.group(2);
System.out.format("Threat on %s from %s\n", date, ip);
}
}
}
// 输出:
Threat on 02/10/2020 from 58.27.82.161
Threat on 02/10/2020 from 58.27.82.161
Threat on 02/10/2020 from 204.45.234.40
Threat on 02/10/2020 from 58.27.82.161
Threat on 02/10/2020 from 58.27.82.161
注:
- 示例中用到了 next(String pattern) 方法。当 next() 方法配合指定的正则表达式使用时,将找到下一个匹配该模式的输入部分,调用 match() 方法就可以获得匹配的结果。