学习系统编程No.25【核心转储实战】
引言:
北京时间:2023/6/16/8:39,实训课中,大一下学期最后有课的一天,还有两天就要期末考啦!目前什么都还没有复习,不到星期天晚上,咱不慌,小小挂科,岂能拦得住我补考,哈哈哈!小事,莫慌,该篇博客出炉之时,就是我复习之日,临阵磨枪不快也光,这方面我是专业的。并且明天是英语四六级考试,看着舍友那没前途的样子,我就想起之前它们报名英语四六级那牛哄哄的场景,全宿舍就我一个人没报上,哈哈哈!在之前的文章引言中有记录哦!并且伴随着暑假的来临,我们就拥有了一个良好的更文环境,并且在更文的同时,我们就可以进行刷题任务了,等这个暑假结束,希望能更上一层楼吧!无论是学习新知识,还是复习之前的知识,都没有任何不同,复习不仅可以让我们掌握的更牢,而且还能对某些知识接触的更深,印证所学知识,增强信心,所以复习的重要性其实比学习新知识更重要。多的不唠,正式进入该篇博客的主题,重点是有关核心转储方面的知识,其次是上篇博客剩下的有关硬件异常产生信号相关知识。
硬件异常产生信号
上篇博客中,我们学习了有关如何使用系统调用接口向进程发送信号和外设产生信号并发送给进程的相关知识,并且明白了进程在收到信号时的三种处理方式,但上篇博客由于时间关系,还剩下了部分有关向进程发送信号知识没有介绍,所以下面我们就来详解一下有关硬件异常产生信号,最终发送给进程的相关知识吧!首先想要搞懂硬件异常产生信号就要搞懂什么叫硬件异常,我们通过两个编码时常见的硬件异常问题来了解什么是硬件异常,如下:
为什么除0错误会导致程序终止?
结合之前学习过的知识,我们明白,当我们编写了一个程序,该程序最终经过编译链接等过程,生成了一个可执行的二进制文件,并且该二进制文件被加载到了内存中,在操作系统的管理调配之下,等待一系列资源,最终被CPU处理,但由于我们在编码的时候,不小心编写了一个除0错误,当CPU处理该句代码时,CPU众多寄存器中的状态寄存器对应的溢出标志位就会被置1,此时当状态寄存器上的溢出标志位被置1,就会导致CPU硬件产生异常。操作系统检测到该行为之后,就会发送一个硬件异常信号给对应的进程,从而终止对应的进程,如下图所示:

所以通过上述知识,我们此时就知道,除0错误造成程序崩溃的原因,本质就是因为CPU在处理二进制代码的时候,状态寄存器中的溢出标志位被置1 ,导致产生硬件异常,最后操作系统为了降低影响,就向对应的进程发送了一个硬件异常终止信号(并且此时该信号就是8号信号),然后进程就收到该终止信号,最终执行该信号对应的默认动作,程序终止,并且将对应的终止信号返回给我们,如上图中所示的:Floating point exception
注意: 终止对应的进程并不会解决硬件异常问题,只有当操作系统通过一系列的操作修复了硬件层面的问题之后,硬件异常问题,才有可能被解决。通过发送对应的硬件异常信号,终止进程,只是为了降低该进程对系统的影响。
几个拓展问题,如下:
1.操作系统如何知道那一个硬件异常,如何知道那一个进程引起硬件异常呢?
CPU中除了状态寄存器,还有很多寄存器,其中某个寄存器就直接存储了正在运行进程的进程pcb地址,此时根据这个地址,操作系统就可以很快的找到对应引发异常的进程,完成后序发送信号的操作,所以操作系统就是通过访问CPU寄存器中进程pcb地址来找到对应的进程,那么操作系统是如何知道是那一个硬件发生异常呢?这个问题就更加简单,因为操作系统的核心工作就是管理软硬件资源,所以当某一个硬件出现异常,那么操作系统肯定能第一时间发现,并且处理。
2.如果使用signal接口将8号信号的执行动作改为自定义动作会怎样呢?
在上篇博客中,我们学习了signal系统调用接口,它可以捕获除9号信号之外的所有信号,并且将对应信号的默认执行动作更改为自定义执行动作,由于上述产生硬件异常之后,操作系统发送给对应进程的信号是一个8号信号,并不是9号信号,所以如果我们使用signal接口去捕获8号信号,将其默认终止进程动作,改为非终止进程的其它自定义动作,此时会产生什么现象呢?如下图所示:

此时我们发现,当8号信号的默认终止进程动作被我们修改完成之后,程序直接进入死循环,为什么会发生这样的现象呢?本质同理上述所说,由于我们的代码中有除0错误,CPU对应状态寄存器的溢出标志位被置1,产生硬件异常,操作系统识别之后,为了降低影响,就需要将对应的进程给终止,但由于此时操作系统发送的8号信号起不到终止作用,并且CPU状态寄存器的溢出标志位一直为1,也就是一直会产生硬件异常,那么此时就会导致操作系统一直检测到CPU硬件异常,从而一直向对应的进程发送8号信号,最终导致死循环。
为什么野指针会导致程序终止
搞定了上述除0错误导致硬件异常的问题,此时我们来看看野指针问题具体是如何导致硬件异常的吧!我们以经典的对空指针解引用造成野指针问题为例,首先明白为什么对空指针解引用会导致野指针问题,因为空指针是一个不指向任何有效对象或内存地址的指针,所以如果你对其进行解引用的话,访问到的就是一个无效的地址,没有被定义的地址,此时就会导致非法访问问题,也就是野指针问题,如下图所示:

强调: Segmentation fault 表示的意思是段错误,本质就是当程序在访问不属于自己地址空间的内存区域时出现的问题或者是当程序试图读取或写入一个无效的内存地址时,操作系统就会抛异常,出现段错误,常见的段错误有:对空指针解引用、使用未初始化指针、越界访问、栈溢出。
通过上述文字和图示理解,明白了什么是段错误之后,此时我们正式开始分析野指针导致硬件异常问题,当然也就是为什么野指针会导致程序终止。首先明白,当我们在程序中定义指针变量指向某一块地址时,无论是该指针变量的地址,还是被指向变量的地址,它们本质都是虚拟地址,所以显然,当该程序生成二进制可执行程序时,该程序对应虚拟地址上定义的变量都需要映射到物理内存中,并且明白,这个虚拟地址到物理地址的映射过程不只是由操作系统独立完成,而是内存管理单元(MMU)在操作系统的控制下完成,所以上述映射过程本质是一个软硬件结合的过程,当然由于虚拟地址空间和物理内存之间是通过页表完成映射,明白页表是一个较为复杂的结构,不仅涉及使用软硬件进行映射转换,还包括了许多权限等细节问题,该篇博客不细细讲解,在之后有关学习过程中,我们一定会再次遇到,到那时我们再深入了解。此时重点还是搞懂野指针导致程序崩溃问题,明白了上述知识,此时搞定该问题,顺理成章,如下:
详解野指针导致硬件产生信号问题
通过上述知识,首先明白,当我们将一个指针变量初始化为空指针(nullptr)时,由于代码中的地址都是虚拟地址,所以当CPU在访问被初始化为空指针的指针变量时,本质访问的就是虚拟地址中的0号地址。其次明白,对应虚拟地址中的数据需要通过页表映射到物理内存中,而页表的本质是通过映射(哈希)去查找对应的K/V关系,并且在查找这个K/V关系,进行转换的时候,这个动作不是由操作系统独立完成,而是由硬件完成,当然也就是上述所说的内存管理单元(MMU),也就是页表通过K/V关系进行转换的时候,需要将数据导入到内存管理单元(MMU),让内存管理单元这个硬件去进行转换,所以说虚拟地址到物理地址,我们采用的方法是一个软硬件结合的方法。反正最终内存管理单元具有了相应的虚拟到物理的映射关系,就可以将虚拟地址转换为物理地址,然后去访问物理内存中对应的地址。明白了这两点,此时搞定野指针导致硬件异常问题就如同砍瓜切菜一般简单,本质同理上述,也就是当CPU访问被初始化为空指针的指针变量时,访问的是虚拟地址中的0号地址,并且由于CPU想要运行一个程序,只能从内存中读取相应数据,所以我们的程序(编写的代码)就一定需要映射到物理内存中,当然也就是虚拟地址通过页表映射到物理地址的过程,所以当CPU读取到了虚拟地址中的0号地址时,此时MMU就需要去判断该0号地址在物理内存是否存在对应的映射关系(也就是是否有相对应的物理地址),如果没有,那么MMU就会产生异常,当然也就是硬件异常。同理,当MMU发生硬件异常,产生了硬件异常信号之后,操作系统为了降低影响,就会找到对应的进程(也就是我们编写的程序),然后发送对应的信号(对应进程pcb位图结构中写入),最终该进程执行该信号对应的默认动作,进程被终止,程序崩溃。如下图所示:
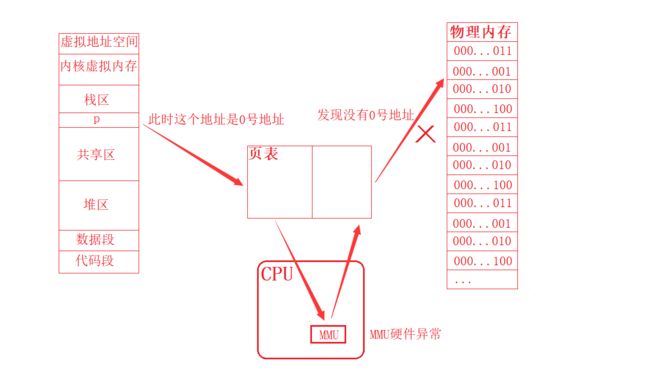
当然上述我们介绍的只是MMU发生硬件异常中最普通的一种,在MMU进行虚拟地址和物理地址进行转换时,MMU还需要考虑权限等问题,当没有对应权限或者权限不匹配时,MMU也会产生硬件异常,最终同理操作系统发送11号信号,让对应的进程终止。如下代码所示:发现当发生段错误时,操作系统确实是发送11号信号来让进程终止

如上图代码所示,死循环的原因同理,这里不多做讲解。强调:如果硬件异常了,我们是没有资格修改的,只有操作系统自己才能修改,如:溢出标志位由0置1之后,想要再置0,只能是操作系统来完成,此时MMU硬件异常同理一样。
拓展知识:
MMU硬件在哪里?
这个内存管理单元被集成在CPU当中,也就是说CPU的硬件构成非常的复杂。注意:CPU内读到的地址都是虚拟地址,所以当CPU想要去访问物理地址,就需要让对应寄存器去访问对应的页表,然后让页表中的数据可以加载到MMU中,最终经过MMU的转化,CPU才能获取到物理内存中对应的地址,从而让CPU可以访问到物理内存中的地址。并且注意:无论是CPU内对应寄存器的溢出标志位出问题,还是CPU内MMU硬件出现问题,操作系统想要识别到具体是那个硬件出现异常,都是需要经过CPU进行处理,只有CPU处理过之后,操作系统才能检测到。
总:我们写代码导致程序崩溃的根本原因就是因为硬件异常问题,然后导致操作系统发送对应的信号去终止该进程。
Core dump理解
在之前学习有关进程控制和进程等待相关内容时,我们详细讲解了有关进程退出码和退出信号相关知识,具体如下图所示:

通过上图明白,当时在学习有关进程退出码和进程退出信号时,学习了wait和waitpid等接口,并且知道这些接口不仅可以避免僵尸进程的出现,而且可以通过返回值的形式获取到该进程的退出码和退出信号,具体退出码如上图位图结构所示,后16个比特位中的最后7位表示的是退出信号,次第8位表示退出码,而16个比特位中最后剩下的那个表示的就是我们即将学习的core dump标志位,这个标志位具体表示什么意思呢?
什么是核心转储
上述Core dump也就是核心转储,顾名思义,为什么要叫做核心转储呢?原来是因为Linux系统提供了一种功能,可以将一个进程在发生异常的时候,将该进程中重要数据给保存下来,这个功能或者说这个过程就叫做核心转储,并且注意:当发生核心转储时,对应被核心转储的数据是保存在当前进程的运行目录下,存储在对应的磁盘中,并且一般就命名为core.pid这样的二进制文件。所以当我们明白了上述核心转储的基础知识,下述我们正式来看看核心转储具体如何,如下:
首先注意,由于云服务器默认将核心转储的功能给关闭了,所以我们需要先通过指令的形式打开云服务器上的核心转储功能,如下所示:
指令:ulimit -a 查看当前系统资源的上限,如下图所示:
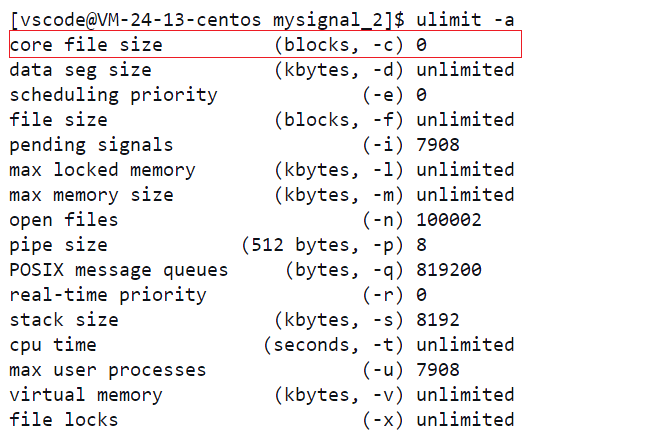
如上图所示,此时我们就可以看到Linux系统下,当前用户一系列的资源上限,什么文件大小,什么栈大小,什么管道大小等,当然最关键的就是上述我们即将要讲的core file的大小,可以发现,在云服务器上core file size的大小确实是为0,当然0表示的也就是关闭的意思,当然,因为此时我们想要验证对应进程被终止时,是否会发生核心转储,所以此时我们需要将该功能给打开,指令:ulimit -c 10240,此时云服务器上的核心转储功能我们就打开了,并且其大小设置为了10240,如下图所示:
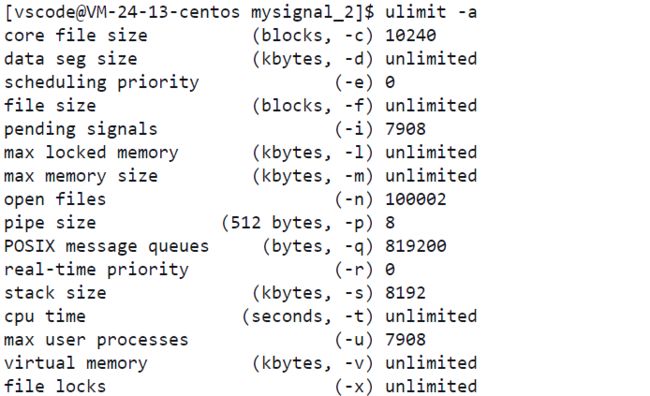
通过上述一系列的操作,此时我们就成功地将云服务器上的核心转储功能给打开啦!接下来我们就可以进行验证,看当一个进程收到了对应的信号时,是否为发生核心转储,不过在此之前,我们需要先了解如下几个信号,可以发现不同的信号对应的行为是不同的,有的是Trem状态,有的是Core状态,那么这两种行为有什么区别呢?

猜想:只有对应行为状态是Core的信号才有资格发生核心转储,处于Term行为状态的信号并不会发生核心转储。到底是不是这样的呢?有待我们验证,我们给一个死循环程序发送不同行为状态的信号,看同一个进程收到不同的信号时,产生的现象是否不同如下图所示:
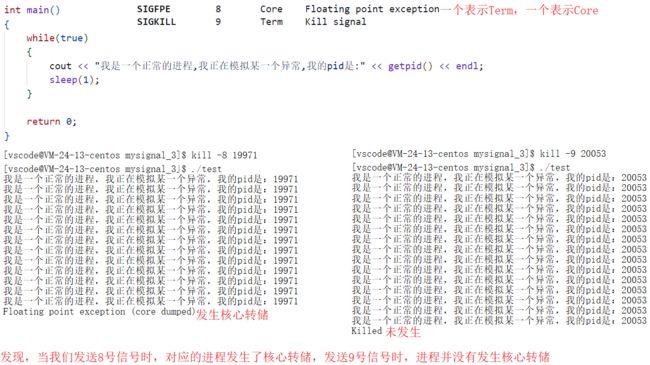
果然和我们猜想的一样,只有行为为Core的信号编号,才能发生核心转储,信号为Term并不发生,并且同理,此时我们在该进程对应的运行目录下,可以发现核心转储后被保存的文件,如下图所示:

核心转储有什么用?
明白了上述知识,此时我们就了解了核心转储的具体内容和如何产生核心转储,此时面临的最后一个问题就是核心转储有什么用呢?其实这个问题很好回答,从核心转储的作用上,我们就可以看出,核心转储就是保存关键数据,所以同理现实生活中的例子,在危机时刻保留某些东西,本质就是为了留下证据,所以核心转储也是一样,本质就是为了可以在一个程序出现问题之后,通过核心转储可以快速的定位问题,从而分析问题、解决问题,那么具体如何通过核心转储来定位问题呢?如下所示:
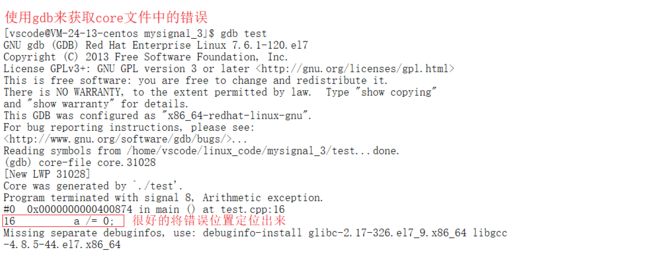
注意: Linux系统下的程序默认都是处于release模式,如果想使用gdb进行调式,就需要在后缀中带一个 -g(编译过程g++ -o file file.cpp -g)
具体步骤:
首先输入指令gdb file,打开对应可执行文件,并且由于该文件已经产生了一个core文件,所以该程序一定是一个错误程序,此时就需要对其进行错误查询,看它是为什么出问题,在gdb模式下,直接执行core-file core.pid,表示的意思就是使用core-file去执行核心转存文件,此时gdb就直接可以帮我们定位该core文件具体的错误原因。所以这种形式的调式也叫作事后调式,让gdb根据核心转储文件自动定位问题。
那么该功能这么好用,云服务器为什么要关闭它呢?
因为核心转储生成的core文件非常的占用内存,此时就害怕存在某种一直生成core文件的程序,此时就会导致生成大量的core文件,极具的占用内存,此时就可能会导致整个系统没有内存可用,导致整个操作系统奔溃,同理关闭云服务器上的核心转储,ulimit -c 0,将大小给为0表示的就是关闭。