python数据挖掘基础环境安装和使用
文章目录
- 一.安装python环境
- 二、库的安装
-
- 2.1 使用pip命令安装virtualenvv
-
- 扩展:cmd无法使用pip,报错:Fatal error in launcher: Unable to create process using ...
- 2.2 安装virtualenvwrapper-win
- 2.3 新建一个用于人工智能环境的虚拟环境
-
- 2.3.1 windows下 python 使用 pip 安装TA-Lib报错的原因及解决方法
-
- 离线安装TA_Lib 报错:whl is not a supported wheel on this platform.
-
- 解决办法
- 2.3.2 扩展:查看Python安装路径方法
- 三、Jupyter Notebook使用
-
- 3.1 为什么要用Jupyter Notebook?
- 3.2 Jupyter Notebook的使用
-
- 3.2.1 界面启动
- 3.2.2 创建文件
- 3.2.3 cell操作
- 3.2.3 markdown演示
完成数据挖掘基础阶段的所有环境安装
应用jupyter notebook完成代码编写运行
一.安装python环境
1.可以去官网下载:https://www.python.org/downloads/windows/
2.可以参考我另一篇文章https://blog.csdn.net/weixin_59633478/article/details/130816658
安装成功了,我的是Windows 11 ,下载的python3.11.3。
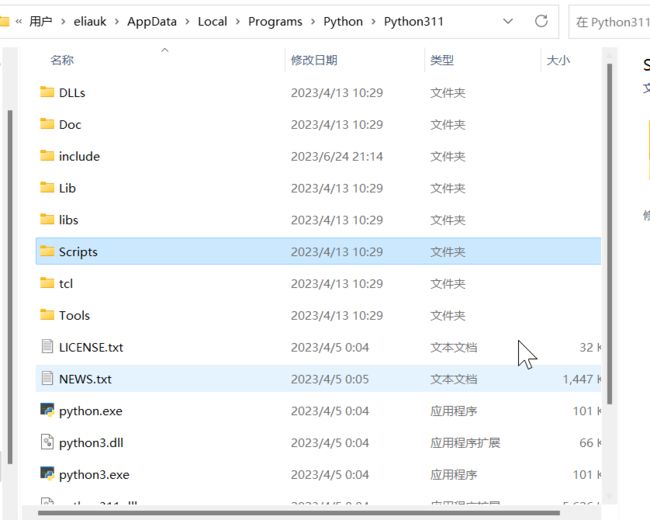
我们打开文件夹C:\Users\xxx\AppData\Local\Programs\Python\Python311 ,这里就是我们安装好的解释器。
Python311目录下 有 python.exe
Scripts 目录下 有 pip.exe

二、库的安装
整个数据挖掘基础阶段会用到Matplotlib、Numpy、Pandas、Ta-Lib等库,为了统一版本号在环境中使用,将所有的库及其版本放到了文件requirements.txt当中,然后统一安装。
2.1 使用pip命令安装virtualenvv
pip install virtualenv
创建默认虚拟环境
virtualenv eliauk
创建指定 Python 版本的虚拟环境virtualenv -p C:\Users\eliauk\AppData\Local\Programs\Python\Python311\python.exe eliauk
cd eliauk
进入虚拟环境.\Scripts\activate
在虚拟环境的任意目录下退出deactivate
扩展:cmd无法使用pip,报错:Fatal error in launcher: Unable to create process using …
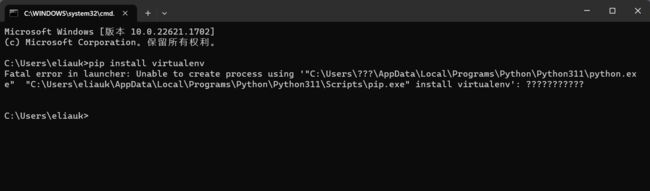
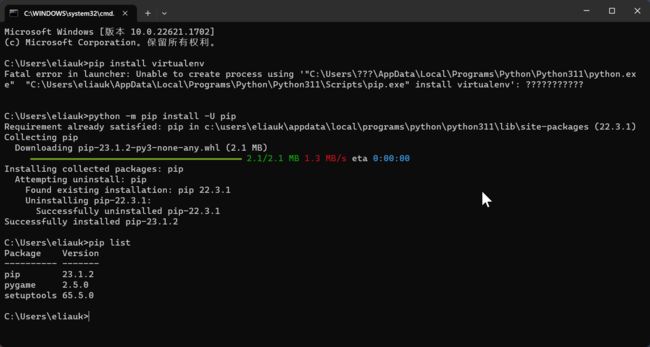
解决办法: 升级 pip
python -m pip install -U pip
pip --version查看版本

再查看 pip list 就会成功
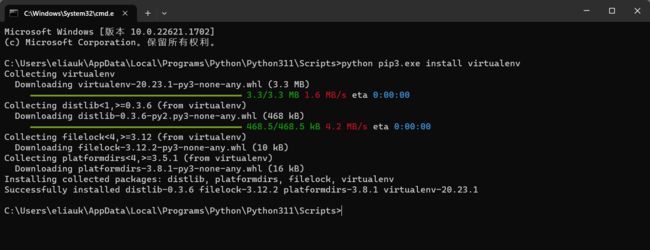
也可以跳过这个问题 在python安装目录下的 Scripts目录下cmd
输入
python pip3.exe install ***(想安装的包)

2.2 安装virtualenvwrapper-win
# 分为windows版和非windows版本
# 非Windows
pip install virtualenvwrapper
# Windows
pip install virtualenvwrapper-win
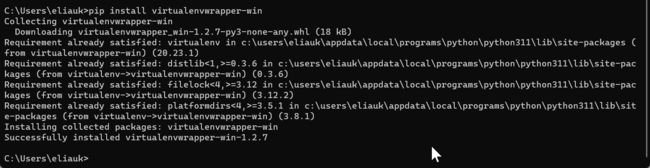
cmd中输入virtualenvwrapper,可以看到相关命令
创建并进入虚拟环境mkvirtualenv eliauk
指定Python版本创建 虚拟环境mkvirtualenv --python=C:\\Users\\eliauk\\AppData\\Local\\Programs\\Python\\Python311\\python.exe eliauk
安装win版本后可以是有命令进行虚拟环境的进入workon eliauk
删除虚拟环境rmvirtualenv eliauk
查看所有虚拟环境lsvirtualenv
进入当前虚拟环境所在的目录cdvirtualenv

2.3 新建一个用于人工智能环境的虚拟环境
-
指定Python版本创建 虚拟环境eliauk- 非Windows
mkvirtualenv -p /usr/local/bin/python3 eliauk- Windows
mkvirtualenv --python=C:\\Users\\eliauk\\AppData\\Local\\Programs\\Python\\Python311\\python.exe eliauk创建并进入虚拟环境
mkvirtualenv eliauk
安装win版本后可以是有命令进行虚拟环境的进入workon eliauk
删除虚拟环境rmvirtualenv eliauk
查看所有虚拟环境lsvirtualenv
进入当前虚拟环境所在的目录cdvirtualenv
Matplotlib画图Numpy高效的运算工具Pandas数据处理工具- 金融数据分析与挖掘(TA-Lib、tables、jupyter)
TA-Lib在股票中有一些技术分析指标,就是一个技术指标库tables用来支持读取某一种特殊的非常好用的数据文件的工具,这个文件hdf5,是一种经过压缩处理的存储数据的文件jupyter是进行数据挖掘分析展示很好的一个平台,接下来整个数据挖掘基础阶段经常用的工具
matplotlib==2.2.2
numpy==1.14.2
pandas==0.20.3
TA-Lib==0.4.16
tables==3.4.2
jupyter==1.0.0

激活虚拟环境
workon 虚拟环境名eliauk
使用pip命令安装
pip install -r requirements.txt

2.3.1 windows下 python 使用 pip 安装TA-Lib报错的原因及解决方法
Windows 10 x64 下使用pip install ta-lib命令安装TA-Lib库时会报错
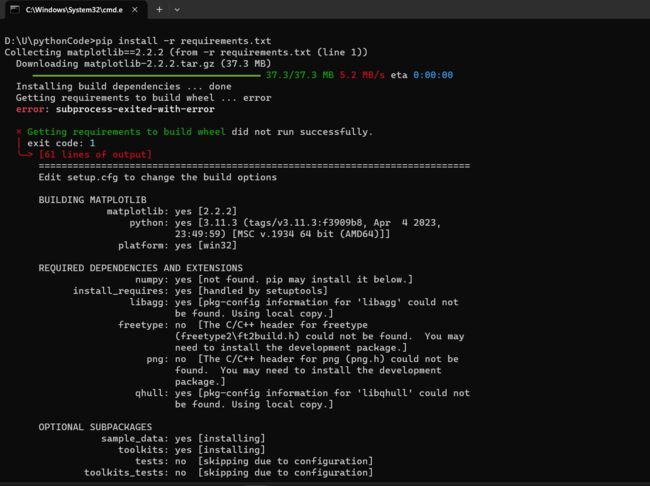
问题原因 & 解决办法
-
不能直接pip下载。下载的是tar.gz的文件。windows不能解压运行。看了下清华的地址列表。只有tar.gz的和一个压缩包。其他地址没看。
直接下载压缩包文件。在使用python setup.py install的时候会使用到c++。然后又是一堆缺少dll的麻烦。dll补全以后又不能调用…
ta-lib没有64bit的库。 TA-lib的底层是一个C库。所以你需要从源码编译一个64bit的dll,或者用别人编译好的。 -
在 https://www.lfd.uci.edu/~gohlke/pythonlibs/ 找到ta-lib库。下载对应的版本的whl文件。
比如:TA_Lib-0.4.24-cp38-cp38-win_amd64.whl(前面是库版本,后面是对应的python版本。最后的数字代表windows系统。32位或者64位。电脑属性查看或者cmd里python查看) -
一定要一一对应。否则会报
ERROR: TA_Lib-0.4.24-cp38-cp38-win32.whl is not a supported wheel on this platform.平台不符合的错误。 -
下载出来的文件不能随便改名。否则会报
ERROR: TA_Lib64.whl(你更改后的文件名) is not a valid wheel filename.文件名无效错误。
另外,若想将TA-Lib包安装在python全局系统环境,则还要确保以下两项:
- 确保pip添加到windows环境变量。在哪都能使pip。
- 确保以上都满足cmd进入下载文件的位置。
TA_Lib-0.4.24-cp38-cp38-win_amd64.whl下载页面
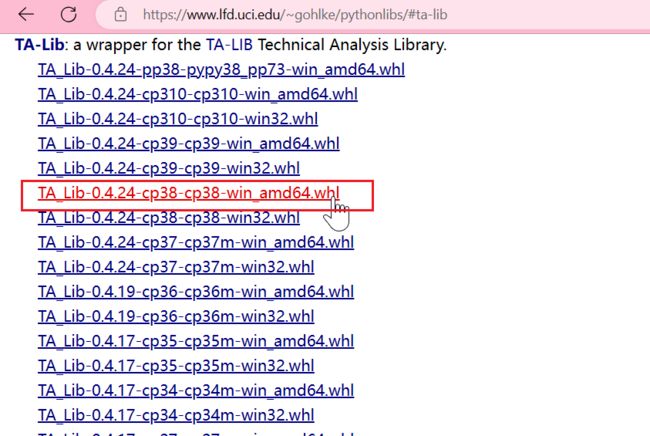
点一下 下载,打开cmd
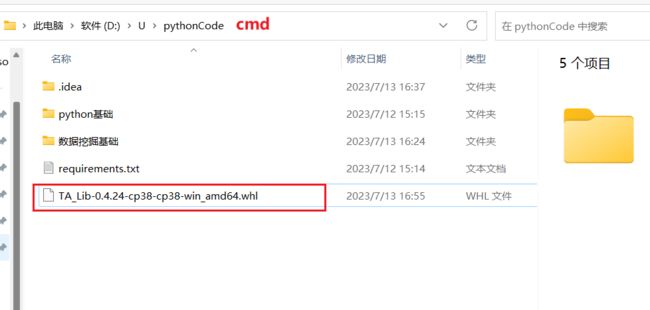 重新下载较新版本的离线包(我下载的是如下版本)
重新下载较新版本的离线包(我下载的是如下版本)
pip install TA_Lib-0.4.24-cp38-cp38-win_amd64.whl
install的内容必须与路径所在目录的文件夹中whl文件的名字相同
然后又报错了ERROR: TA_Lib-0.4.24-cp38-cp38-win_amd64.whl is not a supported wheel on this platform.
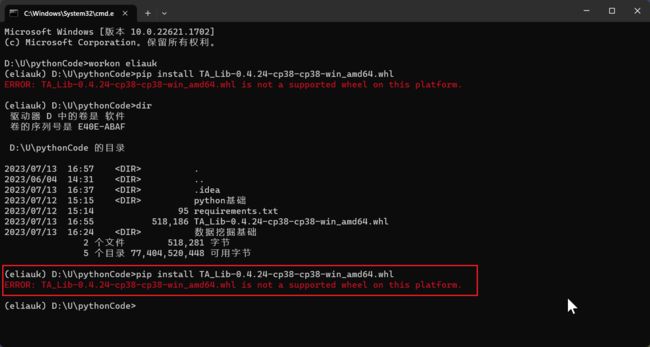
离线安装TA_Lib 报错:whl is not a supported wheel on this platform.
原因:提示不支持当前平台,文件名格式不对
若在官网上没有符合描述的版本,需要手动重命名whl文件。
下面细致介绍每一步怎么做。
解决办法
使用如下命令查看,当前平台支持的版本
pip debug --verbose
提示如下:
D:\U\pythonCode>pip debug --verbose
WARNING: This command is only meant for debugging. Do not use this with automation for parsing and getting these details, since the output and options of this command may change without notice.
pip version: pip 23.1.2 from C:\Users\eliauk\AppData\Local\Programs\Python\Python311\Lib\site-packages\pip (python 3.11)
sys.version: 3.11.3 (tags/v3.11.3:f3909b8, Apr 4 2023, 23:49:59) [MSC v.1934 64 bit (AMD64)]
sys.executable: C:\Users\eliauk\AppData\Local\Programs\Python\Python311\python.exe
sys.getdefaultencoding: utf-8
sys.getfilesystemencoding: utf-8
locale.getpreferredencoding: cp936
sys.platform: win32
sys.implementation:
name: cpython
'cert' config value: Not specified
REQUESTS_CA_BUNDLE: None
CURL_CA_BUNDLE: None
pip._vendor.certifi.where(): C:\Users\eliauk\AppData\Local\Programs\Python\Python311\Lib\site-packages\pip\_vendor\certifi\cacert.pem
pip._vendor.DEBUNDLED: False
vendored library versions:
CacheControl==0.12.11
colorama==0.4.6
distlib==0.3.6
distro==1.8.0
msgpack==1.0.5
packaging==21.3
platformdirs==3.2.0
pyparsing==3.0.9
pyproject-hooks==1.0.0
requests==2.28.2
certifi==2022.12.07
chardet==5.1.0
idna==3.4
urllib3==1.26.15
rich==13.3.3 (Unable to locate actual module version, using vendor.txt specified version)
pygments==2.14.0
typing_extensions==4.5.0 (Unable to locate actual module version, using vendor.txt specified version)
resolvelib==1.0.1
setuptools==67.7.2 (Unable to locate actual module version, using vendor.txt specified version)
six==1.16.0
tenacity==8.2.2 (Unable to locate actual module version, using vendor.txt specified version)
tomli==2.0.1
webencodings==0.5.1 (Unable to locate actual module version, using vendor.txt specified version)
Compatible tags: 39
cp311-cp311-win_amd64
cp311-abi3-win_amd64
cp311-none-win_amd64
cp310-abi3-win_amd64
cp39-abi3-win_amd64
cp38-abi3-win_amd64
cp37-abi3-win_amd64
cp36-abi3-win_amd64
cp35-abi3-win_amd64
cp34-abi3-win_amd64
cp33-abi3-win_amd64
cp32-abi3-win_amd64
py311-none-win_amd64
py3-none-win_amd64
py310-none-win_amd64
py39-none-win_amd64
py38-none-win_amd64
py37-none-win_amd64
py36-none-win_amd64
py35-none-win_amd64
py34-none-win_amd64
py33-none-win_amd64
py32-none-win_amd64
py31-none-win_amd64
py30-none-win_amd64
cp311-none-any
py311-none-any
py3-none-any
py310-none-any
py39-none-any
py38-none-any
py37-none-any
py36-none-any
py35-none-any
py34-none-any
py33-none-any
py32-none-any
py31-none-any
py30-none-any
从中我们可以看到Compatible tags字样,这些就是当前Python版本可以适配的标签。例如,我的Python版本是3.11,可以匹配下面这些文件名:
Compatible tags: 39
cp311-cp311-win_amd64
cp311-abi3-win_amd64
cp311-none-win_amd64
cp310-abi3-win_amd64
cp39-abi3-win_amd64
cp38-abi3-win_amd64
cp37-abi3-win_amd64
cp36-abi3-win_amd64
cp35-abi3-win_amd64
cp34-abi3-win_amd64
cp33-abi3-win_amd64
cp32-abi3-win_amd64
py311-none-win_amd64
py3-none-win_amd64
py310-none-win_amd64
py39-none-win_amd64
py38-none-win_amd64
py37-none-win_amd64
py36-none-win_amd64
py35-none-win_amd64
py34-none-win_amd64
py33-none-win_amd64
py32-none-win_amd64
py31-none-win_amd64
py30-none-win_amd64
cp311-none-any
py311-none-any
py3-none-any
py310-none-any
py39-none-any
py38-none-any
py37-none-any
py36-none-any
py35-none-any
py34-none-any
py33-none-any
py32-none-any
py31-none-any
py30-none-any
把之前下的文件TA_Lib-0.4.24-cp38-cp38-win_amd64.whl 改名成 TA_Lib-0.4.24-py38-none-win_amd64.whl
pip install TA_Lib-0.4.24-py38-none-win_amd64.whl

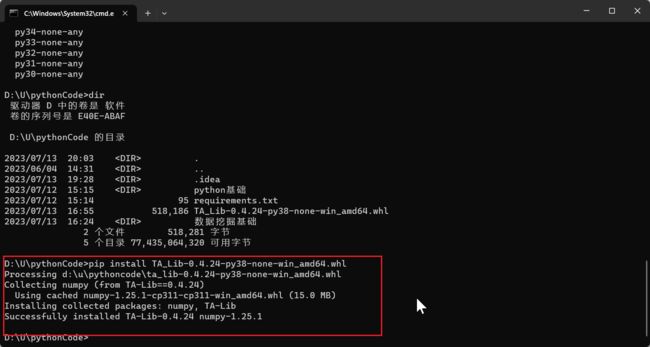
成功!!!!!!!!!
Linux系统如果Ta-Lib安装出现问题,需要先安装依赖库,按照以下步骤安装:
#获取源码库
sudo wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0,4.0-src.tar.gz
#解压进入目录
tar -zxvf ta-lib-0.4.0-src.tar.gz
cd ta-lib/
# 编译安装
sudo ./configure --prefix=/usr
sudo make
sudo make install
#重新安装python的TA-Lib库
pip install TA-Lib
Win系统如果安装Ta-Lib出现问题,直接到以下网址下载
https://www.lfd.uci.edu/~gohlke/pythonlibs/#ta-lib
注意:任何无法安装的情况都可以直接到以下网址查找下载
https://www.lfd.uci.edu/~gohlke/pythonlibs/
2.3.2 扩展:查看Python安装路径方法
对于Windows平台,打开cmd
- 使用命令
py -0p(注意0是零)
显示已安装的 python 版本且带路径的列表
带星号*的为默认版本。

2. 输入命令where Python
可输出Python的安装路径

三、Jupyter Notebook使用
Jupyter项目是一个非盈利的开源项目,源于2014年的ipython项目,并逐渐发展为支持跨所有编程语言的交互式数据科学计算的工具。
- Jupyter Notebook,原名IPython Notbook,是IPython的加强网页版,一个开源Web应用程序,
web版的IPython。 - 名字源自Julia、Python和R(数据科学的三种开源语言)
- ju - Julia
- py - Python
- ter - R
- Jupyter 英语翻译是木星、宙斯
- 是一款程序员和科学工作者的编程/文档/笔记/展示软件
- .ipynb文件格式是用于计算型叙述的JSON文档格式的正式规范
 Jupyter项目旨在开发跨几十种编程语言的开源软件,开放标准和用于交互式计算的服务
Jupyter项目旨在开发跨几十种编程语言的开源软件,开放标准和用于交互式计算的服务
3.1 为什么要用Jupyter Notebook?
- 传统软件开发: 工程 / 目标明确
- 需求分析,设计架构,开发模块,测试
- 数据挖掘: 艺术 / 目标不明确
- 目的是具体的洞察目标,而不是机械的完成任务
- 通过执行代码来理解问题
- 迭代式地改进代码来改进解决方法
实时运行的代码、叙事性的文本和可视化被整合在一起,方便使用代码和数据来讲述故事。
3.2 Jupyter Notebook的使用
3.2.1 界面启动
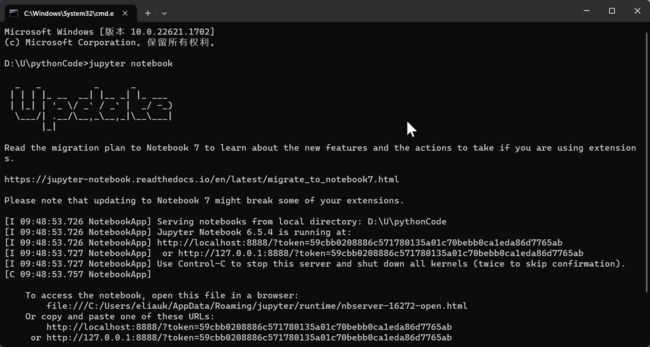
环境搭建好后,本机终端输入jupyter notebook命令或者ipython notebook,按回车,它就会自动弹出浏览器窗口打开 Jupyter Notebook,本地notebook默认URL为 http://localhost:8888/
想让notebook打开指定目录,只要进入此目录后执行命令即可。
# 进入虚拟环境
workon 虚拟环境名eliauk
# 输入命令
jupyter notebook
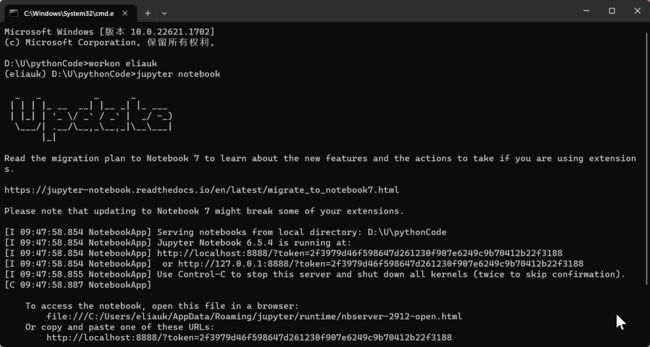
3.2.2 创建文件
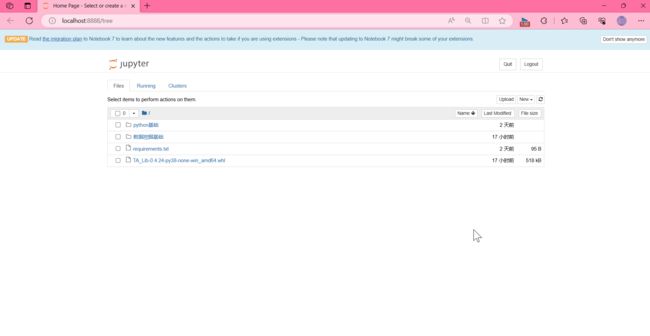
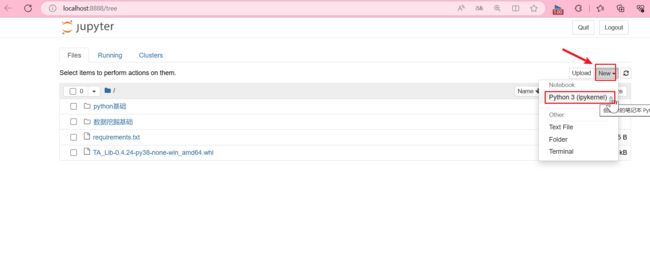
新建文件
notebook的文档格式是.ipynb
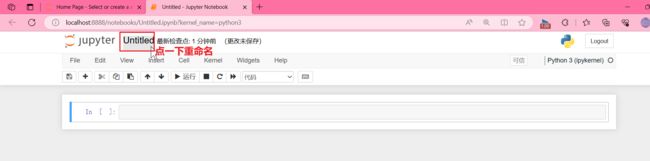
重命名

写代码
print('hello world')

运行代码
- 快捷键
Shift+Enter(回车键)
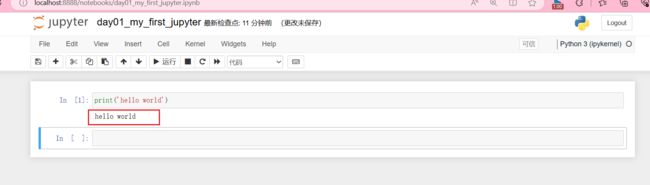
就出来啦!
2. 鼠标点
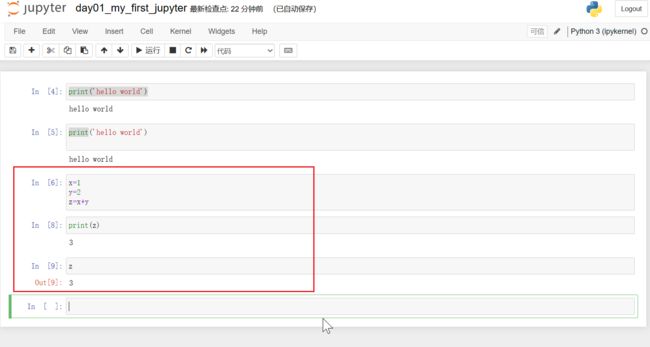
如果我们不用print打印输出,那么就会以Out形式输出。
标题栏:点击标题(如Untitled)修改文档名
菜单栏:
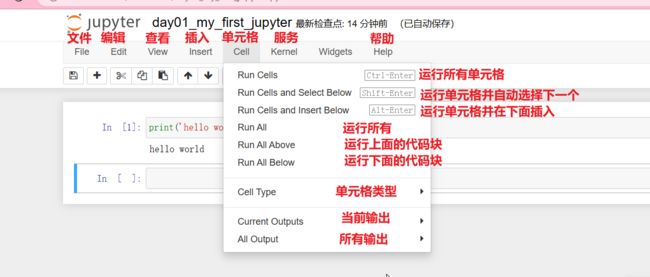
- 导航-File-Download as,另存为其他格式
- 导航-Kernel
- Interrupt,中断代码执行 (程序卡死时)
- Restart,重启Python内核(执行太慢时重置全部资源)
- Restart & Clear Output,重启并清除所有输出
- Restart & Run All,重启并重新运行所有代码
3.2.3 cell操作
一对 In Out 会话被视作一个代码单元,称为 cell。
![]()
Jupyter支持两种模式:
- 编辑模式(Enter)
- 命令模式下
回车Enter或鼠标双击cell进入编辑模式 - 可以操作cell内文本或代码,剪切 / 复制 / 粘贴移动等操作
- 命令模式下
- 命令模式(Esc)
- 按
Esc或鼠标在本单元格之外点一下退出编辑,进入命令模式 - 可以操作cell单元本身进行剪切 / 复制 / 粘贴 / 移动等操作
- 按
- 鼠标操作

- 快捷键操作
-
两种模式通用快捷键
shift + enter,执行本单元代码,并跳转到下一单元- Ctrl+Enter,执行本单元代码,留在本单元
cell行号前的 * ,表示代码正在运行。

-
命令模式:按ESC进入
- Y, cell切换到Code模式
- M ,cell切换到Markdown模式
A,在当前cell的上面添加cellB,在当前cell的下面添加cell双击D:删除当前cell- Z,回退
- L,为当前cell加上行号
- ctrl+Shift+P,对话框输入命令直接运行
- 快速跳转到首个cell, Crtl+Home
- 快速跳转到最后一个cell, Crtl+End -->
-
编辑模式:按Enter进入
- 多光标操作:
Ctrl 键+点击鼠标(Mac:CMD+点击鼠标) - 回退:
Ctrl+Z(Mac:CMD+Z) - 补全代码:变量、方法后跟
Tab键 - 为一行或多行代码添加 / 取消注释:
Ctrl+/(Mac:CMD+ / ) - 屏蔽自动输出信息: 可在最后一条语句之后加一个分号
- 多光标操作:
-
3.2.3 markdown演示
Jupyter是支持markdown显示的,而且我们用到的markdown也不是特别复杂,所以只要满足我们的需求就行。
markdown就是写笔记写文档的一个轻量级的语言,这里只演示简单语法。
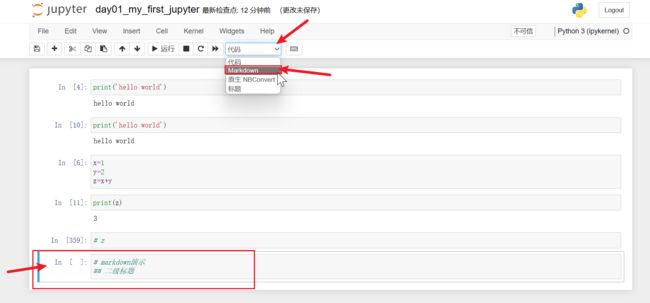
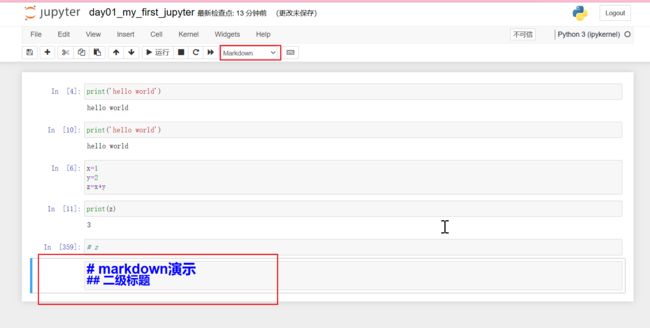 这个样子还不是markdown最终效果,按Shift+Enter
这个样子还不是markdown最终效果,按Shift+Enter
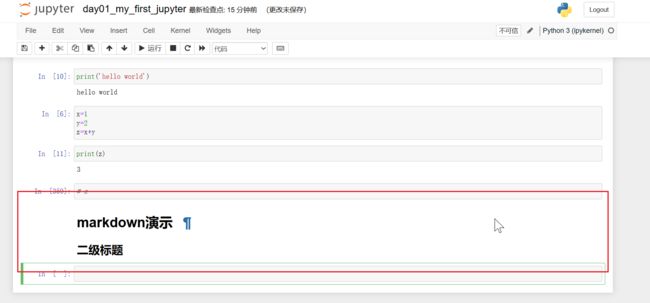
基础语法:
markdown演示
# 一级标题
## 二级标题
### 三级标题
#### 四级标题
##### 五级标题
- 缩进
- 二级缩进
- 三级缩进
效果:
